事务: 并发控制协议: 2PL && TS
并发控制是事务的重要成分,他们会决定事务的调度、处理、abort 顺序。
事务的并发控制可以大致分为:
- 乐观的并发控制
- OCC
- TS
- 悲观的并发控制
- 2PL
乐观的并发控制假设冲突比较少的情况发生,出现冲突就会选择事务 abort;悲观的并发控制则是假设事务冲突经常发生,会避免冲突。
2PL
首先 2PL 的 Lock 和“读写锁” “自旋锁”这些同步操作不是一回事,后者在 DB 层被称为 Latch。
基础的锁可以简单分为:
- S-LOCK:Shared Lock,读获取 S-Lock
- X-Lock: Exclusive Lock,写获取 X-Lock
2PL 分为两个阶段:
- Growing:仅获取锁或者拒绝获取锁的请求
- Shrinking:只允许释放锁
正确性证明
数据库系统概念对这个有一个很棒的证明,用的是归纳法:http://www.mathcs.emory.edu/~cheung/Courses/554/Syllabus/7-serializability/2PL.html
(大意是 1个事务中,已经是串行的。然后 n 个事务中,假设 n-1 个事务是串行的,满足 2PL 条件下,无法找到一种调度,让他满足非串行化调度)
https://zhuanlan.zhihu.com/p/59535337 这篇文章也给了一个反证法来证明。大意也如上,不过用了成环的角度来描述。
此外,关于 2PL 的 order, 还有一个很有趣的概念:2PL 可以当成提出第一个解锁请求的时候,瞬时执行的。这个在下面有一个反证法证明(在 claim 那):http://www.mathcs.emory.edu/~cheung/Courses/554/Syllabus/7-serializability/2PL.html
2PL 的麻烦
CASCADING ABORTS
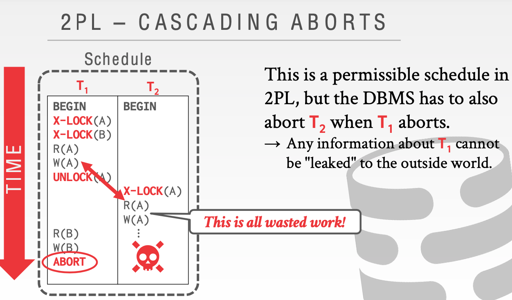
上述调度发生的时候,T1 unlock 了,T2 获取锁读 T1,然后 T1 abort 了,为了防止 G1a,T2 也应该 abort。
那么这个时候,依赖 T2 写入的也都会 abort ,哈,雪崩!
为了防止这种现象,会有 strict 2PL:
A schedule is strict if a value written by a txn is not read or overwritten by other txns until that txn finishes.
在 S2PL 下,不仅能防止上述 cascading abort, 还能靠存储原来的值来恢复 abort。
此外,还有另一种模式:
Another variant of two-phase locking is the rigorous two-phase locking protocol, which requires that all locks be held until the transaction commits. We can easily verify that, with rigorous two-phase locking, transactions can be serialized in the order in which they commit.
