Column or row in database execution
< DSM vs. NSM: CPU Performance Tradeoffs in Block-Oriented Query Processing> 是一篇 CWI 发表于 08 年的论文,介绍在 MonetDB/X100 中实验并比较,对于不同性质的 operator,评估 row/column 执行效率。本篇论文大概分成了两种负载:
- Sequential data access: 直接 scan 类的开销,比如 scan, add, sum 等
- Random data access: 这个地方论文举的例子比较有意思,用(Hash)Agg 来表示
论文很短,是那种八页的小论文。作者评估了不同 Operator 的情况,包括也采用了 CPU Prefetch Intrinsics 来测试 prefetch,得到不同数据规模(fit in L1/L2)下的负载情况。此外,论文当时看起来是有点像想支持行列混合执行的框架,所以
看本篇论文是看到 Datafusion 博客 [1] 中的「Optimized Multi-Column Grouping」一节,这个 Patch 把多列 Agg 从行格式改成列格式,优化了 ClickBench 下的性能。优化是 Arrow->Row->Arrow 到 Arrow->(Accumulated)Arrow format,通过(可能增大)compare 开销,降低 copying 开销。对这块内容感兴趣,所以翻出了这篇文章,发现对这个话题有比较大的启发。
Abstract / Introduction
列存优势(老生常谈)
(i) CPU cache and TLB miss ratio, resulting from the data access patterns; (ii) the possibility of using SIMD operations (e.g. SSE) to process multiple data items with one instruction; (iii) the average amount of inflight instructions unbound by code- or data-dependencies, thus available to keep the instruction pipelines filled.
作者提出的关键词:
- block-oriented query processing: 一组数据(不管行还是列)的处理
- horizontal tuple layout (NSM): 行存
- vertical layout (DSM): 列存
Typically, performance increases with increasing block size, as long as the the cumulative size of tuple-blocks flowing between the operators in a query plan fits in the CPU cache. The main advantage of block-oriented processing is a reduction in the amount of method calls (i.e., query interpretation overhead). Additional benefit comes from the fact that the lowest level primitive functions in the query engine now expose independent work on multiple tuples (arrays of tuples).
NSM
关于列存实现,有点意思,大致说了为啥 c-store 那种格式不被选中,而是现在的 null-buffer + data-buffer pattern:
Traditionally, the Decomposed Storage Model [9] proposed for each attribute column to hold two columns: a surrogate (or object-id) column and a value column. Modern columnbased systems [5, 16] choose to avoid the former column, and use the natural order for the tuple reorganization purposes. As a result, the table representation is a set of binary files, each containing consecutive values from a different attribute. This format is sometimes complicated e.g. by not storing NULL values and other forms of data compression [21, 1]. In this case, some systems keep the data compressed for some part of the execution [1], and some perform a fully-transparent decompression, providing a simple DSM structure for the query executor [21].
在这种模式下,地址大概是这样的:
1 | value = attribute[position]; |
Extra Buffer Management
Variable-width datatypes such as strings cannot be stored directly in arrays. A solution is to represent them as memory pointers into a heap. In MonetDB/X100, a tuple stream containing string values uses a list of heap buffers that contain concatenated, zero-separated strings. As soon as the last string in a buffer has left the query processing pipeline, the buffer can be reused.
这里有点像 Arrow String 类型的编码,但是可以有多于一个 Buffer
NSM tuple-block representation
Typically, database systems use some form of a slotted page for the NSM-stored tuples. The exact format of the tuples in this model can be highly complex, mostly due to storage considerations. For example, NULL values can be materialized or not, variable-width fields result in non-fixed attribute offsets, values can be stored explicitly or as references (e.g. dictionary compression or values from a hash table in a join result). Even fixed-width attributes can be stored using variable-width encoding, e.g. length encoding [17] or Microsoft’s Vardecimal Storage Format [3].
