SIMD Extensions and AVX
这一节离前面一节又过了很久,写前一节的时候还没过年,现在都年后了。我们复习一下前面的目录:
- https://blog.mwish.me/2022/11/05/x86-and-SIMD-programming/
- https://blog.mwish.me/2023/11/15/Fast-Scalar-Code-and-Compiler/
- https://blog.mwish.me/2023/12/10/Compiler-Optimizations-Power-Limits-Auto-vetorize/
AVX 基本概念
这节我们正式以 AVX2 为例,来介绍 SIMD。x86 有它的 Core 平台,而 2011 年,AMD 和 Intel 集成了 AVX 到它的平台中,寄存器从 SSE 的 128 位扩展到 256位,简单来说,AVX 新增的内容如下:
- 与通用寄存器不同,使用非破坏性语法,如果 src 和 dst 不是同一个寄存器的话,那么不会修改 src 的值
- AVX2 增加了 broadcast, shuffle, perm 指令等
- 增加了一种向量索引寻址模式,便于 load/store 非连续的数据
- AVX-512 还增加了8个名为 K0-K7 的掩码寄存器
此外,还有一些扩展的指令,包括 BMI/FMA/LZCNT 等指令集,严格意义上这些好像也不算 SIMD,算是「通用寄存器指令集扩展」,他们作用在通用寄存器而不是 SIMD 的寄存器中。一般在使用相关指令之前,程序需要通过测试 CPUID FMA 功能表示来确定扩展可用性(相关代码:https://github.com/apache/arrow/blob/605f8a792c388afb2230b1f19e0f3e4df90d5abe/cpp/cmake_modules/SetupCxxFlags.cmake#L47 )
x86 支持不同数据类型的计算,包括双精度、单精度浮点数,和各种宽度的整数,还有 char 之类的 1Byte 结构。AVX2 还有半精度浮点数的支持
AVX/AVX2 本身和浮点数用同一组寄存器,寄存器如下(XMM 是 128位的 SSE 寄存器组,YMM 是 AVX 寄存器组):
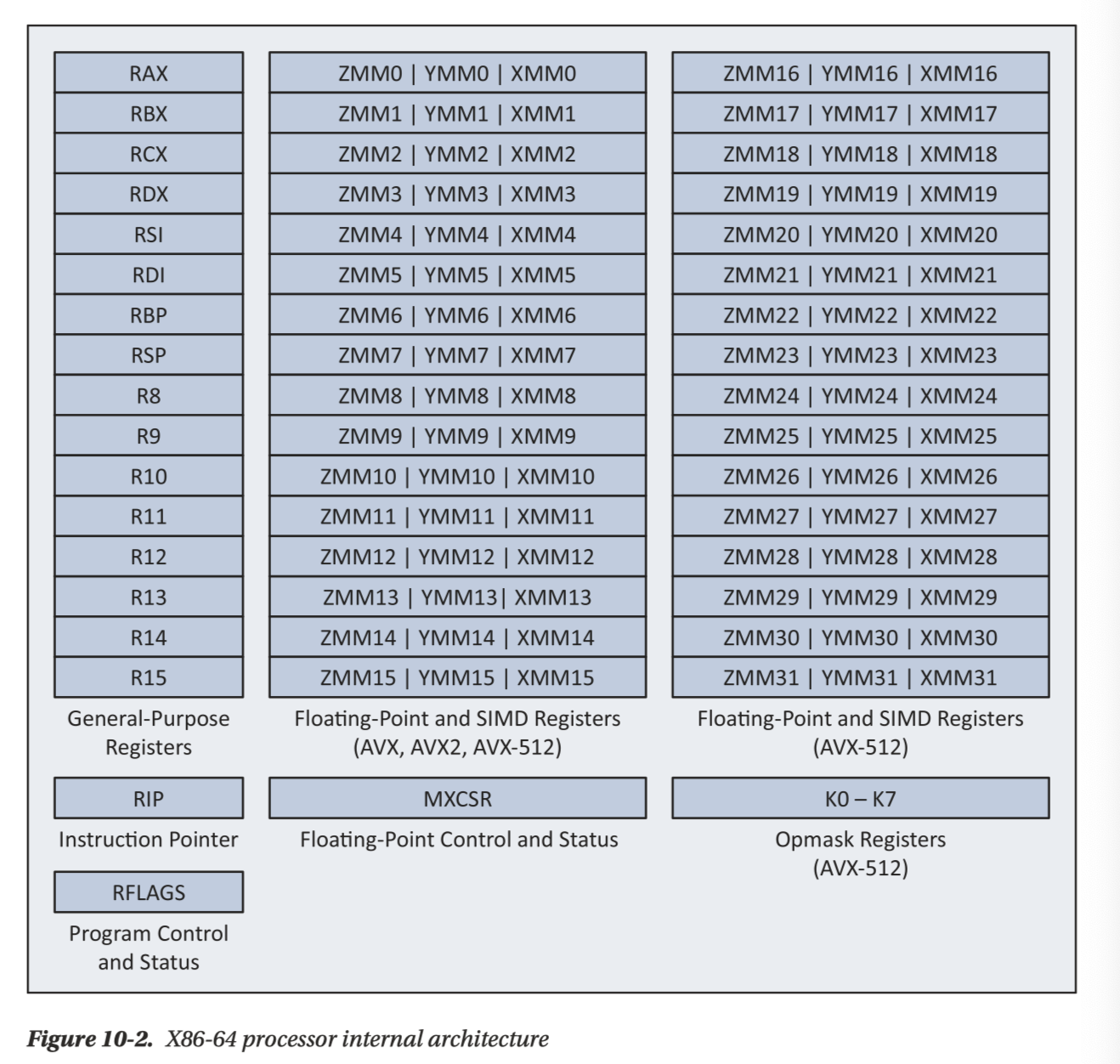
(AVX512 扩展到了 512 bits,并且增加了 16个寄存器,即 ZMM16-ZMM31)
这组寄存器也能够表示单精度、双精度的浮点数:
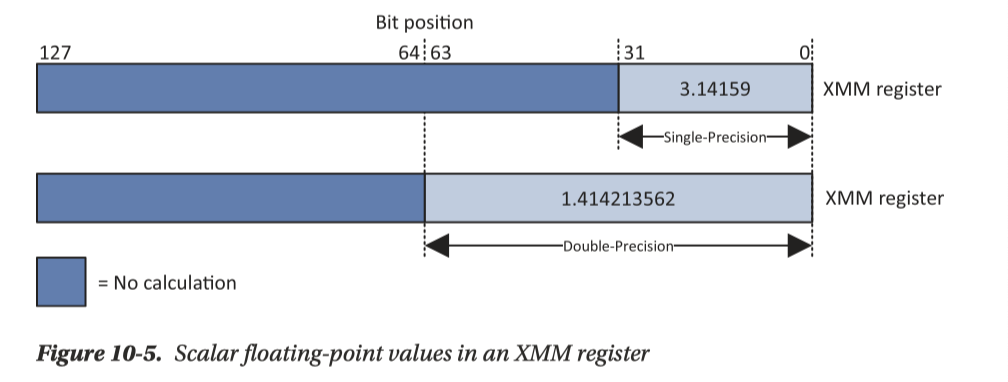
此外,这里还涉及一个表示
AVX2 和 x86 一样,也有数据类型的概念,可见:
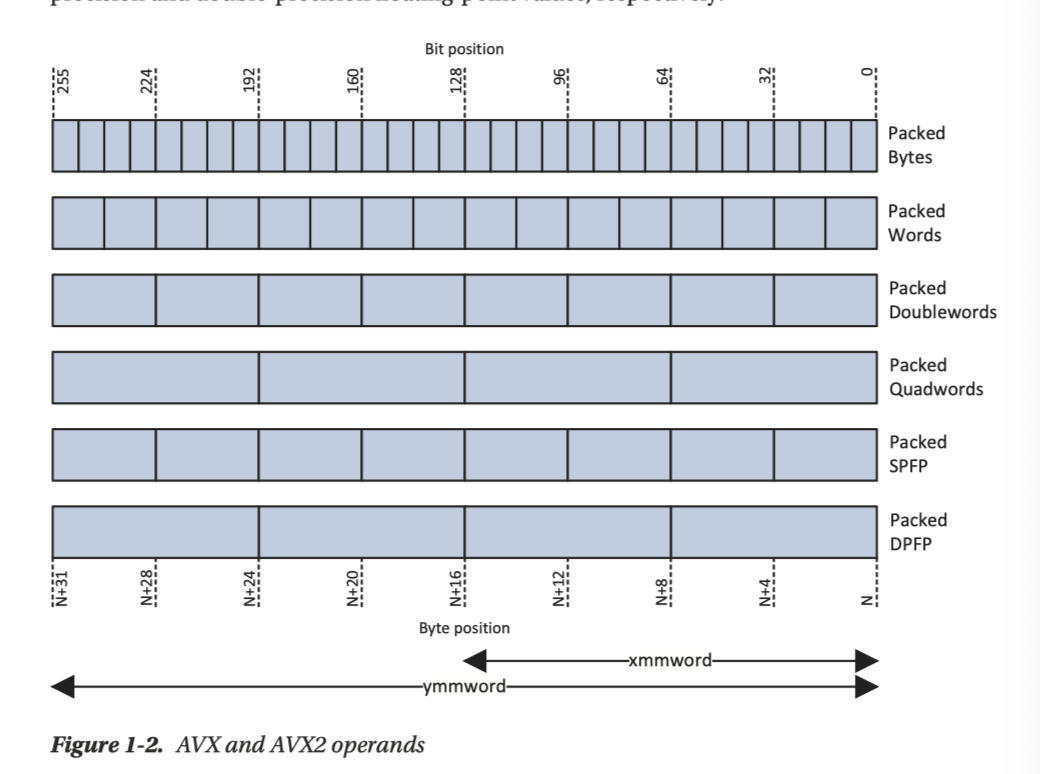
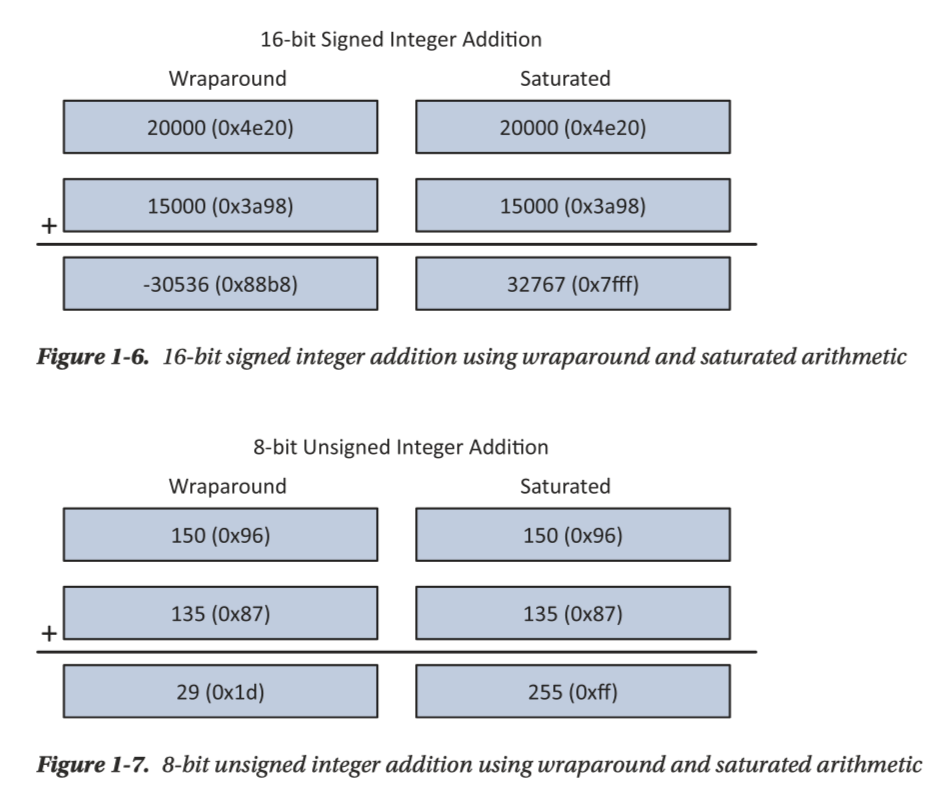
Avx 支持一种整数的 “saturated arithmetic”, 即对 overflow/underflow 做特殊判断,这个结果看下图很好理解,我们在之后会了解到如何设置本模式。
