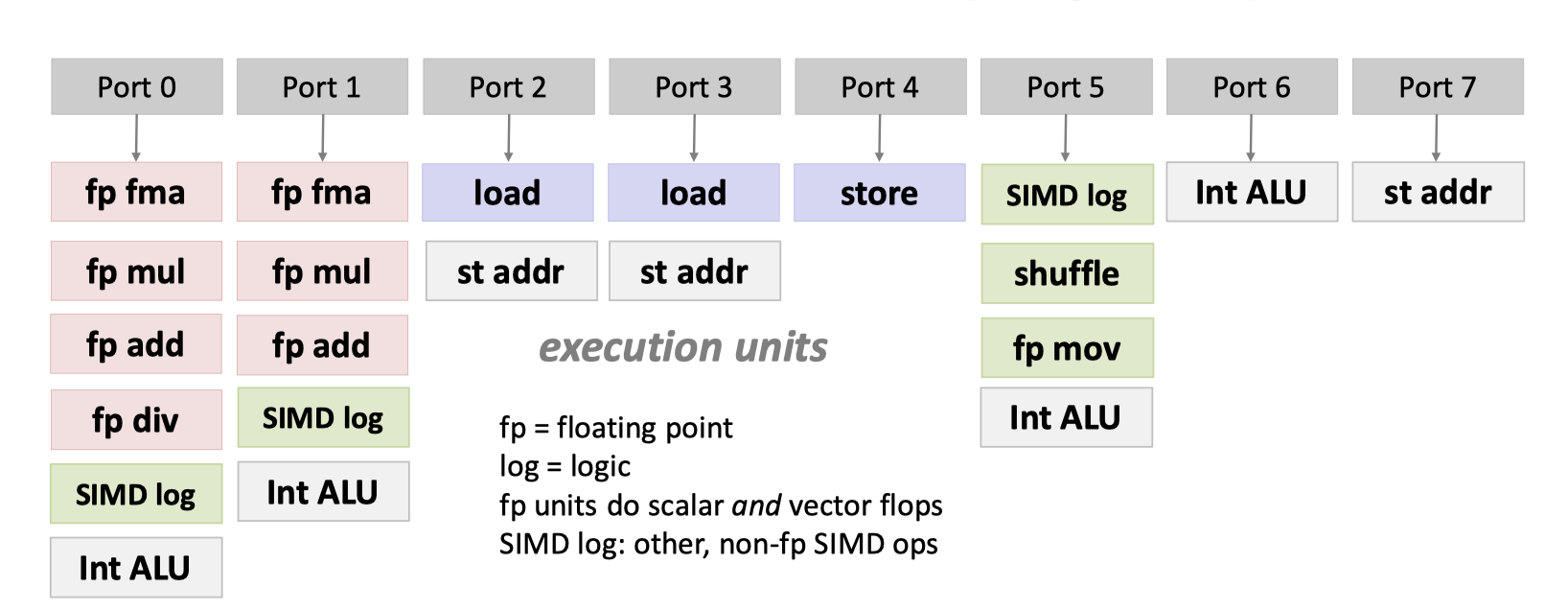
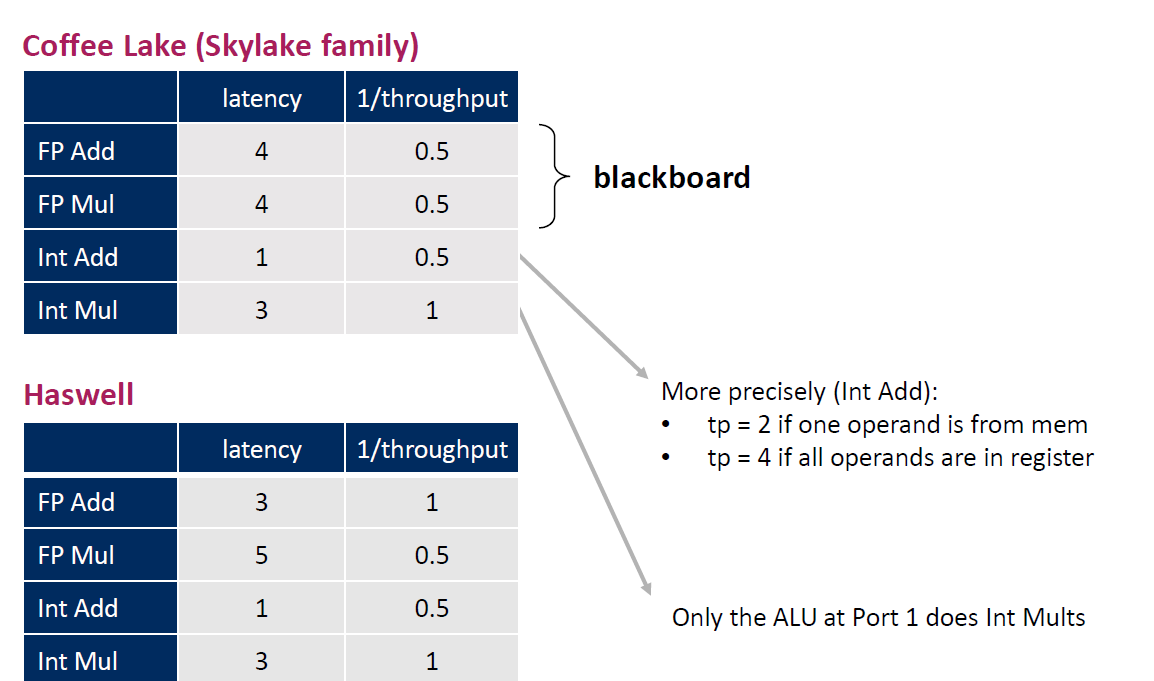
上一期( https://blog.mwish.me/2022/11/05/x86-and-SIMD-programming/ ) 介绍了 x86 和 SIMD 的背景,同时介绍了 x86 Skylake 的架构。这文章写了都整整一年了(我也太摆烂了),所以我们还是需要回顾一下。x86 CPU 上面通过 decode 代码,把 x86 CISC 指令转化为 RISC 的 micro-arch 的指令。SuperScalar 的指令被解析后,里面有一组 Port 来执行对应的代码。这样我们的 CPU 可以 OoO 的执行。理论上给定一组代码和 Port 甚至可以算出一个代码执行的上限。
当然上面这里说的还是一个理论的上限值,实际上在上篇文章中,我们还了解了如何衡量一个应用是 bounded by CPU 还是访存。
在访问内存上,有 L1 — L2 — L3 的 Cache。这里 L1 在每个 CPU 上,L3 则可能涉及一些共享。笔者这里并不做特别细的介绍是因为这块并不属于 ISA,而是 microarch 之类或者实现上应该管的一部分。Prefetch 本身也和高性能的代码相关,但是这个更多只能用来解释。
这一节我们介绍的是如何写出高性能的 “scalar” 代码,说是 scalar 主要是因为在这里我们不会用到 SIMD 的指令。取而代之的是如何利用 superscalar 之类的性质,写出高性能的 Scalar Code。我们首先会介绍从 fastcode 的代码和生产的代码来分析这块的性能。下一节也会介绍 LLVM 的 Auto-vectorize 和 编译器的优化。
Fast Scalar Code 代码本身可能和 code 执行的汇编数量、访问的负载之类的东西有关。根据我们上篇文章的知识,指令的延迟、吞吐都是不一样的。此外,我们还知道了所谓 Super Scalar 的大致语义。那么,尽管不同架构代码可能 Port 之类的数量会有不同,但是这对我们写出快的 scalar 代码是有指导意义的。
关于乱序如下面所述
1 2 3 t2 = t0 + t1 t5 = t4 * t3 t6 = t2 + t5
那么 这里 (1) (2) 行的其实可以串行执行。考虑到 Memory Model,Store Load 可能会有一些影响,但是很多东西也走不到 Memory ( 比如看这个链接 https://stackoverflow.com/questions/29722676/atomic-operations-on-superscalar-processor ,实际上一些 Atomic 操作的时候,CPU 也仿佛不是 Super Scalar 的了)
