SIGMOD'14: Morsel-Driven Parallelism
本文由 TUM 发表于 SIGMOD’14. 在前一篇文章中提到,VLDB’11 的时候,TUM 引入了 LLVM Codegen 和 Data Centric 的 Push-based Execution。在那篇文章中,介绍的是从一个 Volcano Model 转化成一个 Push-based exec 的 Plan,并没有介绍怎么在里面处理并发,生成的东西可以理解成是串行执行的
本论文可以视作上一篇论文的后续,即在 “data centric” 的执行下,怎么去根据数据来做查询切分/并发。在这套架构下,数据被切分成 Morsel 然后被 CPU 线程调度执行(论文其实没那么细介绍 TableScan?)。此外,文章也考虑了一些现代 CPU 的特性,比如 NUMA。Morsel 因为是data-centric 的,所以执行这点还比较自然(实际上某种意义上说,tp 数据库很多地方没 TPC 之类的东西还不太好做)。这里允许把输入数据切分成 Morsels,根据机器的执行状况来定义 DOP (degree of parallelism)而不用在 Plan 之类的地方写死,由 Runtime 来做动态的调度甚至变更执行期的 DOP(当然,可能有一些 colocate-join 之类的不知道要不要特殊处理)。
在新硬件上,本文考虑了新的 NUMA 硬件。NUMA 可能会有多个不对等的 Memory Controller,文章的 Point 很有意思:(这里考虑的主要是 locality 部分)