Upgrade Lock
如果 txn 先读 object a, 再写 object a。那么它需要进行 upgrade, 把 S-LOCK 变成 X-LOCK。
升级只能在 growing phase 中进行。
Deadlock
在实现上,通常2PL会引入 LockTable 来记录锁的信息。同时向 LockTable 申请锁定。所以与 OS 不一样,数据库可以高度介入这些行为。
有两种处理死锁的方案:deadlock detection 和 deadlock prevention。
Deadlock Prevention
deadlock prevention 可以用某种方式,比如开始的时间,来控制优先级。有了优先级,当事务申请 Lock,同时这个 object 上已经有 lock 的时候,有两种策略:wait-die 和 wound-wait,这些策略本身暗示了一个事务序号或者时间戳的存在:
- wait-die: 如果请求的事务有更高的优先级,那么等待,否则会 abort
- wound-wait: 如果请求的事务有更高的优先级,那么 abort 掉持锁的事务,否则会等待事务完成。
这两种方式让事务抢占锁的时候,有了一个单调的 total order。所以本身是 work 的。同时,为了避免冲突,被 abort 的事务会要求一定程度上用原有的优先级。
还有一种混合的策略是锁超时,一定时间事务没有推进下去之后,会被判定为超时。
Deadlock Detection
deadlock detection 通常采取 wait-for graph 的形式来实现,它构建一个 DAG,然后在申请锁的时候,构建 Transaction 的 direct 依赖。unlock 的时候,释放相关的依赖。当 wait-for graph 出现环的时候,说明有冲突. 需要挑选一个 victim 事务 abort 掉。
当然,这个 wait-for graph 也可以在定时或者其他的时机构建,比如在定期检查的时候构建。
Abort 事务本身也是有讲究的,这里可能会在 wait-for graph 里面成环,我们需要 abort 掉环中的一个事务。
- 事务执行了多久,还需要执行多久
- 回滚时牵涉的事务
- 这个事务是否重复了很多遍,再 abort 就饿死了。
LockTable
综上,上述的内容需要一个 LockTable 来实现。这里采取了一个 HashTable + Chain 的结构:
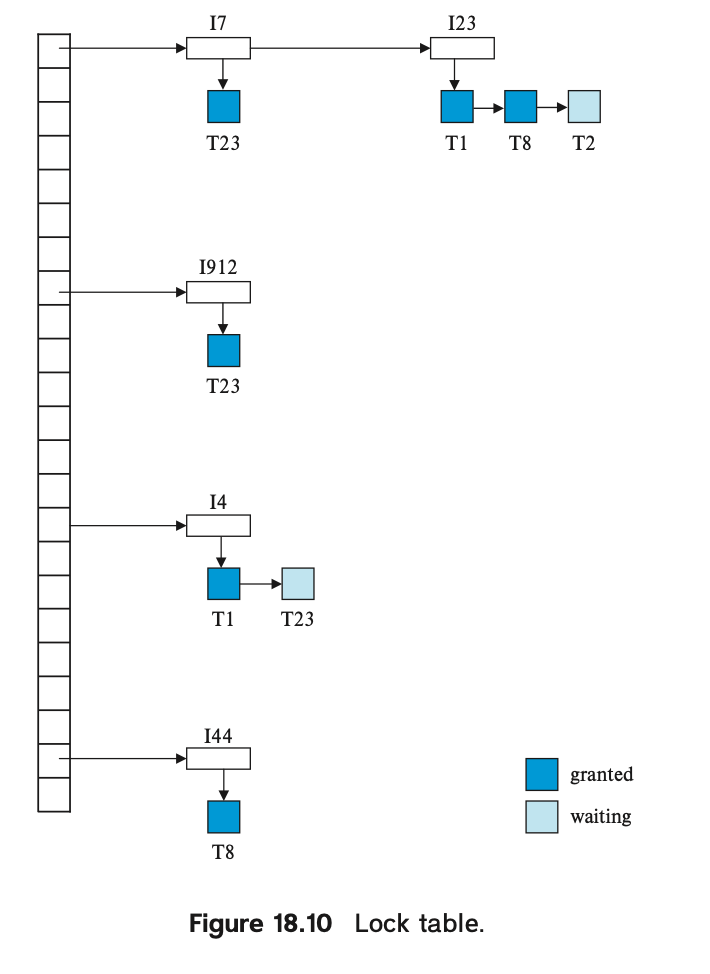
- 当有 LOCK 请求时,请求排队处理;共享的请求可能被同时 grant
- 有 unlock 请求时,释放元素,并且处理下一个
- 有 abort 请求时,clear,并进行恢复工作。
Multiple Granularity && intention locks
关系型数据库有不同的层次:
- Database
- table
- Page
- Tuple/Row
- Column
当 Txn 申请 Lock 的时候,DBMS 会面临分配的层次问题:
- 层次低的话,分配更多低层次锁,允许更高的并行度,但是 LockTable 会面临更大的时空开销(主要是内存/CPU)。
- 分配高层次锁,可能的并行度会降低,但是 LockTable 面临的时空开销减小。
同时,实现者在 LockTable 维护 Lock 的时候,会发现,协调不同层次的锁是困难的,而且从 Root 开始锁定开销过大,因此有了 intention locks.
