VLDB'09: SIMD-Scan
SIMD-Scan: Ultra Fast in-Memory Table Scan using onChip Vector Processing Units 这篇文章发表于 2009 年的 VLDB,文章介绍的是 fast-scan,但是主要是文章的 fast-unpack 技术在后来被广泛使用了。本文特地对其第四章做一些记录,然后直接介绍 Arrow 的 unpack 这块的源代码。关于硬件假设,09 年的假设也是过早了,所以扫一眼就行,懒得介绍垃圾了。本文介绍的时候文章主要扩展的 SIMD 还是 SSE,但文章写的时候也强调了这个实现能适配各种宽度的 SIMD。本文作者来自 Intel 和 SAP,项目好像还不是 SAP Hana,不知道本项目是不是 Hana 的前身。考虑到一个硬件差别:写文章的时候 unaligned access 好像还是有不少 penalty 的,但现在感觉不太多了。
Unpack32 实现
本文把 Unpack32 分为下面几个阶段,并以 9bit 的压缩为例子来展示这块代码的实现:
- 16-Byte Alignment
- 4-Byte Alignment
- Bit Alignment
这里大概的流程如下,不考虑 epilogue.
- N: 本块的 number of bits
- m: m开头的代表mask
- b/c: 代表存放 epi32 的 vector
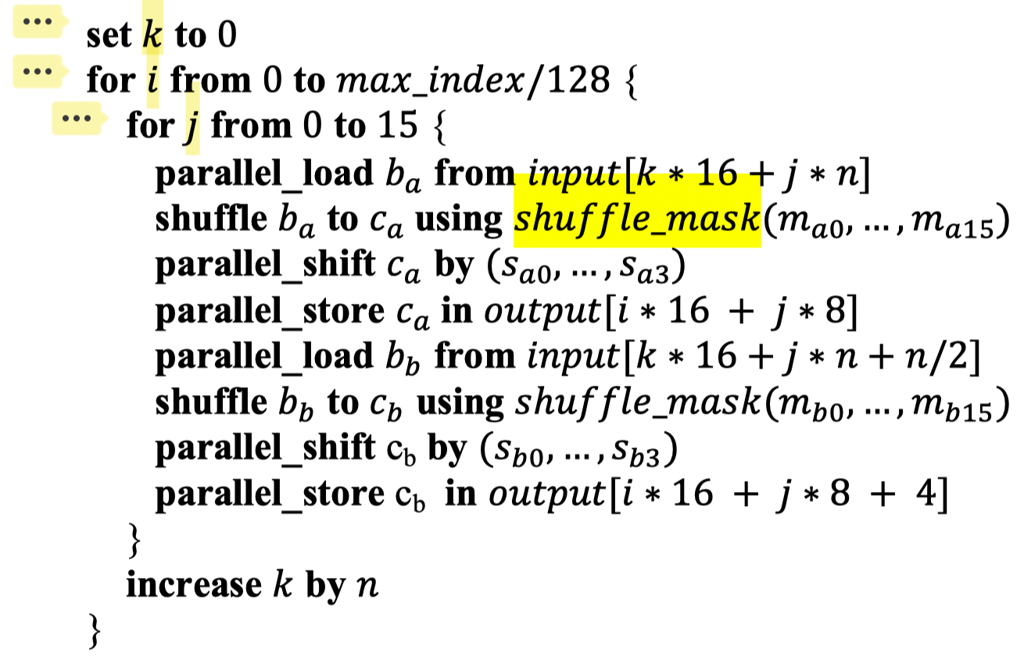
16Byte Alignment: 你直接叫 Load 得了
主要问题:
- Byte-Aligned 去 Load 一个包含这次要处理数据 SIMD Batch(这轮代码不要求 aligned,只要求包含这个 batch 需要处理的数据)
- 这个地方有一个问题是「load 下一批 batch」怎么处理,例如有两种处理:
- 靠下次从一个合适的位置去 load(比如一个 batch 16B,然后 bitpack 每个数字 9bit,那么这次需要处理的是 15Byte-31Byte)。写论文的时候,unaligned access 开销是比较高的,所以作者没有选择这种方式
- Load 下一个 Batch,靠 (Byte) Shift + And 来解决.
