Distributed Transaction in DynamoDB
DynamoDB 是一个 Dynamo 之后亚马逊主要推进的一个 K-V 型产品,定位上是一个强一致、多租户的 key-value 存储。DynamoDB 产品做的比较早,但是论文发布在 ATC’22 上 [1] 。
ATC’23 的论文 Distributed Transactions at Scale in Amazon DynamoDB 介绍了 DynamoDB 是怎么支持高性能的分布式事务的,本来我是比较期待他们整什么特别好的活,但实际上看前三节的时候有一种「感觉不如 ByteGraph…事务…」的感觉。本文前几节讲述了 DynamoDB 事务的负载和实现,它的负载主要是一个 Point Get 或者多行事务读,单row/多row Update 之类类似 RocksDB 但没有 Iterator 的场景(还有一个操作是 condition ? op1 : op2 这种类似 RocksDB Merge 的场景),和在这种场景下,如何不依赖 MVCC 和锁服务、依靠本地时间戳实现 OCC 事务。本文的重点在第四节,描述了在这种特定负载下,如何通过 Thomas Rule 之类的方式来做 OCC Reorder。
笔者看完觉得亮点在第四节,虽然看着有一点失望,但是无疑本文能帮我一定程度上 recap 之前做的分布式事务,也方便看看,它为什么这么做,特定领域的优化有没有前途。和语义化处理事务的一些实现逻辑。
在论文里,他们的描述如下(首先需要了解他们是一个 primary key-value 的模型):
- 事务相对于维护成 session,只是在单个单个请求里面提交(天啊这不是我们 bg 的梗吗)
- 采用乐观事务来实现(用户真的不会有意见吗)
- 对非事务操作(Get / Put)、1PC 等场景有特定优化,让事务逻辑尽量不影响它们。同时这些操作也不会 break 事务操作的逻辑
