Snowflake: Streaming and Change in Table
What’s the Difference? Incremental Processing with Change Queries in Snowflake 是发表在 SIGMOD’23 上的论文。描述了 Snowflake 内部的增量计算场景。这个部分有点类似 Streaming 或者说什么,Snowflake 可以在表或者 MV 的对象上开启 STREAM, Stream 内会包含 Snowflake 产生的类似 CDC 的数据 CHANGES,然后,Snowflake 本身能够根据 Time Travel 的功能来跑出 STREAM 上的 CHANGES,下游会消费这个 CHANGES,来用增量构建 diff。Snowflake 声称这套代码已经跑三年了,另外,这套论文的第一作者是 MillWheel 的作者。什么刘式家族。
Streaming System 和 Batch 的大乱斗有悠久的历史了,作者认为这其中的区别在于:
- Batch 需要处理整套输入来产生输出
Streaming 处理的是「增量」
* 可能会做一个 Partition,单个 key 的处理在 Partition 内是按行操作、序列化的
Snowflake 做了下面的概念区分:
- Tables: 每个时间点内,表的完整状态
- Stream: changes to a dataset over time, 表示 Tables 上发生的「变更」(类似 Redo Log 流?但是是更上层的概念)
Snowflake 倾向于「用户可以直接查询 CHANGES」的方式,并且认为有这样的 Usecases:
- Event Queuing: 给 SQL 一个 message queue 的语义
- Notifications: 论文认为消费
CHANGES表,相对来说资源开销会小很多 - Incremental View Maintenance(IVM): 给上层实现增量 MV 维护提供比较好的工具
- Flexible Change transformation: 消费 CHANGES 的时候,有的用户只关注一部分,并且这种 CHANGES 走 SQL 的话也算有优势