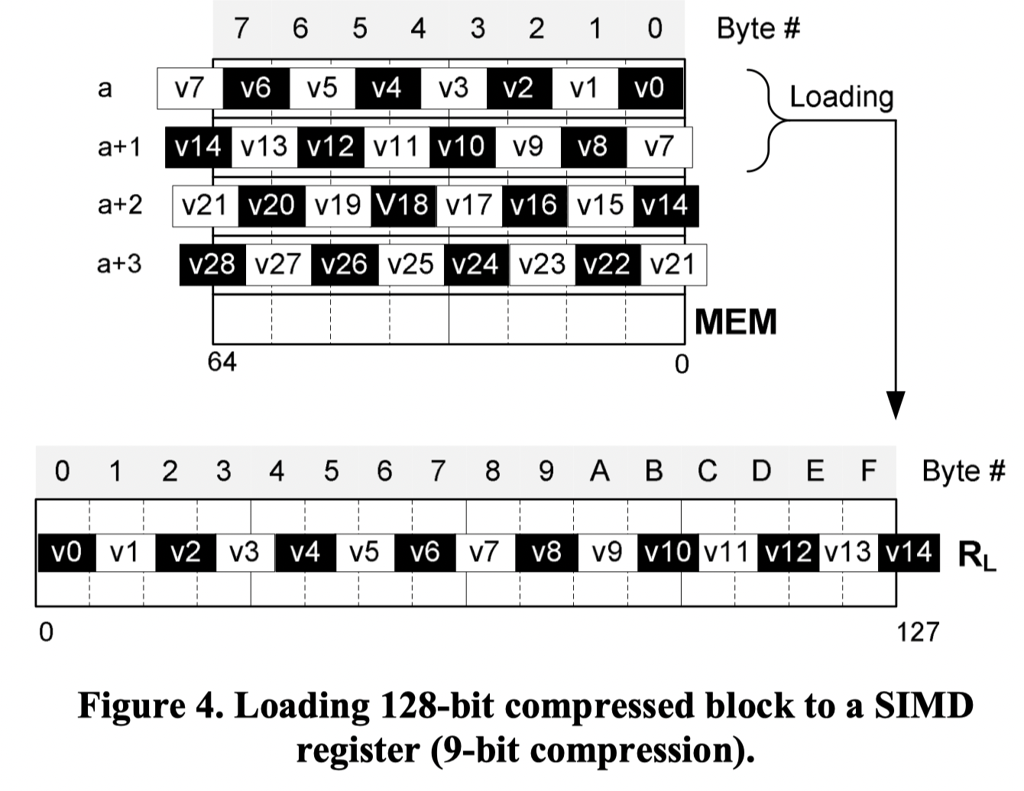
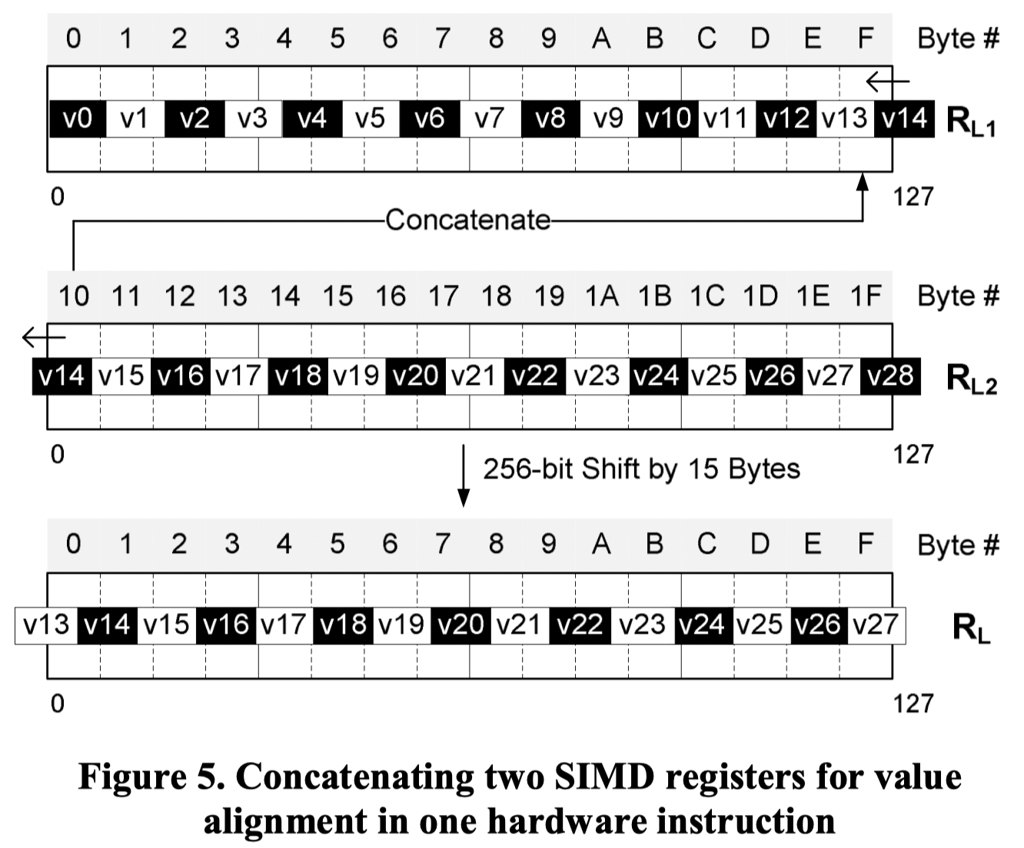
4-Byte Alignment ( Byte Shuffle )
记 16-Byte Alignment 输出为 $R_L$,本轮的目标是让每个数字对齐4B。这个目标如下图
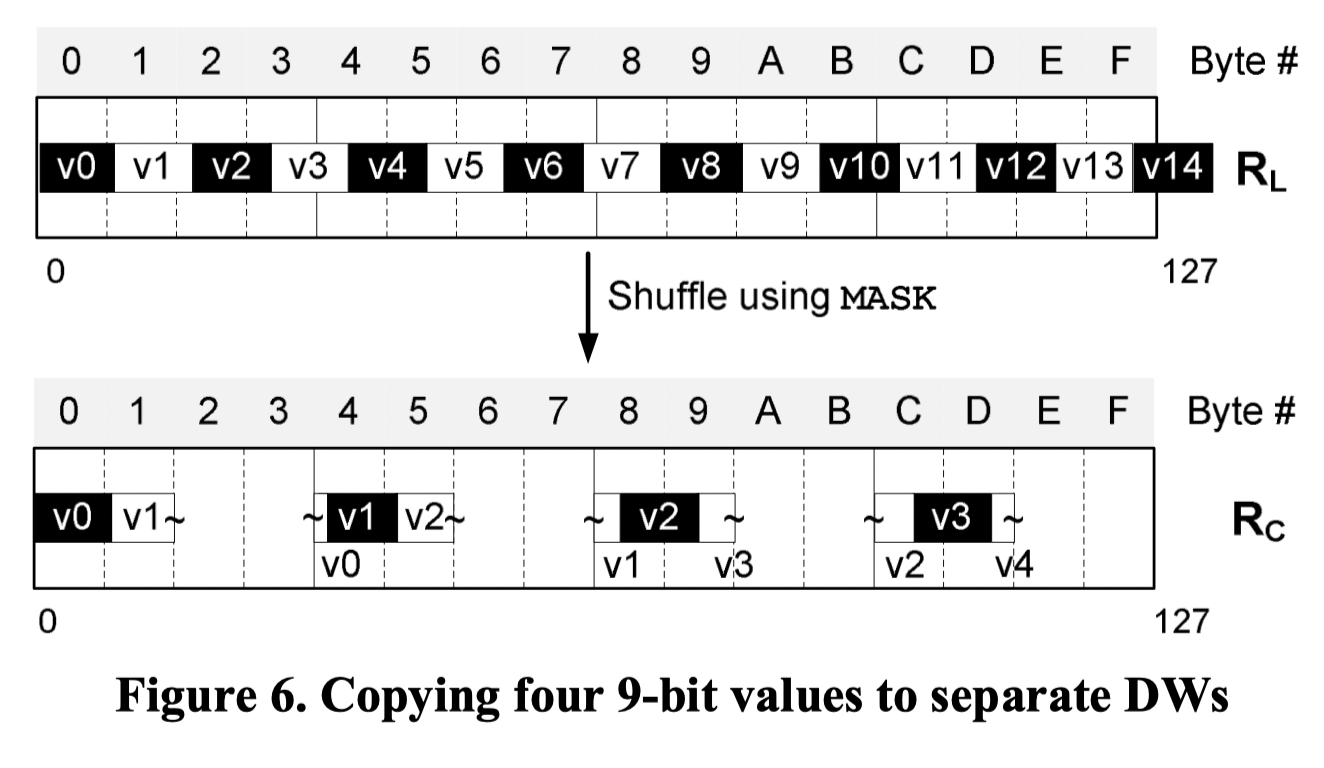