In essence, the computer has become a network in itself as the access costs of data items varies depending on which chip the data and the accessing thread are located. Therefore, many-core parallelization needs to take RAM and cache hierarchies into account. In particular, the NUMA division of the RAM has to be considered carefully to ensure that threads work (mostly) on NUMA-local data.
在一般数据库中,算子内部的并行可能需要一个 Exchange Operator 来切分计算,并需要一个 Optimizer 或者什么阶段定死的。这篇论文称其为 plan-driven 的并发调度。而相对的,本文提出了一种 Morsel Driven 的调度,下图是三个 Join 执行的情况:
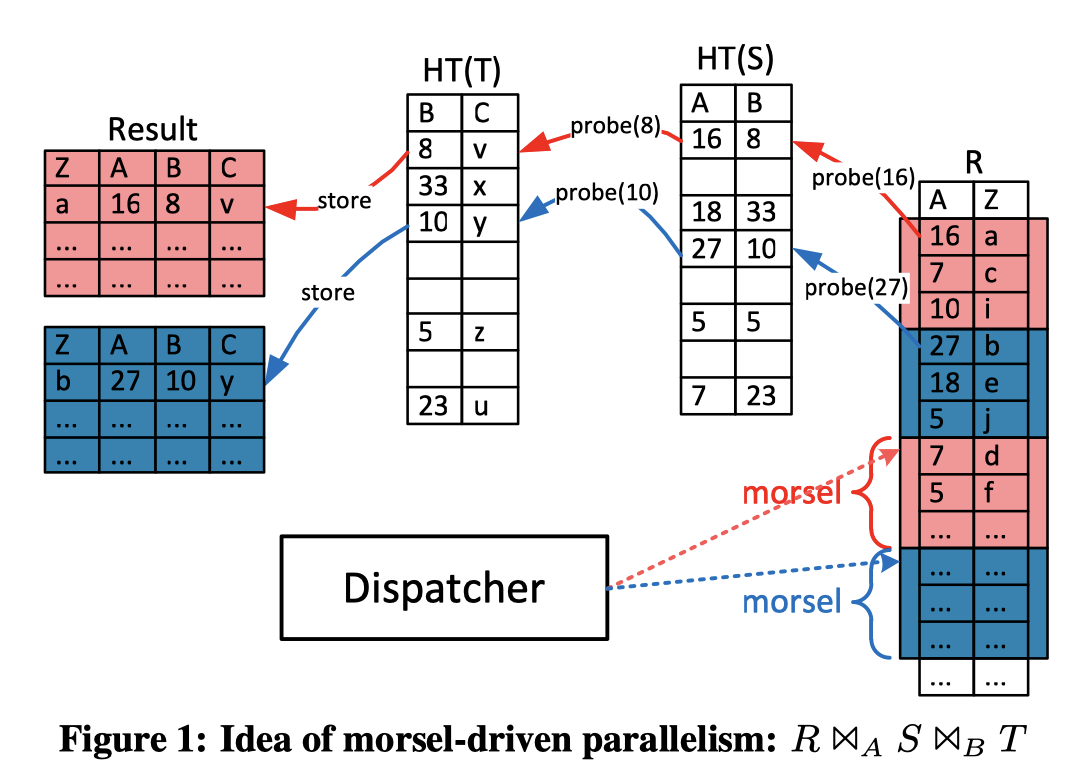
在这个系统上,线程固定数量并绑核。
Morsel Driven 的调度相对来说需要一个半全局的状态,数据从输入拿到一份内存,然后丢给输出的 Buffer。虽然这里是全局的状态(也允许 work-stealing),但是本身来说因为调度会考虑 locality,所以认为这块的 locality 相当好。当然这里 Operator 的实现也要进行一些改造来适配 Morsel。
本论文的内容大概包括:
- Morsel-driven 的查询执行框架