课程举了个 Sample 来介绍如何写 fast scalar 的代码,sample 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template < typename ArrowType, typename Op> void BenchmarkOp(benchmark::State& state) { using CType = typename ArrowType::c_type; auto rand = random::RandomArrayGenerator(kSeed); auto valueArray = std::static_pointer_cast< NumericArray< ArrowType>> (rand.Numeric< ArrowType> (4096 * 16 , 0 , 114514 )); int64_t length = valueArray- > length(); auto values = valueArray- > raw_values(); for (auto s : state) { CType sum = 0 ; for (int64_t i = 0 ; i < length; i+ + ) { sum = Op::call (sum, values [i]); } benchmark::DoNotOptimize(sum); } }
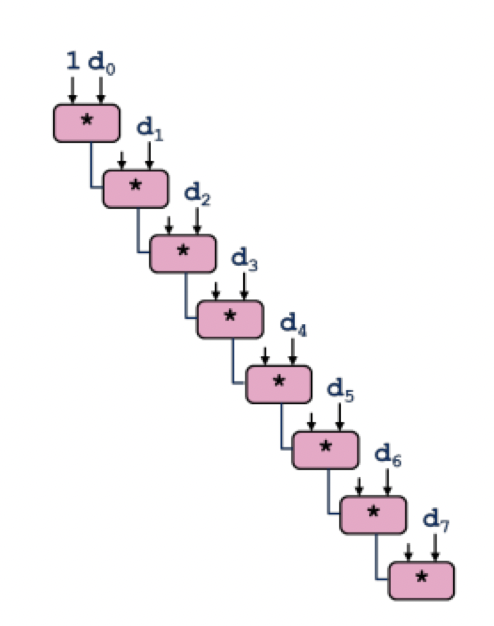
这个代码执行如下图所示,可以说是 Scalar Code:
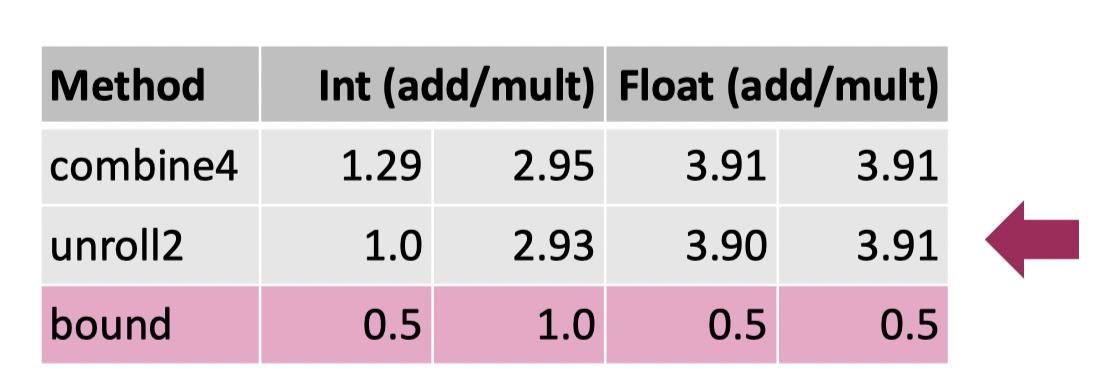
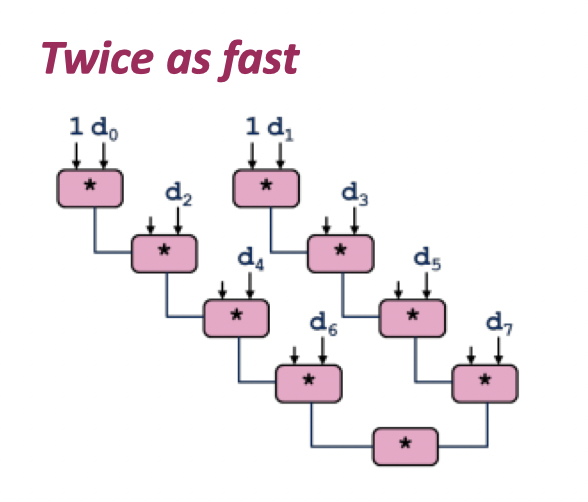
这里的 sequential op 导致流水线并行没有被很好的利用上,都是线性执行这些代码。下面这里提供了 unroll2 的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 template <typename ArrowType, typename Op>void BenchmarkOp2 (benchmark::State& state) using CType = typename ArrowType::c_type; auto rand = random::RandomArrayGenerator (kSeed); auto valueArray = std::static_pointer_cast<NumericArray<ArrowType>>(rand.Numeric <ArrowType>(4096 * 16 , 0 , 114514 )); int64_t length = valueArray->length (); auto values = valueArray->raw_values (); for (auto s : state) { CType sum = 0 ; int64_t i = 0 ; for (; i < length; i += 2 ) { sum = Op::call (Op::call (sum, values[i]), values[i + 1 ]); } if (i < length) { sum = Op::call (sum, values[i]); } benchmark::DoNotOptimize (sum); } }
这里的操作相当于把原先循环中一次改成了两个 OP,那么这个会怎么样呢?答案是没怎么变化。
