Hash joins and hash teams in Microsoft SQL Server
本论文发表于 VLDB’98 ,很多部分的知识到今天还是有一定指导意义的。算是教科书的 SQL Join 实现的细节版,同时也有一些比较细的 Join 上的思考
The implemented techniques include hybrid hashing, dynamic destaging, large units of I/O, partition tuning (also called bucket tuning), recursive overflow resolution with three operator phases (input, intermediate, and output phases similar to input, intermediate, and output phases in sorting), dynamic role reversal between build and probe inputs, histogram-guided skew resolution, “bail-out” using alternative algorithms if inputs contain excessive numbers of duplicates, multi-disk concurrent read-ahead and writebehind, cache line alignment of in-memory data structures, bit vector filtering, and integration into an extensible execution paradigm based on iterator objects.
All these techniques are either fully implemented or designed and prototyped. In addition, this is the first implementation of Nary “teams” of hash joins, which realize in hash-based query processing most of the benefits of interesting orderings in sort-based query processing.
可以看到,这里还是一份很细的实现提到了 Hybrid Hash (即引入 Disk)——和怎么动态的根据内存限额,从内存卸载到盘上,同时描述了实现的时候的 io-size 这一细节;此外,这里也描述了怎么调整 hash join 的 hash partition 大小 tuning,也描述了处理过大 partition 的机制——递归 hash join 或者 bail out (对极端的 case,转换成更慢-更稳的 join)。这里也提到了内存协调的问题,对于你有大量的 memory-intensive operator 的( Agg, Sort, Join),这里还需要协调内存。
To the best of our knowledge, there is no known general solution for this problem that considers random arrival and completion of queries, bushy plans shapes, execution phases of complex query plans with multiple “stop and go” operators such as sort and hash join, and, maybe the most difficult yet most frequently ignored issue, the notorious inaccuracy in estimating the sizes of intermediate results.
论文中协调内存的方式比较简单,但本质原因还是这块内存不是很好估计,如果动态允许查询进入,然后运行的时候来协调这些内存的话,论文认为这里结果还是会比较复杂的,所以在后面篇幅里面说才用了静态内存限额的方案,同时也介绍了别的内存配置方案。
本篇论文提到它有一个创新点是 “Hash Team” 的概念,就是针对多个 Hash Operator 组成 Team,来像 Sort 一样,利用同样或者相似的 Hash Key 来处理。这里不仅是 Operator 和别的 Operator 在逻辑上用 Hash 来处理,同时也抽出了 Operator 数据的调度和 Spill 之类的处理。Hash Team 这个词在现代感觉几乎没听过,但我觉得和 Grouped Execution [1] 应该是个相对相似的概念。
The benefits of hash join and hash grouping
这一节首先讨论了 hash join / hash grouping 的优势,即在 unsorted, non-indexed 输入上处理。
The truth is that there is no one overall winner, and each of these algorithms is superior to its alternatives in certain circumstances.
客套话:没有 winner。
Since hash-based algorithms process large, unsorted, non-indexed inputs efficiently, they are particularly useful for intermediate results in complex queries, for two reasons.
- First, intermediate results are not indexed (unless explicitly saved to disk and then indexed) and often are not produced suitably sorted for the next operation in the query plan.
- Second, since query optimizers only estimate intermediate result sizes, and since estimates can be wrong by more than an order of magnitude in complex queries, algorithms to process intermediate results must not only be efficient but also degrade gracefully if an intermediate result turns out to be much larger than anticipated.
(其实 2 本质上可以和 aqe 一起想,本质上在 shuffle 后再 plan join 的话,相当于「统计信息是非常准确的」)。
这里还有一些 Index 有关的操作,我理解是 non-cluster index 上的 tuple 之类的用 Hash?
Once an efficient join algorithm is available that requires neither sorted nor indexed inputs, some of the query plans traditionally associated with bitmap indexes can be exploited, such as index intersection, difference and union.