浮点数编程的概念:
TBD
混用 SSE 和 AVX 是有风险的,AVX 下用 SSE 会清除对应的高位。这也可能带来对齐之类导致的性能开销,见:
- 为什么AVX反而比SSE慢? - 知乎 https://www.zhihu.com/question/37230675
- https://www.intel.com/content/dam/develop/external/us/en/documents/11mc12-avoiding-2bavx-sse-2btransition-2bpenalties-2brh-2bfinal-809104.pdf
根据手册:
It is often possible to remove AVX-SSE transitions by converting legacy Intel® SSE instructions to their equivalent VEX encoded instructions. When it is not possible to remove the transitions, it is often possible to avoid the penalty by explicitly zeroing the upper 128-bits of the YMM registers, in which case the hardware does not save these values.
这里提到了两种做法:
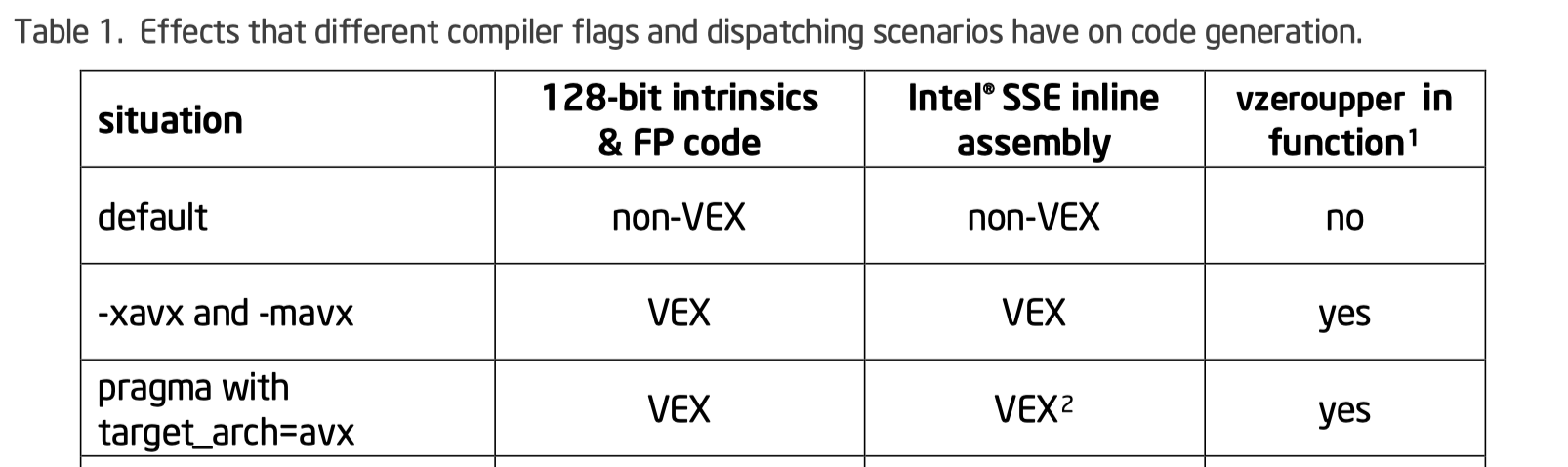
- 使用 VEX 指令,例如
movaps->vmovaps,转化成对等的 vex 指令。这个操作如果写了 intrinsics 并且编译的时候带上了对应的参数 - 使用
_mm256_zeroupper();之类的指令来清除上面的指令。不是所有的 SSE 都有对应的 AVX2 指令,因为跨 lane 的操作是比较昂贵的。
混用 AVX2 和 AVX512:原则上没问题,不过小心降频。AVX512 会提供一组更多的寄存器:
TBD
AVX2 & Intrinsics
Intrinsic 还是比较重要的概念,当然你或许多少见到过。你可以在 Intel 页面上 ( https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html )看到过。这里相当于 C++/C 代码开洞,给参数这些对应的类型,然后写 C/C++ 代码来调 SIMD 代码,我们后面代码基本以 intrinsics 形式来写。
这一块在处理的时候是没有 overhead 的,此外这里 intrinsics 还会处理一些奇怪的工作,比如靠 intrinsics 写 SSE 指令,在 SSE 和AVX intrinsic 都会被编译器生成 VEX-encoding 代码。
在我们关注 avx2 的时候,我们可以先看看 intrinsics 对应的类型(你会发现啥后缀没有的好像就是 float):
1 | __m256 f; // = {float f0, f1, f2, f3, f4, f5, f6, f7} |