Snowflake 提供了下面的语义:
- CHANGES:对表或者增量 mv 的变更
- STREAM: 对表或者增量 mv 的变更流,包含很多 CHANGES 和时间戳,需要消费来推进。
Semantics
Snowflake 把表构建为一个 TVR 模型(time-varying relations), 并构建了一个 Table + Redo Log 的模型,来捕获 SQL 中发生的 INSERT, UPDATE, DELETE 操作。在这里,Snowflake 先抽象成了 Delete + Insert 的模型。下面是论文中用到的 SQL 和时序,后面会不断回来看这个的:
1 | 12:00> SELECT * FROM people; |
下面是论文中的操作序列:
1 | 12:01> INSERT INTO people VALUES (3, 'Walter'), (4, 'Maud'), (5, 'Uli'); |
查询结果是:
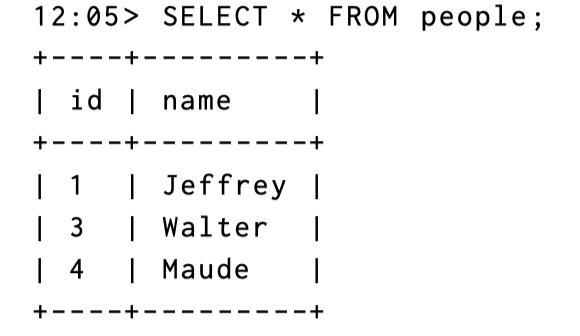
那么,这里逻辑上的 Redo Log 如下所示(这并不代表最终产生的 CHANGES):
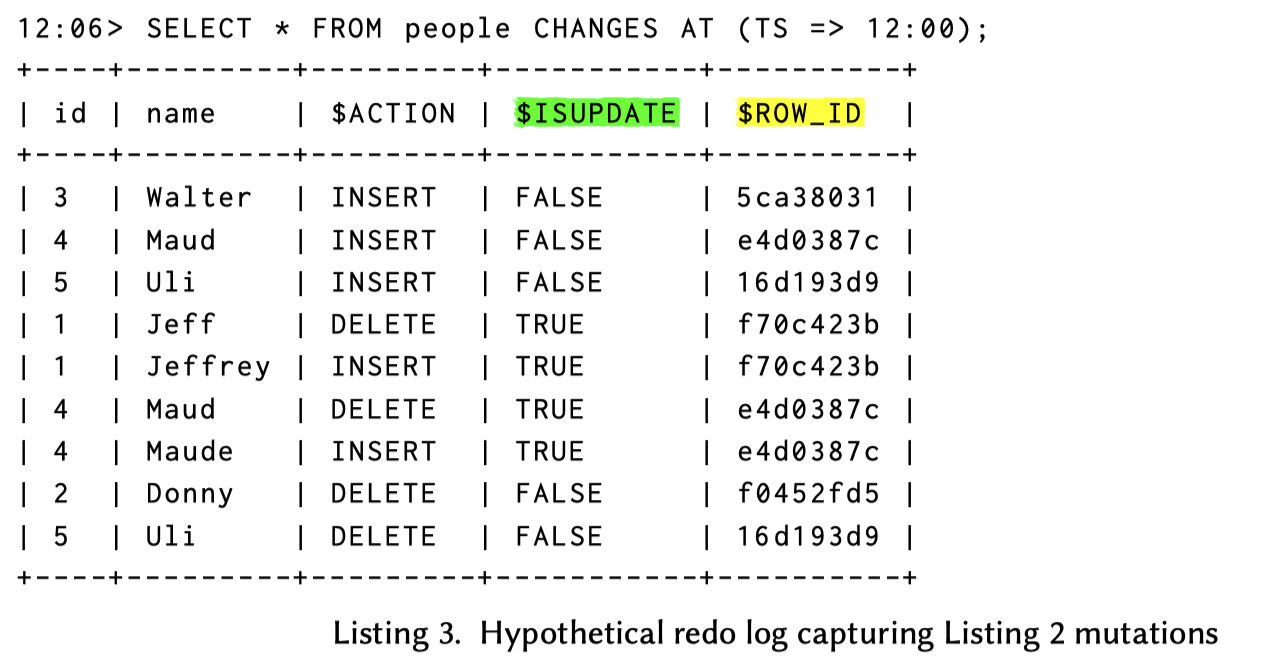
这种抽象对 Table 或者 MV 都有用,还是比较通用的,当然这里可能是说,需要在删除和插入的时候都带上完整的行记录,对于宽表来说还是有点大的。不过这年头我还是觉得简单就是好,大力出奇迹就行,优化什么的等客户有需求再说吧。
CHANGES quries
CHANGES query 是 snowflake 的一种查询 CHANGES 的查询,支持 SQL。Snowflake 早就支持了 Time Travel,用户可以指定 START 和 END 的时间戳,如果不指定 END 就是查询 START 到现在的数据,当然,除了时间戳,用户还可以使用 STREAM 对象来查询。
如之前 Listing 3 所描述的,在 CHANGES 查询的结果中,有一些 metadata columns:
$ACTION: CHANGES 是 INSERT 还是 DELETE$ISUPDATE: 对于 UPDATE,它在 CHANGES 中会变成 INSERT + DELETE. 在这种场景下$ISUPDATE = true$ROW_ID: 这个就非常有意思了。表示 Row 的 Unique Id,后面会介绍这个字段是怎么构成的