作者又讨论了一下 de-normalization。这个模式经常被吹牛的用在 nosql 数据库上,作者的讨论还是有意思的,他觉得 denormalization 在 disk-space 和 index 的层次上,也应该被称为一种 master-detail clustering;但是这个在上层建模层无疑是一种冗余。但是更高效的 Join 也让一部分 de-normalize 的需求没了——你不拆分我就跑的够快了。
An overview of hash join techniques and terminology
本质上 hash join 能处理不少类型的 operator,从 join 到 uniq,此外,一些关系数据库还有合并多个 index 结果的方式,比如 MySQL 的 Index Merge [2][3] 和 PostgreSQL 的查询,这里可能会算一个 Merge Union。
- inner join; left, right, and full outer join; left and right semi-join: intersection; union; and difference. In set operations such as intersection, as well as in duplicate removal, the hash key consists of all columns.
- duplicate removal and grouping: (like “sum (salary) group by department”). These modest modifications boil down to using the one and only input for both the build and probe roles. (有的数据库分成了 Hash Aggregate 和 Streaming Aggregate)In grouping operations, the columns of the “group by” list play the role of the hash key.
- Additional predicates are possible, and are evaluated as “residual predicate” separately from the comparison of hash values. Note that the hash key can be an expression, as long as it can be computed exclusively from column in a single row.
这里也分成了几种对应的情况:
- In-memory hash join: The simplest case is defined by a build input that is smaller than the memory allocated to the hash join operation. —> 最简单的流程,和你想的一样,先 build hash table,然后 probe 阶段产生 matches 数据。可以不切 Partition
- Grace hash join: If the build input does not fit in memory, a hash join proceeds in several steps. Each step has two phases, build phase and probe phase. -> 切 Partition,然后处理这些文件,来对这些 Partition 进行 In-Memory Hash Join
- In the initial step, the entire build and probe inputs are consumed and partitioned (using a hash function on the hash keys) into multiple files. In other words, the two inputs are partitioned into “fan-out”many pairs of files.
- Recursive hash join: Grace Hash Join 切分后仍然放不下,可能要递归的切分,或者专门处理一些大的分区。能在内存中处理的分区按照 (2) 来处理,否则递归的再次切出更小的 Partition,然后处理这些 Partition。
- In the worst case, multiple partitioning steps and multiple partitioning levels are required. Note that this is required only for very large inputs, i.e., inputs for which a standard external merge sort would require multiple merge levels. Also, if only some of the partitions are very large, additional partitioning steps are used only for those.
- In order to make all partitioning steps as fast as possible, large, asynchronous I/O operations should be used, such that a single thread can keep multiple disk drives busy with useful work.
- Hybrid Hash Join: 如果内存只比内存大一点,那么可以混合 Grace Hash Join 和 In-Memory Hash Join,在内存中处理一些 bucket,另一些 bucket 在盘上处理。我理解 Velox 之类的现代库实现都是按照这个思路来的。
论文中的实现大概是:
- 从 in-memory hash join 开始实现
- 能够 “dynamic destaging”,自动降级到别的实现。
- 如果实现的任何阶段产生了 bucket spill, 这里实现都会包含一个内存 bit vector filter(感觉类似 bloom filter?),来表示 hash 的存在性,probe 的时候先 probe bloom filter 再查 hash ( todo: 我其实不知道这样开销什么样,相当于用内存来换哈希?)
- 这里甚至还有一定的 AQE 类似的实现:如果估计错了 build 和 probe side,对于错估的 spill partition,这里可以倒置 build 和 probe side. 在处理 spilled partition 之前,可以用更小的一侧作为 build input,这种技术被称为 “role reversal”
Hash join implementation
毕竟是十年前的论文了,快点跳过吧。这里基础部分感觉思路在今天来看一般般,没有特别优秀。
Data Structure
这里是一个 bucket + linked listed 的形式,64B 连续的分配内存。这块其实新系统可以参考 Google SwissTable 的实现 [4]。
- The hash table is a large array, say 1,000 or 50,000 slots, depending on the size of the available memory.
- Each slot anchors a linked list, which we call a hash bucket.