接下来展示 Separate Accumulators 的版本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 template <typename ArrowType, typename Op>void BenchmarkOp2SA (benchmark::State& state) using CType = typename ArrowType::c_type; auto rand = random::RandomArrayGenerator (kSeed); auto valueArray = std::static_pointer_cast<NumericArray<ArrowType>>(rand.Numeric <ArrowType>(4096 * 16 , 0 , 114514 )); int64_t length = valueArray->length (); auto values = valueArray->raw_values (); for (auto s : state) { CType sum0 = 0 ; CType sum1 = 0 ; int64_t i = 0 ; for (; i < length; i += 2 ) { sum0 = Op::call (sum0, values[i]); sum1 += Op::call (sum1, values[i + 1 ]); } if (i < length) { sum0 = Op::call (sum0, values[i]); } benchmark::DoNotOptimize (Op::call (sum0, sum1)); } }
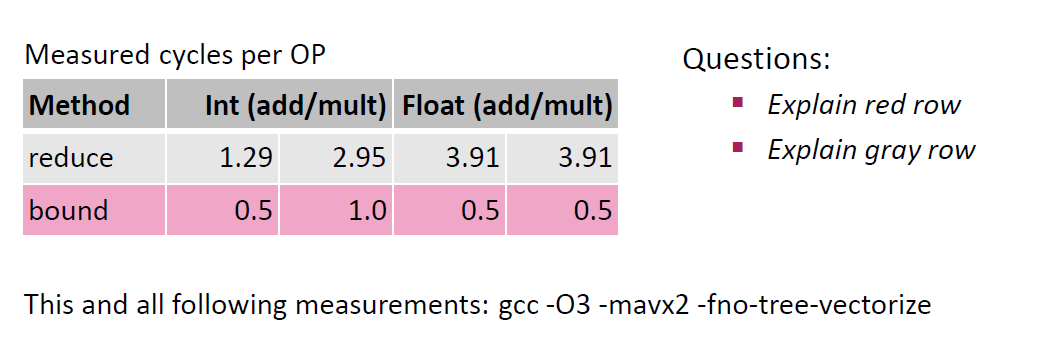
这里可以得到一定的提升,但是肯定不会超过性能上限。此外,对于浮点数来说,这样的操作可能会略微变更对应的结果 。
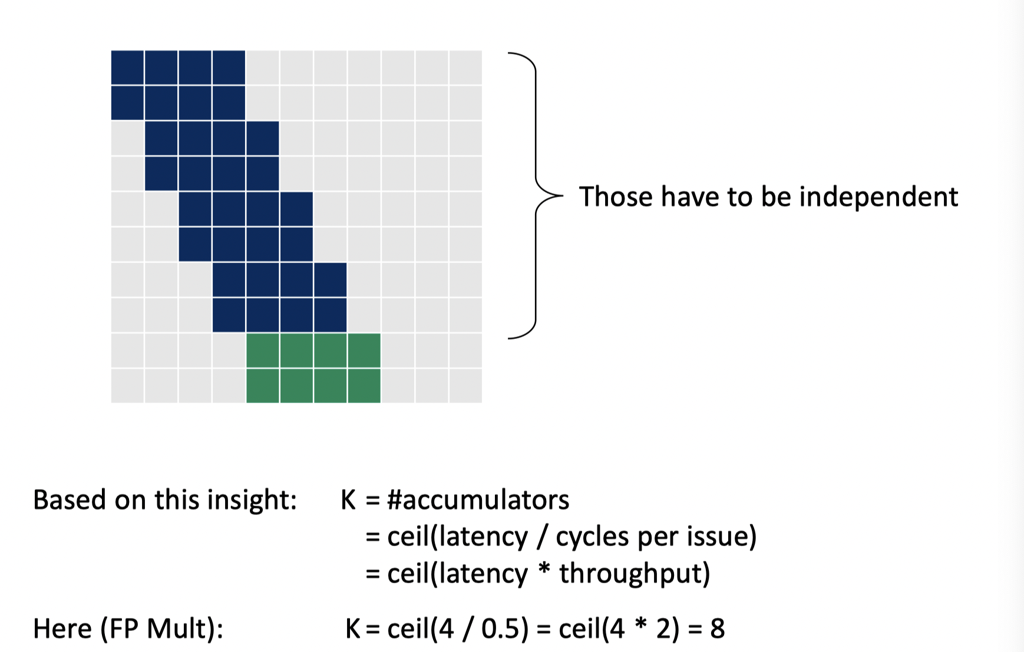
本质上,这里可以算出来一个并行度,然后来优化对应的操作:
当然,这段其实是个理论分析,某种程度上感觉至少我在 LLVM17 开 O3 编译器会帮忙做很多事情,除了浮点数都会优化到差不多的性能,感兴趣的也可以拿我们上面的代码去跑一下,感受一下这块的具体内容。
Parquet BYTE_STREAM_SPLIT 加速 下面这里我们再以 BYTE_STREAM_SPLIT 为类型,分析一下 Scalar 代码怎么提速。这是 Parquet 标准中一种浮点类型的无损浮点 Encoding。它要结合压缩来使用。它的算法大概是:
对于 k Bytes 的 n 个浮点数拆成 k 个 n bytes 的 Stream
第一个 k Bytes 的浮点数,内容第一位写在第一 Byte;第二位写在第二个 Stream 的第一 byte ,以此类推
如果你觉得上面不清晰,可以直接看原文:https://github.com/apache/parquet-format/blob/master/Encodings.md#byte-stream-split-byte_stream_split--9