Most of the described techniques have a goal of reducing the size of a tuple, which is crucial for disk-based data storage. Unfortunately, in many cases, such tuples are carried through into the query executor, making the data access and manipulation complex and hence expensive. In traditional tuple-at-a-time processing, the cost of accessing a value can be an acceptable compared to other overheads, but with block processing handling complex tuple representations can consume the majority of time.

1 | value = attribute[position * attributeMultiplier] |
这里实现似乎没有考虑变长的字段的处理,不过参考 Arrow/Velox 之类的 Row 格式,其实我感觉区别应该不大。本质上是尽量快的访问,来做 benchmark 并避免一部分开销。
Experiments
环境:
Core2 Quad Q6600 2.4GHz with 8GB RAM running Linux with kernel 2.6.23-The per-core cache sizes are: 16KB L1 I-cache, 16KB L1 D-cache, 4MB L2 cache (shared among 2 cores). All experiments are single-core and in-memory. We used 2 compilers, GCC 4.1.2 2 and ICC 10.0 3 .
很古早,感觉现代的自动向量化能做的好不少,这里他也用 icc 来代表自动向量化的 case
Sequential data access
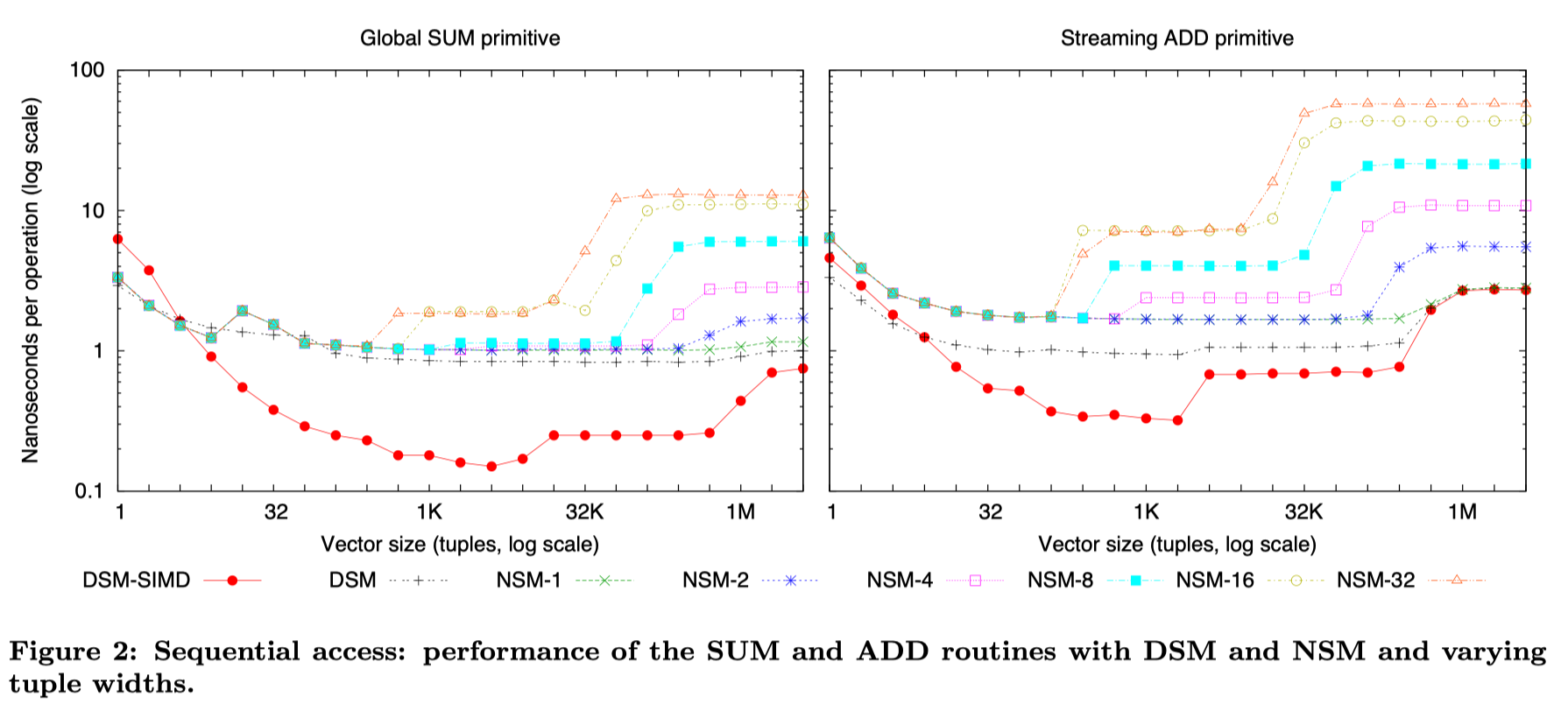
这里测的是 select sum(..) from .. 的情况和 select add(..) from 的情况,前者只需要访问一列,后者读数列写一列。性能 benchmark 如上。这里向量化逻辑可以参考之前的博客:https://blog.mwish.me/2023/12/10/Compiler-Optimizations-Power-Limits-Auto-vetorize/