其实 (1) (3) 还比较好理解(但是需要细分一下 ROW_ID 是怎么构成的),此外 Snowflake 还支持查询 INFORMATION,表示 CHANGES 的元信息。下面介绍 Snowflake 的区分处理方式,Snowflake 目前支持两种 CHANGES 格式,这里都可以表示为类似 Redo Log 的形式:
- Append Only: 表示数据第一次插入表的日志,可能来自 INSERT, Merge, COPY 或者 Snowpipe(file-based) / Snowpipe Streaming(row-based)。UPDATE/Truncate/Delete 其实在这里都不会被记录。下面展示了在 Snowflake 查询 Listing 2 的 APPEND_ONLY 数据
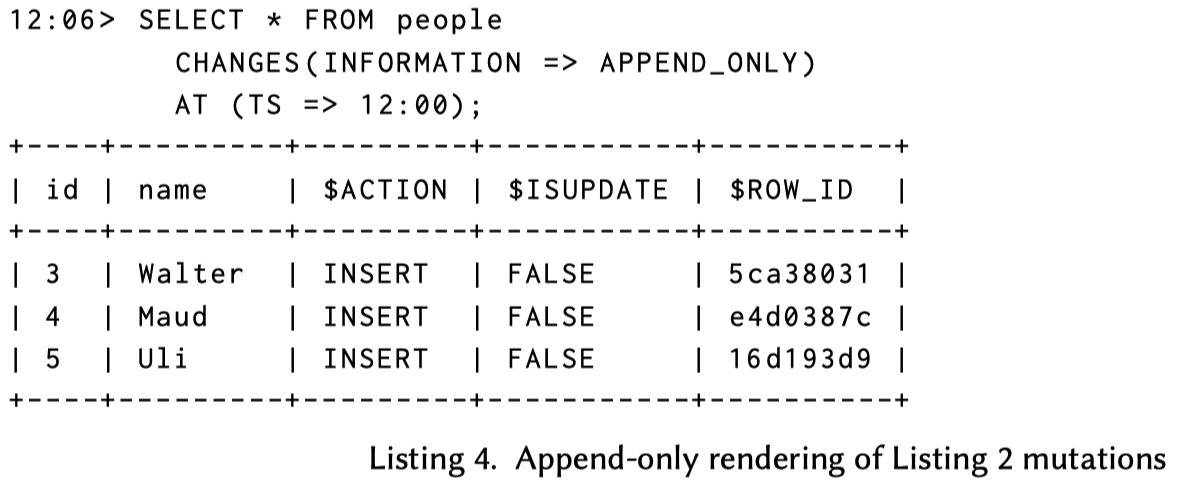
- Minimum-delta: 在指定的时间段或者 STREAM 变更内的 INSERT/UPDATE/DELETE等写 操作最小DELETE/INSERT集合(即合并重复操作)。这种操作相对于物理变化其实好处比较多,比方说用户跑了个 Merge 请求或者内部跑了个 Compaction,你 dedup 一下用户/下游幸福多了。
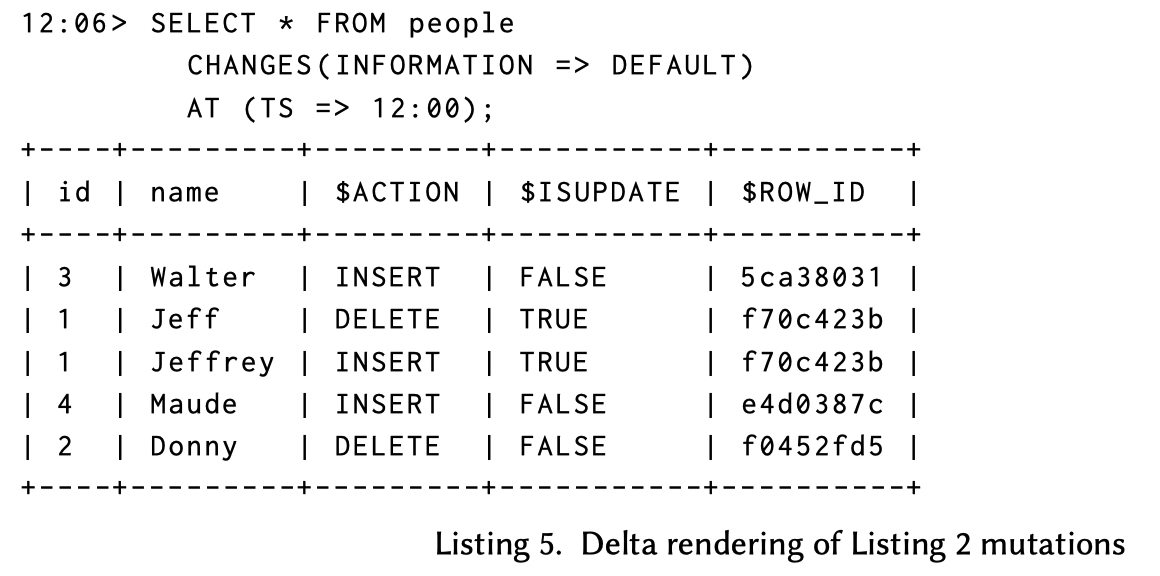
这里可以对比 Listing 3,可以看到对 id 4 的重复操作都被折叠掉了,对同一个对象( id 5 )的 INSERT - DELETE 也没了(可以拉上去对比一下)。
在这里,Snowflake 做了个比较有意思的评论:在审计场景中,所有记录都要是可见而不能被折叠,不过目前大部分用户觉得凑合着用就行,之后可能会把所有 CHANGES 都暴露出去。
这里有个问题是,delta 信息可能比 Insert 全一些,为啥还需要 minimum-delta
CHANGES queries on Views
之前例子中的 CHANGES 都是对表的,下面有一个比较恶心的:对 View 的 CHANGES.
