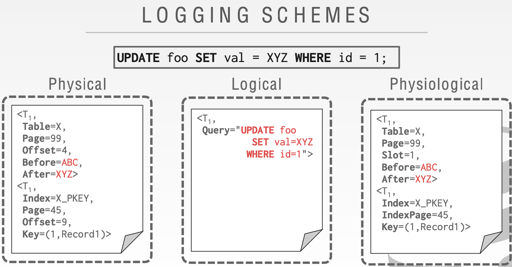
Database Recover System
对于一个 DB 系统而言,大概要考虑这些错误:
- transaction failure
- Logical error: 例如 db 的资源不够,输入错误等问题
- System error: 数据库系统进入了诸如死锁之类的状态
- System Crash: 硬件故障或者系统故障,可能导致持久存储上的数据损坏。(与这个相反,程序崩溃之后,不会影响持久数据的假设,成为 fail-stop assumption)。精心设计的系统即使出现逻辑 bug,也会有一些
assert等方式,让系统不至于出现数据损坏,所以这个模型还是可信的。 - Disk failure: 简单说就是盘坏了。
今天这里不会介绍 HA 和 replica 相关的内容,因此,对于磁盘丢失数据我们略过不表。系统希望从崩溃的状态恢复的话,应该可以很粗糙的被分为两个阶段:
- 系统正常运行的时候需要做的事情,用于在出现故障的时候,恢复系统的状态
- 系统出现故障后,恢复系统的状态。
(系统的状态可以简单理解成 ACID 或者给用户提供的语义。)
存储模型
这个标题名称似乎有些让人困惑,但实际上,后续很多算法都需要依赖一个靠谱的存储层。对于单机 RDBMS 而言,它提供的语义可能类似 block. 并且,可以简单拆分成下面几项:
- volatile storage
- non-volatile storage
- stable storage
(1) 类似于我们的 memory system, (2) 可以视作简单的盘。(3) 提供了一种数据很难丢失、损坏的语义。通常来说,需要靠 RAID/备份等方式来实现 (3) 这样稳定的存储/块存储语义。同时,写盘也可能出现问题,在写入存储的时候,可能有下列的 case:
- sucessful completion
- total failure
- partial failure
(3) 实际上是很多问题的来源,为了解决这种 case,需要 CRC/double write 等不同方式。
下面这里抽象了一下写盘的语义。
Recover and Atomicity
- Force: 事务完成之后,修改的 page 是否强制要求刷盘
- Steal: 事务完成之前,能否把 Page 刷盘

不妨看看上面的图,实际上做了一个很清晰的定量分析。等等,这是不是说,没有 log 也行呢?
实际上 BoltDB(虽然只是个 kv) 就提供了这样的能力,它不需要写 wal。本身依靠 cow 来实现这些逻辑:
- 系统限制只有一个写事务
- 每次修改后,会在新的存储空间上做写入 Page
- commit 的时候,强制刷盘,并且更新 meta,保证下次读到对应的内容
实际上,它的 Recover 也简单,看一下 2个元数据块是否正常,两个都不正常就节哀了,一个不正常挑正常的,两个都正常挑事务 id 大的。
如果允许并发写的话,问题需要麻烦很多,早期的 sqlite 对这种模式提供了支持:
- 事务会把修改前的 Page 写到 Journal File 空间上
- 恢复的时候,会用 Journal File 上的 Page 来提供恢复
以上类似 cow 或者 shadow paging 的方式可以比较简单的实现一些事物的语义,同时,它们相对于 logging protocol 来说可能开销是更大的。它相当于 force + no steal:
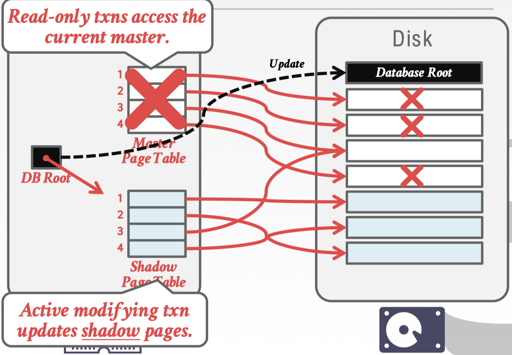
WAL Protocol
这里提供了物理日志和 wal 协议,这里,日志包含: < txn id, object id, Before Value (for undo), after value( for redo)>, 这里可以记作 <T_i, X_j, V_1, V_2> (我感觉这个是一个很简化的模型了,是不是还要处理 delete/insert 之类的). 同时,这里需要和事务有关的信息, 比如: <Txn i begin> <Txn i Commit> <Txn i Abort>。 log 需要被写到 stable storage 中。
另一点要说的就是对 block 的写入,我们回到 steal/force 的 case:
- 可能事务完成前就刷了写入过的盘,这个时候,假设事务 abort 了,显然,我们需要
