ATC'19: EROFS
之前看到培神在群里转华为贡献的 EROFS 可能进安卓主线并作为默认只读文件系统,不仅对这一贡献比较感兴趣,遂把论文拉出来读了一遍。文章作者来自华为和 SJTU iPads,内容还是比较清晰的,描述了它们怎么优化只读文件系统的,它们的贡献大概有:
- 利用 LZ4 来把输入块压缩成固定大小的块输出 BLOCK 存储在块存储设备上
- 利用巧妙的技巧,来优化解压缩的开销。作者认为这块的开销有两个方面:文件大小的放大、解压缩需要的的内存开销(见后文图)
- 文章把 compressed block 分成了两种模式:cached io 和 in-place io。
- 用多种方法来优化解压缩,包括直接把用户内存映射到解压缩对应的 Page、跳过不需要解压缩的多余数据
本文只代表 19 ATC 发表的状况,听说 2023 年 Linux 主线代码和这个有点变化,而且作者目前还在维护这套系统。感兴趣的可以翻翻 maillist 来得知最新的情况。
背景和相关系统介绍
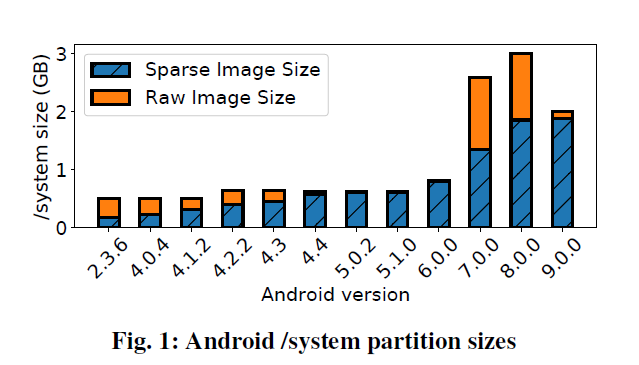
EROFS 是一个只读的压缩文件系统。而安卓本身代码也使用了 Linux Kernel 部分的一些代码[3]. 本身 Linux 上很多地方就是放只读文件的,比如系统的 /system 之类的 read-only space. 那么根据论文的作者所说,实际上安卓的系统文件大小本身是挺大的,在 android 9 上面增长到了 1.9 GB。如下图
(Sparse Image 和 Raw Image 是镜像的不同格式,见 [4] )
- Btrfs 这种 fs 对压缩并没有那么友好,它会把数据切分成多个 128KB 的 Chunk,然后独立压缩,把这些数据存放在不同的 Extent 中,这些 Extent 的位置会存放在一个 Btree 索引上。需要读取的时候这里需要 decompress 整个 column chunk. 然后去处理. Btrfs 是可以更新的,但是更新和重写整个 chunk 差不多了,还要额外更新一下 index。