- Append-only CHANGES
- Monotonicity: 这里定义了 Monotonicity, 即插入一条数据是否保证最终的插入,例子是 Anti-Join,可能表 A 插入一条数据,Anti-Join 的 MV 会减少一条数据。这里认为不是很方便的直接计算到 append-only changes,所以这里只允许 append-only changes 提供给 monotonic query(mv)
- Repeated inserts: 有一个例子是同一条边被插入 - 删除 - 插入 ,第二次插入是否要被包含。这里认为不需要包含,它认为这样会让实现更简单一些(哪里更简单了呢)
- Minimum-delta CHANGES
- Excluded Columns: 对于 Filter 条件来说,Base 被 Filter 掉的或者是根本和 mv 没关系的列,MV 不会再出现这样的 CHANGES
- Update coercion: 对于 Excluded -> INLUDED 的请求(比如 UPDATE),这里会将上游的 Update 变成 CHANGES 中的 INSERT
接着举例子:
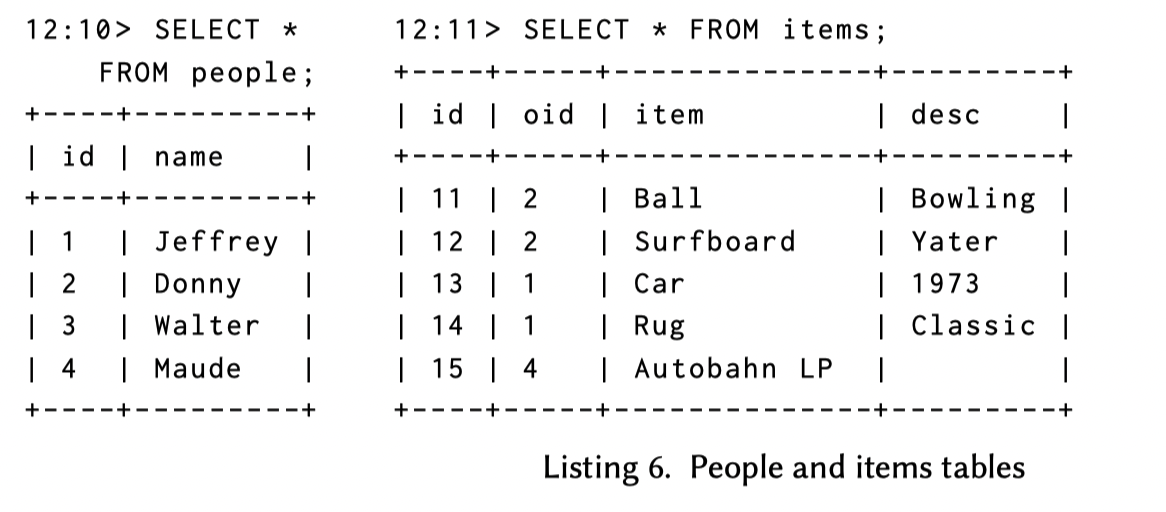
Oid 是 id 的 foreign key, 下面创建一个 inner join 的 mv:
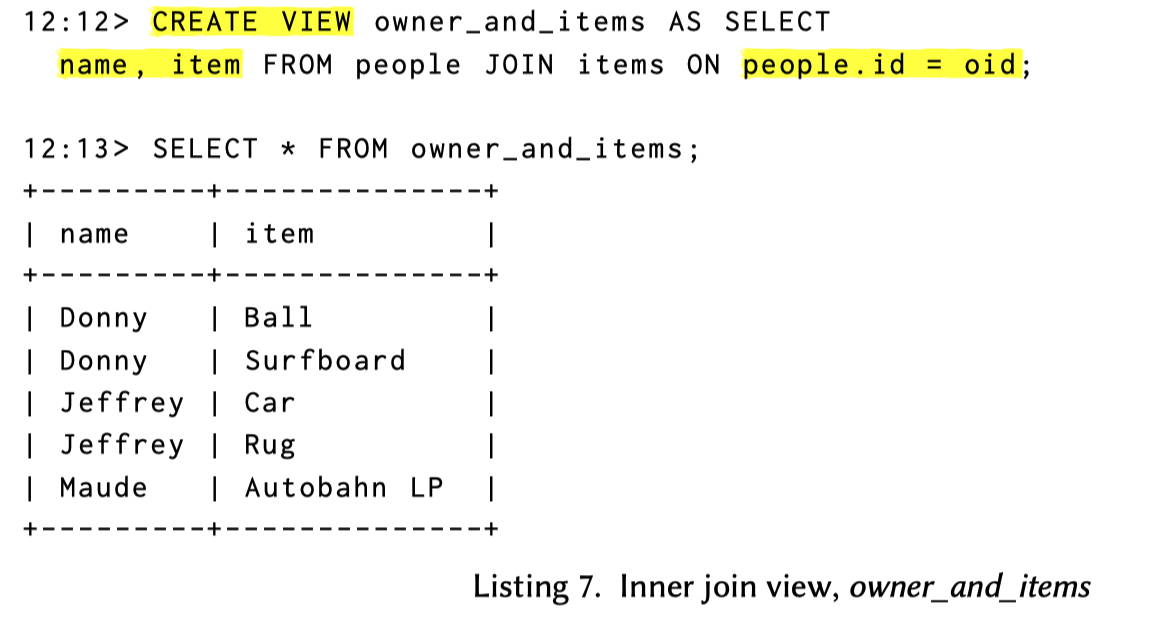
下面描述了一些变更操作:

- 这里比较好玩,第一个 SQL 相当于最终 mv 的一个 UPDATE,产生了 DELETE + INSERT
- 第二个 UPDATE 在 Base 表是一个 UPDATE,但是它导致 mv Join 变更了,相当于 Delete + Insert
- 第三个更新
desc列归属于 excluded column,所以没一点影响 - 第四个 DELETE 会导致 mv 两条 Delete (感觉它的 fk 不是强约束,总觉得在 db 这种数据很难删)
STREAM Objects
CHANGES 是一个比较好用的工具,而 STREAM 则是 CHANGES 和表的状态维护。能够完成存储状态和容错等功能。我们列举 STREAM 的逻辑:
- 表(persistent or view) 级别,对应一个 schema-level catalog object ,绑定于 source view (表或者 mv)
- STREAM 的状态叫 frontier,代表 CHANGES 被消费完的一个时间点(类似 ckpt?)