- IS: Intention-Shared,希望更细粒度的获得 shared lock
- IX: Intention-Exclusive: 希望获得更细粒度的 exclusive lock
- SIX: S + IX
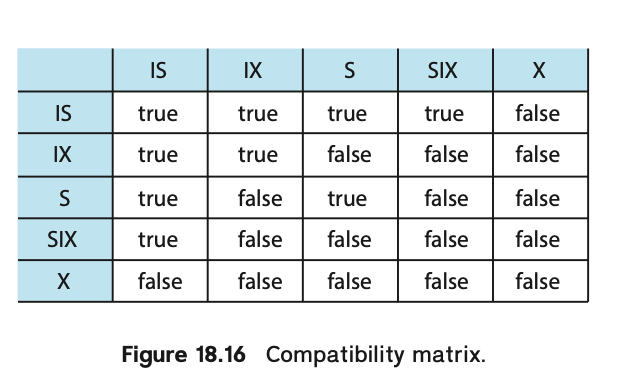
这个应该横坐标是 holding lock, 纵着的是过来的请求。事务给下层上 S/X 锁,父节点必须有对应的锁或者意向锁。
发现行锁过多可能会进行锁的升级(escalation) ,来更新父级别的锁. 不过 InnoDB 没有,因为它自称自己上锁很便宜(虽然被何登成老师吐槽过 orz):https://dev.mysql.com/doc/refman/5.6/en/innodb-transaction-model.html
Predicate
S2PL 很大程度上能防止 G0 G1 G2-Item 了,但是无法保证 G2 不发生,所以需要处理 predicate。这里可以:
- 整个 Lock 住信息:添加一个 information object, 读会对他上 S-LOCK,写会 X-LOCK,导致产生冲突。这种方式的缺点是并行能力太差,需要把整个对应的 index 锁住。
- 采用 index-locking:读/写之前对对应 B+tree index 的 leaf node 锁定,更新的时候锁定 index 的
(old)(new) - predicate-locking: 对 Predicate 上锁,比较复杂、性能低下而一般不采用。
MySQL 采用了 next-key locking 的实现,来解决 predicate 和 phantom 的问题。为什么是 Next-Key Locking? 这个策略貌似是上世纪 ARIES/KVL 搞出来的,将谓词锁转化为记录的锁,这种方式相对来说直观又节省空间。
插入和删除
插入本身需要注意锁相关的信息。比方说插入的时候本身要对记录上锁,删除的时候也要注意上锁。MySQL 会有插入意向锁,具体可见隐式锁相关的描述:http://mysql.taobao.org/monthly/2020/09/06/ 。
杂项
更低级的一致性,比如二级一致性(degree-two consistency)可以靠提前释放读锁之类的方式来实现. 有一种方式被称为游标一致性,这里会在 cursor 读期间上读锁,读完之后释放。
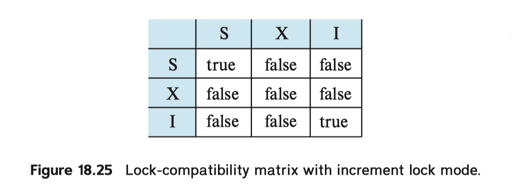
increment lock 是一种特殊的锁。为了保证在某些 inc/dec 操作上的高效而使用:
TS
对于 2PL 而言,如果要定序,事务本身会在第一个 lock 释放的时候作为 commit 时间。2PL 本身有这个依赖,其实就简单实现一下是不需要 commit_ts start_ts 的。
Basic-TS 协议则不然,它会在事务开始的时候,给事务一个 TS,对于事务 T,记作 TS(T),而 ts 是尽量单调递增的(可以是系统时间或者是一个 counter),某种意义上,这给了所有事务一个 total order。
那么,我们在事务开始的时候就获得了“如果 commit 应该有的 ts”, 所以,实现上会需要每个 object 的读/写 时间,来完成相关的验证,一旦发现违背了隔离级别的需求,就要进行一定的恢复处理:
To implement this scheme, we associate with each data item Q two timestamp values:
- W-timestamp(Q) denotes the largest timestamp of any transaction that executed write(Q) successfully.
- R-timestamp(Q) denotes the largest timestamp of any transaction that executed read(Q) successfully.