这里注意到,对于 SUM 一列的场景
- DSM 的非向量化性能和一列 NSM 性能相似
- 在向量化场景下,因为行存的代码更加复杂(猜测是因为没有 codegen,所以也不好推断类型),这里不是很好生成向量化的代码
- 更宽的 (NSM-2 - NSM-8),在 NSM-16 以下,因为在测试中能 fit-in-l1,所以性能相似。当表无法 fit in l1 的时候,性能开始下降,瓶颈会出现在 L2 Cache 出现的时候
- NSM-16 以下的,考虑到可能大于 cacheline,性能会进一步下降( 这里没完全看懂,感觉是跨了多 cache line,导致访存进一步下降?)
Add 和 SUM 有一些区别:
- First, the higher number of parameters passed to the NSM routine (pointers + tuple widths VS only pointers) results in a higher interpretation overhead.
- multiple more complex value-access computations in NSM have a higher impact on the CPU performance
- With a higher memory demand, the impact of data locality on performance is significantly bigger, making even the DSM implementation fully memory-bound and in par with the NSM-1 version.
结论上,列存在 Sequential scan 的场景下优于行存可能性是:
- Allows simple value-access code. ( 访问的内存更小 )
- Second, individual primitive functions (e.g. SUM,ADD) use cache lines fully in DSM, and L2 bandwidth is enough to keep up. ( 内存吞吐为瓶颈的情况下,列存对 cache line 之类的利用比较友好 )
- Finally, the difference in sequential processing between DSM and NSM can be huge if the operation is expressible in SIMD, especially when the blocks fit in L1, and is still significant when in L2. ( L1 下,列存计算带宽更好发挥)