这块原先的代码非常好懂:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 template <typename T>void ByteStreamSplitEncodeScalar (const uint8_t * raw_values, const int64_t num_values, uint8_t * output_buffer_raw) constexpr size_t kNumStreams = sizeof (T); for (size_t i = 0U ; i < num_values; ++i) { for (size_t j = 0U ; j < kNumStreams; ++j) { const uint8_t byte_in_value = raw_values[i * kNumStreams + j]; output_buffer_raw[j * num_values + i] = byte_in_value; } } } template <typename T>void ByteStreamSplitDecodeScalar (const uint8_t * data, int64_t num_values, int64_t stride, T* out) constexpr size_t kNumStreams = sizeof (T); auto output_buffer_raw = reinterpret_cast <uint8_t *>(out); for (int64_t i = 0 ; i < num_values; ++i) { for (size_t b = 0 ; b < kNumStreams; ++b) { const size_t byte_index = b * stride + i; output_buffer_raw[i * kNumStreams + b] = data[byte_index]; } } }
这段代码在 CPU 上和内存上其实都并不高效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 for (int stream = 0 ; stream < width; ++stream) { uint8_t * dest = dest_streams[stream]; for (int64_t i = 0 ; i < nvalues; ++i) { dest[i] = src[stream + i * width]; } } for (int stream = 0 ; stream < width; ++stream) { const uint8_t * src = src_streams[stream]; for (int64_t i = 0 ; i < nvalues; ++i) { dest[stream + i * width] = src[i]; } }
新的算法在末端会至少以单个 “STREAM” 为单位去读写,避免一些逐个 Value 访问 Stream 的时候把 Cache 搞进来又搞出去