我们可以看到 instrinsics 中的数据类型有关的命名:
- ps: 由float类型数据组成的向量
- pd:由double类型数据组成的向量
- epi8/epi16/epi32/epi64: 由8位/16位/32位/64位的有符号整数组成的向量
- epu8/epu16/epu32/epu64: 包含8位/16位/32位/64位的无符号整数组成的向量
在 intrinsics 中,代码和指令可能是一对一的( Native Intrinsics ),也可能是一对多 (Multi Intrinsics ) 的关系,我们列举如下:
1 | _mm256_load_pd() <-> vmovapd |
下面的类似解释如下:
_mm256_set1_pd()这个intrinsic function,在新的avx系列的指令中是由VMOVDDUP和VINSERTF128这两条汇编指令组成的。实际上_mm256_set1_pd()可以看成是一条宏汇编指令,只不过这是通过intrinsic function来实现的。很多时候汇编器为了方便,会提供一些宏汇编指令,这些宏汇编指令会由一般是两条指令组成,有时候会是一条汇编指令组成,甚至有时没有对应的汇编指令。但avx中大部分的intrinsic function都是对应一条汇编指令的。
关于 cast,还有一些甚至类似 reinterpret_cast,实际上什么都不会做的。
此外,这里还提供了一些宏,比如 _MM_SHUFFLE(): https://community.intel.com/t5/Intel-C-Compiler/mm-shuffle/m-p/947890
初始化寄存器: Load & Stores 和其他操作
Aligned/Unaligned Load from array。所有的类型都支持 aligned / unaligned 的 Load / Store。

Pd: packed double precision.
这里需要注意的是,SSE 有一些特殊的指令支持 single-lane load,比如 _mm_load_ss _mm_load_sd
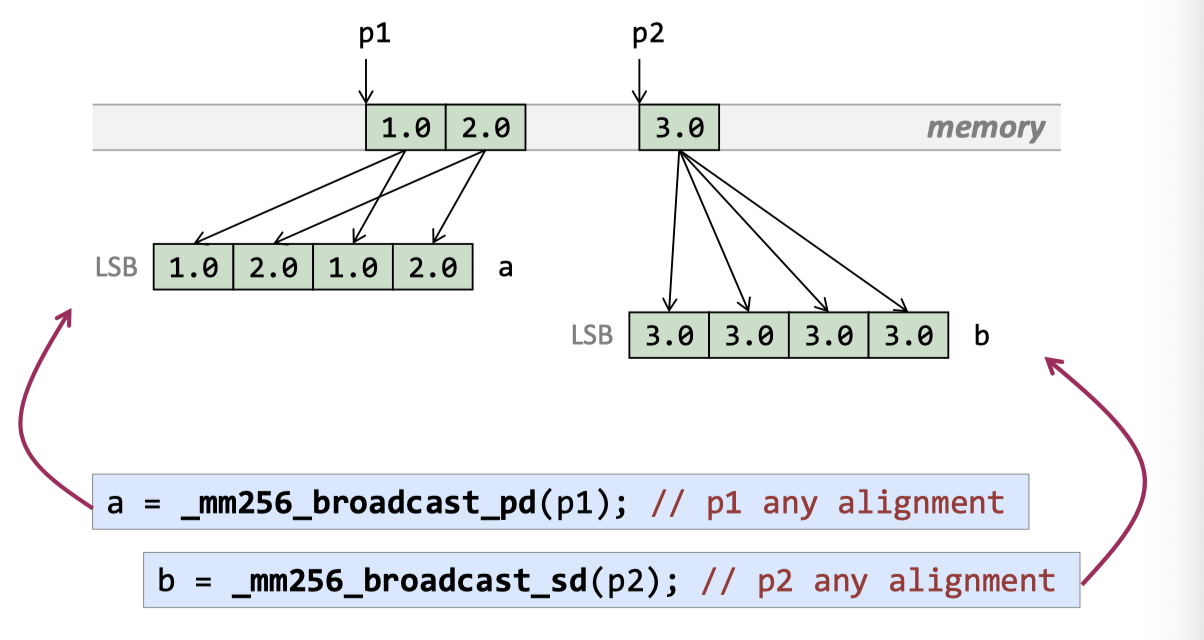
Broadcast ( with a __m256i mask)

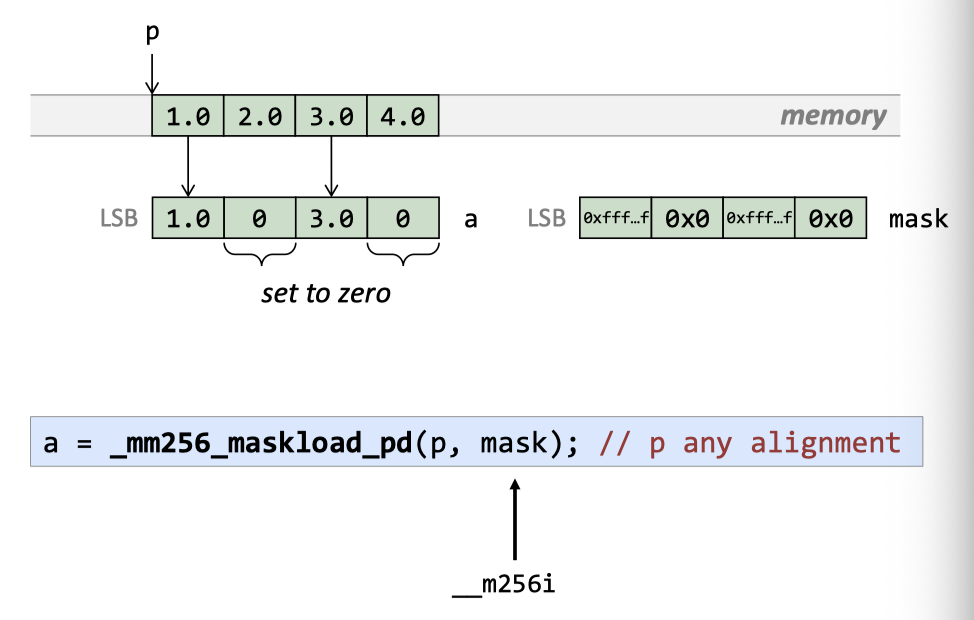
maskload
Gather ( From offsets )
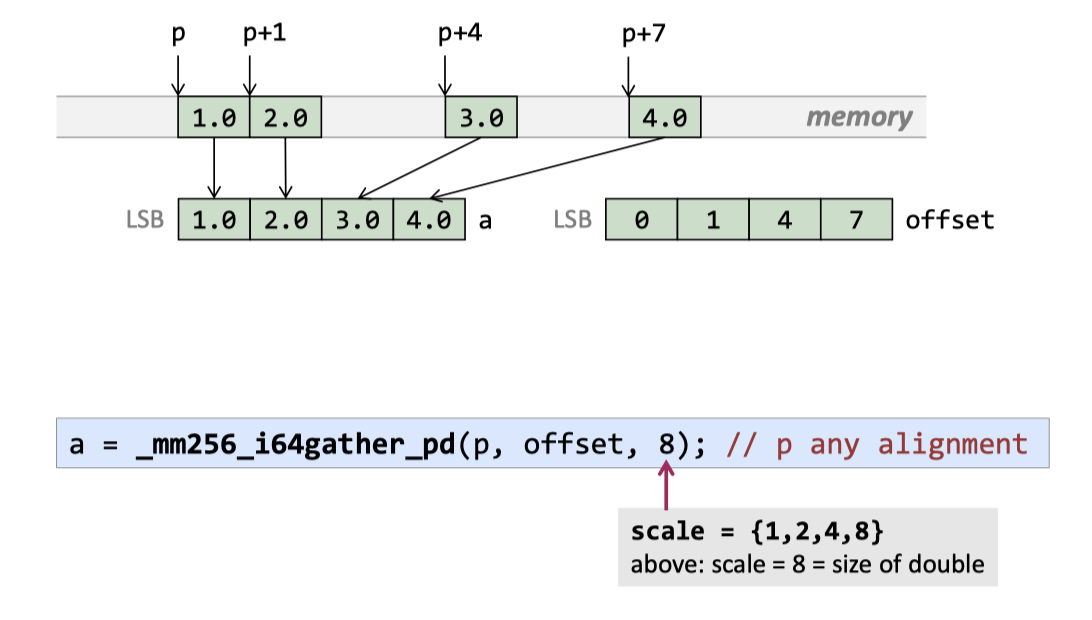
(scale 是用来处理 offset 的,这条指令可能会受到访存之类的限制,不会很快)
Load from Constants

这里还有一些编译器对应的行为,哈哈…
Finally, in many cases you don’t need to do anything special to load values. If your source data is aligned, you can just write code like