- 适配 Morsel 执行框架的并行算子实现
- NUMA 特性的利用探讨
Morsel-Driven Execution
Figure2 展示了一个多表读取 -> Join 的执行流程:
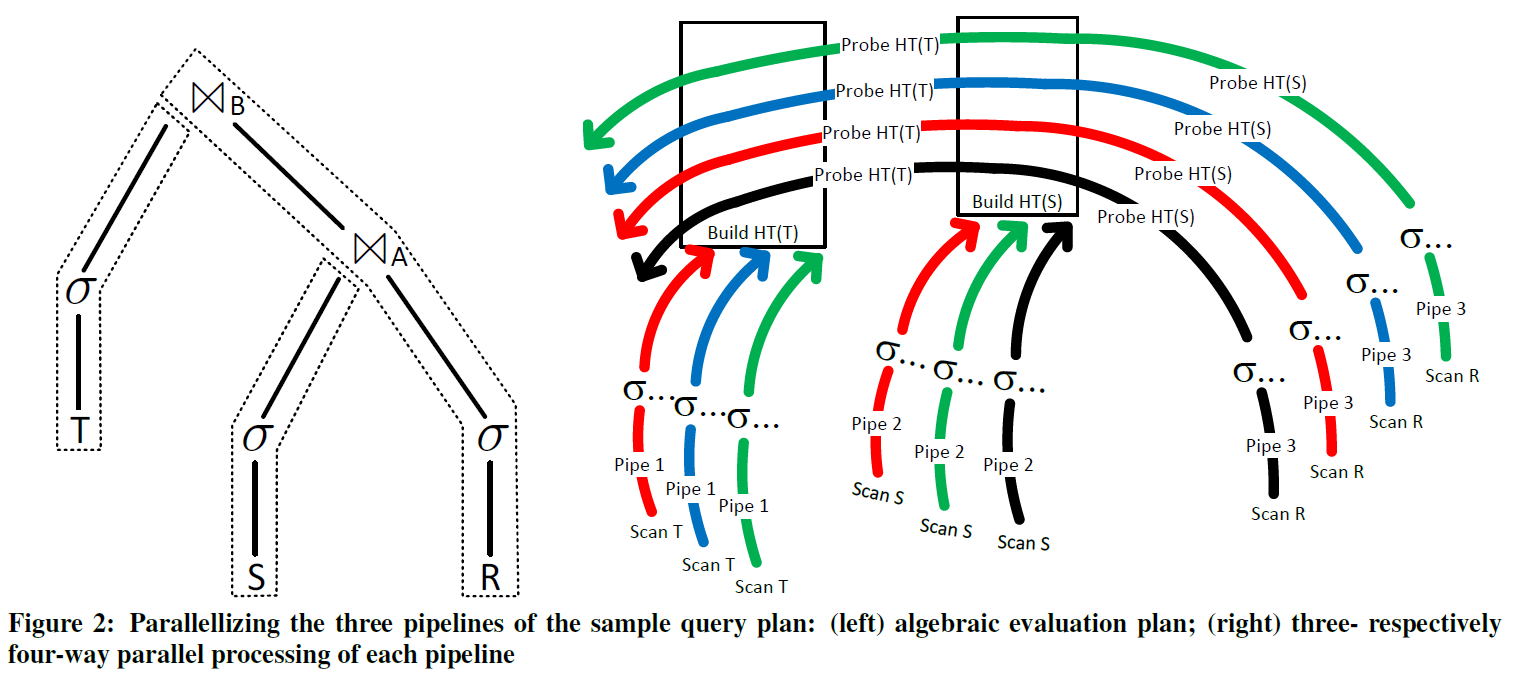
执行方式在前一篇论文里提到,这里不再赘述(值得一提的是,HyPer 这里也使用了 vectorize 的策略)
论文引入了组件 QEProject (Query Engine Project?),把 Pipeline 转化为 dispatcher (用 Velox 类似的话说,是分给不同的 Driver 来执行?)在论文的执行中:
- Probe 只有在 build 完成之后才能开始执行。
- 每个 Pipeline 里面 QEProject 会切分等大的输入,当然这个可能造成输出大小不等大。
- Dop 的上限受系统线程的限制来防止对应的抢占。
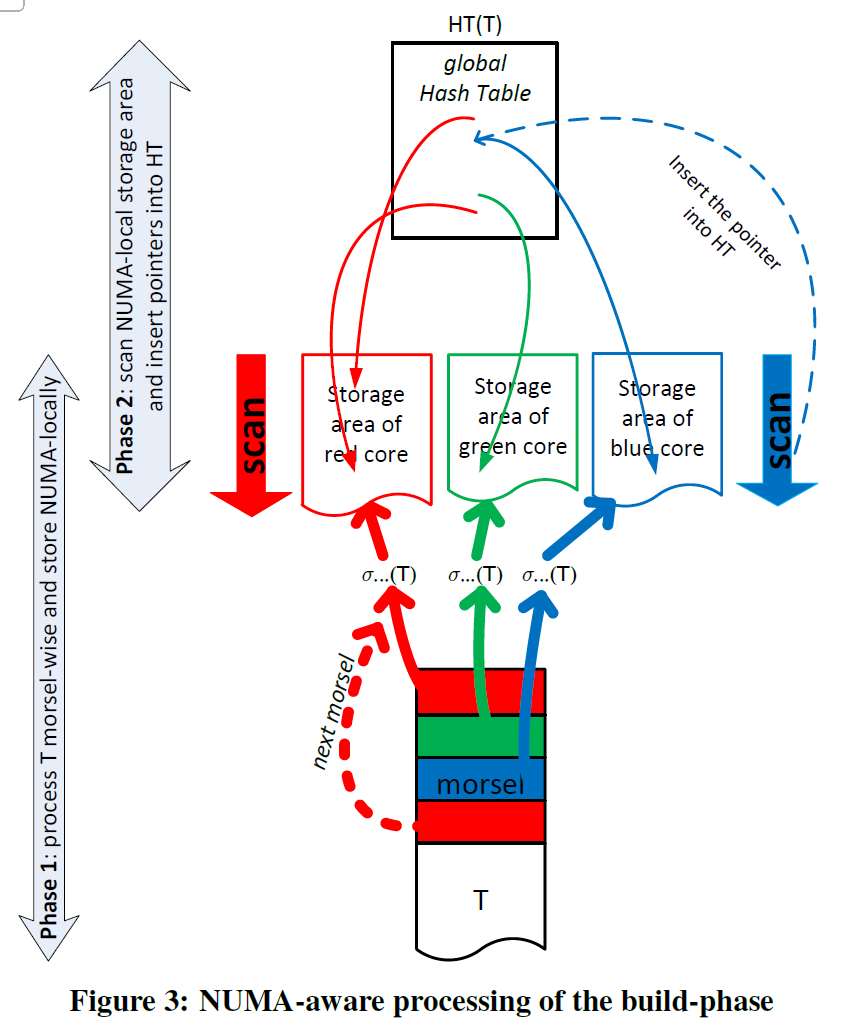
这里在 Scan 的时候会相当于有一个抢占,此外我们再看 Figure 3,考虑到本文这里因为并发,那么 hash build 的时候,如果由 Scan 线程直接插入的话,这里会有一部分的内存的问题:读写共享区域,甚至是 Hash Table 的扩容。于是这部分会把 Scan->Build 分成两个阶段:
- 在 Scan 阶段,数据从数据源 fetch 出来然后把 Filter 之后的数据推到 NUMA-Aware 的存储区域(在某个 NUMA 中来避免过多的同步、抢占开销)。如上图的 Storage Area 所示。这种情况下如果有 skew 的话,需要继续调度(在 DOP 小于切分的情况下),如红色执行流所示。
