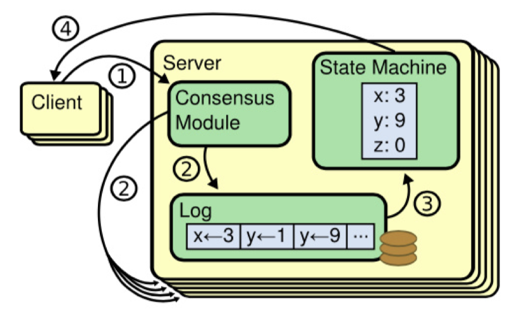
Raft’s RPCs typically require the recipient to persist information to stable storage, so the broadcast time may range from 0.5ms to 20ms, depending on storage technology. As a result, the election timeout is likely to be somewhere between 10ms and 500ms.
采用新配置时,旧配置没有收到 Heartbeat,可能 ++term 然后变 candidate,随之会影响一些没收到 $C_{new}$ 日志的机器,把它们 term 也搞起来。这里的方案是,Leader 存在的时候,不会切 Leader 重新选举;然后 Server 在一次选举之间,如果收到了更高 term 的请求,也要等待一定时间,防止心跳把自己打炸
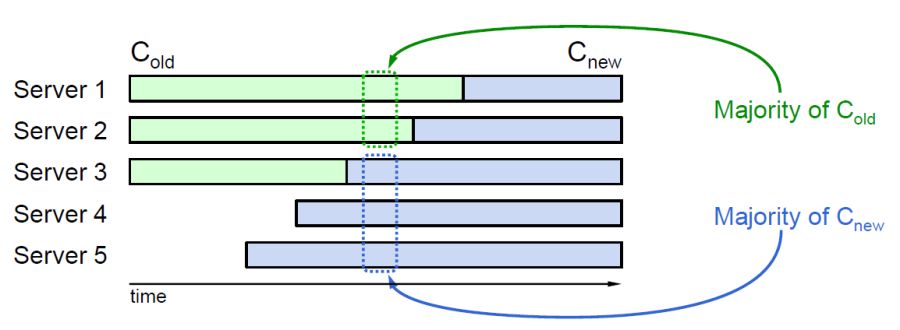
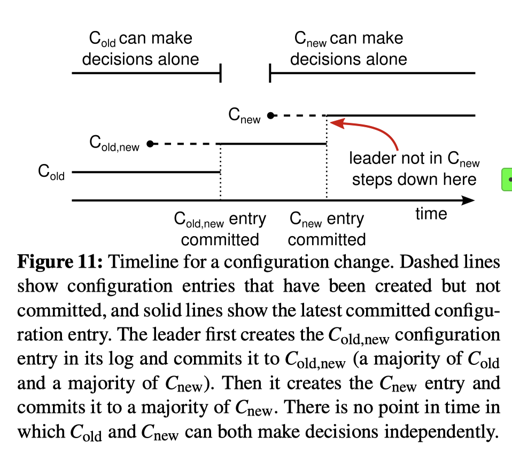
那么,为什么 Conf 需要直接用 new 的呢?走 Committed 在进入下一阶段的目的是在第一阶段达成两方的 Majority,第二阶段只需要新的 Majority,它们不相交。而直接用的目的是不用追踪大部分机器的 CommitIndex:
If servers adopted $C{new}$ only when they learned that $C{new}$ was committed, Raft leaders would have a difficult time knowing when a majority of the old cluster had adopted it. They would need to track which servers know of the entry’s commitment, and the servers would need to persist their commit index to disk; neither of these mechanisms is required in Raft. Instead, each server adopts $C{new}$ as soon as that entry exists in its log, and the leader knows it’s safe to allow further configuration changes as soon as the $C{new}$ entry has been committed. Unfortunately, this decision does imply that a log entry for a configuration change can be removed (if leadership changes); in this case, a server must be prepared to fall back to the previous configuration in its log.
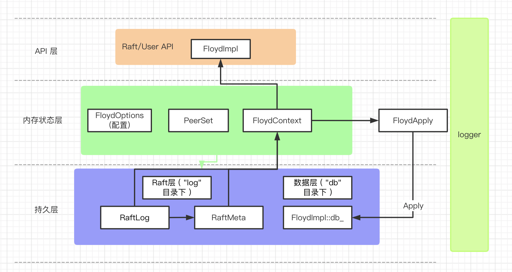
classFloyd { public: static Status Open(const Options& options, Floyd** floyd);
Floyd() { } virtual ~Floyd();
virtual Status Write(const std::string& key, const std::string& value)= 0; virtual Status Delete(const std::string& key)= 0; virtual Status Read(const std::string& key, std::string* value)= 0; virtual Status DirtyRead(const std::string& key, std::string* value)= 0; // ttl is millisecond virtual Status TryLock(const std::string& name, const std::string& holder, uint64_t ttl)= 0; virtual Status UnLock(const std::string& name, const std::string& holder)= 0;
// return true if leader has been elected virtualboolGetLeader(std::string* ip_port)= 0; virtualboolGetLeader(std::string* ip, int* port)= 0; virtualboolHasLeader()= 0; virtualboolIsLeader()= 0; virtual Status GetAllServers(std::set<std::string>* nodes)= 0;
// used for debug virtualboolGetServerStatus(std::string* msg)= 0;
// log level can be modified virtualvoidset_log_level(constint log_level)= 0;
private: // No coping allowed Floyd(const Floyd&); voidoperator=(const Floyd&); };
// when adding task to peer thread, we can consider that this job have been in the network // even it is still in the peer thread's queue voidFloydPrimary::NoticePeerTask(TaskType type){ for (auto& peer : (*peers_)) { switch (type) { case kHeartBeat: peer.second->AddRequestVoteTask(); break; case kNewCommand: peer.second->AddAppendEntriesTask(); break; default: } } }
// 对方的 Term 比自身高, 设置状态为 Follower, 更新 Term. if (res.request_vote_res().term() > context_->current_term) { // RequestVote fail, maybe opposite has larger term, or opposite has // longer log. if opposite has larger term, this node will become follower // otherwise we will do nothing context_->BecomeFollower(res.request_vote_res().term()); raft_meta_->SetCurrentTerm(context_->current_term); // 实际上相当于清空 ip/port. raft_meta_->SetVotedForIp(context_->voted_for_ip); raft_meta_->SetVotedForPort(context_->voted_for_port); return; } // 如果自身状态还是 Follower, 且对方的 Term 不比自己高, 那么要么投给自己, 要么没投.