然后,有一些对应的读写规则:

上面比较复杂,不过简单说大概思路就是:
- 欲写
X,不可以写TS(T) < W-TS(X)的数据,不能被定序的后来写入的事务写了。 - 欲写
X,不可以写TS(T) < R-TS(X)的数据,不能被定序的后来写入的事务读了。 - 欲读 , 不能读到定序的事务之后的写入。
我们下面来考虑 Recoverable 和 Cascadeless:
TS 协议本身不是 recoverable 的,需要一定的更改,有下面这些参考方案:
- Recoverability and cascadelessness can be ensured by performing all writes together at the end of the transaction. The writes must be atomic in the following sense: While the writes are in progress, no transaction is permitted to access any of the data items that have been written.
- Recoverability and cascadelessness can also be guaranteed by using a limited form of locking, whereby reads of uncommitted items are postponed until the transaction that updated the item commits.
- Recoverability alone can be ensured by tracking uncommitted writes and allowing a transaction T**i to commit only after the commit of any transaction that wrote a value that T**i read. Commit dependencies, outlined in Section 18.1.5, can be used for this purpose.
TS 不会产生死锁,因为有冲突都 abort 了。但是 Basic-TS 有一些 performance 上的问题:
- 本身不是 recoverable 的,需要一定的更改。
- 更新 timestamp 开销比较大。
- 长时间运行的事务碰见冲突概率比较大,可能会饿死。
关于 ts 协议有一些批评,就是即使读也要更新相关的数据,造成额外的写开销。
Thomas-Write Rule
回顾一下规则:欲写 X,不可以写 TS(T) < R-TS(X) 的数据,不能被定序的后来写入的事务读了。
Thomas-Write Rule 允许你跳过这个规则,因为你可以视作“写入被后来的覆盖了”。
OCC: 基于检查的方法
对于一个事务而言,如果大部分事务是只读事务,冲突较少,那么应该减轻各种处理的开销。OCC 大致分为三个阶段:
- Read Phase: 读对象,把对象 copy 到事务内写
- Validation Phase: txn commit 的时候, 检查事务是否和别的事务产生冲突
- Write Phase: 把记录写入
我们引入几个时间点(不一定要分配时间戳)来帮助理解这个流程:
StartTs(T): 事务开始执行的时间ValidationTS(T): 完成 Read Phase, 开始进入StartTs的时间戳FinishTs(T): 完成写阶段的时间戳
这里可以尝试在 Validation Phase 中分配时间戳,然后 trace 读写的对应时间戳:
- 两个事务没有冲突,且
TS(Tk) < TS(Ti), 当且仅当:FinishTS(Tk) < StarTs(Ti). 这点是显而易见的ValidationTS(Ti) > FinishTS(Tk)且WriteSet(Tk)和ReadSet(Ti)没有相交
这个方法是 Cascadeless 的,因为 Write 阶段之后才能读到正确数据。
CMU 15-445 描述了一个 validation 的基本策略,他的大致逻辑如下:
- 检查与 StartTS 至 ValidationTS 间的提交事务有无冲突,即验证是否读取了 FinishTS 事务的写集合
- 发现进入 ValidationTS 的事务中,更旧的事务的时候,进行下列验证:
- 验证阶段的时候(准确说是开始写的时候),对方已完成写。那新事务的读集和旧事务写集不冲突即可。
- 验证阶段的时候,对方没完成写,那要求旧事务的写集不和新事务的读写集冲突。
进入 ValidationTS 的时候,TS 是递增的。如果用 StartTS 作事务的时间戳,本身协议上是满足序列化的,但是问题在于验证的时间戳可能不是递增的,这个情况下可能出现:
- 两个事务差不多时候开始,
TS(i) < TS(j) j比i更早进入验证阶段
这个时候肯定就有问题了,所以倾向于在 Validation 阶段分配。
性能评估
这里不考虑 MVCC 的部分,对他们的性能进行评估. <Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores> 给了一个评估,但我不是很信任它的结果,感觉作者对 scalable counter 没啥经验。
Reference
2PL 部分:
- InnoDB 的 Locking https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
- InnoDB存储引擎(第2版) https://book.douban.com/subject/24708143/
- CMU 15-445
- 数据库系统概念(第七版)
TS 部分:
- CMU 15-445
- 数据库系统概念(第七版)
OCC 部分:
- CMU 15-445
- Microsoft Hekaton
- 数据库系统概念(第七版)