- 而 SquashFs 是一个已存在的压缩只读文件系统,但是这个系统会带来不少 overhead,有的是设计层面的,有的是实现层面的,见下图:
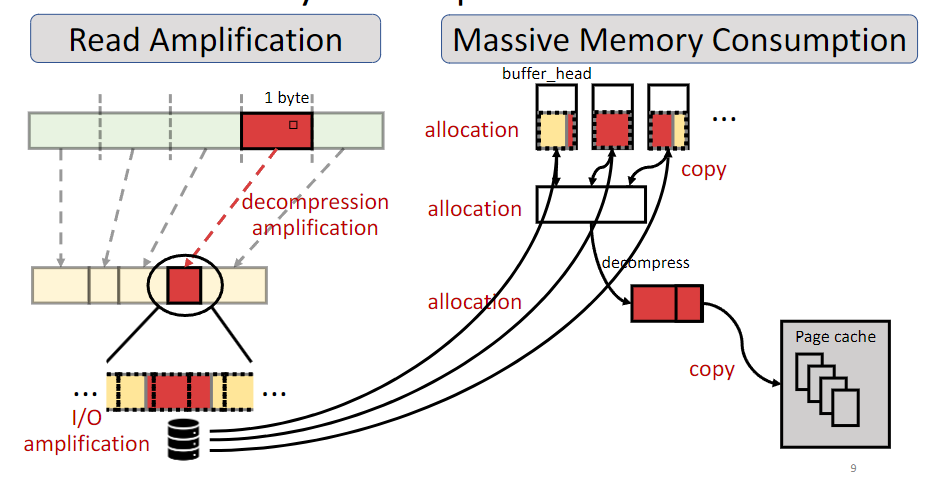
Squashfs 支持配置输入 block-size,然后把这些压缩到输出然后分配到磁盘的 Block 上。也支持配置一些算法。在 Squashfs 上,也需要一些元数据(比如压缩前后的映射)。压缩后的大小存储在 inode 中的列表上。
从文章的实验角度看,这些设备的压缩率其实是很高的。这导致:
- 每次会多读一些磁盘 IO 的数据(这个是设计角度导致的,比如压缩后的块和磁盘 size 不对齐)
- 解压缩需要申请 uncompressed 的块大小的临时内存。本来盘大小就小于内存了,你这资源开销更大了…这些内存在现在还没多大内存的机器上操作还会加剧 swapping。
作者认为,Squashfs 设计有下列核心问题:
- Fixed-sized input compression: 这种方式对小 io 带来了比较大的读放大和内存放大,如果全要读倒还好,但是对于小 io,比方说要读取第一个 block,然后磁盘上可能没对齐的 BLOCK 都给读了,然后又要准备解压缩空间,因为你也不知道这些东西每个用户层面的读要的数据在哪块. 当配置成 4KB 的输入块的时候,上述问题会被改善,但是压缩的 batch-size 又太小了,导致白压缩了。
- 数据拷贝的开销。这部分上面的图写的非常清晰,这里读的 buffer->解压块 -> 用户内存。每部分都引入了一定的开销。这部分我感觉一定程度上也是实现问题了。不知道 block-size 和设计感觉和这个的影响没有那么直接。主要是工程化的时候怎么在内核上支持这些需求。在实现上的时候,squashfs 实现如下
- 拿到 compressed block 的数量
- 给每个 compressed block 申请内存。然后 issue io 把它们读起来。这里可能会有个 io page 池,这个池是预先申请的,给 io 对应的需求使用