- 不用 MVCC,事务本地直接更新。作者觉得多版本开放在存储上太复杂了(感觉甚至包括用 write intent 这种形式),所以做了一个单版本的事务(我本人对这个不置可否,因为感觉它们没有 scan 负载,所以可以尽量做简单)
- 用事务的 start-ts 来做时间戳,时间戳从亚马逊的单独的服务上处理(类似 TrueTime,但是看论文描述说是会有点偏差的,估计就是 NTP 矫正有时间偏差有个 lower-bound 的时钟?)
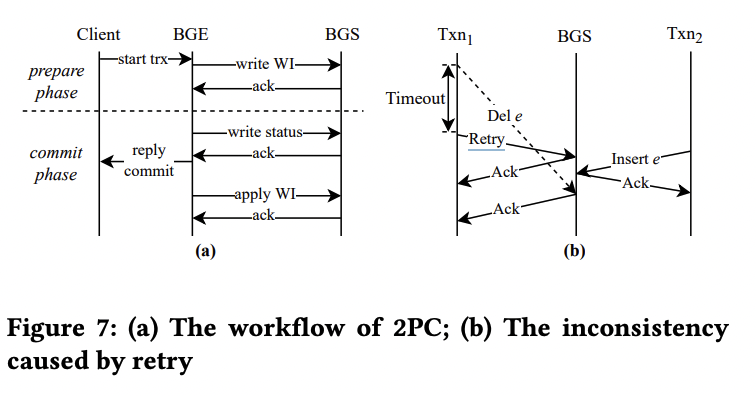
(题外话,在 ByteGraph 论文里面重点描述了这种场景下 Retry 可能带来的问题,但是 DynamoDB 好像没强调这个,他们只强调了写请求会带上一个 client id,感觉没有深究,不知道是他们没做还是什么情况,如下图)
DynamoDB Interfaces
DynamoDB 提供了操作 Table 或者 Index 的抽象 . 下面是它开放的非事务 API:
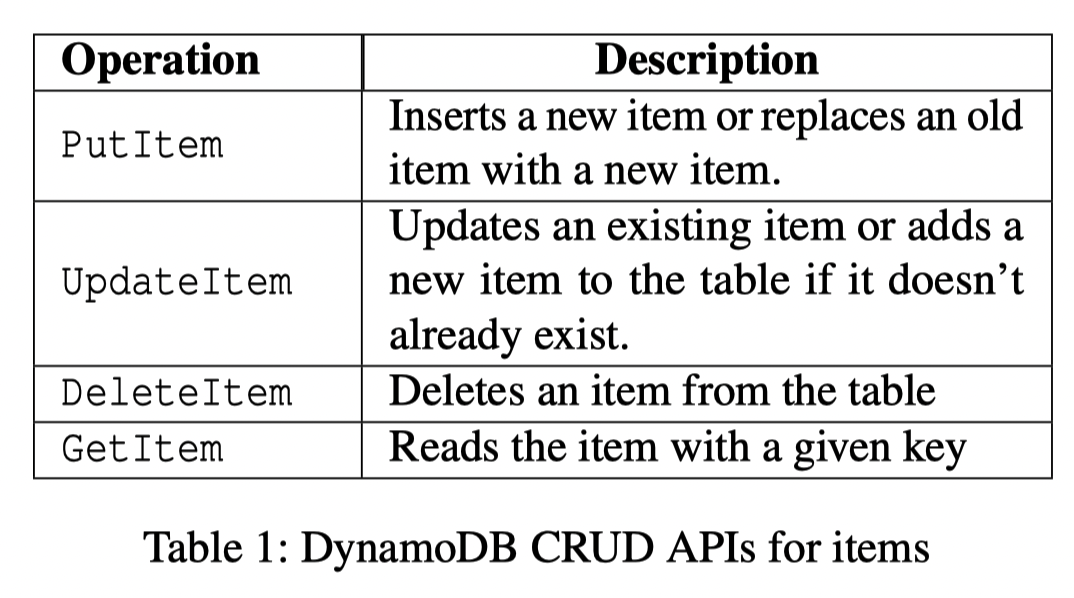
对于事务 API,我们可以列出来然后看看具体代码的写法(确实有点像 RocksDB)

- 它的
TransactGetItems维护的是一个类似 SI 的语义( RC 应该直接走读接口就行) - 写操作会保证自己是幂等的,具体而言它允许用户带上一个 client-id,然后保证10min的窗口内这里是会检查是否重复的(但是论文没有强调这块具体的实现,有点像是在内存或者存储上维护了一个 Purge Window,因为这里比较恶心的情况是 client-id 和 txn-id 逻辑不一定在一起,除非它做了什么特殊的保证操作或者在节点内存上跟着事务一起维护了这个窗口,我感觉都能做但是就有点麻烦。难道是用这个生成 transaction-id…?)

上面的逻辑描述了 DynamoDB 先 Check,满足的话就去更新并且创建订单(总觉得这个组织还是比较平坦的,不知道允许不允许复杂一点的逻辑结构,看了下文档感觉不太建议用户这么搞,估计就是个简单的 check + merge)