- Each element in a linked list contains a full four-byte hash value and a pointer to a record pinned in the buffer.
- Multiple elements in a bucket are allocated together, in units of 64 bytes, to optimize the faulting behavior in CPU caches by reducing the number of next pointers in the linked lists.
下面还有一些关于 bucket / partition 状态的实现:
- bucket 被分到某个 Partition 下,Partition 可以有对应的 spill file. 如果是 build / probe 这样多路输入,假设 partition = 10,那么实际上最多可以 build 侧10个 spill,probe 侧 10 个 spill。
- 如果 partition 存在内存中 (resident),所有 build 侧内容都 pin 在内存的 buffer 中,可以通过 hash bucket 访问
- 如果 partition spill 了,hash table 没法访问对应的数据,hash table 的 buffer 会被当成前文中的 bit vector filters (我理解是 bf )
- Knowledge and control over which partitions are currently spilled is delegated to a separate object, in order to facilitate “teams” of multiple hash operations for N-ary operations, as described later. 这里大概是说,Partition Spill 和对应的状态由外部控制,方便处理 hash teams
逻辑上,Hash Join 有几个 Partition Set:
- 正在 Building 的 Partition,可能是 Spill 的或者 Resident 的
- 构建完成的,可以处理的
- 过大需要 Recursive 处理的。实际上绝大部分查询这个 set 都是空集
此外,这里还有一些控制信息,比如自描述( Join 类型等)
Basic Algorithm
这里的核心逻辑也是说,可以避免在 partition 处理中引入递归,而是在 steps 里面先开始处理没有 spill 的(最开始消费最外层的 operator input),处理他们的各个 partition。Spill 掉的可能会放入后续的 partition step,然后再沿着后续的 Partition Step 继续处理。
这里有几个循环:
1 | for partitionStep in partitionSteps: |
- partitioning step
- 可以用来描述 Partitioned input operator 或者一个 overflow resolution step,来切分原来前面 step 产生的分区到更细的分区。这里形式上也可以是内存中的、spilled 的之类的各种状态
- Partition Step 根据可用内存大小来决定 partition fan-out , 处理 build / probe 。如果没有发生任何 io,partitionStep 会被丢弃,然后处理另一个,否则这里弧线了 overflow partition
- 这里能够处理一组或者多组输入 Operator
- Input:
- 允许打开一组 spilled file, 决定输入的
(hash value, hash bucket, partition) - 特别的,这里描述了 probe 阶段的时候,数据存在 spilled 的地方的处理: If the input record’s partition is not resident but spilled, the bit vector filter may be set or tested, the record may be appended to the partition file, or an output record may be delivered (in outer joins, based on the bit vector filter).
- 允许打开一组 spilled file, 决定输入的
Hybrid Hashing and dynamic destaging
- 在最初状态下,所有 Buffer ( 因为没啥数据)都是 available 的,所有 Partition 都是 Resident 的,这里(强制)要求 Partition Size > Available Buffer Size
- 在 Spilled 的状态下,最多只持有一个 Output Buffer,用于写 Spilled File
- Resident Partition 申请 Buffer 的时候,如果申请不到合适的 Buffer,就会需要 Spill 最大的 Resident Partition
- 最大的 Partition 要求至少有两个 Page (见前面的约束)。这里要么可以 Spill 最大的 Partition,要么 Spill 自己,都能回收出大于一的 Page
- Spill 最大的 Partition 有一个好处,在不知道 Probe Input 是否有 Skew 的情况下,Spill 最大的 Partition 本身也比较适合做 io (Velox 之类的有提到过 Spill 数个 Partition 的操作 [5],我理解这个选 Partition 也是类似一个背包问题的)
关于 Partition Fanout 的设置,这里的 idea 是:因为之前说的很难预估 size 和数据分布的原因,Partition Fanout 本身比较难预测,这里涉及一些问题
- Write-Behind Buffer (我理解类似 Buffer Pool Dirty Page)和 Read Ahead Buffer (我理解是预读 Buffer)
- 小的 partition fanout 对 skew 之类的场景不友好,并且如果分太小,会产生过多的 spill 和下一层的 scaning;大的 fanout 这里也会浪费 buffer
- 最终:初始分区步骤的分区扇出通常设置为可用内存的 50%-80%,根据 Build 预估大小和对大小估计的可信度来调整这个 Ratio。同时,对于 N-ary operation (或者不知道有没有上层带上 Histogram 分配信息的),这里也会采用 Partition Tuning 机制,在最初的 Build phase 完成后,会收集一些 Partition 的 Historgram 信息,来指导更下层的 Partition 分配
这里还介绍了一些 io size 的信息,论文采用 64KB 作为size 来 gather/scatter io,这块我其实不是特别熟悉:
In general, the goal is to maximize the product of sustained bandwidth and the logarithm of the fan-out, because we believe that a merge step in external merge sort and partitioning in hash-based algorithms are very closely related, and because this goal maximizes the number of comparisons per unit time in a merge step.