这个仍然是 byte-level shifting,没有做 bit 的对齐,只是按照 byte 把需要解析的某内存移到对应 32Bit 的第一个位置。这里认为应该用 shuffle 系的命令来处理(Q: shuffle dest 是如何生成的?)论文给出了这个 mask:
MASK = {(0,0), (1,1), (1,4), (2,5), (2,8), (3,9), (3, C), (4, D), (zeros, else)}
通过这个 mask,来写入第一组,后面的组可能需要生成不同的 mask 去 shuffle. 再注意到结尾,这里会需要对 invalid bits 做 cleaning,而且这里因为做的是 Byte Shuffle,有一些 Byte 可能会带着下一个(甚至下几个 value) value 的 trailing bits。有的部分需要最后一步做。
上面的 shuffle 还是比较易懂的,但是上面算法还有一个问题,见 Figure7 的例子(这个例子很好理解,比如 32b 目标中,如果有大于 3 Byte 的对象,那这个大于等于 3Byte + 2bit 实际上可能横跨 RL 中的五个物理 Byte)
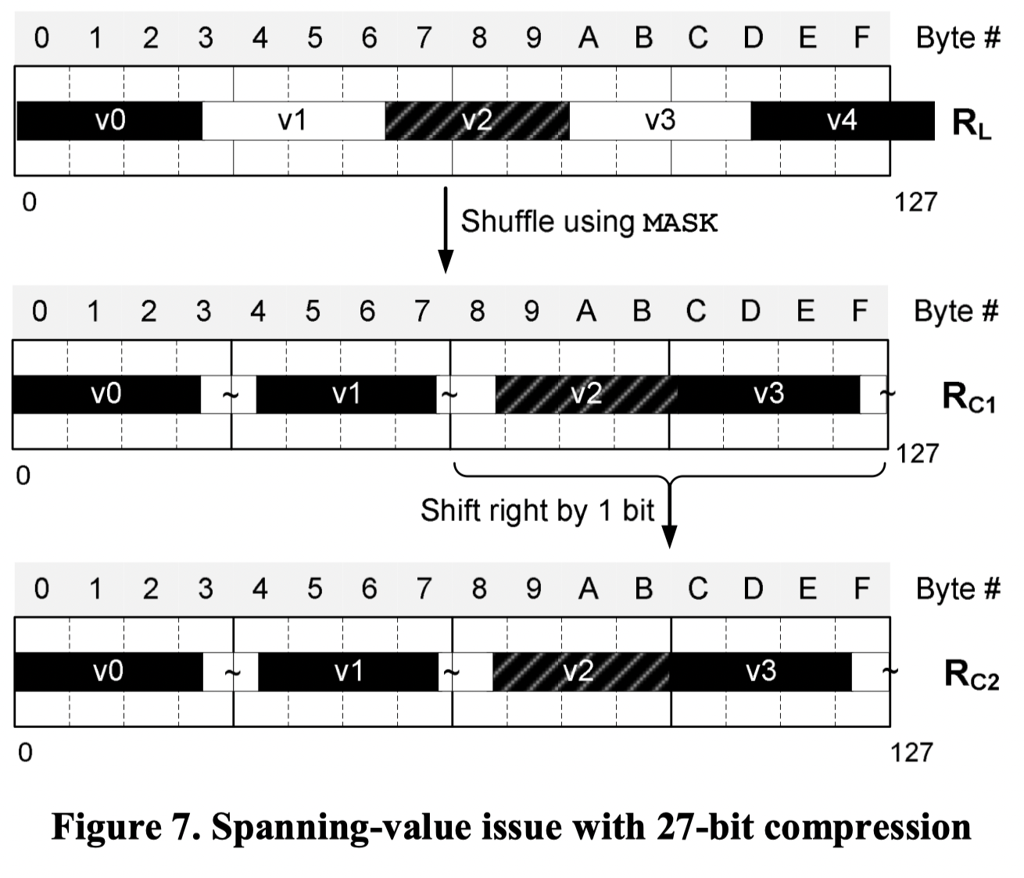
这里采取的解决方案是 mask + (Partial) shift
Bit-Alignment
这个 epi32 的 shift 完成…了吗?没,这里还要有个清除 trailing bits 的 bit-and 操作。
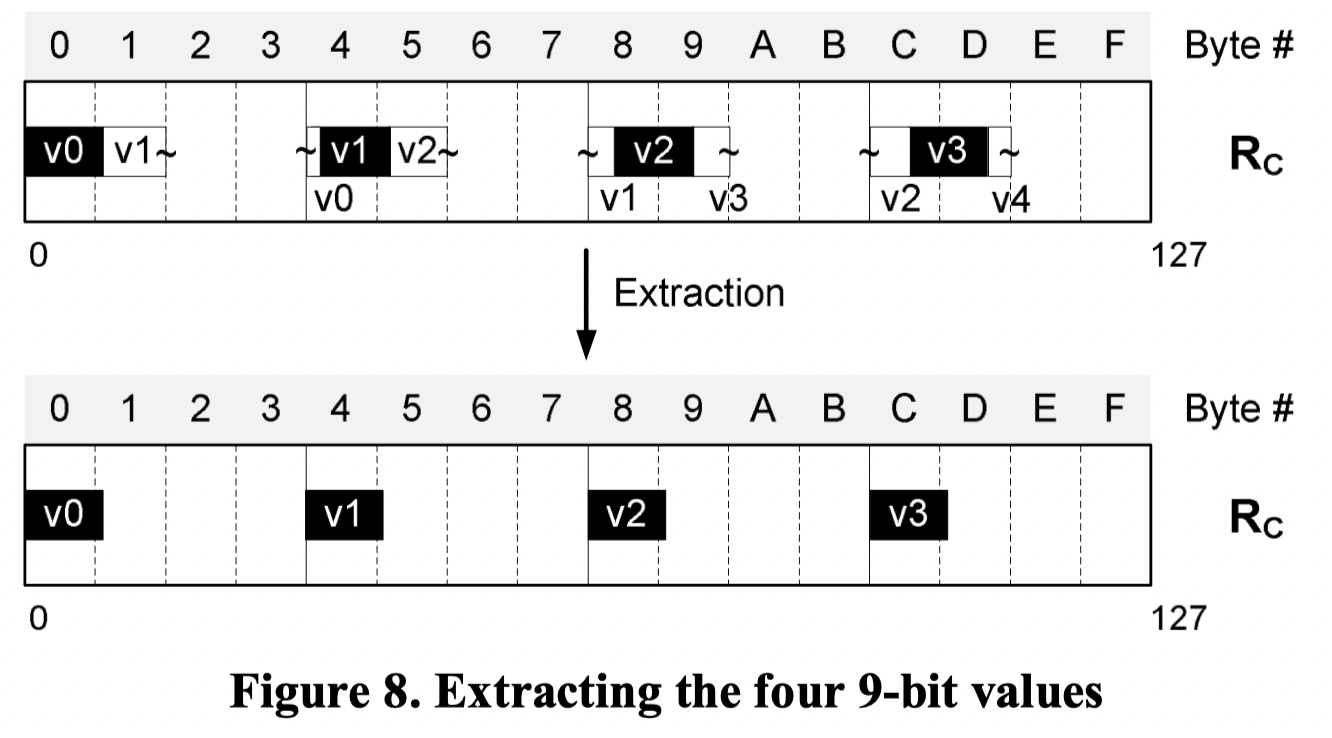
然后再走一个 aligned store,完事!