当然这里不止是这套逻辑,这里把 Encoding 的逻辑拆成了下面的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 inline void DoSplitStreams (const uint8_t * src, int width, int64_t nvalues, uint8_t ** dest_streams) constexpr int kBlockSize = 32 ; while (nvalues >= kBlockSize) { for (int stream = 0 ; stream < width; ++stream) { uint8_t * dest = dest_streams[stream]; for (int i = 0 ; i < kBlockSize; i += 8 ) { uint64_t a = src[stream + i * width]; uint64_t b = src[stream + (i + 1 ) * width]; uint64_t c = src[stream + (i + 2 ) * width]; uint64_t d = src[stream + (i + 3 ) * width]; uint64_t e = src[stream + (i + 4 ) * width]; uint64_t f = src[stream + (i + 5 ) * width]; uint64_t g = src[stream + (i + 6 ) * width]; uint64_t h = src[stream + (i + 7 ) * width]; #if ARROW_LITTLE_ENDIAN uint64_t r = a | (b << 8 ) | (c << 16 ) | (d << 24 ) | (e << 32 ) | (f << 40 ) | (g << 48 ) | (h << 56 ); #else uint64_t r = (a << 56 ) | (b << 48 ) | (c << 40 ) | (d << 32 ) | (e << 24 ) | (f << 16 ) | (g << 8 ) | h; #endif arrow::util::SafeStore (&dest[i], r); } dest_streams[stream] += kBlockSize; } src += width * kBlockSize; nvalues -= kBlockSize; } for (int stream = 0 ; stream < width; ++stream) { uint8_t * dest = dest_streams[stream]; for (int64_t i = 0 ; i < nvalues; ++i) { dest[i] = src[stream + i * width]; } } }
对于每个 Block,Block Size 会是 8 的倍数
Block 内,这里会 8 个一组,把 8 个浮点数的 Byte 写到一个 Stream 里面
这里就是本节介绍的操作方式,可以看到,这里有几个 Trick:
分离访存操作和 CPU 操作
对于同质大量计算,高效的处理所有值
References
https://github.com/apache/arrow/pull/38529 LLVM Auto-Vectorize https://llvm.org/docs/Vectorizers.html