Random Data Access
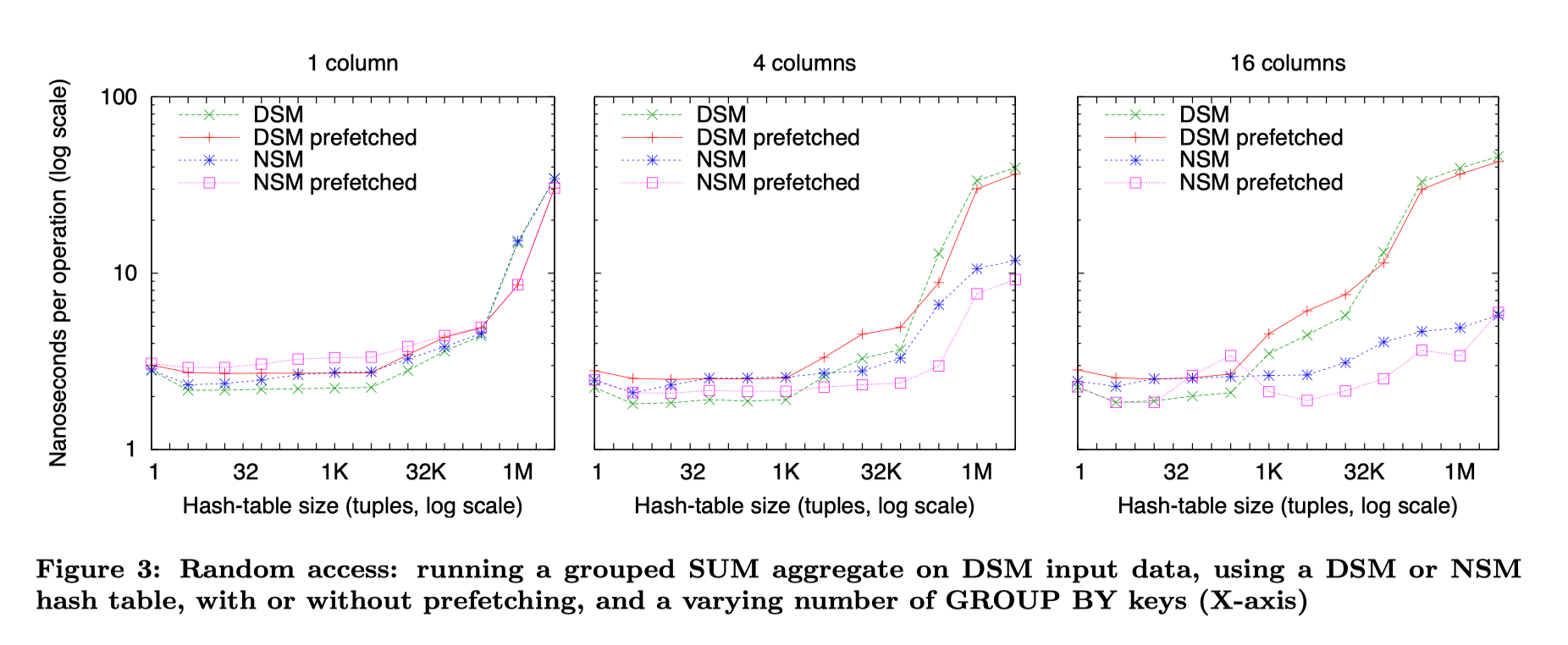
这里测的是下列的情况
1 | SELECT SUM(data1), ..., SUM(dataN) FROM TABLE GROUP BY key; |
Benchmark 的结果比较 sound:
对单列来说:
- 如果小于 L1 大小,列存会稍微快于行存,因为 Fit In L1 Cache
- 如果大于 L1 大小,两边都是 Memory Limit 的了,因为两边大小差不多,所以性能差不多
对多列来说:
- 如果小于 L1 大小,列存仍然保持优势
- 否则,行存占优势。这里和 cache miss 有关,如下文
This is caused by the fact, that in DSM every memory access is expected to cause a cache-miss. In contrast, in NSM, it can be expected that a cache-line accessed during processing of one data column, will be accessed again with the next data column in the same block, as all the columns use the same key position. With the increasing number of computed aggregates, the same cache-line is accessed more often, benefiting NSM over DSM.
开启 prefetch 指令后,行存的优势变得更加明显,猜测是因为 Pattern 可以预测,导致这块可以更快
In general, our experience with prefetching is that it is highly sensitive to the platform, and prefetch distances are hard to get right in practice. The end result is that prefetching does improve NSM performance when the aggregate table exceeds the CPU caches, however in contrast to [8] we could not obtain a straight performance line (i.e. hide all memory latency).