__m128i value = *pointer; and it’ll compile into an equivalent of regular load.
哈哈…
编译器的直接使用内存和操作
理论上,一些 avx 指令的操作数可以是内存,比如:
1 | _mm_add_ps( v, _mm_loadu_ps( ptr ) ) |
下面可以是直接转化成一条指令。
还有一些特殊的指令,比如 _mm[256]_stream_something ,可以 bypass cache,这种在视频处理之类的地方很管用
Arithmetic
Add / Sub / Mul / Divide
这些都实现了:
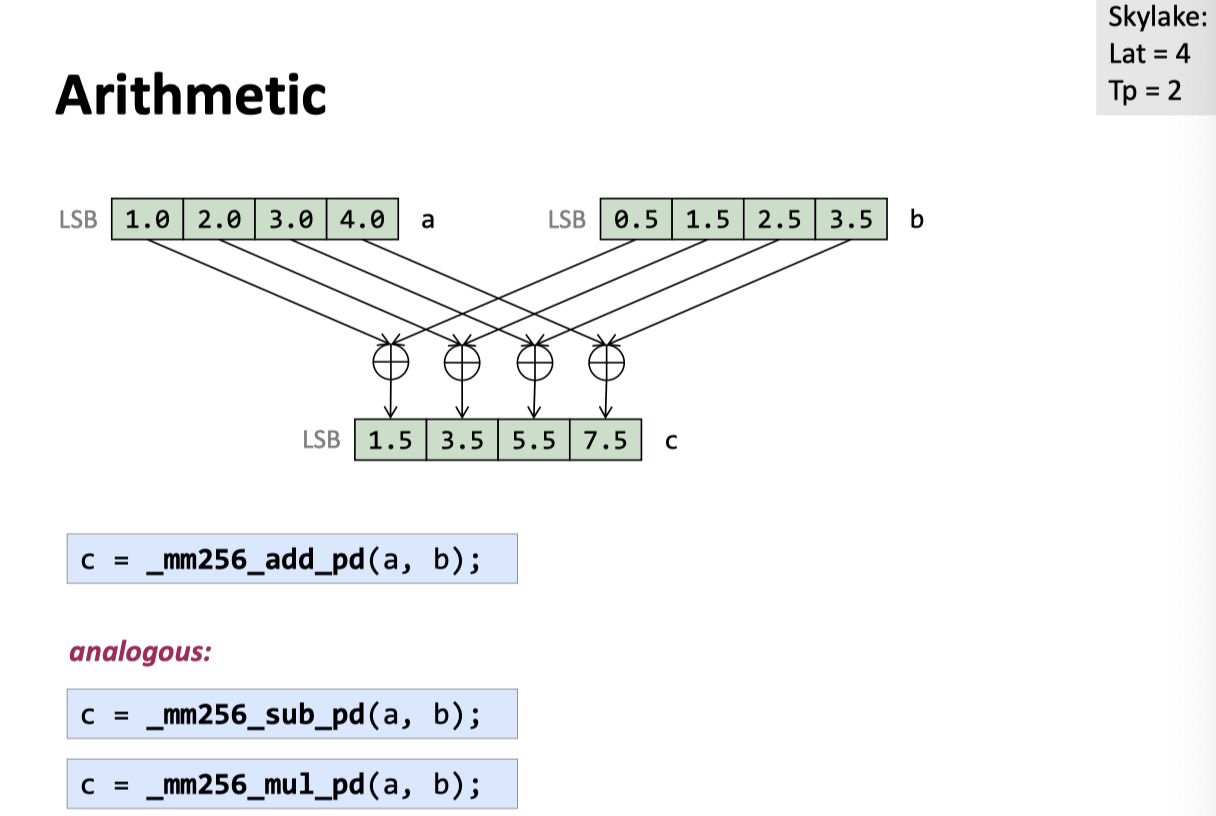
Unorthodox
关于 min-max 操作的支持,比如 _mm256_max_pd, _mm256_min_pd
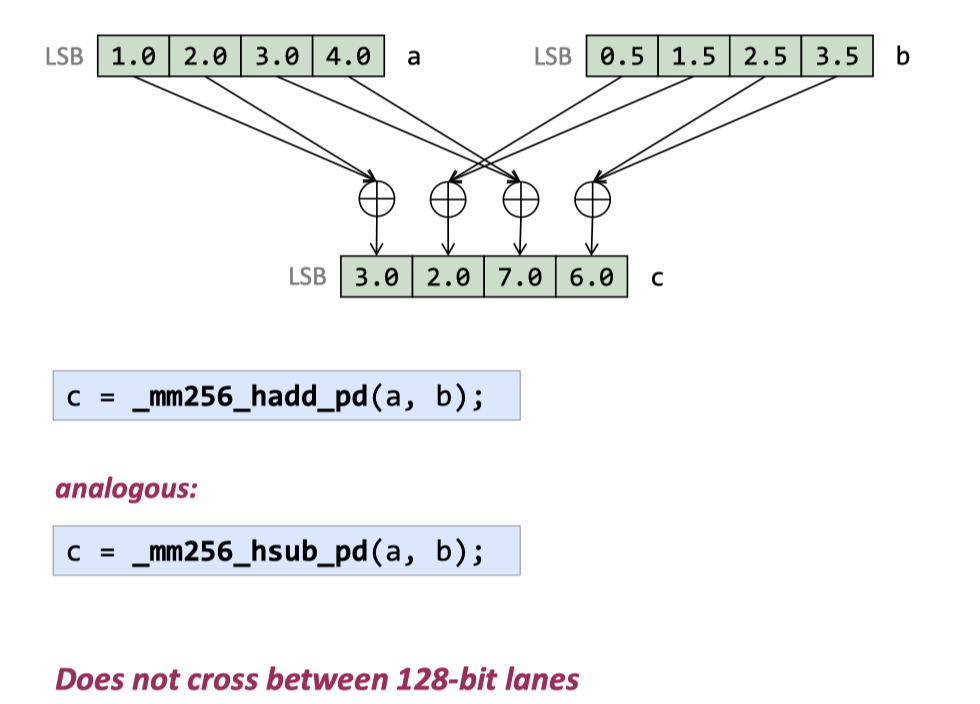
addsub