- 等 Scan -> Filter 完成后,这里会切换到 Hash Build Phase。因为 Scan 已经完成(并 Staging),这里会预先申请好 Hash Table。这里会完成并发插入的流程。此外因为会有并发插入,所以 TUM 作者把这个 Hash Table 弄成 Lock-free 的了。后文有介绍 HashTable 的实现
在两个 Scan 都够早晚 Hash Table 之后,这里就会构建 Probe Pipeline。
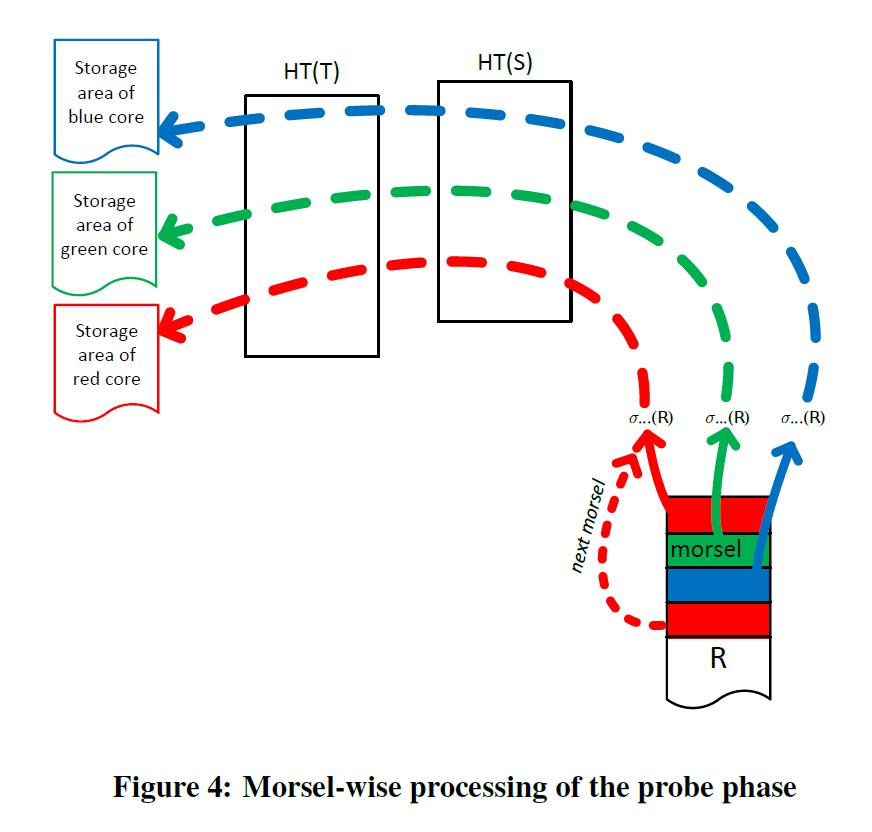
相对 volcano, 这些执行线程可能不用预先分配 dop,但是需要同步读写一些全局的(或者 numa 有关的)状态信息,因为这点,所以状态处理变得很重要。
Dispatcher: Scheduling Parallel Pipeline Tasks
如前文所说,HyPer Pipeline 调度的时候采用了 TPC 模型。那么在调度的时候,自己这个任务 Morsel 执行完了(Morsel Boundary)可能就要处理别的代码了。这里的 Dispatcher 并不是一个线程,而是一个逻辑的概念。
这里它预期的目标是:
- 有一定的 Locality,把任务尽量分配给本核心
- 能把线程资源尽量跑满(这里应该没有 Latency 相关的,因此应该考虑 Bandwidth 或者本文说的并发度就行?不过后文也有介绍一些优先级调度有关的东西。)
- 在 Locality 的情况下,避免过度 Skew。
下图是 Dispatcher 的逻辑概念图。可以看到:
- Dispatcher 维护了逻辑的 (Pending) Pipeline Job 和对应 Pipeline Job 上的
- 这个框架也能包含 Intra-query 并行,比如例子中两个 Hash Build 的 Scan 都能够被加入这个队列。
- 作者认为这块其实用处不是很大。因为这样估摸着你本身异构的任务也不是很多,大家不同的话,执行起来也比较容易 skew,同时这里还会影响 cache (我觉得即影响 icache 也影响 dcache)。所以感觉这个作用不是特别大。
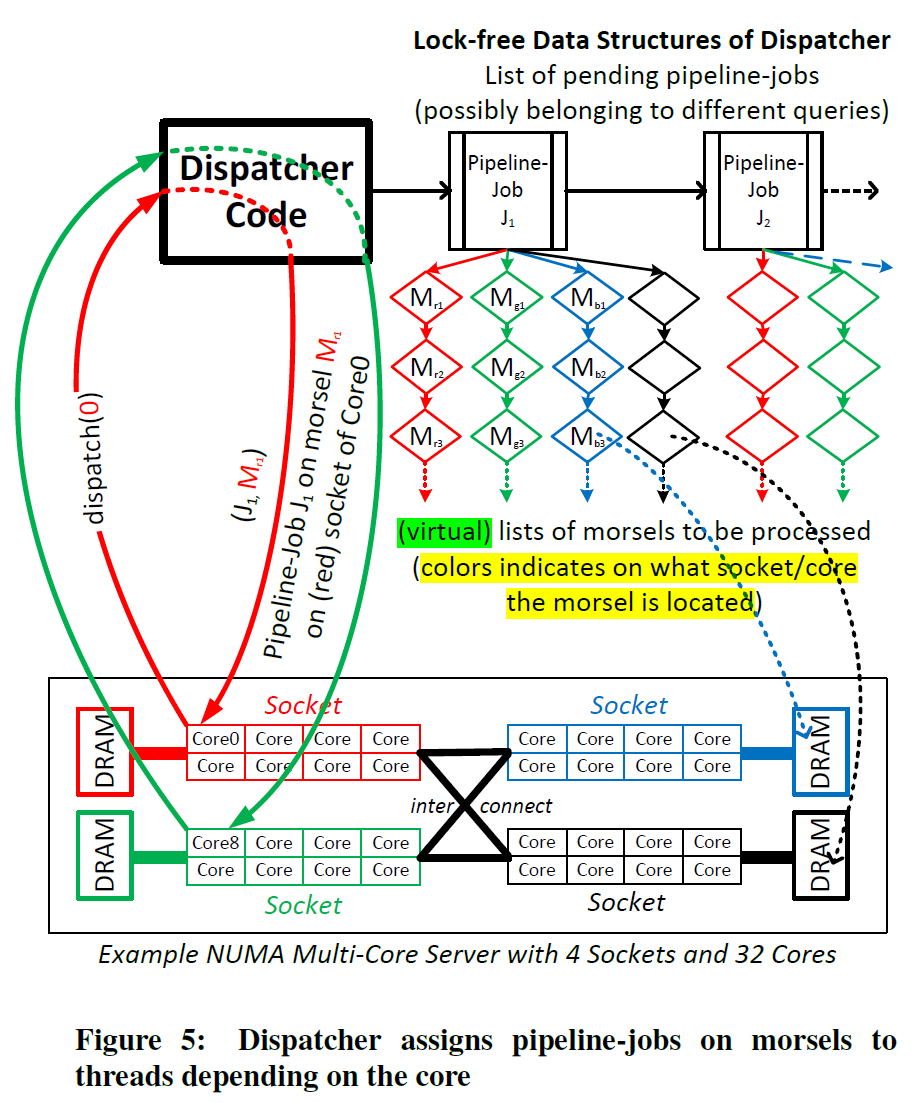
在论文写作时,HyPer 并没有什么内部优先级的概念,每个查询优先级相同。(他们说 Priority 当时已经在开发了,感觉这套也已经是比较成熟的东西了)。每个 NUMA 这里也会有相关的 List ,来协助调度。当本 core 没啥 Morsel 的时候,这也会做成 work-stealing 的(作者认为这块非常不频繁),work-stealing 之后,数据丢在执行线程的 Core 上。
Dispatcher 这东西实现成额外线程也不好,所以 Dispatcher 实际上是一套静态的 code,由 worker thread 在 Morsel Boundary 执行。这里还允许 query canceling,因为 dispatcher 是个全局状态,在全局状态设置就特么行了。
Morsel Size
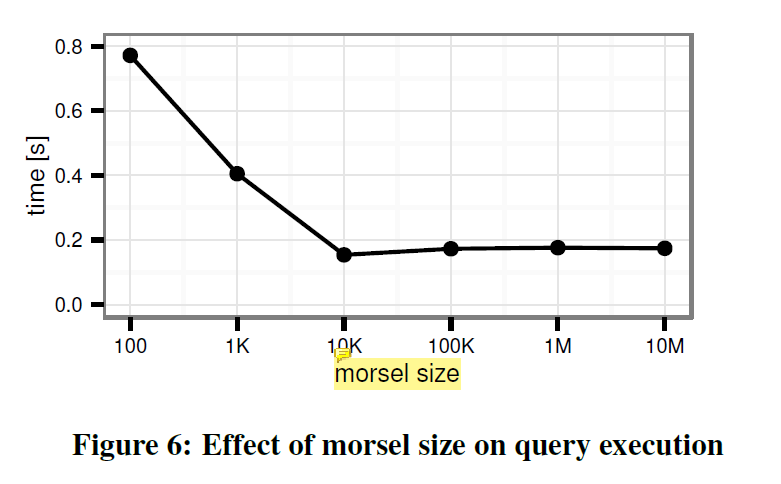
论文提到了个很好玩的东西:
there is no performance penalty if a morsel does not fit into cache.