undo这些变更 - 可能事务完成后,没有写入 block,这个时候,假设事务 commit 了,显然,我们需要 redo 这些变更
同时,需要考虑的还有 concurrency control 的语义:同一个 object, 被 txn1 写入之后,在 txn1 commit/abort 之前被 txn2 写入了应该怎么办呢?幸运的是,如果我们采用的是 strict 2PL 协议,这里并不会有这种情况。而 ts 协议大部分时候也避免了这种情况。当然,后面我们会提到,如果希望提前 release lock, 有什么方法能补救这个 case。

上述是一个对应的序列,那么,能够看到对应的 log:

假设在上述任何一个节点 system crash 了,我们都要走下面两个状态:
redo(T_i): 这个过程在从前往后扫 wal 的时候发生,对于任何一个 start 的记录,它会把日志中的操作 replay 一遍。undo(T_i): 这里不仅要undo对应的记录,也要写下对应的 undo 相关的恢复日志 (比如<T_i, record, before value>,完成的时候也需要写<T_i, abort>, 防止下次 recover 的时候,还需要恢复这样的状态。
所以,这里有个简单的 recover 协议:
- T_i 在有
start, 但是没有commit, 也没有abort的时候,需要被 undo - 在事务有对应
commit或者abort的时候需要 redo。abort的时候为什么要 redo 呢?因为我们刚看到,abort 的时候需要把恢复对应的日志写下来,再 abort。
Checkpoints (ckpt)
上面的内容暗示了日志的全量 scan, 实际上日志肯定要 GC 的,这里给出了一种方法:ckpt, 它暗示之前的 wal 都不重要了:
- 把所有留在内存中的日志写到 storage 上
- 把所有的 dirty block 写到 storage 上
- 写下
<checkpoint {active Txn1, active Txn2, ...}>日志,表示还活跃的 txn 有哪些。
这些活跃事务之前的 txn 都已经在 block 中了。那么,恢复的时候,只要找到最近的一条 ckpt 日志,然后开始恢复即可。
当然,这在性能上带来了一些问题:把所有 dirty block 写到 storage 上,再写 ckpt 日志的时候,事务如果再进行更新并写 log,就会导致 ckpt 之前会有一些不在 disk 上的 log, 导致 ckpt 并没有这么有用。这里可以用 fuzzy checkpoint 来尝试解决这个问题。
Recover Processing
上述几个部分主要描述的是“系统正常工作的时候,如果希望后来系统是可以 Recover 的,需要做什么
正常事务 abort 的回滚
如果 Ti 需要被 rollback, 那么它会反向 scan 日志,对于每一条 <Ti, Xj, V1, V2> 的日志。逻辑大概是:
- Xj 被还原到 V1
- 写下一条
<Ti, Xj, V1>的恢复日志。这条日志是不需要被 undo 的。这些日志被称为 compensation log records (CLRs). - 一旦
<Ti, start>的开始日志被反向 scan 找到,日志恢复结束,写一条<Ti abort>的日志。
System Crash 后的恢复
- redo 阶段中,先需要找到最近的一个 ckpt,然后 replay redo logs
- 同时,这里应该需要维护一个需要被补充 abort 的事务状态表 undo-list。ckpt 有一个活跃状态列表,同时,事务 start 的时候,会被加到这个列表里,有事务对应的 commit 和 abort 的日志时,可以从这个列表中排出。
- 这个时候有一个 undo-list, 对着这个 undo-list 反向 scan, 进行正常事务 abort 的回滚操作,直到 undo-list 为空,即找到 undo-list 中最早 start 的事务的 log (感觉这表示这之前的 log 都可以 GC 掉)
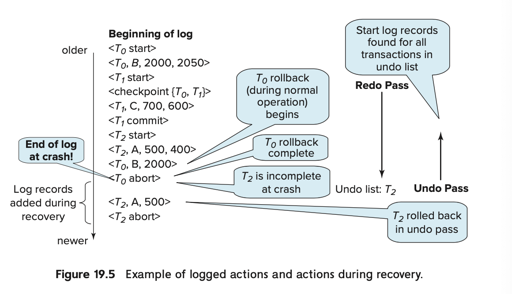
Buffer Pool & GroupCommit & WAL
下面是一些优化。写入的时候,可以写到 Buffer Pool 里面,然后把 Page Mark 成 dirty 的,按需求异步去写盘。某种意义上,这降低了写放大,但是也导致 BTree 有些逻辑比较难 tunning.