- 拷贝到 temp input buffer,这里需要一个连续的空间,然后解压到 temp output buffer. 作者认为,这里的主要瓶颈还是 memory access 而不是 CPU
- 给用户的 page cache 拷贝
作者认为,优化空间在于:
- 减少 io
- 减少内存申请
EROFS
Fixed-size output compression
作者认为,一部分问题来源于 Fixed-size input 的不够 flexible,所以他们使用的策略是 fixed-sized output (这块其实我也没有百分百被说服,因为感觉是有 trade-off 的,在同样压缩率的情况下,这里保证了对下层 block 的 io 是对齐的,但是本身 decompress 中的各种放大还是存在的。)
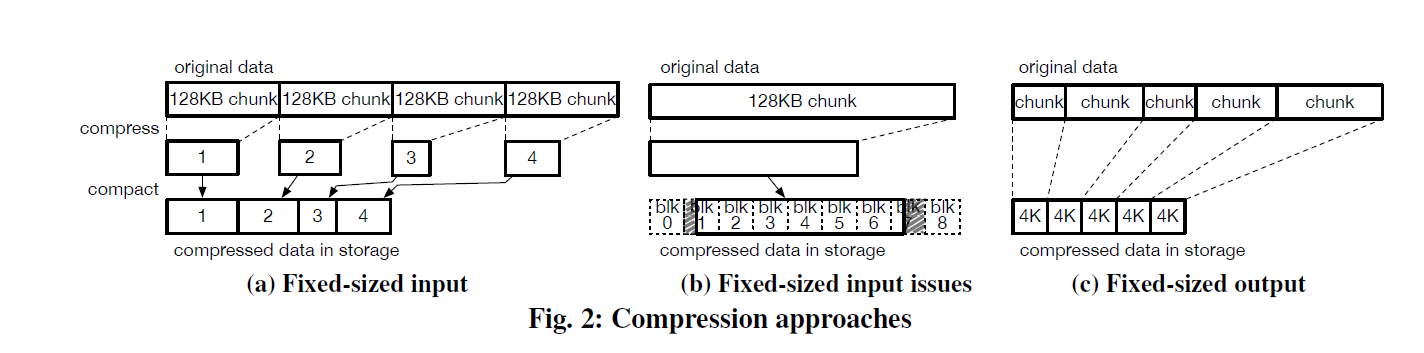
具体方法上,EROFS 采用了 LZ4 的方式,在 {输入大小到达 1MB, 输出大小到达4k} 两个条件任意满足一个就会切下面的 BLOCK。如果是输入大小为1MB可能也会准备一个 4K 的块。这个增加了压缩率的上限(毕竟原来128KB一压)。2(c) 就是压缩的一个图例。作者认为这样有如下有点:
- 最大压缩率更好(我认为这个取决于输入吧 orz)
- 在解压缩的时候,io 控制的比较好。作者也通过一些 hack 的方式让解压缩尽量解压少的空间
- 作者认为只有对应的压缩数据会被解压,我觉得没差把。我感觉一个隐含条件就是这堆东西压缩率很高,压缩率低的条件下文章提到的很多东西都比较扯。。。这样对于小碎读有一定优化,比如小碎读最多引入两个 Physical Page IO. (不过看文章领悟了一下,应该这里 fs 层也是 Page-Level IO,原则上 fs 上层读一个 Page 下头确实最多读两个物理 Page)。
- 使得后文提到的 in-place compression 成为可能。
Input Buffer Handling: Cached I/O and io-place I/O

- Cached I/O: 如果要 partial read 某个 block