- Stream 可以被 consume:
- 被查询的时候,STREAM 生成 frontier 到现在的应用
- DML 操作 STREAM 的时候,STREAM 会在 DML 的事务中被处理(原子性),当事务 COMMIT 的时候,推进 STREAM。
- 一个表可以创建多个 STREAM
- STREAM 支持 show initial rows,在 STREAM 被第一次消费的时候,它的数据包含表的数据(我猜是全部都是 INSERT 的形式)。这个让整个 STREAM 构成一个能恢复整个表的 redo log 流
下面展示了 Listing 1/2 的 STREAM


(这里 idea 还是挺明显的)
作者认为,STREAM 引入的存储开销比较小,相对的只需要存储 frontier,所以作者觉得 STREAM 可以随便开,当然论文也提到了,STREAM 本身和表的 retention policy 有关,这里认为 STREAM 本身也依赖表的 Retention 策略,如果下游某个时间戳的表 GC 了,那么这里会表示文件再也捞不到了,所以 STREAM Stale 了。当然 Snowflake 本身有一定的 Time Travel 机制和 Retention 相关的,它允许维护、延长一段时间的 Retention,直到这个数据真的 Retire 了。
Implementation
Snowflake 希望能够尽量复用以前的组建和机制、也减少客户的负担(废话)。这里要求:
- 给 Storage Layer 增加 Row-Level Metadata
- Query differentiation framework to Rewrite query
- Integrate STREAM with Transaction system
这里,论文总结了一下 Snowflake 的架构,然后介绍了一下它们是怎么实现 STREAM 的。
Table Metadata
Snowflake 的表在数据上由多个 micro-partition 组成,他们是大小不一的数据文件,以 z-ordering 之类的形式来组织,存储在 Blob Storage 上,元数据存储在一个 FoundationDB 集群上(妈的现在 fdb 的贡献者全是 sfc-gh 家族了,迫真占领社区)。Snowflake 有一个 table version,来表示 Table 的状态:
- System Timestamp
- Set of micro-parititons
- Partition-level statistics
而表的状态也类似连续的 Redo Logs:
- INSERT 等操作插入新的 micro-partitions
- DML 的操作的 Micro-partition 级别,比如 CoW 那种就是 Delete / Insert;或者干脆直接删了
- 上述都走 Transaction 提交操作
- 如果超过 Retention,去回收数据
表的版本和查询的版本直接关联,metadata system 首先会拿到时间错对应的 table version, 拿到对应的 micro partitions
Query Differentiation
查询的模型
这里的技巧在于,把查询改写为增量 mv 的查询我原封不动贴一下论文的模型:
given that we want the CHANGES of a query 𝑄 over an interval 𝐼, we say we differentiate 𝑄 to obtain the derivative of 𝑄 , Δ 𝐼𝑄 , which varies over 𝐼.