Transaction Execution: Basics
这节介绍了 DynamoDB 的事务执行,之所以叫 Basic 是因为这节介绍的是大概的框架,而没有介绍 OCC 相关的核心优化。
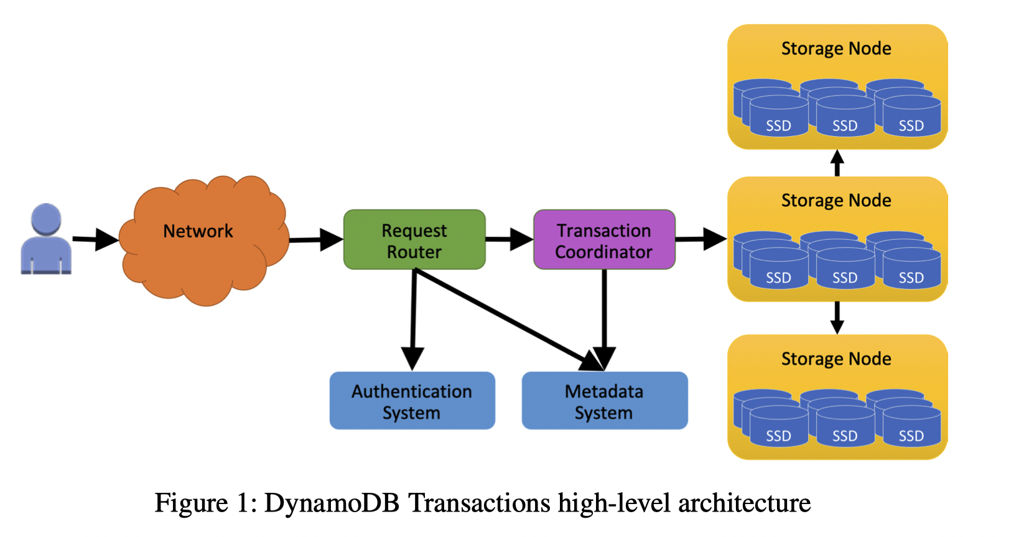
在鉴权等操作之后,事务请求(不包括非事务请求)都会被发给 Transaction Coordinator。Transaction Coordinator 是一个无状态的节点,任何一个 Transaction Coordinator 都可以充当一个事务的 coordinator。
在 coordinator 上,事务会被 assign 一个 start-ts (使用 AWS time-sync service [3],一个 NTP 池)作为事务操作的 ts,然后要求按照 ts 做 ordering。这里比较 trick,因为它这里不依赖 TrueTime、Lock 而且做的还是 OCC,我觉得这段还是得比较谨慎的判断 corner case 的…
Write Transaction Protocols
这里的协议是个 2PC:
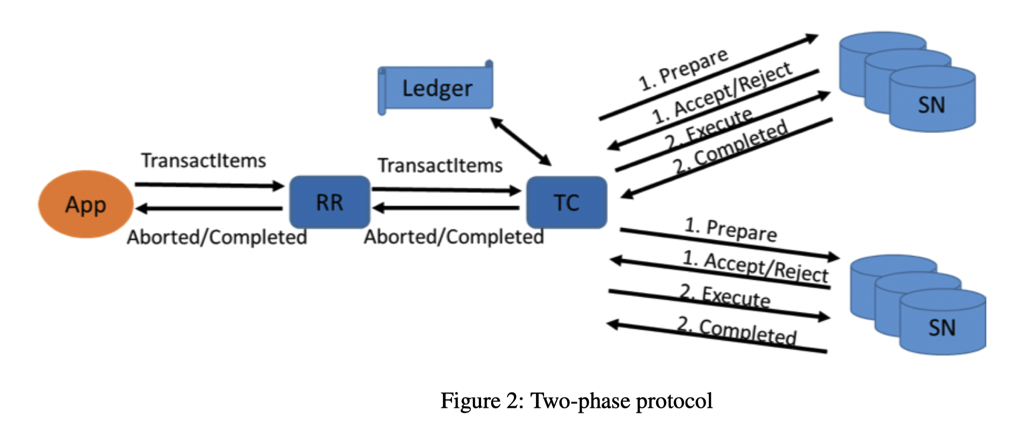
- Prepare
- Commit / Cancel
- (post) 去 Ledger 记录事务的 FIN 信息
- 这里面,对于 DynamoDB,每个 row (或者说 item) 有一个
{timestamp(commit时更新), update-txn-id(prepare时更新,commit清理)}的标记, 作为事务更新的标记,这里有一点需要注意:
- 这里面,对于 DynamoDB,每个 row (或者说 item) 有一个
- 对于一般的数据库,这种一般是插入一条边,带上自己的 ts/txn-id 作为锁,然后等 commit 阶段这条记录变得对外部事务可见。可能旧的 row 会带上 end-ts。当然也有一些系统是 implicit 完成这个约束的,比如构建在 kv 系统上的 Percolator