同时,wal 也可以 buffering, 但是这里需要注意的是,如果 wal 都做了 buffer, 需要有下面的约束:
- 当且仅当
<Ti, Commit>日志写进持久存储之后,Ti 才可被视作提交 <Ti, Commit>写进存储的时候,Ti相关的所有日志必须已经顺序落盘- Block 在写入的时候,需要保证,这个 Block/Page 有关的日志全部被 flush 了。
同时,显而易见,Commit 的时候,需要有落盘的开销。对于 SSD,这可能是 ~100us 的级别,对于 HDD,可能是 ~ms 的级别。这个时候,可以靠 Group Commit 来解决这个问题。这可能是增大单次写的 latency ,但是把写入的 IO 数量减少了,并均摊了写入的时间,优化了写入。
此外,事务可以 Batch 的来处理 insert/delete/update 请求,来作为优化。
Lock Release and Logical Undo
作为实现来说,对于 inc/dec 类的操作,简单做成: read + set,然后写物理日志是没问题的。但是,如果希望在这里增大并发的话,就会有一些奇怪的问题了。2PL 提到过,这里可能会有 cascading abort 的概念。
但是实际上,这里也可以用 logicial undo log records 来做一些优化。
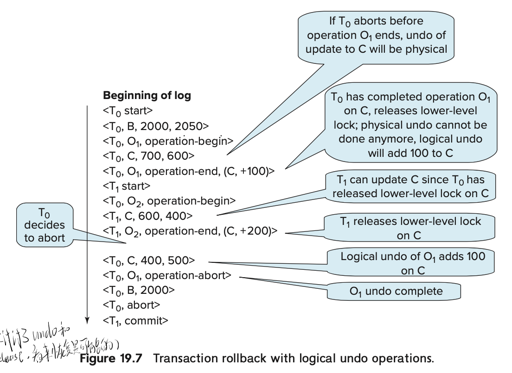
如上图,这里把 inc/dec 做到了 log 里,用逻辑日志来做对应的操作。
在日志修改索引之前,txn 会创建 <Ti, Oj, operation-begin> 的日志记录。Oj 是对象的标示。
这里写的时候,实际上也需要写物理日志,标志 prev 和 new value。写完之后,需要写一条逻辑日志,表示更新的操作。
这里,rollback 和 recover 的时候,可以遵照逻辑日志的语义:
- 不完整的(没有 operation-end 的逻辑日志)会被物理日志 resolve。
- 没有 operation-end 可能表示对这个 tuple/对象 的锁定还没有释放,默认这种行为是串行的
- 有 operation-end 的逻辑日志会用逻辑日志的信息回滚,并生成一个 operation-abort 的日志
- 跳过这个事务的日志,直到找到对应的 operation-begin
- 如果往前扫的途中,找到了一个 operation-abort, 那么他会跳过这个 Ti 对这个 object 所有的操作
- 直到结束
ARIES
我们之前的描述中,recover 会 scan ckpt 以来所有的日志,然后给 block/page 来 replay 这些 redo 日志,再反向去 undo. 这些流程实际上可能还会把内存中所有 page 变成 dirty 的,同时,也带来了很低的效率。同时,ckpt 的过程相对来说也是低效的。
ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging 提出了 ARIES, 它相对来说提供了很快的 Recover,允许上层使用细粒度的锁等方式。
