schedule: Mesos
在之前博客中,我们介绍了 MapReduce 和 Spark 的框架,这两个的程序类型都是 Batch Job,batch job 这里会被分配到对应的机器上,由一个类似 master 的节点来调度或者监控它的执行。
对于小的任务来说,细粒度的调度是比较难控制的,从一些 Morsel Driven 的调度到 Scylladb 和 RocksDB 的一些例子,看着都很难,而且智能是在负载上、核心或者线程池上切分,做一些细粒度的调度,OS 下面也有一些调度相关的,比如非常经典的 CFS 调度。对于 Batch Job 来说,问题其实有那么点类似 OS (包括后来 Google 和 Meta 的场景,可能都类似一个分布式的 OS,对数据中心大量机器进行高效的调度和分配)。这里有一些区别是,任务可能会有一些先验的预期之类的。
我们讨论的 Mesos 是一些平台的前身,但同时,Mesos 也被捐献到 Apache 中,和 Yarn 类似的,广泛的进行一些 Hadoop 系 Batch Job 甚至小一些的任务的调度,并管理 MPI、Hadoop 等计算框架。Mesos 的论文发表于 NSDI’11,可以看到论文比较早,论文主要的点在于:
- 出现的时候,主要取代的是静态分片的集群
- 2级调度,来允许用户自己编写调度框架,Mesos 管理资源和调度框架交互。这样不能保证全局最优的调度,但是提供了 scability
- 基于两级调度设计的 api
- 有一些亲和度甚至是必要条件有关的考量
- 资源量对于应用/框架不够的时候,怎么处理
- 任务是否能够被 kill
- 对于资源占有了,但是没跑起来这种会死锁的情况,怎么处理
- 定义任务的平均执行时间和执行时间的分布,Mesos 的对应处理
这里我们也只介绍「框架」相关的,其实尽量避免介绍具体的策略,感觉策略要到 queuing theory 或者 DRF 的论文可以介绍一下。
两级调度
需求:Hadoop, MPI 等多个集群共享资源,而每部分可能会有自己的调度器。把所有的调度器整合到全局在工程上比较重(当然也可以,但是那要求中心化的调度 + 可能会比较粗糙的调度算法 + 不好复用框架自己的代码,因为每个框架可能对调度的需求不一样,然后人家写啥你写啥,如果卡顿一下搞得 master 卡住了就更是灾难了)。此外,这里需求还有 HA。
此外,对于那种同一组资源的多个集群,Mesos 甚至能给你拆两组 scheduler 然后自己跑在上头管,提供了很多方便搞事的方法。
综上,Mesos 没有选择中心化的调度,而是选择了两级调度:
这里 Mesos 可以给调度器提供资源,然后调度器决定具体 task 的运行,这中间有很多细节:,但是大致框架如下:
- Mesos 决定把多少资源给用户(resource offer)
- 调度器可以拒绝这些资源或者开跑,关切这里的具体调度
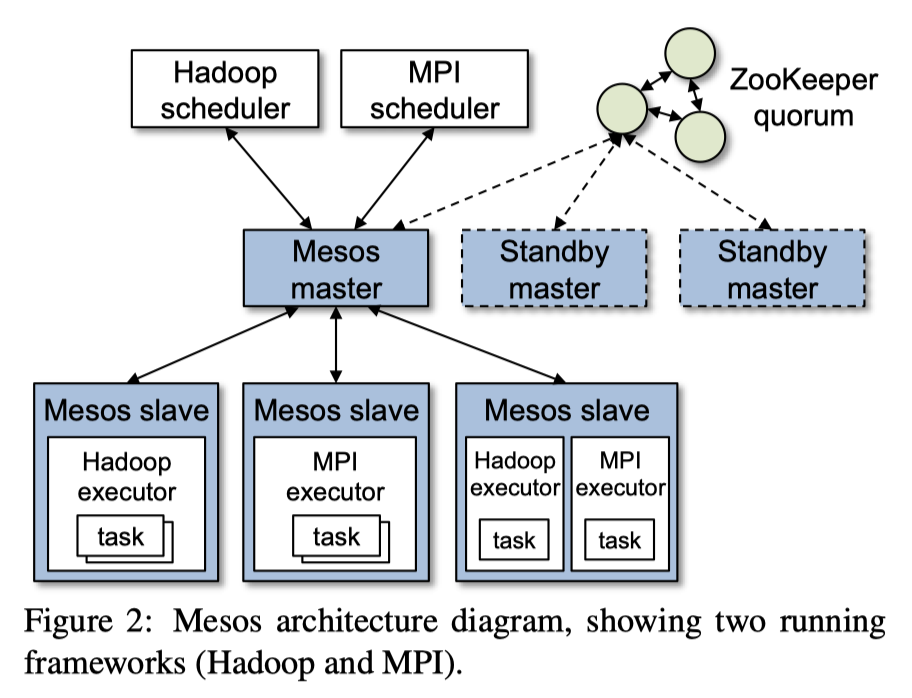
架构和例子
Mesos 的架构如 Figure 2,下面是个论文的的 Mesos 例子:
Mesos 会运行:
- Executor: 承载具体的 Task 的运行
- Scheduler: 核心的调度器。本身是一个轻状态,会有 backup 和 failover
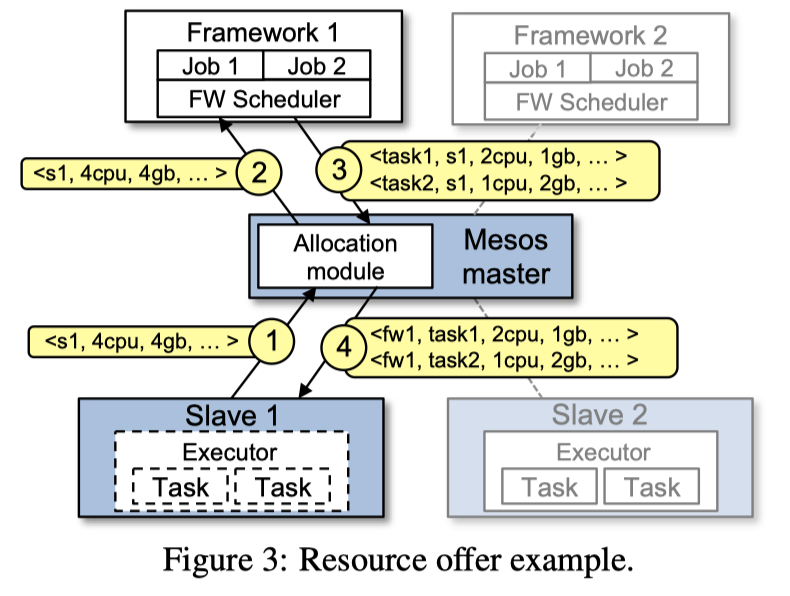
Figure3 展示了对应的流程:
- Slave 1: 汇报自身的资源
- Master 1: 决定提供给 Framework 1,然后告诉它对应的资源描述
- Framework 1: 调度后发两个 Tasks,每个 Task 也有对应的资源描述
- 任务被派发给对应的 executor
(这里考虑到机制上还有任务的 rit,failover 之类的问题,不过我感觉,因为大部分计算重复计算了也没什么问题,然后本身 master 是个弱状态的节点,所以这块相对可以比 tp 的 master,比如 hbase, 处理的粗糙一些)
那么上面这张图是个最简单的情况,实际上是有很多细节的,包括 corner case 和下面一些信息:
- 为了在接口上比较 clean,框架可以 Reject 资源,比如说 Mesos 给的资源不够的时候 Reject、不满足需求也可以 Reject。本身提供了一个 Reject 的可能,然后这个请求本身要走一轮 RPC,为了提前优化掉 RPC,框架可以编写 Filter,让 Mesos Scheduler 测提前过滤,包括设置 ip 白名单这种操作
- Mesos 认为 Filter 不是必须的,只是节省 rpc,当很多小的 task 的时候,直接 delay scheduling (攒着一些 slave 信息再发)的效果贼好,这种情况下没 Filter 性能也不错
- Mesos 在论文写作的时候支持两种 filter:
- 只支持 Set 中的 Executor 节点
- 提供支援的时候,至少需要 R 的资源
- 原则上,其他 Filter 也能支持(rnm,那你还写这么多?)
- 在写这篇论文的时候,Scheduler 的调度算法是 min-max fair sharing 的调度,当然一段时间之后,他们就搞了 DRF. 如果都是短作业,然后一个 10% share 的框架可能需要等待 10% 的执行时间,但是如果有一些大 task,这里调度会受到一些影响。Mesos 允许 revoke(kill) 对应的 task,然后给应用一个 grace period 来清楚对应的 task。当然有一些 Job,比如 MPI 这种 dependency 比较复杂的,也可以通过 guaranteed allocation 来申请一定的资源,这种情况下,在这个框架申请的资源在 guaranteed allocation 之下的时候,Mesos 可能就不太会去 kill 它了(可以看作是一个低水位)
- 论文写作的时候,isolation 还没啥好的机制,掠过不讲。
- 在申请资源的时候,回到上述步骤,这里在 (3) Scheduler 收到框架信息的时候,Mesos 才会把资源占用计算给它(感觉这个在处理挂掉的 Framework 的时候有一点乐观,可能极端情况资源会发出去几份?虽然我觉得计算层面挂掉问题不严重,不过跨几个系统处理问题终归有些麻烦)。实际上如果框架很久不返回,Mesos 会 rescind 回收相关的资源,然后允许把这些资源调度给别的框架)
- 关于 Failover:
- 如果 Mesos Master fail 了,那么允许拉起。这里还运行了一个 zk
- 如果 Mesos Executor 挂了或者任务 crash 了,可以交给 Framework 处理
- 如果 Framework 挂了,Mesos 允许用户在 Framework 测注册一组,允许从顶上去

这里 Scheduler Callback 是用户调度器,Executor 是对应的执行器。Callback 是被 Mesos 执行的操作,Action 是主动对 Mesos 执行的操作。
Mesos 的行为和优化
这里对 Mesos 的行为进行了建模:
- Framework ramp-up time: 一个 framework 调度到 task 的时间
- Job completion time: one-job per framework 的情况下的调度时间
- System utilization: 集群利用率
这里考虑到的调度和计算任务相关的一些性质:
- Elastic: 是否和 MapReduce / Dryad 这样能调整对应的并发。这并不是说调整任务 dop 这种,而是说可能可以分开来 task 完了就停止了,比如对应的 MPI 就不能直接具备这个能力(rigid)
- 对资源要求的 mandatory 或者 preferred
- Mandatory: 强制的要求,比如要在有 GPU 的机器上执行
- Preferred: 要求,只是调度亲和性这种逻辑。
- 暂时假设 mandatory resources 不会超过 guaranteed share,防止出现死锁的情况(TBD: 话说一般的调度框架是怎么处理死锁的呢?)