SSE3 和 AVX 中有,交错去 add / sub: _mm256_addsub_pd:
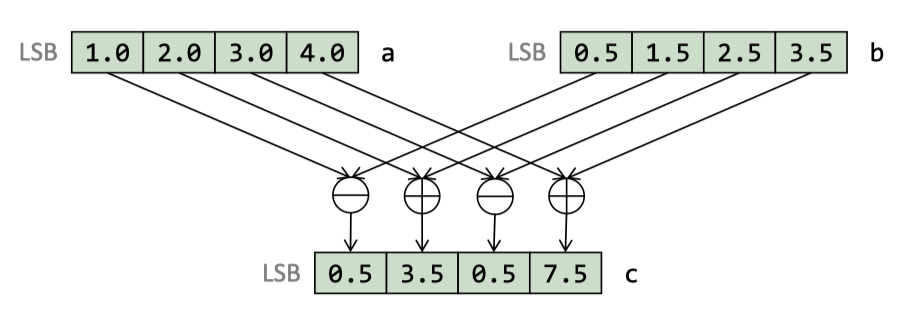
hadd/hsub ( Does not cross between 128-bit lanes )
相当于两个一组的去处理
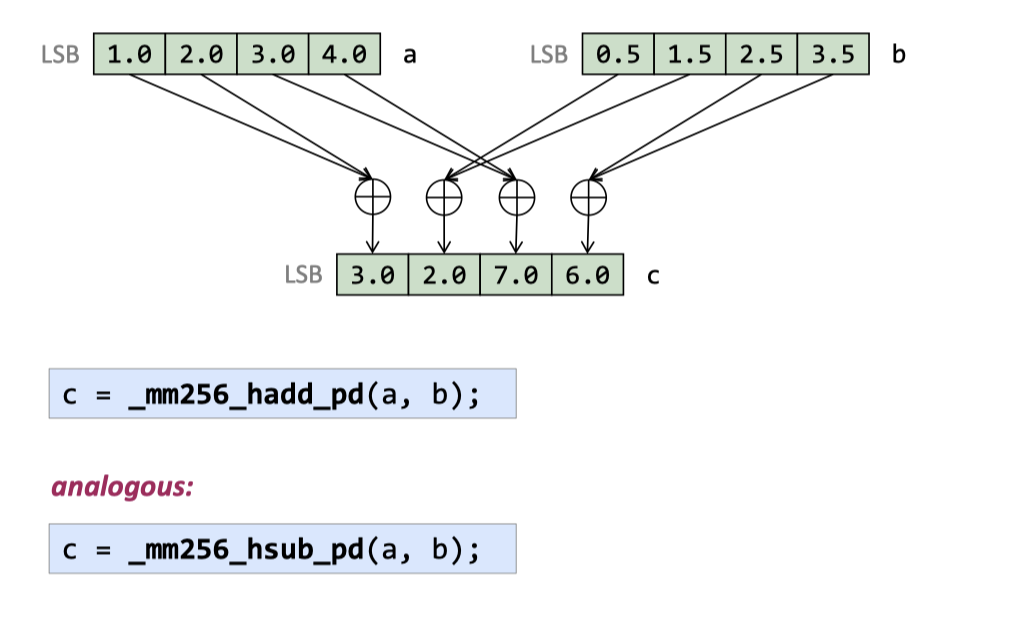
(The performance is not great, though.) 这块是用来执行这种任务的:https://mathworld.wolfram.com/ComplexMultiplication.html
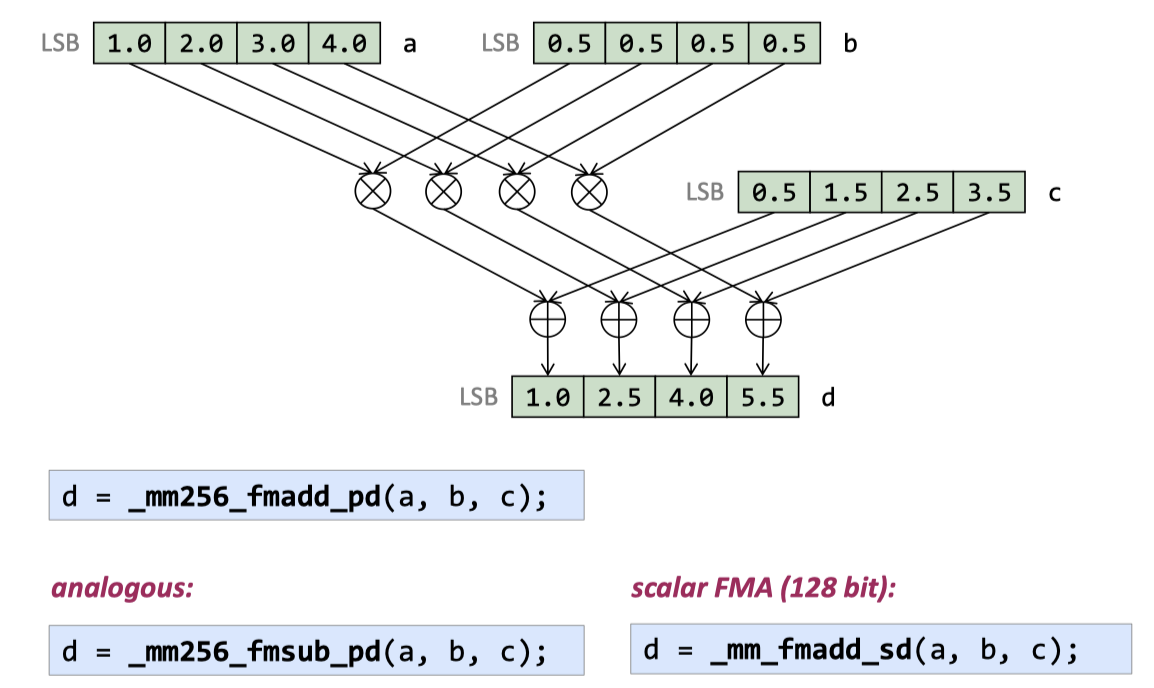
fma ( fmsub )
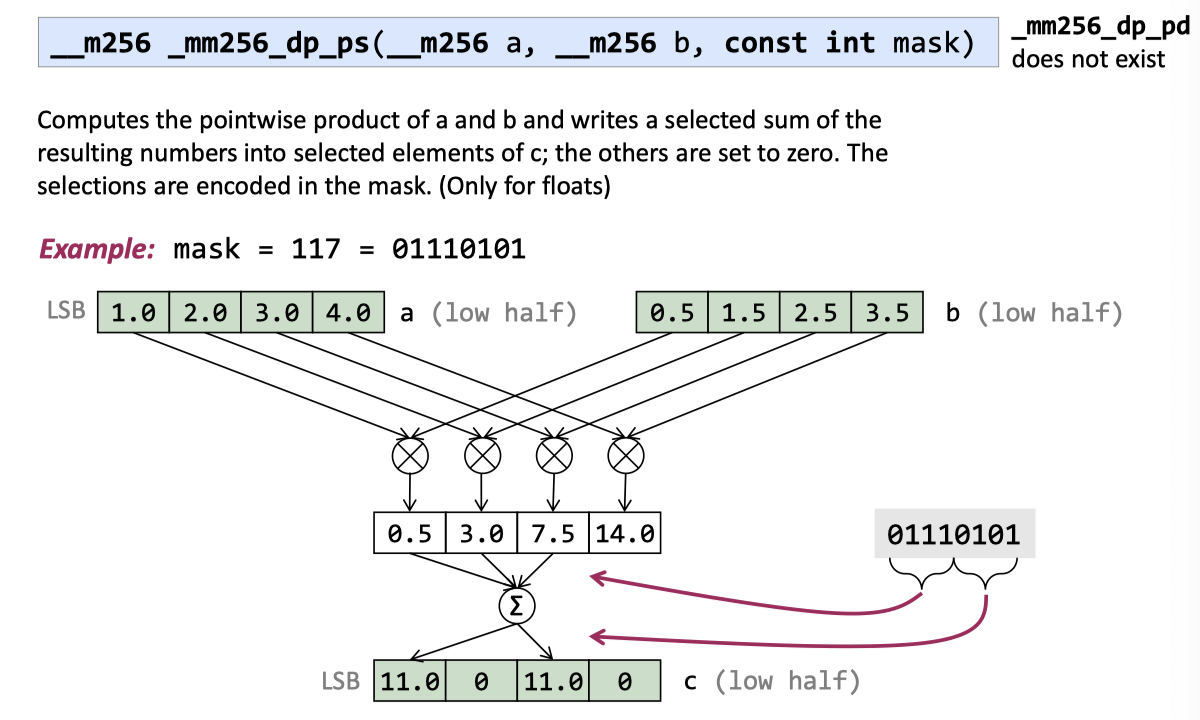
Dot product ( 单精度 )
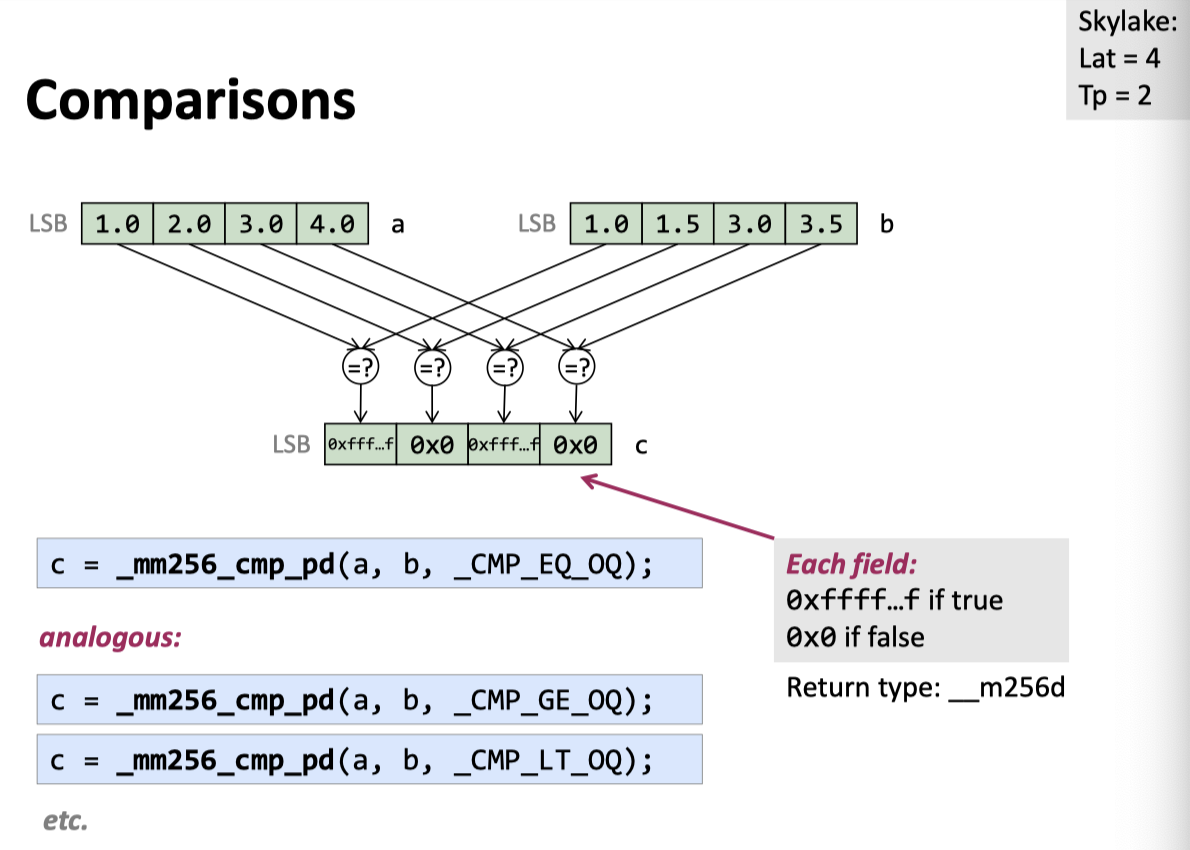
Comparisons (Return type: __m256{} with LSB)