Morsel 只是论文拆分任务的单元,和 Vectorize Batch Size 有关但并不绝对相关,一个 Morsel 甚至可以分成多个 Batch 来执行并大于 Cache-Size。所以 Morsel 大小就变成了调度的单元(当然潜台词是 Morsel 肯定要不比 Vectorize Batch 小,哈哈…):
- Morsel 小会导致多次调度,影响全局调度器,增加同步次数
- Morsel 大会导致 skew
Parallel Operator Details
如果需要在 Morsel 上高效执行,那么 Operator 本身也需要是一个高效的并发执行算子,它也要能接收 Batch 的数据。论文介绍了 Hash Join / Partition (Scan) / Grouping / Agg / Sorting 的对应的实现。这些实现可能是互相相关的,比如 Hash Join 本身可能和 Partition 会有关系(一些行为依赖 Scan 提供 Join 的两表的性质),会根据切分来高效的推进 Scan。
Hash Join
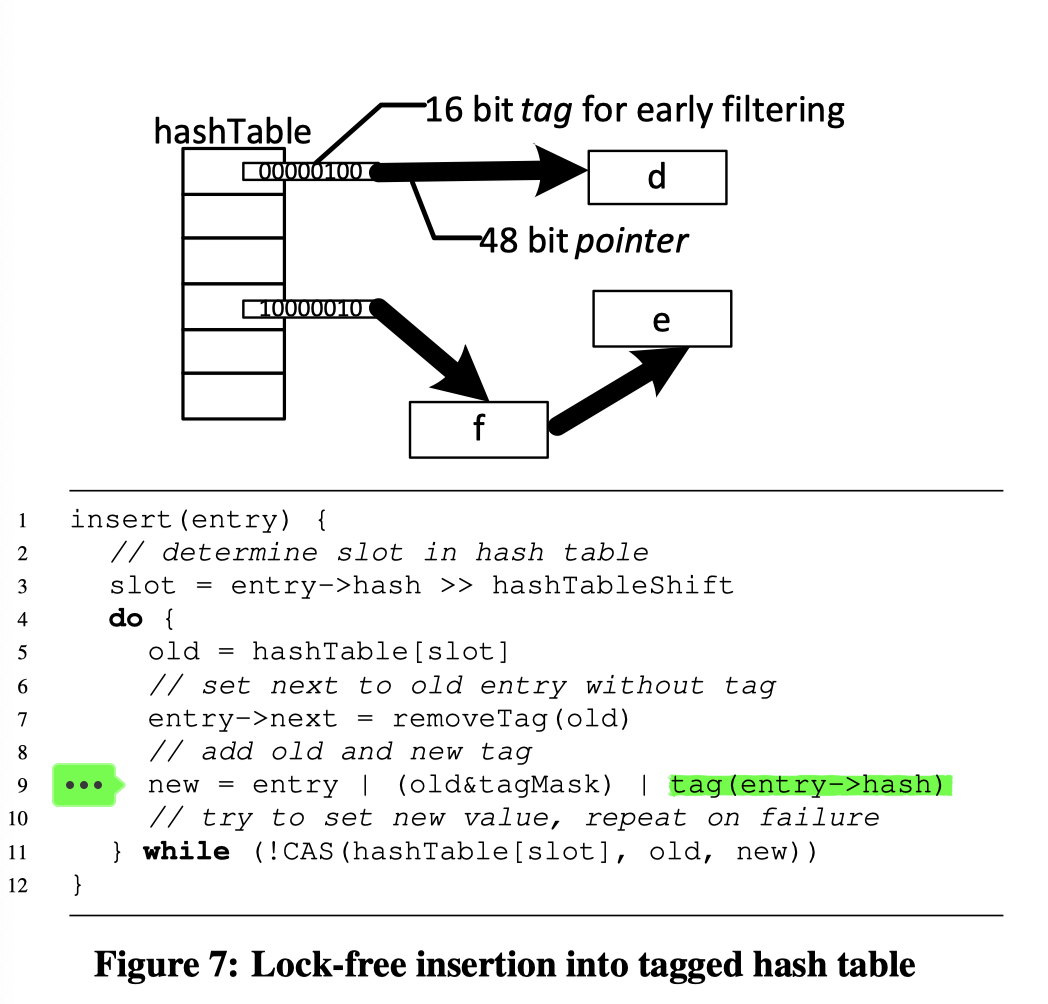
这里 Hash Join 有几个 Point:
- 对于哈希表,用了分离链接的方式来做 lock-free hashing。因为预先知道大小,所以能做比较好的 hash。
- 利用了指针 48bits 的 trick。指针存着一个类似 1bit 的 Bloom Filter 的东西,来做一个快速 filtering。
- 作者认为这种方式相对 radix Join 来说有着不错的 cache locality
- 这里使用 2M 的 Page 来做哈希表。这里作者认为,申请大页之后,这里会由第一个插入的线程触发真实的内存分配,这个时候,NUMA 页面会有一定的亲和度。之后插入可能也是这个线程
- 笔者认为,光看这一段比较牵强,但是如果数据有很好的 Hash Partition 特性,而且和哈希表哈希方式对齐的话,可能会有一定的 locality,后面文章也提到了数据的 Partition。而在读阶段,因为是只读的,所以哈希表在 l2 cache 里就可以保证一定的高性能。
Modern operating systems do not eagerly allocate the memory immediately, but only when a particular page is first written to. This has two positive effects. First, there is no need to manually initialize the hash table to zero in an additional phase. Second, the table is adaptively distributed over the NUMA nodes, because the pages will be located on the same NUMA node as the thread that has first written to that page. If many threads build the hash table, it will be pseudorandomly interleaved over all nodes. In case only threads from a single NUMA node construct the hash table, it will be located on that node – which is exactly as desired.