- 对于 DynamoDB,这一组标记仅仅是一个 update-locking,在 Prepare 阶段在旧的数据上标记这个 row 的锁被占用了,并且在 commit 阶段可以做检查(commit 阶段的检查应该和重试之类的也有关系,一般分布式事务可能需要有一个 background resolve 之类的后台清理之类的流程),这组「锁」在事务提交之后,它认为 txn-id 就可以 discard 了。

Coordinator 上正常链路的操作还是很简单的。Prepare 正常链路的协议如下:

这里注意到几个地方:
- 只有通过了 check 才能推进
- 如果现在操作被另一个事务(
tx)占有了,时间戳比 tx 小直接就返回了,但是比更新大还是会失败,因为这上面有ongoing - 因为删除一条记录这个物理记录就会不存在了,这个会维护
partition上的maxDeleteTimeStamp。然后如果插入的时间戳小于maxDeleteTimestamp,表示可能和对这条边的删除冲突,所以不得推进。(这里 bytegraph 主要是靠 lock 来维护的,然后 binlog 需要维护一个 delete set) - 如果遇到冲突或者失败,这里就会 cancel 自己(感觉在高冲突场景下,这个要么得优化要么得甩锅给用户)
- 需要在节点上提交成功再返回,感觉没有做 async commit
- 感觉它们没有描述一个事务表,在 coordinator 上好像也没有存储,这个感觉是对他们来说算得上独特的地方,因为这样感觉就不好确定事务最终的状态或者所有 participants 了。这个后面有讲 Ledger。
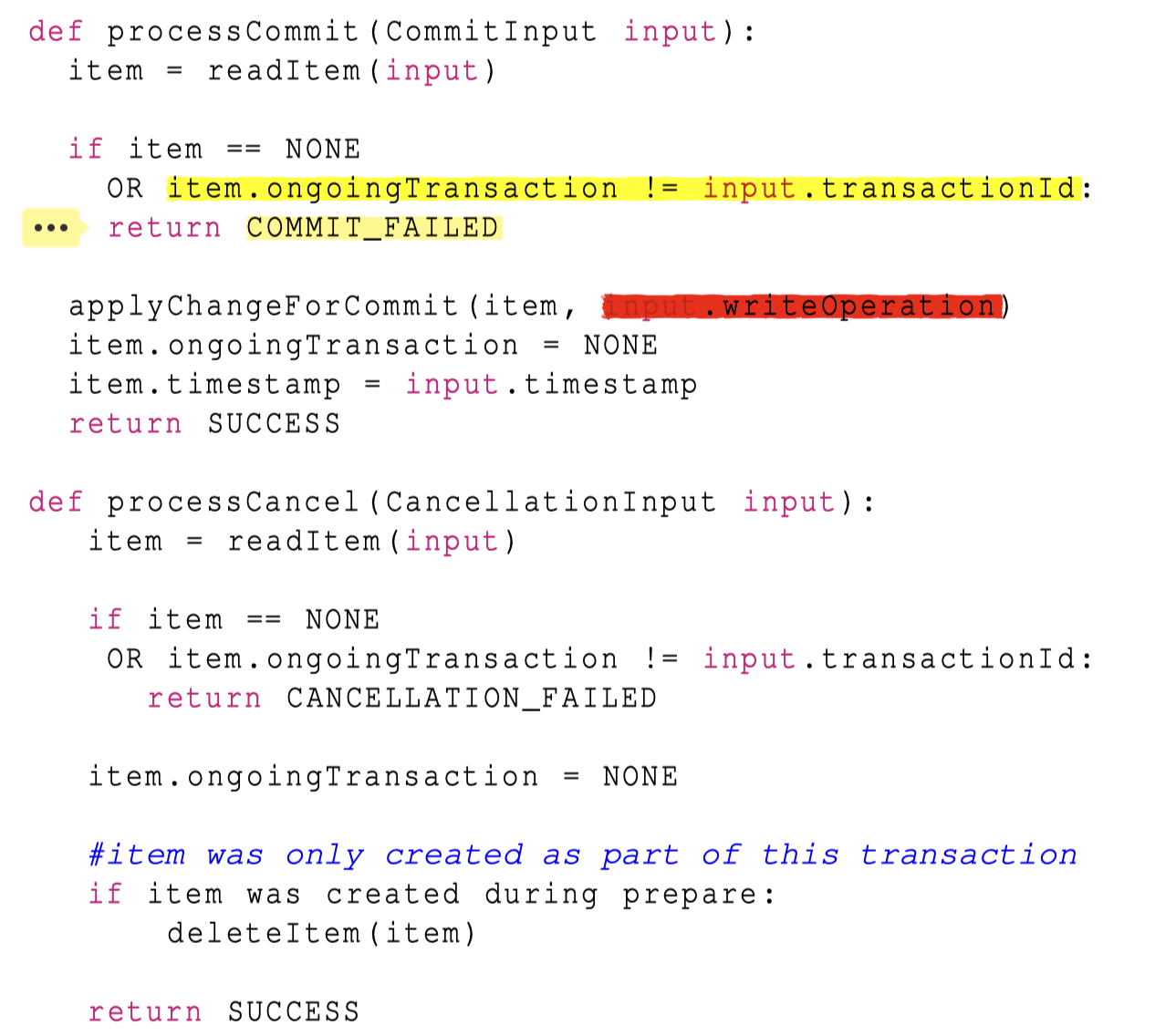
Commit 阶段,比较有趣的是它会做一个 item.ongoing == commit-txn 的检查,这个和后面几节介绍的 recover 有关。