下面,假定这里用 Strict 2PL 的模式进行并发控制,并使用 steal + no-force 的方式控制并发。
下面是一些概念:
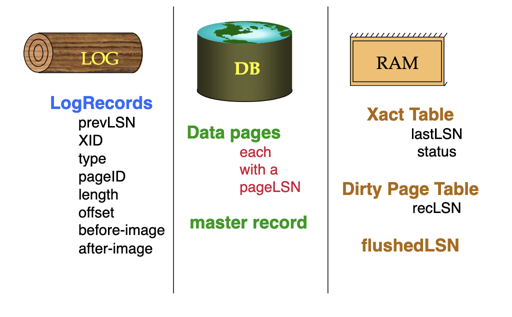
- LSN(log sequence number): 每个日志带有的序列号
然后系统很多地方都会带有这个 LSN:
| name | where | definition |
|---|---|---|
| flushedLSN | Memory | 磁盘上的日志中,最大的 log id (即 flush 过的最大日志的 id) |
| pageLSN | per page (memory) | 对这个 Page 最近的写入的 log id, 在内存中 |
| recLSN | per page (memory / disk) | 这个 Page 上次 flush 的时候,最大的 log id, 在内存和盘上都有 |
| lastLSN | per transaction | 事务最后写入的 LSN |
| MasterRecord | disk | 上个 ckpt 的 LSN |
然后同理,根据之前的 wal 协议,我们要保证:任何时候,任何 pageLSN 小于 flushedLSN。
Commit
- 写 Commit 日志
- 等待 Commit 和之前的所有日志被 flush 到盘上,并更新 flushedLSN. 内存中小于 flushedLSN 的记录可以被清除。
- 写一条
TXN-END记录, 不要求立刻 flush
Abort
相对于我们之前的物理日志,这里要加上一些额外的字段:
prevLSN同一个事务的上一条 LSN,这可以把一个事务的日志穿成一个单向链表
abort 的时候,这里也要写 CLR,相对我们之前记录的 CLR,这里也增加了内容:
undoNext指针,就是 undo 一条 CLR 只有,根据prevLSN的记录,找到的下一条要恢复的 redo 日志
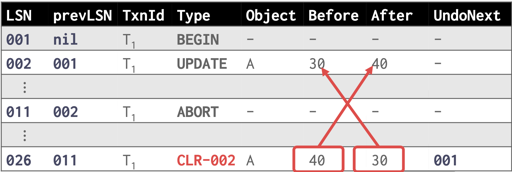
相对来说,这些记录能在 crash 的时候,提高恢复的速度。
crash 的时候,这里会:
- 写一套 abort 的记录
- 写对应的 CLR, 然后沿着版本链 undo
- 写
TXN-END
Fuzzy Checkpoint
checkpoint 需要把所有的 dirty page 刷到存储中,这段时间都要 stop-all-txns, 然后要 flush the buffer。fuzzy checkpoint 可以提供一个模糊的 ckpt,这里需要记录事务和 Page 相关的内部状态,所以需要两个 Table:
- Active Transaction Table (ATT)
- txnId: txn id
- status: 现在事务的状态,分为
Running,Committing,Candidate for undo lastLSN: 事务上一次修改的LSN
- Dirty Page Table (DPT)
- 记录了 page 和
recLSN
- 记录了 page 和
这里相对来说,就不用 flush all, 而是说记录了哪些 Page 是 dirty 的。