Partition Tuning
对 Join 之类的 Binary 或者 N-ary 操作,在 build phase 需要 Partition Tuning(想想 AQE):
- 如果有多个 Spilled Partition 相对可用内存来说比较小,他们可以被并行处理,同时,可以在 probe 测合并到同一个 Spill Partition(这里处理的逻辑类似 Velox [5] 或者 Grace Hash Join,Probe 的时候也去写 Probe Spill File),来减少读写的 spill io 量和 buffer 量。
- 这里实现逻辑也是类似一个背包问题?论文贴一下原文:
In our implementation, we employ a simple first-fit heuristic bin packing algorithm on the spilled build overflow files, and restore the build overflow file of as many partitions as possible into memory, restoring the smallest build overflow file first.
Recursive overflow solution, three phases, and iteration methods
Multi-level partition 就是做着做着 partition 变多了。我们回顾一下之前流程:
- 如果没有 Spill,来自输入的各个分区会被类似 In-Memory Hash Join 或者 Agg 一样,直接 InMemory 的处理完所有的内容。
- 否则的话,处理完所有 in-memory 的之后,需要再次「递归」处理 spill 的内容,可以有前面的 Partition tuning 之类的调整
类似 Merge Sort 也有这样的步骤。注意这个地方虽然逻辑是递归,但是写法最好还是写成 partitionStep 有关的循环或者是状态机。
对于spill的对象,这里会尝试做 memory squared: 识别这个 partition 是否能被内存处理完成。然后在这个阶段中,一些特别大的 partition 可以尝试用尽可能多的预留内存来处理查询,同时也避免过大的并发和内存争用。
Role reversal
类似 AQE 文章[6] 提到的。对于 spilled 分区,如果查询允许,那么 build 和 probe 侧可以允许 reorder,来减少内存占用,提升局部性和性能。这是因为和 sort 不太一样,hash 能利用到更多的大小分区带来的优势。即使两边数据大小相似,可能 probe 测也能提供一些更有效的 bloom filter (我没太看懂这块,猜测是 probe spill 的时候,可以用 build side 的 bloom filter 来继续裁剪 rows,带来更小的 hash table)。
Bail-out
在 skew 非常重的场景下,比如 key 不 unique 然后有很严重的 skew,这里可能会分区递归好几层都算不出来。这里会 fall-back 到别的 Join ( Merge-Sort Join 或者 Nested Loop Join),来更稳的跑出结果。这种行为被称为 bail-out。Spark 之前一些实现似乎想考虑这种行为 [7],不过根据 Velox 的人说,大部分时候 Photon 还是更喜欢 Hash Join [8]。
因为这里是个 fallback path,所以论文作者对这块的要求就是稳,而不需要跑多快。这里也会尽量避免过多的 memory 申请。论文摘录了一些替代手段,并说自己为什么没用:
There are very few alternative bail-out strategies. Other than sort- and loops-based strategies, one can:
- resort to additional memory allocations,
- data compression,
- or dropping columns from overflow files.
Additional memory grants can disrupt the entire server, as well as lead to deadlock (waiting for a memory grant while holding a lock on data).