这里会根据上面几部分来改写查询,下面是数学部分,我只能看懂大概(悲),大概是 Join / Filter / Project / Agg 拆分成增量的形式。

当然,等量代换完成之后,就涉及到代价的问题了:
- Inner Join 之类的代换可能性能及户都会有优化
- Agg 之类的,如果大部分 key 被修改了,性能可能会一坨
所以这里丢给 Cost-based Optimizer 去自己评估了。
Change Tracking
Snowflake 会在 TableScan Operator 处理增量,它需要在 TableScan 捞出 changes。这里会利用行上的 metadata 来处理,Snowflake 给行上启用了 properties:
- A unique id. Stable across updates (还记得 min-delta 上的嘛)
- Whether the row was inserted into the current micro-partition or was copied in from another.This information makes it trivial to produce append-only changes. (行的来源,但我觉得这个在 Compaction 之后计算很蛋疼啊,包括 insert + compaction,你总不能每一行去 traverse version chain 吧,迫真 MVCC,不过它也处理了这个问题)
这两块我觉得存储开销肯定还小,因为列存一压很多东西就没了,但是我觉得这套框架和别的合起来还是有问题的。当然,这里肯定会有重复(redundent delta),于是 query rewriter 会在上面区分这个查询是否会产生 delta,如果可能有 delta 就属于 redundant-delta properties,给你嗯加一个 consolidation 去去重。Snowflake 发现大部分 CHANGE QUERY 只有 一堆INSERT 或者 一堆 DELETE,所以它提供了不少 Plan Shapes:
- MINIMIZE
- ADDED_ONLY
- REMOVED_ONLY
考虑到这个,在 planning 的时候,这里会找到 INSERTED micro-partitions 和 DELETED micro-partitions(这个对 Compaction 也生效),然后进行下面的 Plan,那个 UNION 就很精髓,Minimization 看下面计算的性质。这里还有个 ISUPDATE 计算,我们一会儿讲。
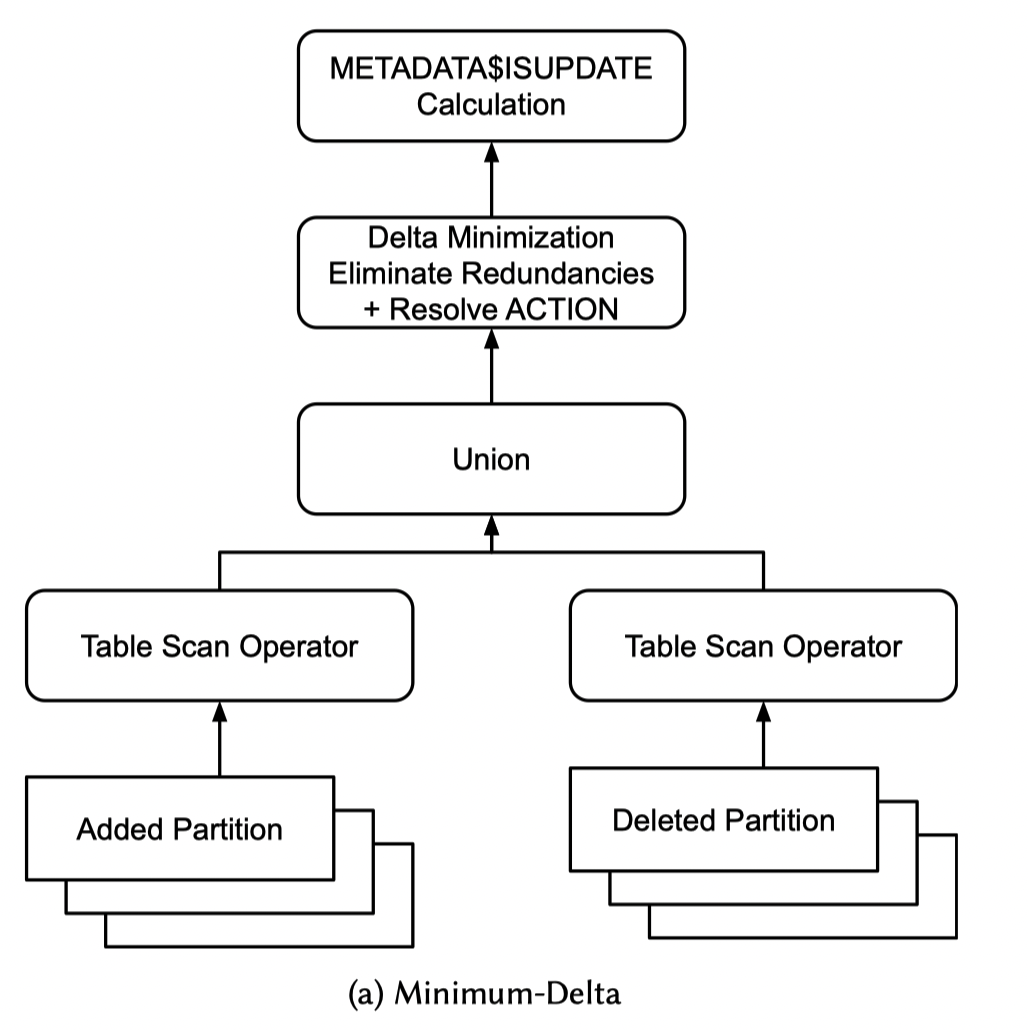
对于 Added 来说,这里会找到:
- 所有 Added Partition,包括 Compaction 产生的
- 扫描所有记录,只有行来源不来自于别的文件的才会被记入
这个算法也是比较简洁的
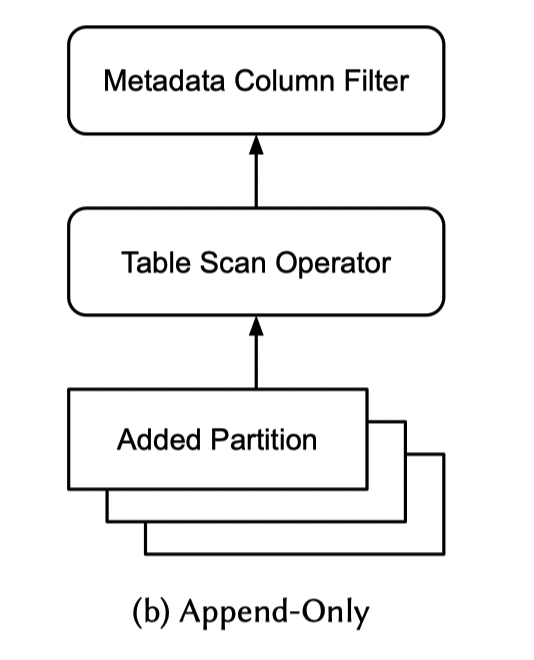
在元信息上,关于 ACTION 的计算是很简单的,ISUPDATE 的计算会是最终合并的(而不是中间的操作),总的说它只看起止。
比较重要的是 $ROW_ID,这个东西设置了可能就没那么好改了:
- 可以是有含义的语义,但是可能会对系统未来的 evaluation 造成兼容性负担(也不那么会把?)
- 可以是没有含义的语义,比如 Hashing Columns。因为这里也希望 TableScan 之类的时候,不会对 Shuffle 之类的内容造成太大的负担