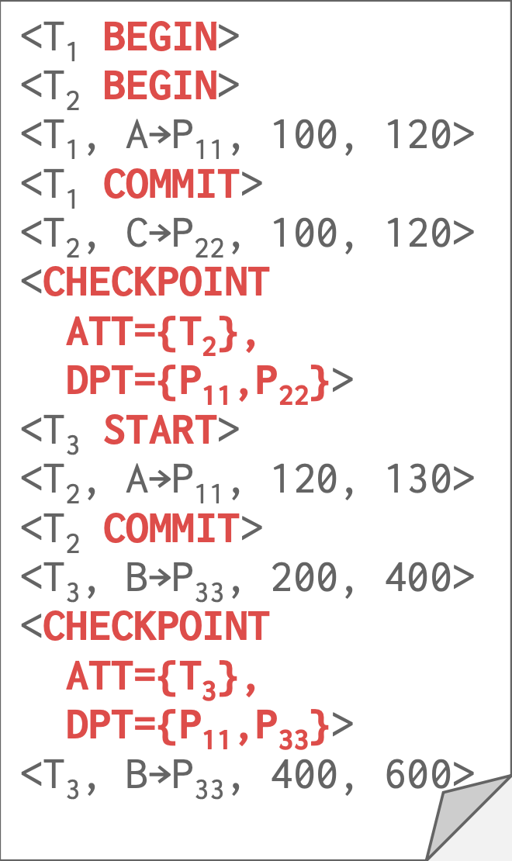
这里 flush 的时候,知道 Page 是 dirty 的。可能需要前面一些的日志,来恢复这些 Txn, 当然这里 att 也能拿到 lastLSN, 来比较快的定位。
当然,这里也要求,写一条 CHECKPOINT 日志的时候,这中间把这条日志刷下去之前,还需要上锁和短暂的 stop,这里是想保证写入 CHECKPOINT 的时候,之前不会出现别的变更日志,让 ATT 和 DPT 的这里还有一种优化,让这个日志写两条:
CHECKPOINT-BEGIN: 逻辑上的 ckpt 实践CHECKPOINT-END: 包含 ATT + DPT
这实际上就是把日志拆成了两条,然后延缓了这个状态。虽然这里也要有小小的 stall。
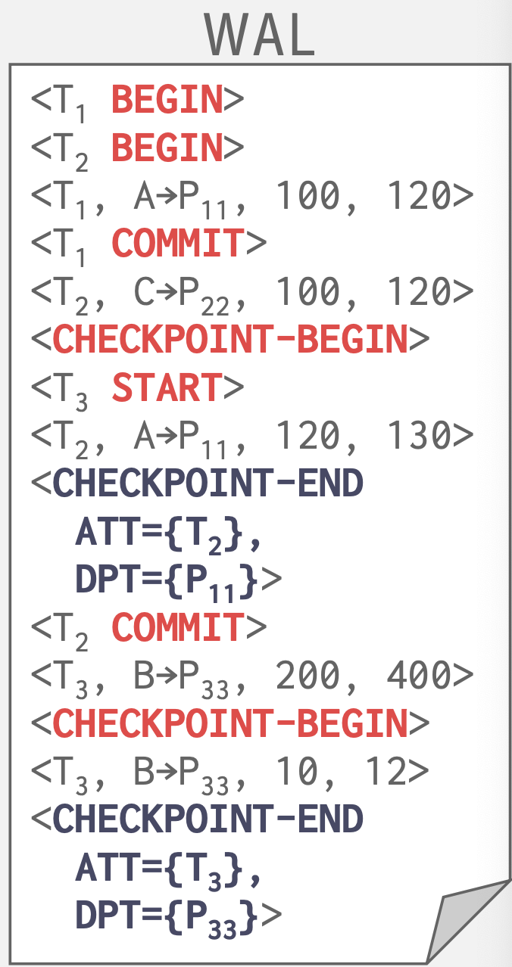
同时,当 checkpoint 写入完成的时候 checkpoint-begin 需要更新到 MasterRecord。这里相当于,checkpoint-begin 到 checkpoint-end 之间的事务,不会纪录到 ATT 中。
Big Picture
在进入 Recover 之前,让我们对这些结构都有一个全局印象吧:
Recover
这里 recover 分为三个阶段(还记得之前的 redo/undo 吗):
- analysis
- redo
- undo
analysis 阶段中:
- 先找到 MasterRecord, 这里对应了一个存储里最新的
BEGIN-CHECKPOINT. - 构建 ATT 和 DPT,这里
CHECKPOINT-END可以帮助构建 ATT,别的状态刚进来是 UNDO - ATT 而言,对于剩下的日志:
- 如果来了一个事务,把它状态设置成UNDO
- 如果事务提交了,设置成 COMMIT
- 如果找到了
TXN-END, 也要从 ATT 中移除。
- DPT 而言,对于剩下的写入:
- 如果 Page 不再 DPT 中,把 P 增加到 DPT 中,然后初始化它的
recLSN
- 如果 Page 不再 DPT 中,把 P 增加到 DPT 中,然后初始化它的
在 analysis 阶段中,构建了完整的 ATT/DPT.
在 DPT 中,这里记录了 Page 的 recLSN, 这里找到最小的 recLSN, 然后开始对对应的 Page 来 replay:
- 如果 Page 不在 DPT 中,跳过这条日志
- 如果 Page 的 LSN 不小于日志 LSN,跳过
- 否则,apply log, 并且设置内存中的
pageLSN - redo 完之后,给对应的事务写上 TXN-END 记录,并且从 ATT 中移除
UNDO 阶段中,这里可以用 lastLSN 来加速查找,并且写入 CLR
ARIES 这边支持的 redo 是 Physiological REDO logging + Logical UNDO,用来提供相关的性能支持。Physiological REDO 可以进行,因为本身通过 Page 来定位,用 LSN 来让操作是幂等的。