- Data compression, in particular data compression on the fly, is very complex and would have introduced substantially larger implementation and testing effort.
- Dropping columns from partition files (replacing them with pointers into permanent files, and re-fetching the dropped column values later) can be very expensive due to the cost of fetching.
- Most importantly, however, all three alternative strategies only alleviate but do not completely resolve the problem. If the set of duplicates is truly very large, these three alternative strategies might well fail. Our goal, however, was to find a robust and complete solution for this rare case.
Histogram-guided partitioning
对于 Hash Partition Fanout F,在递归处理的场景下,可能会有不太好的分区处理。这里的实现通过 Histogram 来提前采集下一组 Partition 的信息,通过增加 Build 的时候的开销,来给之后可能的递归处理提供信息。
采集 4F 后,这组信息也可以用来指导后续怎么 Partition,比如合并下层4F,或者提供更大的 Partitions。这个也可以帮助指导是否 Role Traversal 甚至是否走 Bail out。
Teams for N-ary hash joins
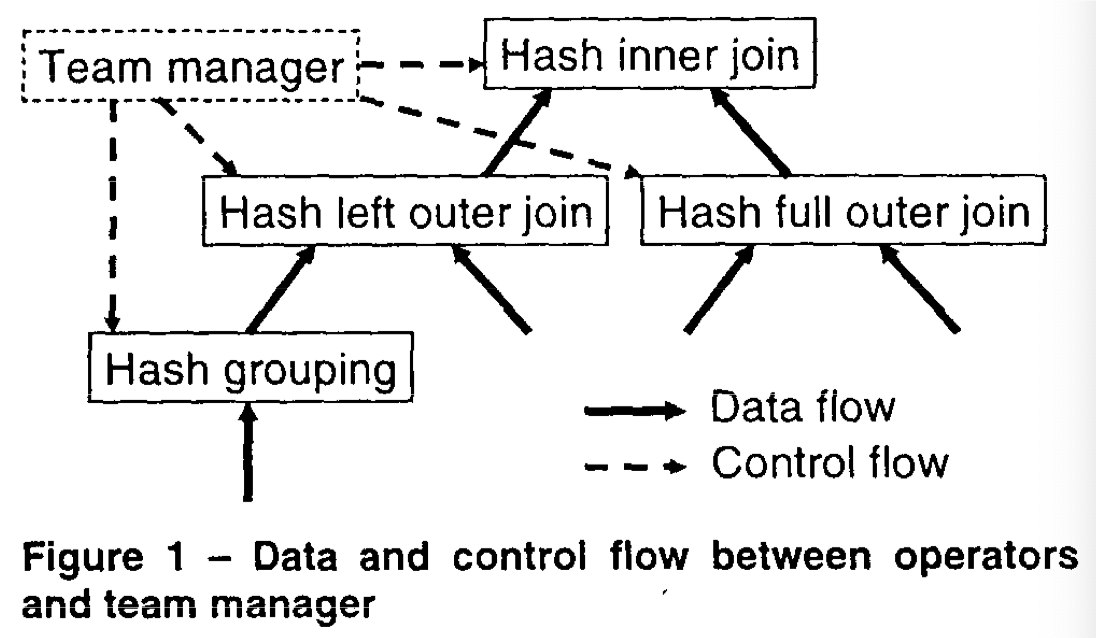
这里 Teams 类似 Sorting,把 Hash Partition 当成类似 Interesting Order 的信息维护,希望下面的 Operator 能用到上面的分区信息。用来优化多组的分片。
The key to implementing hash teams is to separate control over spilling (overflow) and partitioning policy decisions from the individual hash operation and to assign it to a team manager, which performs this control function for all member operations within the team. As a result, all team members (which, by definition of a team, hash on the same set of columns) spill, restore, and process the same partitions at the same time, even when recursive partitioning is required.