Data Conversion
这里 Conversion 被认为是比较快的,原论文做了个快速计算:
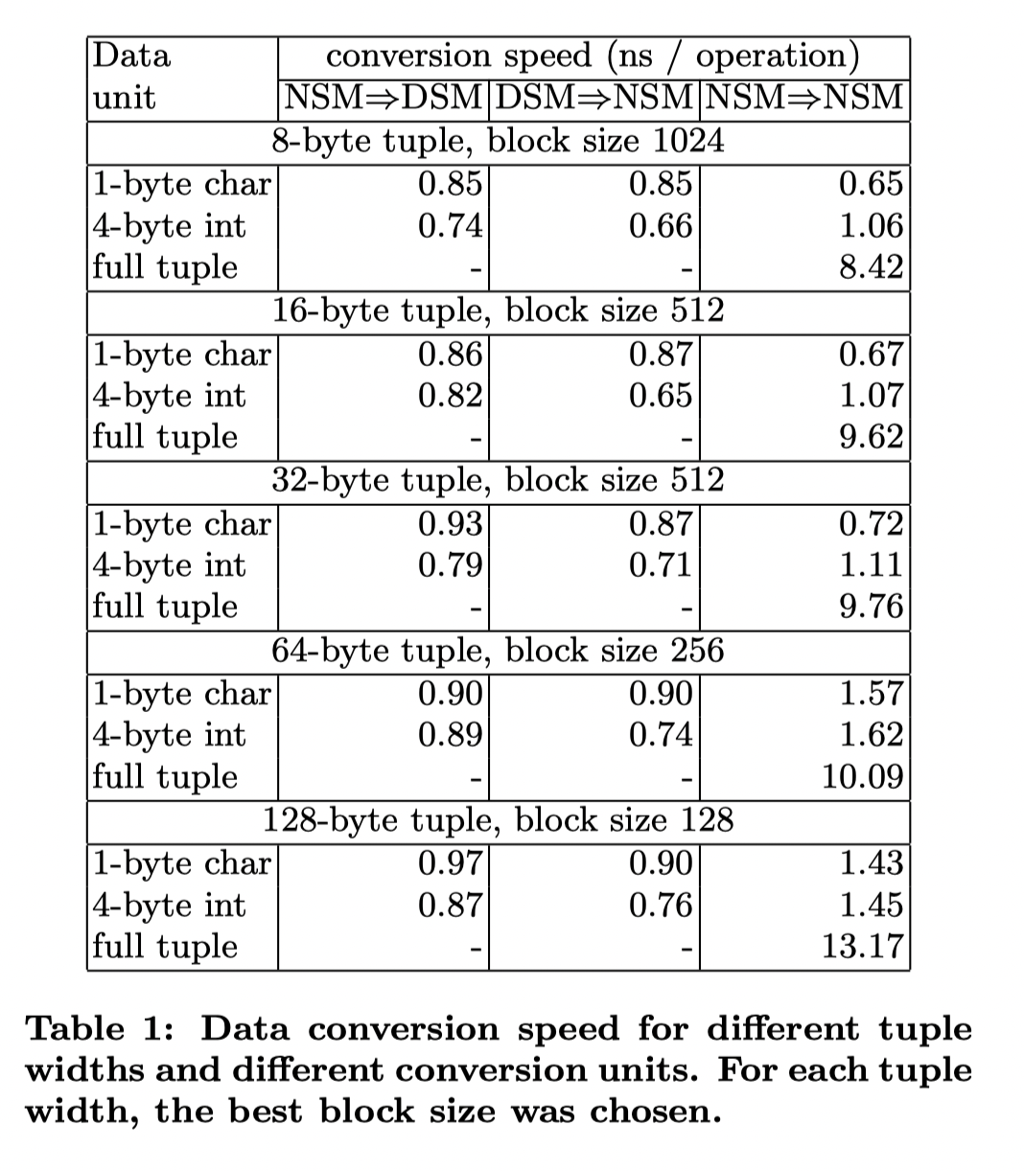
这里计算本身没啥问题,但是论文没有考虑变长列,导致这个场景过度简单了。实际上参考 Velox/Arrow/Arrow-rs 代码,这里可能会分成:
- 列转行(可能是 Hash Agg 之类的算子输入):需要 calc size ,计算出每行的 size -> 然后分配空间 -> 然后快速向量化的写入内容。这三种中间的 barrier 比较少,可能要进行一些 memcpy 的转化
- 行转列(可能是 Hash Agg 之类的算子输出):需要处理好 str,如果 str 生命周期处理的比较好的话(比如 Velox 的 StringView),这里也可以做到向量化的输出。