Partition the input
这里希望根据 Hash(attrs),并选择尽量重要的(比如和 Join 有关的方式)来调度。这样能利用上一些 co-locate Join 等方式,并且能够让数据分布很均匀。
当然,作者认为这里只是一个 Hint,因为 Morsel 本身也有 work-stealing 的能力。
It should be stressed that this co-location scheme is beneficial but not decisive for the high performance of morsel-driven execution, as NUMA-locality is, in either case, guaranteed for table scans, and after the first pipeline that materializes results NUMA locally.
Grouping/Aggregation
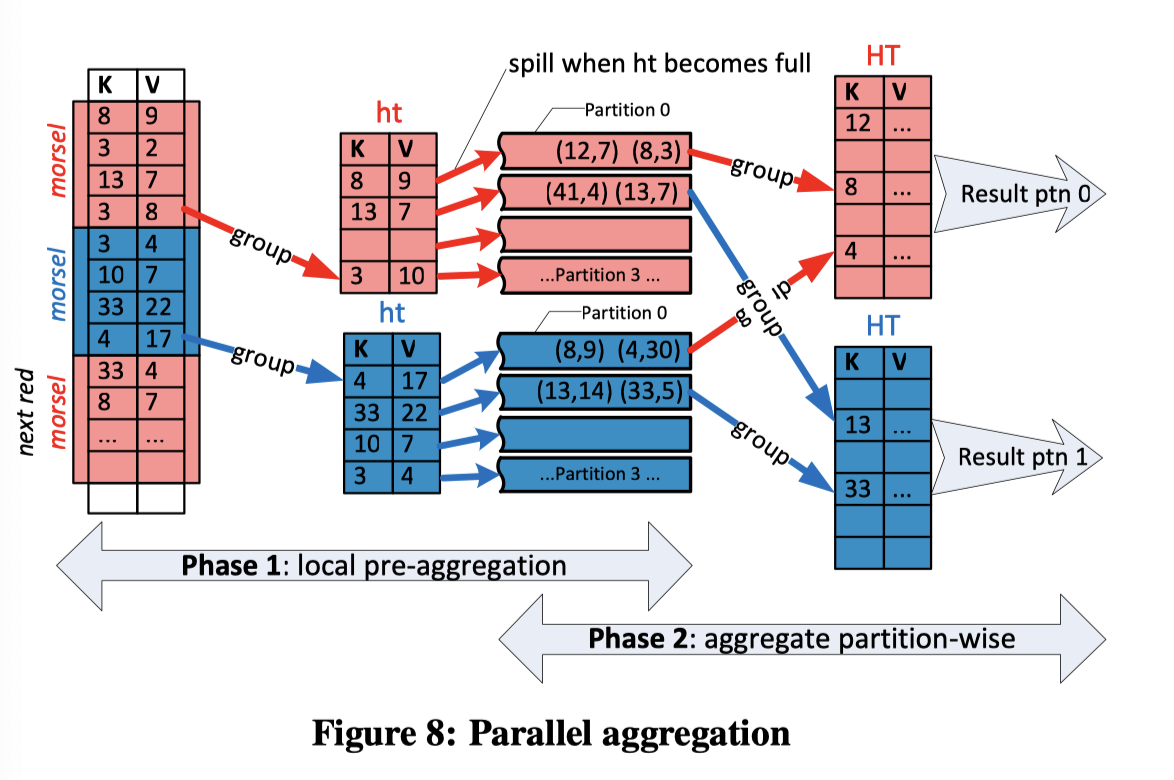
这里类似 Map-Reduce 的 Shuffle 的模式,先本地做 Hash Partition(维护 thread local hash table,而不是 Join 的那种)。在 Hash Parititon (ht)重,如果满了,就 Spill 到额外的区域内(当然我猜这里也可以 Agg 直接做)。
然后在阶段二由不同线程 fetch。每个线程负责收集某个 Partition 的数据,当他收集完所有输入 Partition 的时候,会直接 Push 对应的输出给下游的 Operator (这个 Phase 不是个 Blocking 的)。
这里原理特别像 Shuffle。
Sorting
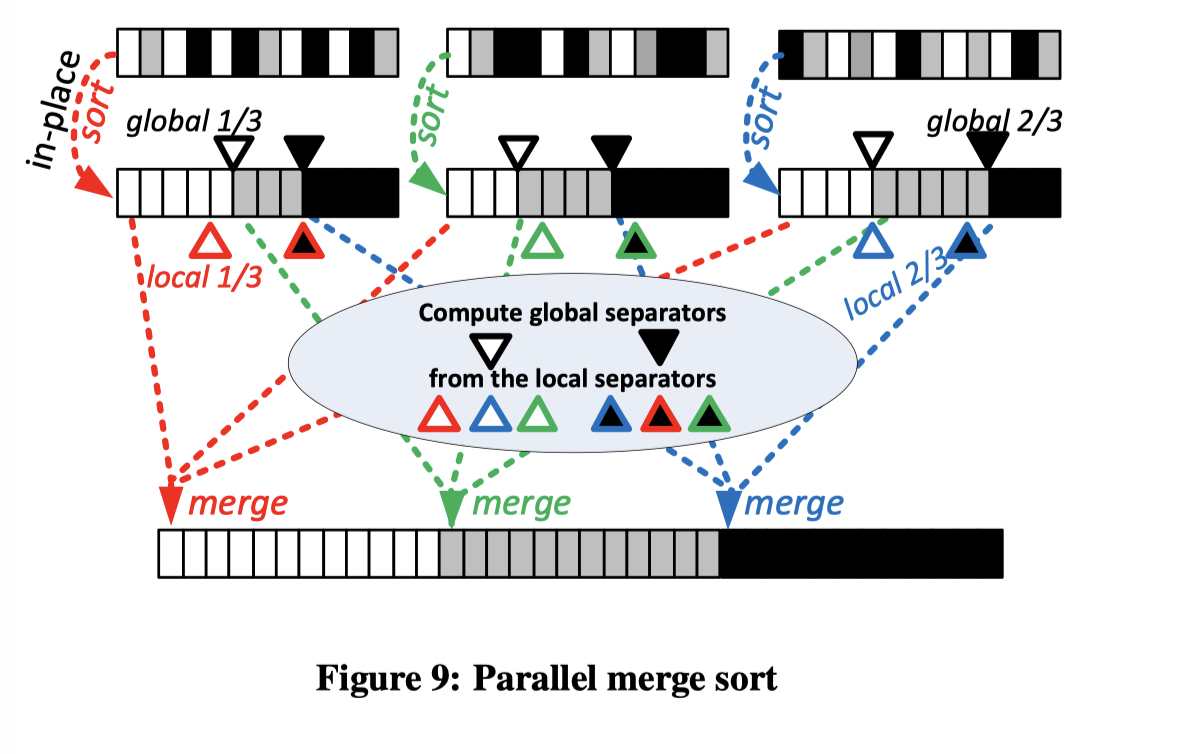
Local Sorting -> Merge
Other cases and Blogs
Datafusion
Datafusion 自身是一个 pull-based Morsel Driven Execution 的执行模型,它的参考文档如下:
- Tustvold 写的 RFC https://docs.google.com/document/d/1txX60thXn1tQO1ENNT8rwfU3cXLofa7ZccnvP4jD6AA/edit?pli=1#heading=h.3iwlbn2gzs29
- 一些相关的讨论:
Alamb 提到一些比较有意思的思考:( https://github.com/apache/arrow-datafusion/issues/7001#issuecomment-1666569951 )
The claimed benefits of morsel driven parallelism of the classic approach are:
- Better NUMA / cache locality
- Near linear scaling (so if you double core count to 32 to 64 expect to see a linear 2x speed up)
- Better runtime optimization by scaling up/down cores, but I think this is less important in the real world (as you most often run out of memory long before you run out of CPU)
Basically, I think it is totally reasonable for DataFusion to scale linearly to high core counts — like 128 / 256. I just need to prove that is the case and I suspect it will take some finagling with the current Repartitioning code
(3) 是个比较额外的点。就算引入 Spill 之类的东西感觉还是会对内存造成一定的影响性。
DuckDB
https://github.com/duckdb/duckdb/pull/991
这里提到会把 Morsel 切分成 100 vector,不知道新的版本是啥样子的
TiFlash
依靠 Exchange 算子来做并行。见 http://fuzhe1989.github.io/2022/04/17/tiflash-executor-thread-model/