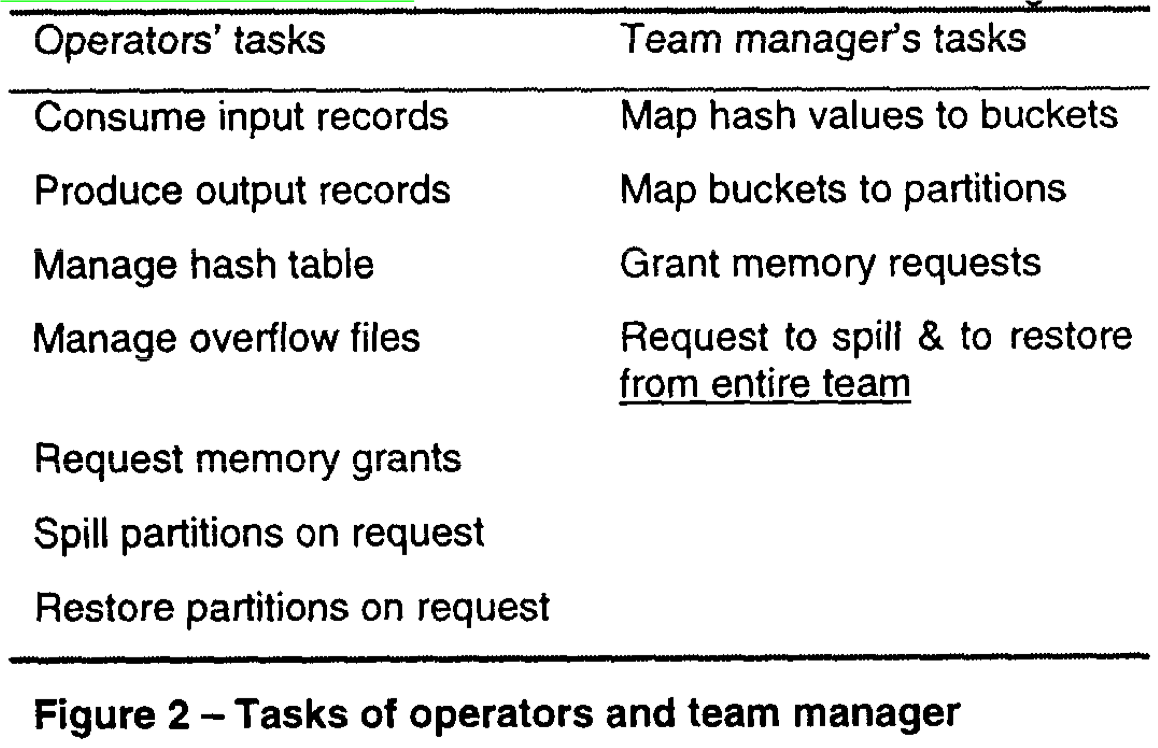
Memory Management
- 每个查询在启动时被分配一个固定的内存量,复杂查询计划被划分为多个阶段,每个阶段分配一定比例的内存。
- 中间阶段的操作(如 Hash Build 和 Hash Probe)会分配 100% 的可用内存。
通过放弃复杂的替代方案,论文最终选择了一种简单但稳定的内存管理策略,确保系统能够在复杂查询中高效地分配和释放内存资源。在 Query 内部去协调各种状态和 Spilling。
Reference
- Presto 的 Group Execution https://github.com/prestodb/presto/wiki/Stage-and-Source-Scheduler-and-Grouped-Execution
- MySQL·源码分析·索引选择 http://mysql.taobao.org/monthly/2023/07/02/
- MySQL Index-Merge代价估算原理 http://mysql.taobao.org/monthly/2024/09/04/
- SwissTable https://www.youtube.com/watch?v=ncHmEUmJZf4
- Velox Spiller 的逻辑 https://facebookincubator.github.io/velox/develop/spilling.html#spiller
- Spark AQE https://blog.mwish.me/2024/12/11/Adaptive-and-Robust-Query-Execution-for-Lakehouses-at-Scale/
- https://issues.apache.org/jira/browse/SPARK-32634
- https://github.com/facebookincubator/velox/discussions/3735