关于比较的,包括 <, >, ≤, ≥, ≠ 在内的基础操作. 这里返回的也是个 __m256{} 寄存器,如果是 true,对应位就是 11..., 否则是 00...
Casting / Converting
并非指令的转型
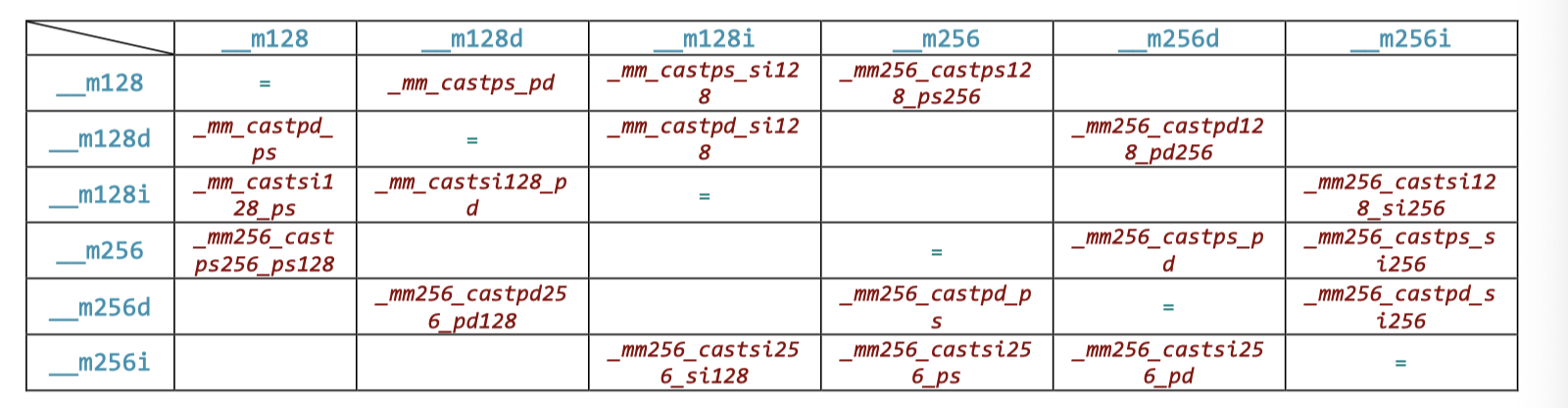
All these intrinsics compile into no instructions, so they’re practically free performance wise. They don’t change bits in the registers, so 32-bit 1.0f float becomes 0x3f800000 in 32-bit lanes of the destination integer register. When casting 16-byte values into 32 bytes, the upper half is undefined.