- 暂时分成 slot-based 的 min-max share
Homogeneous Tasks
We consider a cluster with n slots and a framework, f, that is entitled to k slots. For the purpose of this analysis, we consider two distributions of the task durations: constant (i.e., all tasks have the same length) and exponential. Let the mean task duration be T, and assume that framework f runs a job which requires βkT total computation time. That is, when the framework has k slots, it takes its job βT time to finish.
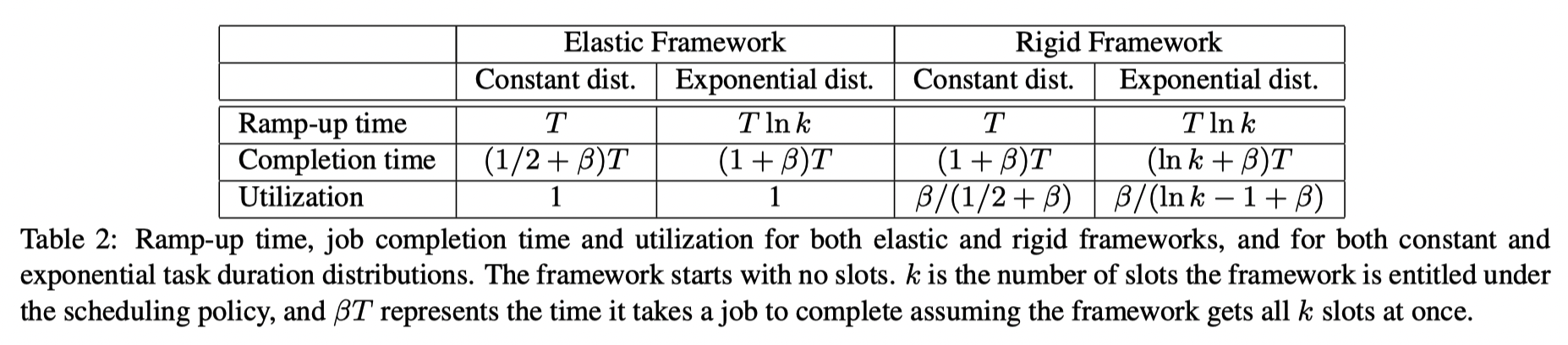
- 对于 Ramp-up time, 如果分布是 constant,那么 T 的时间基本上都会调度到。如果是指数分布的,那么可能会有 Tlnk 的期望时间.
- 对于 Job completion time, Elastic 这里比较简单,Rigid 里面要拿到所有资源才能开始
- 利用率同上
Preference
在引入 Perference 的时候,内容会发生一些改变。当每集群 prefer 都够用的时候肯定没问题,出现抢占的时候,这里可能会用类似彩票调度的方式来分配。
Heterogeneous Tasks
这里主要指的是大 task 和 小 task 都有的场景。
Such heterogeneous workloads can hurt frameworks with short tasks. In the worst case, all nodes required by a short job might be filled with long tasks, so the job may need to wait a long time (relative to its execution time) to acquire resources.
In particular, we can associate a maximum task duration with some of the resources on each node, after which tasks running on those resources are killed. These time limits can be exposed to the frameworks in resource offers, allowing them to choose whether to use these resources. This scheme is similar to the common policy of having a separate queue for short jobs in HPC clusters.
References
- 集群调度系统的演进 - 邵明岐的文章 - 知乎 https://zhuanlan.zhihu.com/p/51790388
- 号称了解mesos双层调度的你,先来回答下面这五个问题! - 网易数帆的文章 - 知乎 https://zhuanlan.zhihu.com/p/49429953
- 让你彻底搞明白YARN资源分配 - 斜杠代码日记的文章 - 知乎 https://zhuanlan.zhihu.com/p/335881182
- 久经沙场的集群管理系统调研:Borg, Twine, Protean, Mesos, YARN and K8S - Peter的文章 - 知乎 https://zhuanlan.zhihu.com/p/388355341
- Hadoop YARN:调度性能优化实践 - 美团技术团队的文章 - 知乎 https://zhuanlan.zhihu.com/p/76697106
- https://draveness.me/papers-mesos/
- https://draveness.me/system-design-scheduler/
- https://blog.mwish.me/2022/05/29/Scheduling-Blog-Overview/