arrow dataset
Dataset 是 Arrow 中泛化处理 {某种 fs 上, 某种 format} 的多个文件的抽象。在读取文件的时候,通常会有多个数据集合,吐出同一种 Schema。
有数据集合,那么自然就有单个文件,Dataset 抽象出了 Fragment 的概念。每个 Fragment 对应的范围可以是文件,也可以是 “文件的一部分” ( e.g.: Csv 文件的一定行数,Parquet 文件中的1个 RowGroup)。对于 Fragment 来说,Fragment 的 Schema 可能和数据的 Schema 会有一点区别,Dataset 会在这一层做 Schema Evolution (但是 Arrow 目前,至少 13.0 还不支持 Parquet upcast,只支持少读几列或者多读几列不存在的这种类似 Project 和包括 Projection 的搞法),将多部分 Fragment 的 Schema 转化为 Dataset 的 Schema 的逻辑由 FragmentEvolutionStrategy 处理。
Dataset 有 Discovery 的能力(DatasetFactory)。这部分我觉得有点怪,比如说,它能给定一个目录,然后把这个目录当成 Hive 分区那种方式处理( key=value)。不知道这个算不算一个实用功能,因为在我看来,这块总觉得是应该丢给 Meta 系统来处理的。
Dataset 可以用来看 Schema 然后 Scan,产生一个对应的 Scanner 对象(有 Scanner,里面持有 FragmentScanner)。产生对应的 RecordBatch。不过我看好像还没有针对 Iceberg 之类的处理的逻辑。在 Scan 的时候,这里会有一定的预读策略,不过这几块的逻辑基本是给 Acero 准备的,有的地方策略看起来还是挺奇怪的,比如基本是一个 push-based 的模型,不断 push 具体的内容。
此外,对于 Scan 来说可以指定对应策略,比如 Prefetch 的属性、是否要求 Scan 出来的数据满足 Ordering,e.g.:
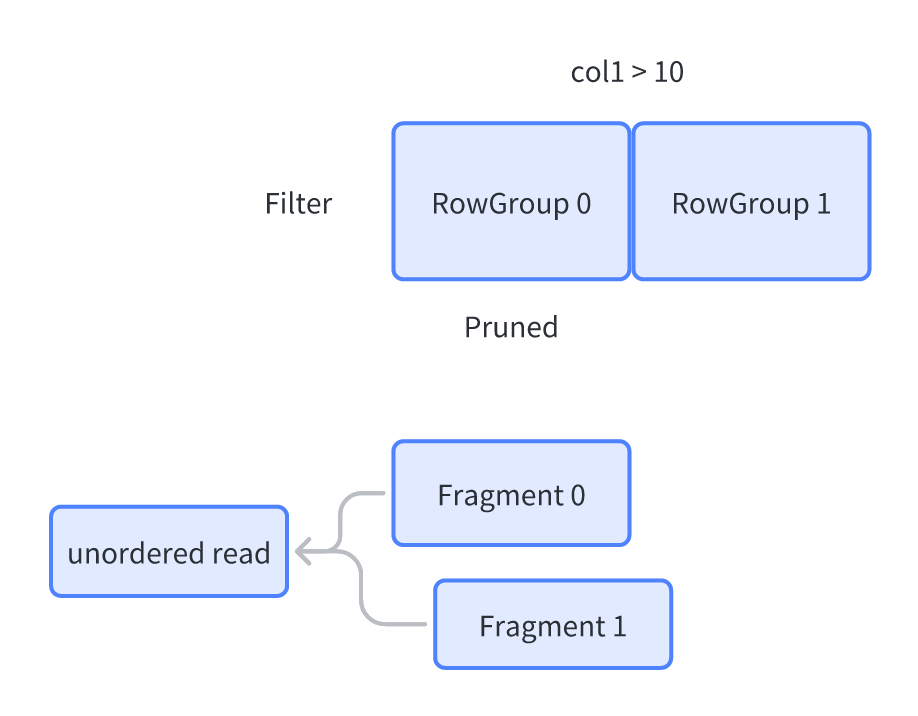
目前在一种 DataSet 里面,有的 Dataset 只能处理一种 Format (Parquet、CSV…)的数据,它们可以靠 UnionDataset 连接起来处理。而 FileSystem 上的内容则靠 FileSystemDataset。之后我们会了解这些东西是怎么组合起来的。
上面的 Dataset 部分和 Acero 是交融的,Dataset 可以利用 Acero 的部分来 Scan,而 Acero 又借助了 Fragments:
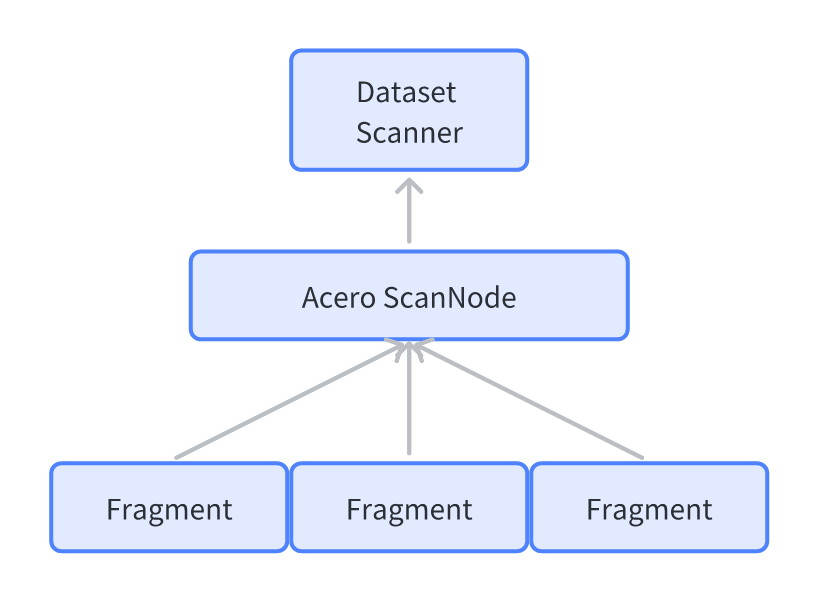
Arrow 还允许写 Dataset,它提供了:
- DatasetWriter
- SinkNode
这里组织和之前差不多,不过老实说我感觉 Arrow 对写这块没那么熟悉,所以写链路上感觉打磨的不是很多。
Fragment
Fragment 是 Dataset 的「一部分」抽象为一个子单元,可能会有一些 Partition 约束
1 | class ARROW_DS_EXPORT Fragment : public std::enable_shared_from_this<Fragment> { |
这部分逻辑比较简单。
FragmentScanOptions是一套多态接口,允许你自己定义InspectFragments会允许你去 Inspect 对应的内容CountRow会尝试(注意,这个不一定真的返回)告诉你有多少行,它会做成 Best Effort + 准确的。比如它读 Parquet,如果发现自己某个 Expression 没法判断是否满足,就会快速熔断,返回std::nullopt.
FileFragment