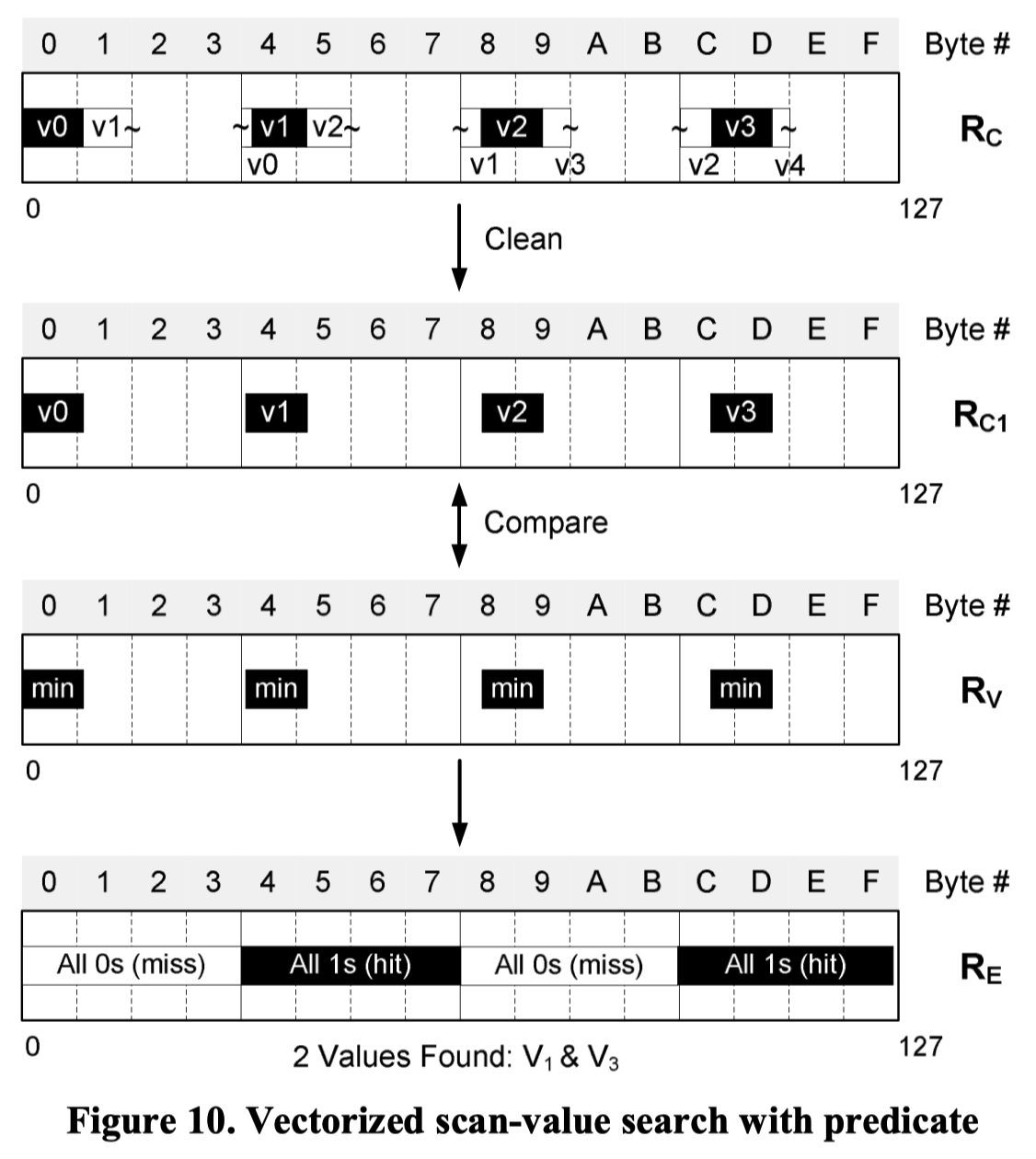
Applying (简单的) Filter
这个地方还是生成 Mask 在 4B 的时候处理
Arrow 的实现
Arrow 的实现实际上 Load Byte 会稚嫩很多,这里还是按组去 load 好完整的 Byte,而没有实现成文章中 Load -> shuffle (-> optional shift ) 的方案
这里代码特别有意思,因为这个是脚本生成的 bitpack32: https://github.com/apache/arrow/blob/main/cpp/src/arrow/util/bpacking_simd_codegen.py , 发出来图一乐了
以 unpack5 为例:
1 | inline static const uint32_t* unpack5_32(const uint32_t* in, uint32_t* out) { |