题外话,我觉得这里很重要一部分是 Merge 操作的原子性和读写集。这里看了下官方文档:
You can’t target the same item with multiple operations within the same transaction. For example, you can’t perform a
ConditionCheckand also anUpdateaction on the same item in the same transaction.
我总觉得 condition 的 item 也得上个写标记。
(Naive) Read Transaction Protocol
DynamoDB 不想和 TS Protocol 一样维护一个 read-ts 标记。所以才用了两阶段读(类似 Hekaton OCC 那套):
- Phase1: 查看读的 item 是否都没有 on-going 事务,如果有的话,返回失败,否则记录 item LSN
- Phase2: 读完之后再次检查 LSN 有没有变更
这个实际上过于 Naive 了,所以第四节会讲这部分怎么进行优化。(妈的又引入了一个 LSN 的概念,你用 ts 会死?)
Recovery
因为 Paxos 协议,所以 Participant Failed 是很好处理的,但是 Coordinator Failed 可能会丢失事务执行的上下文(Percolator 类的协议会有 Primary 存储对应事务的上下文,DynamoDB 没有说,这个可以节省一轮提交时候的 rpc,但是感觉对 resolve 来说会有一定负担)。这里有个后台 scanner 去扫没完成的事务,然后尝试交给一个新的 Coordinator 来 Resolve。
论文提到 transaction 可以并行 resolve,没啥问题,但是比较恶心的是,如果你去 resolve:
- 你怎么定义这个 txn 是 abort 还是 commit 呢?
- 你怎么找到所有的 participants 呢?