主要的 Fragment 是 FileFragment,是在某种 fs 上,给定某个 Schema 读取,有着 Format 的固定单元。FileFragment 对应某种文件格式,但是不一定对应一个文件。比如 Parquet 的 FileFragment 就可能对应 File 下的一到数个 RowGroup。
这里面包装了如下的类型:
- FileSource :
((fileName, fs) or (input buffer), compression..), 允许用户在上面打开一个RandomAccessFile或者InputStream(老实说我觉得 InputStream 比较自然…不过 OSS 这种做 RandomAccess 的话要包一堆 pread 之类的语义,也不是不行) - FileFormat : 相当于
FileFragment的工厂,包装了一些 Fragment 的接口,然后根据FileSource之类的创建 FileFragment,和所有 Fragment 上的接口. 这里感觉不会创建 RowGroup 上的 Fragment。FileFormat 对每个文件类型需要实现一遍子类。此外,每一种 Format 工厂上还有一个FragmentScanOptions,作为默认的 Scan 配置。这种 Format 作为工厂的配置代码没啥奇特的,不过作为框架代码还是可以拿来抄的
在 FileFormat 下有多种 Format,比如 Csv, Ipc, Json, Parquet。作为 Dataset 的抽象。
FileFragment==FileSource + FileFormat. 包装了一个FileFormat和FileSource,完成对应的需求。
我们以 ParquetFileFragment 和 ParquetFileFormat 为例
ParquetFileFragment: 包括SchemaManifest、文件的metadata_,此外还有一些 Partition Guarantee Expression、RowGroup 裁剪表达式的内容ParquetFileFormat: 包装了上层的一个奇怪的 ReaderOptions,和 default config
在 Format 层实现的:
- IsSupport: 看一下 Footer,查看一下文件使用的版本呀编码呀自己是否支持
GetReader/GetReaderAsync: 打开 Reader- 读取 Schema
- 读取的时候做 Schema Projection (这里包含把外部读取的 Schema 映射到内部,可以看
InferColumnProjection, 我觉得这块写的怪怪的,甚至还有检查 duplicate fields name 的)
在 ParquetFileFragment 层,默认会「打开 Footer,然后包含所有的 RowGroup」,然后外层用户可以:
- 下推 Filter,这里会把每个 RowGroup 的信息抽出来,抽成一个 Expression,然后看这个 Expression && 用户传入的 Filter 如果一定是 False 的话,那么可以尝试裁剪掉
- 允许 Subset,取这里的一小部分
- 在打开 Scanner 的时候 (
ParquetFileFormat::GetReaderAsync),才会打开 InputStream (FileSource::open)
我们可以简单看一下 Filter 的代码:
1 | Result<std::vector<int>> ParquetFileFragment::FilterRowGroups( |
(我感觉这块虽然没问题,但是 Column As Expr 看着有点别扭,而且这种模式在搞 BloomFilter 的时候,就不是很方便了。之后看看 Velox 和 Impala 之类的是怎么搞 Column Filter 的,比方说你其实有点不那么好把 BF 抽出来作为一个表达式然后放这里(其实也不是不行))
这里取 Subset 的时候,相当于 FileMetadata 和 SchemaManifest 这几个东西会传过去,不会重复 Reopen footer.