实际上,这里的 cast 可以说可能只是一个类型转型(类似 reinterpret-cast)
类型转换
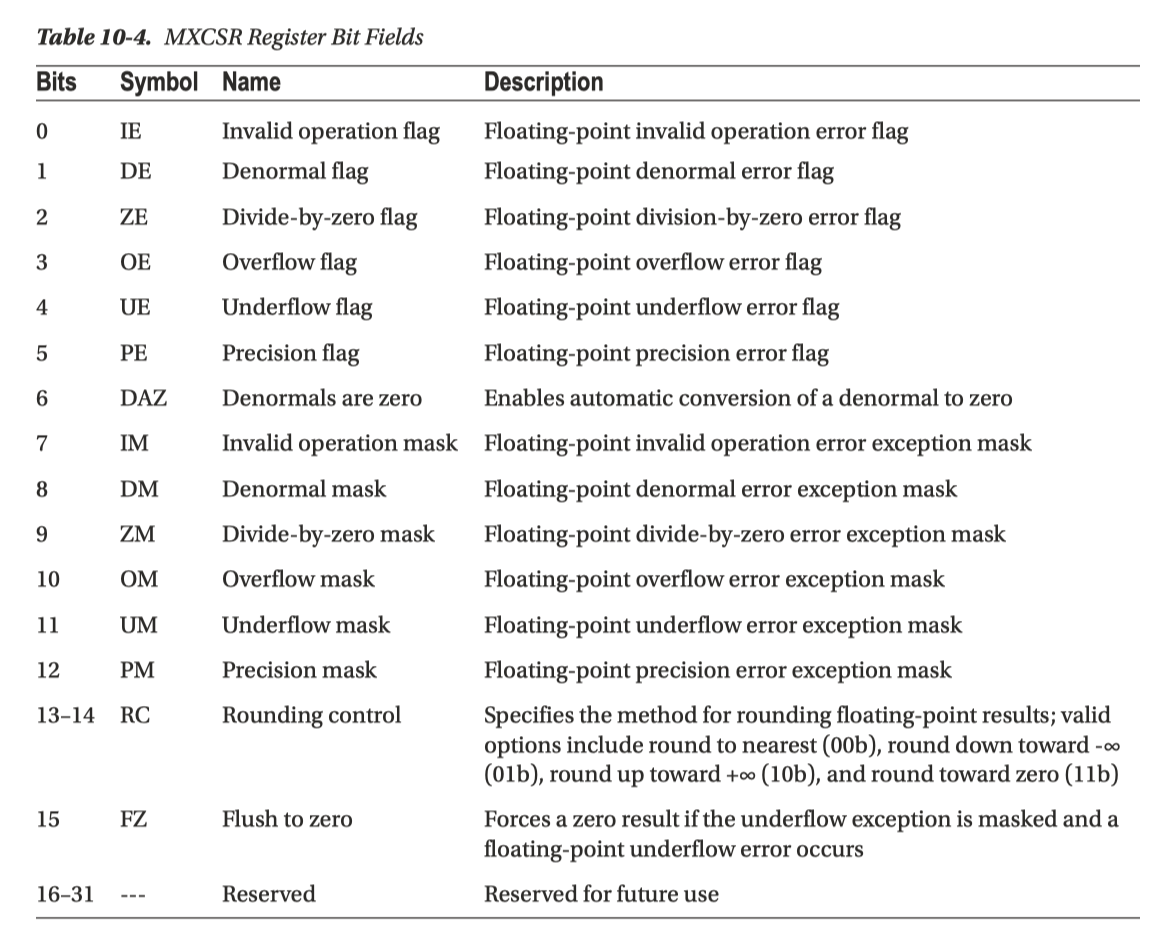
MXCSR 寄存器控制一些相关的模式

上面就有相关的转型,基本格式还是 cvt{Src}_{Dst}
Shuffles
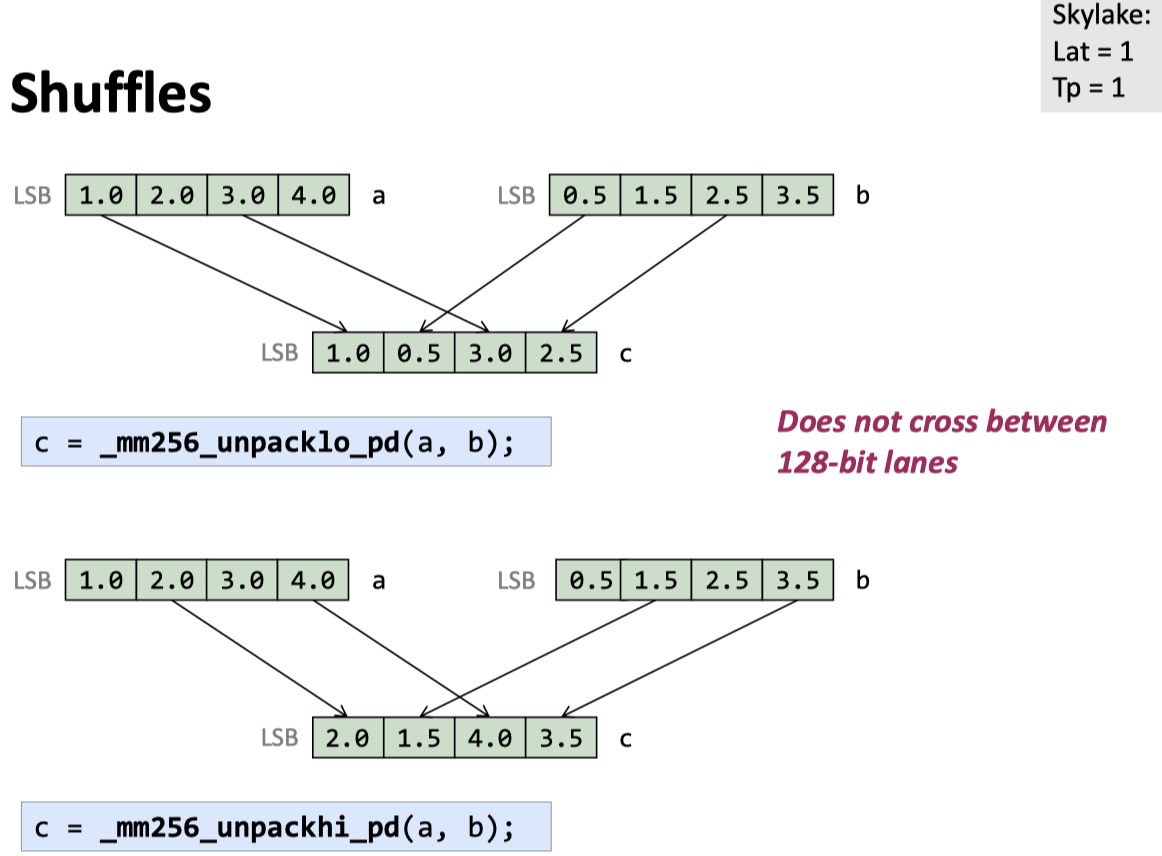
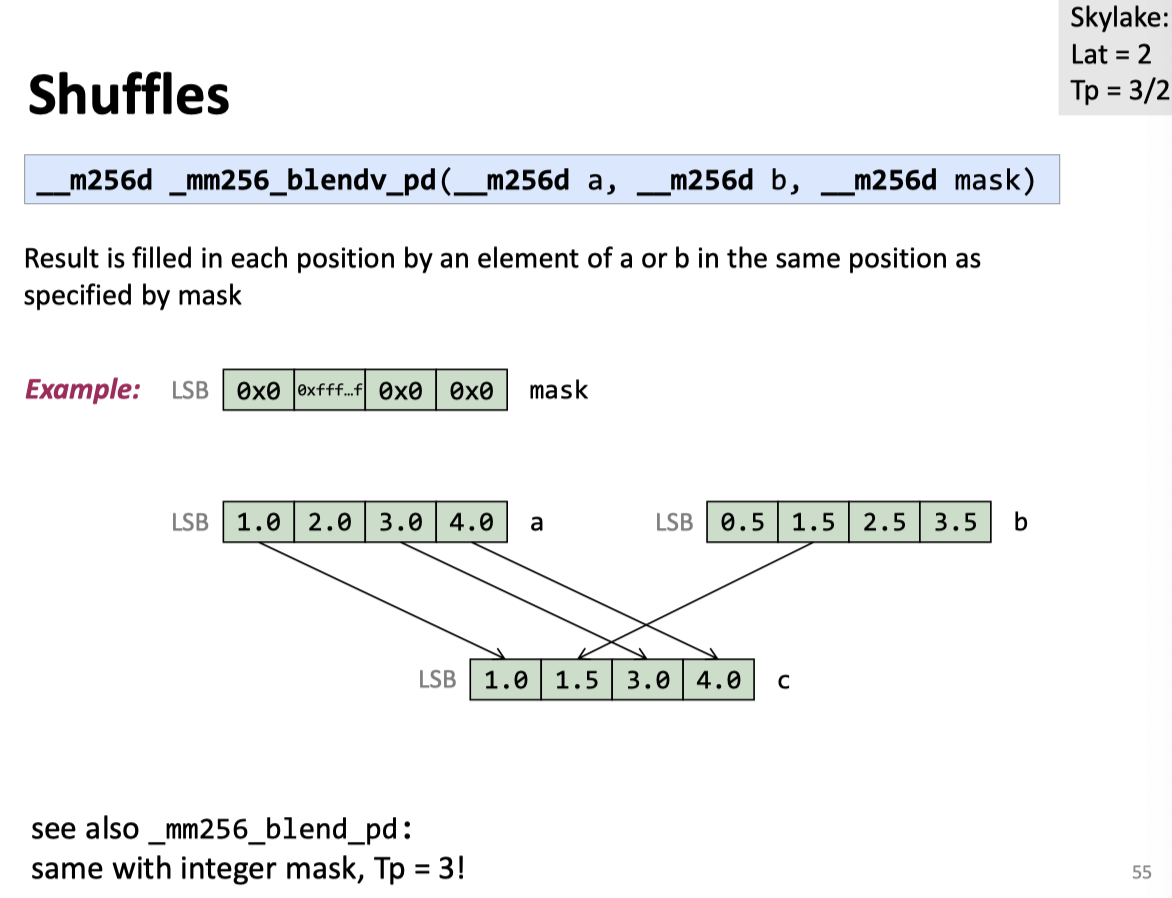
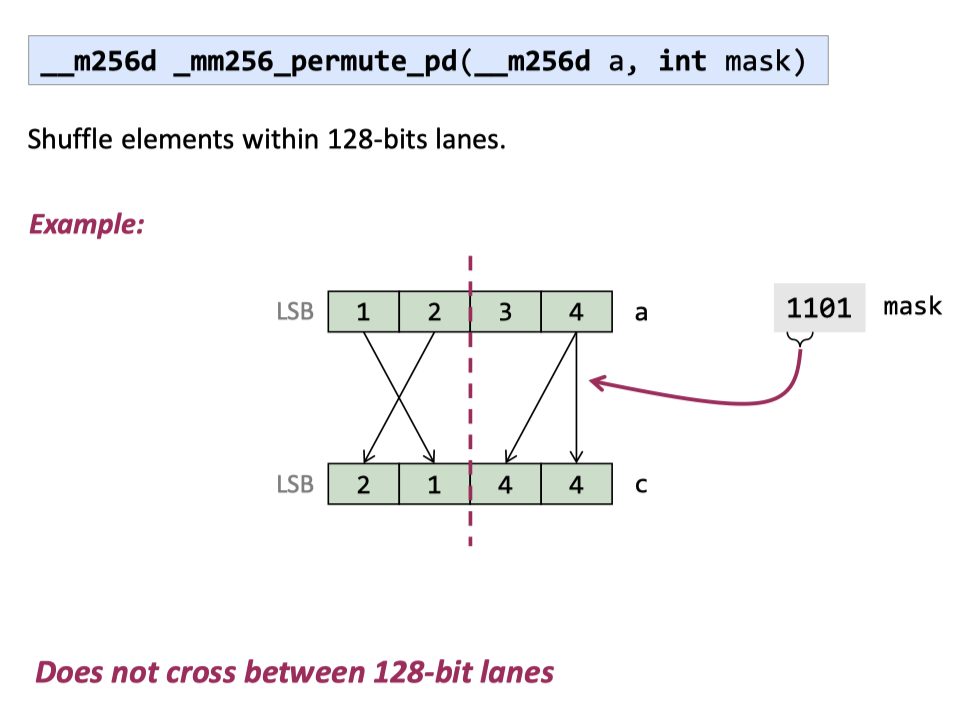
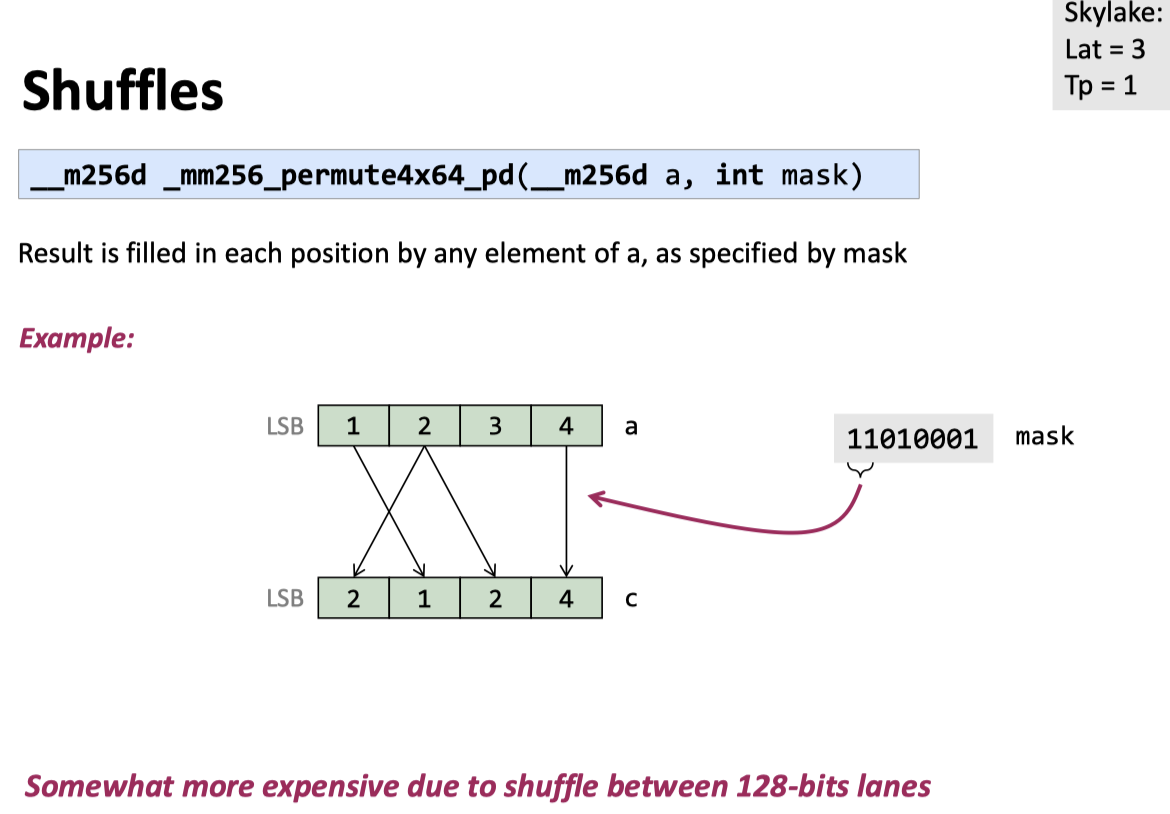
关于 cross-lane 操作,这里还有一些 notes: https://stackoverflow.com/questions/47646238/do-128bit-cross-lane-operations-in-avx512-give-better-performance
References
- https://acl.inf.ethz.ch/teaching/fastcode/
- Modern Parallel Programming with C++ and Assembly Language
- http://const.me/articles/simd/simd.pdf
- https://github.com/rust-lang/portable-simd/blob/master/beginners-guide.md