这里它们没有 async commit,但是也不能看到一个 abort 一个,要不然最终状态又问题,但论文提到了 Ledger 来存储事务的状态。(论文里没有提到它是不是同步写 Ledger,不过我觉得应该是,这样 resolve 的时候可以找到所有的 Participants,然后再去 resolve)
Ledger 本身是 DynamoDB 上一个特殊的表,用这个来处理相关的事务逻辑,Storage 节点也会主动把没完成的事务上报,然后提醒上面主动清理(BG 也有这套逻辑,害,感觉他们做的没啥啊 XD)
Adapting timestamp ordering for key-value operations
DynamoDB 区分出了 Delete / Partial Update / Insert / Upsert(Put) 之类的语义(里面有些没直接说,但是大致是这个意思)。然后应用了一些 OCC 上的经典 Rules,同时把非事务的操作也囊括进来了(很难避免事务和非事务操作在某些方面上的冲突)
PointGet 始终会成功
读保证 RC 语义即可,可以看做它的时间戳:
- 大于等于已经提交的事务
- 小于 Prepare 的事务
反正 Point Get,在这个 Partial Order 的系统没有什么要和别人同步的。这个不会走 txn coordinator,直接路由到 Storage Node 就行了。
Single Put 可以直接写没有 Prepare 的 row
首先注意这里不会走 coordinator 节点,直接路由给 Storage。
这里单点的直接写是可以的,发现没有 Prepare 的 row 的时候,可以直接写入(Delete/Update/Put…)。如果是 checked-write 的话就不太行,这里论文也没太仔细论证,我感觉这个时间戳还是比较复杂的,类似 PolarDB-X 设计上的 1PC 的流程了
Single Put 可以直接 Buffer 写没有 Prepare 的 row
对于有 Prepare 的 row,这里可能会 Buffer 写请求然后分配一个 Later Timestamp。
这里它们还提了一个 further optimization:
- 如果是 unconditional Put/Delete,这里可以直接覆盖然后返回成功,之前的事务成功与否都不可见(类似 Thomas Rule 了,不同的区别是,Thomas Rule 可能要处理 Cascade Abort,但对于 DynamoDB,这类 1PC 操作既然做了就是一定成功的,不过我觉得这套东西实现的时候还是挺恶心的,估计不好查问题)。
对于最新写入是覆盖写的操作,旧时间戳的事务写可以认为与它无冲突
这个比较好理解,和上面一条原则差不多。但我觉得搞得太复杂了,对于 checked-write 这类 Merge 操作那你也要算上,这个本身时间顺序就从一个 ts 全序变成一坨 start-ts 和 arrive-ts 很混乱的东西了。
多条写同一 row 的 Put/Delete 事务可以 batch prepare
这条我没读太懂,这怎么敢的…把 Prepared 变成一组 vector?然后提交的时候更新记录,从 vector 移除自己?
如果是 partial update,那么需要全序,否则可以并行 prepare。
我还是那个问题,你 checked-update 要排序怎么办。。。感觉我就没理解这个 check 的语义…如果 check 的语义就是检查元数据的话倒是没问题,但是这个包括检查数据,估计要么走写协议,要么走读协议,不然看着非常别扭。
Read 可以不用走 OCC 的两轮流程
This GetItemWithTimestamp operation returns the latest value of the item if its last write timestamp is earlier than the given read timestamp and if any prepared transactions have later timestamps, and otherwise rejects the request.
这部分概念简单,但是有一个分布式系统时间戳回退的问题,这部分有点像 TiDB 的 async-commit 提到的读水位维护。要求后续更新 row 不能低于这个 Max-Row-Read-Ts。
题外话,这傻逼文章之前还说不想维护 read-ts,这下全回来了。
写同一个 Partition 的事务可以走 1PC
废话。
总结
本文描述了 DynamoDB 的分布式事务处理,亮点是相关的语义,但笔者觉得:
- 它缺少 scan 的场景,在 scan 场景下,DynamoDB 的读处理将变成一堆废物。不过反过来想,如果没有 Scan 支持,那我们也不一定需要做一个 MVCC 的系统
- 特定语义的区分。根据 Update 区分为不同语义和区分为是否是事务写,来做一些特定的事务优化。这些优化不是通用的,而且可能 break 系统 invariant,但是可能确实能优化一些特定场景。
Reference
- Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service https://www.usenix.org/conference/atc22/presentation/elhemali
- DynamoDB 事务相关的文档 https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/transaction-apis.html#transaction-conflict-handling
- AWS Time Sync https://aws.amazon.com/cn/about-aws/whats-new/2022/11/amazon-time-sync-internet-public-ntp-service/