FileWriter
FileWriter 包装了不同 Format 文件的写接口,可以给 SinkNode 来写入数据,不过我觉得写的很简单也很挫,随便看看就行了。
上层操作
FragmentEvolutionStrategy 在上层处理了一些 Evolution
1 | /// \brief Rules for converting the dataset schema to and from fragment schemas |
每个 Fragment 在文件级别会有一些 Guarantee,表达:
比如这个 Fragment 如果 Field 少了一个,那么整体还是可读的,但是这个 Batch 可能会有一些 Gurantee。比如读取 <a: int, b:int, c:int> 三列,文件只有 <a: int, b:int>,那么 c 可以补齐,这个时候会有一些 EvolveBatch(把 Batch 补齐),或者 Gurantee(保证 c == null ) 的操作,给上面提供一些处理的帮助。这个 DevolveFilter 能够把对应的 Filter 补成对应的,或者补充一些别的重新映射之类的操作(比如 <a: int, c:int, b:int> ). 这部分方便做 Resolve.
Dataset
Dataset 是 Fragment 的集合,表现为一组可以被 arrow 捞出来处理的整体,这些 Fragment 可能按照一些分区规则之类的方式被排序。Dataset 可以处理的逻辑有:
- ProjectSchema: 允许 Dataset 上套一层 Project,Project 甚至可以是一些表达式
- 产生 Scan 对象
这么说来这套东西还是挺简单的是不…并不是,我们可以看看这套类型是怎么组合的:
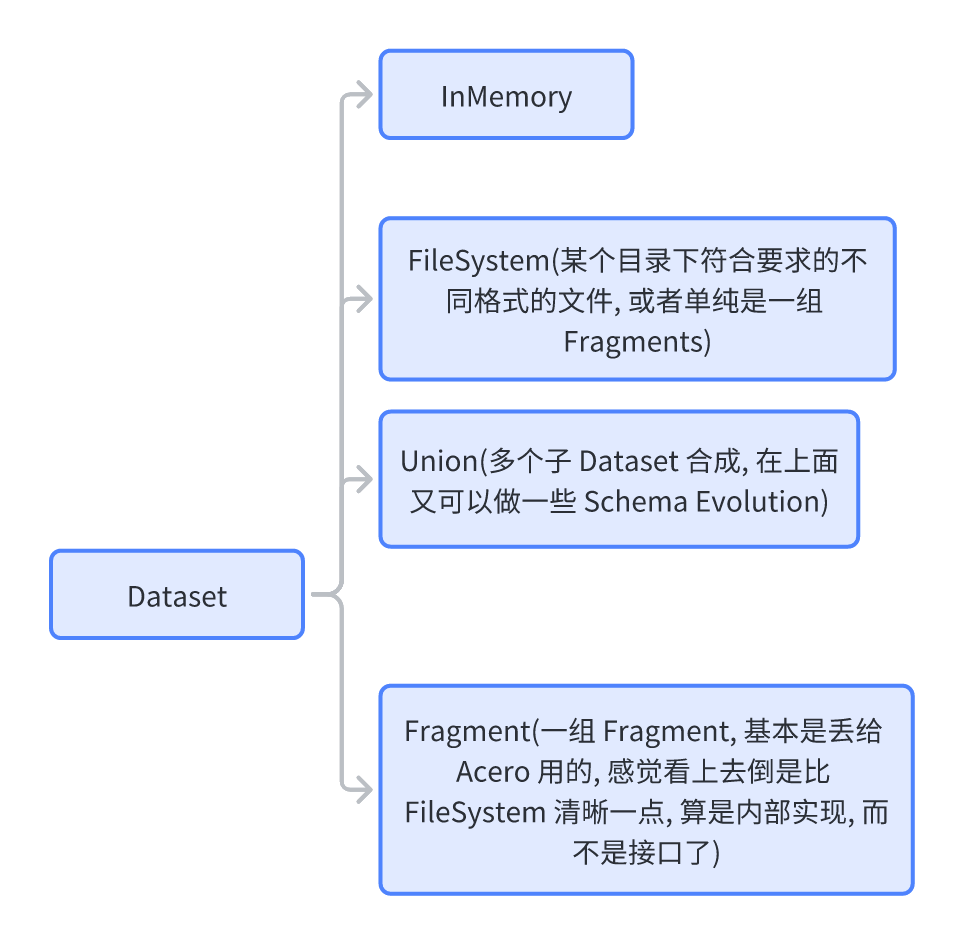
DatasetFactory 可以帮助构造不同类型的 Dataset,实际上这里主要目的是 List 出对应的目录然后构建到一起。
实际上,这里面大概逻辑是:
- 用户可以用
FileSystemDatasetFactory之类的,指定对应的 S3 或者 Local 等目录,List Plan 到对应的文件 - 构建出一组 FileSystemDataset,然后用 Union 连接到一起
- 拿到对应的 Fragment,然后允许对 Fragment 打开 + 预读。可以创建
FragmentDataset然后丢给 Acero - 用 Acero 之类的 Scanner 去做对应的 Scan