- 使用一块 inode 区域来存储状态,数据被 fetch 到一个额外的 page cache 中。
- 作者认为这种小块读可能是连续的,所以可能会 cache 一会儿,后面读到了后面的区段可以避免反复解压(这段有点抽象,可以看后面的 decompression 一节)。
- In-place I/O: 比较 hack,包含一些核心优化,给一些需要 decompressed 的 Page 准备的。这里认为大块读不会被反复请求,所以把 page 放到连续的解压缩 Buffer 的尾部
(这段有点抽象,可以看后面的 decompression 一节,配合理解)
Decompression
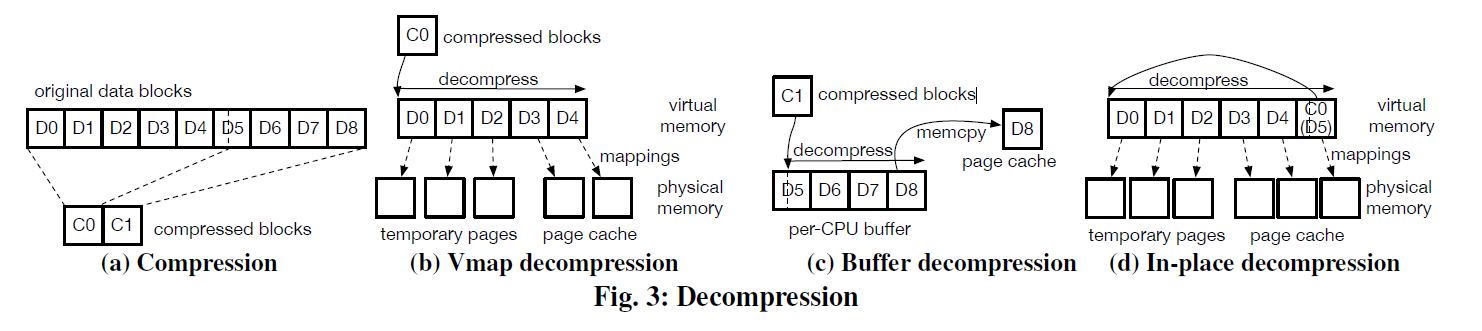
如上图,假设现在用户需要 D4/D6 ,这里需要看看 Cache-IO 怎么处理
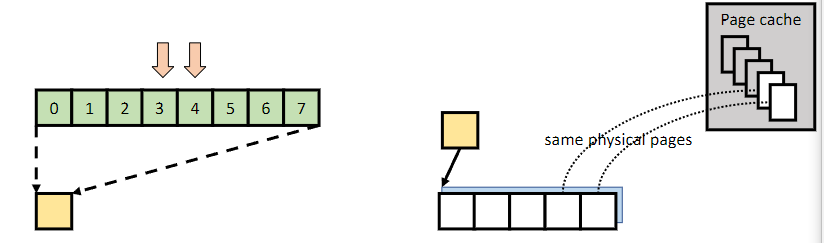
如上 (b),这里 EROFS 只需要 D3 D4,所以它:
- 发起两个 Page 的物理 io
- 准备一些 temporary page 给 D0-D2,因为 和 需要 mapping 的 Page 不一样,这些暂时不需要,然后直接解压,然后 D3 D4 解压的用
vmap映射好丢给用户层
如果是 in-place I/O,那么如同 (d),这里 C0 会被放到尾部,然后直接解压完。
这里还有几个工程优化:
- 小页面用 Per-CPU buffer decompression。因为很多小页面解压,EROFS 禁止了切换(在第五节介绍的)然后切成 per-cpu 的小页面解压,这里再解压缩页面小于 4个 page 的时候才会使用,例如 3(c). 当然这里也需要拷贝出去了
- Rolling decompression: 为了避免不需要的内存申请太多,这里会每个 CPU 准备 16 个 Physical Pages,然后滚动 decompress
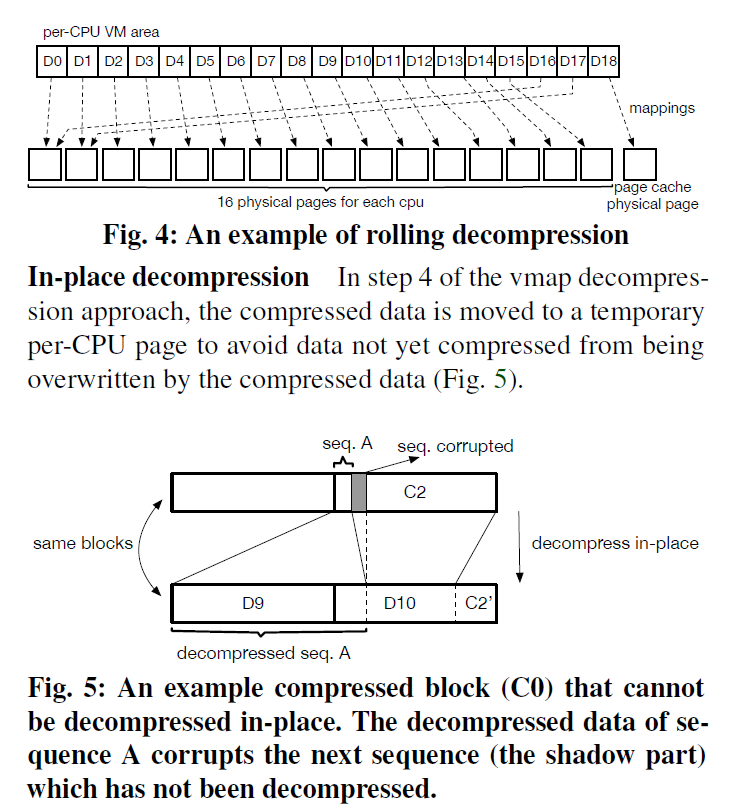
此外,如果当 figure5 这种场景出现的时候,也会使用临时的 Per-cpu页面。