if (context_->role == Role::kCandidate) { // kOk means RequestVote success, opposite vote for me if (res.request_vote_res().vote_granted() == true) { // granted // However, we need check whether this vote is vote for old term // we need ignore these type of vote. // // 可以成为 Leader 啦! if (CheckAndVote(res.request_vote_res().term())) { context_->BecomeLeader(); UpdatePeerInfo(); primary_->AddTask(kHeartBeat, false); } } else { // Note(mwish): 对方没有投票给自己, 怎么就变成 Follower 了. // 这个地方没有 Bug(因为 context_ 变更不会导致错误), 但是会很容易引起 bug // 我觉得可以全部 comment 掉. context_->BecomeFollower(res.request_vote_res().term()); raft_meta_->SetCurrentTerm(context_->current_term); raft_meta_->SetVotedForIp(context_->voted_for_ip); raft_meta_->SetVotedForPort(context_->voted_for_port); } } } return; }
/* * If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (5.1) * * 变成 follower, 然后设置 VoteFor. */ if (request_vote.term() > context_->current_term) { context_->BecomeFollower(request_vote.term()); // 推高自己的 term. raft_meta_->SetCurrentTerm(context_->current_term); } // if caller's term smaller than my term, then I will notice him if (request_vote.term() < context_->current_term) { LOGV(INFO_LEVEL, info_log_, "FloydImpl::ReplyRequestVote: Leader %s:%d term %lu is smaller than my %s:%d current term %lu", request_vote.ip().c_str(), request_vote.port(), request_vote.term(), options_.local_ip.c_str(), options_.local_port, context_->current_term); BuildRequestVoteResponse(context_->current_term, granted, response); return-1; }
// 论文: 安全性, 不能给 Log 比自己旧的投票.
uint64_t my_last_log_term = 0; uint64_t my_last_log_index = 0; raft_log_->GetLastLogTermAndIndex(&my_last_log_term, &my_last_log_index); // if votedfor is null or candidateId, and candidated's log is at least as up-to-date // as receiver's log, grant vote if ((request_vote.last_log_term() < my_last_log_term) || ((request_vote.last_log_term() == my_last_log_term) && (request_vote.last_log_index() < my_last_log_index))) { BuildRequestVoteResponse(context_->current_term, granted, response); return-1; }
{ slash::MutexLock l(&context_->global_mu); if (!result.ok()) { return; }
// here we may get a larger term, and transfer to follower // so we need to judge the role here if (context_->role == Role::kLeader) { /* * receiver has higer term than myself, so turn from candidate to follower */ if (res.append_entries_res().term() > context_->current_term) { context_->BecomeFollower(res.append_entries_res().term()); raft_meta_->SetCurrentTerm(context_->current_term); raft_meta_->SetVotedForIp(context_->voted_for_ip); raft_meta_->SetVotedForPort(context_->voted_for_port); } elseif (res.append_entries_res().success() == true) { if (num_entries > 0) { match_index_ = prev_log_index + num_entries; // only log entries from the leader's current term are committed // by counting replicas if (append_entries->entries(num_entries - 1).term() == context_->current_term) { AdvanceLeaderCommitIndex(); apply_->ScheduleApply(); } next_index_ = prev_log_index + num_entries + 1; } } else { uint64_t adjust_index = std::min(res.append_entries_res().last_log_index() + 1, next_index_ - 1); if (adjust_index > 0) { // Prev log don't match, so we retry with more prev one according to // response next_index_ = adjust_index; AddAppendEntriesTask(); } } } } return; }
intFloydImpl::ReplyAppendEntries(const CmdRequest& request, CmdResponse* response){ bool success = false; CmdRequest_AppendEntries append_entries = request.append_entries(); slash::MutexLock l(&context_->global_mu); // update last_op_time to avoid another leader election context_->last_op_time = slash::NowMicros(); // Ignore stale term // if the append entries leader's term is smaller than my current term, then the caller must an older leader if (append_entries.term() < context_->current_term) {
// we compare peer's prev index and term with my last log index and term uint64_t my_last_log_term = 0; Entry entry; if (append_entries.prev_log_index() == 0) { my_last_log_term = 0; } elseif (raft_log_->GetEntry(append_entries.prev_log_index(), &entry) == 0) { my_last_log_term = entry.term(); } else { return-1; }