- Our row IDs are a cryptographic hash of the change tracking columns, which ensures uniqueness to a very high probability.(比如 geohash 或者类似的?猜测和 row 还有 partition 有关)
这里还有个问题是,上面作为 base 表的,那么作为传下去或者 mv 的呢?这里的处理方式是:
- Filter / Project 不改变 row-id
- Group By 根据 Group-by Agg Keys 来做 row-id
- UNION ALL 在同一张表的 Filter 的时候,可能相对复杂一些
Snowflake 说他们没遇到什么 corner case,什么绿皮暴力搞法大力出奇迹。
Stream Transactions
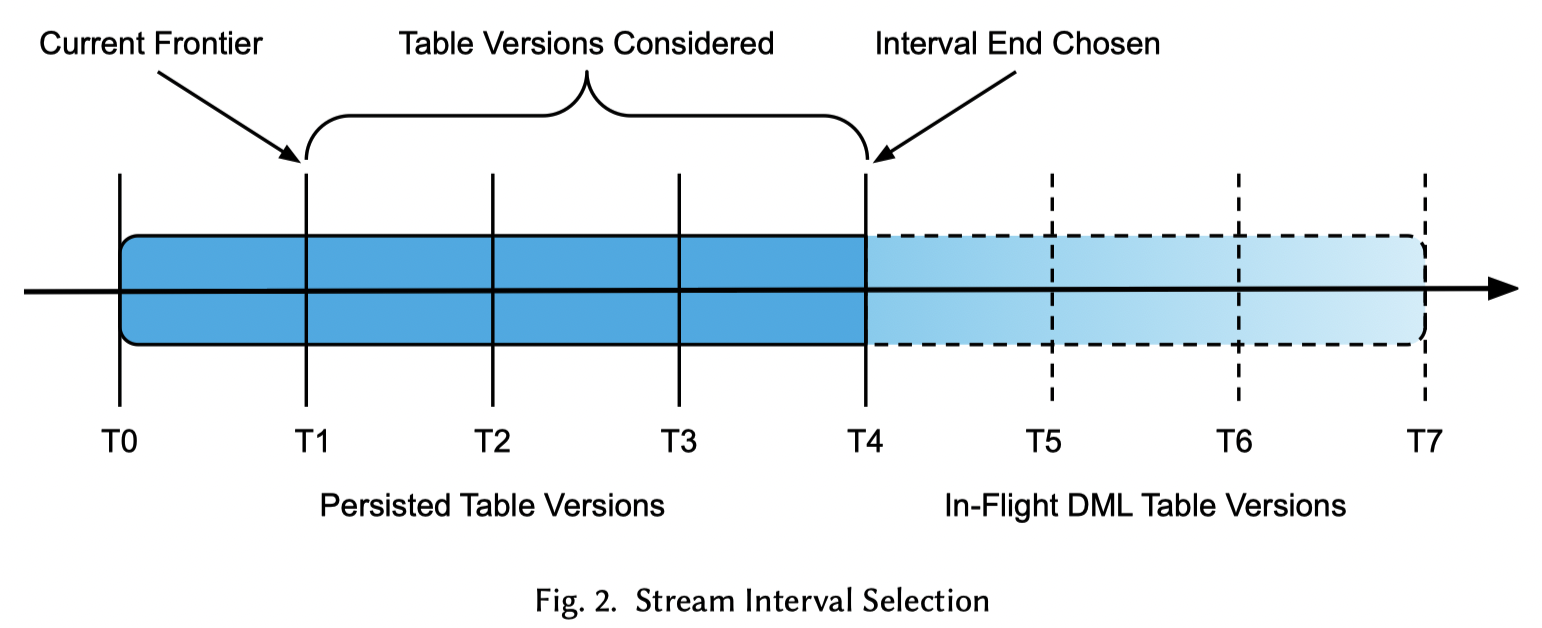
在 STREAM 被查询的时候,这里会尝试消费,消费的时候会满足原子性。
- 如果设计单个 Table,那会很简单,但是多个 table,会比较蛋疼,因为 snowflake 好像没有全局时间戳。这里 frontier 会检测多个 base table 的版本,来保证 STREAM 内部不会有冲突
- STREAM 本身代表过去的时间戳,所以它自己要存时间戳,这里也会有个 last updated 的物理时间戳
- 在消费 STREAM 可能会有事务,所以一个 STREAM 可能不能被多个客户端消费
- Staleness 会根据 Retention 来维护
USAGE AND PERFORMANCE ANALYSIS
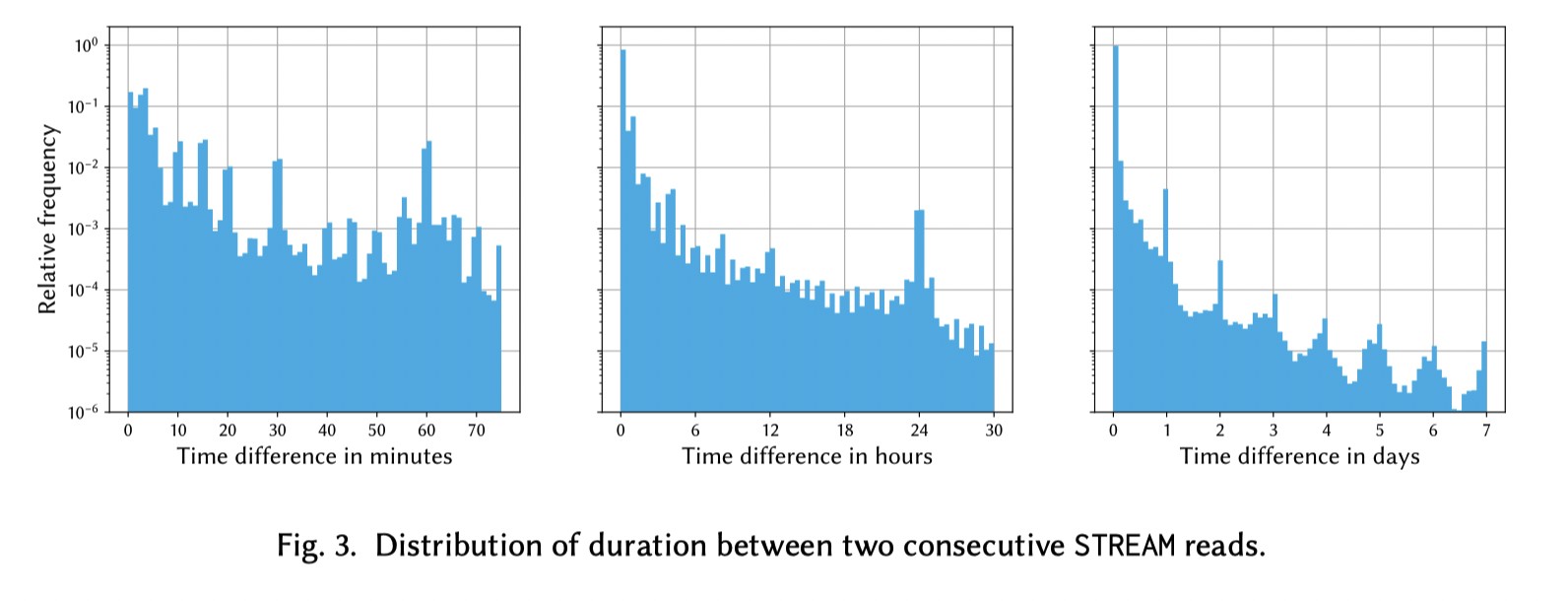
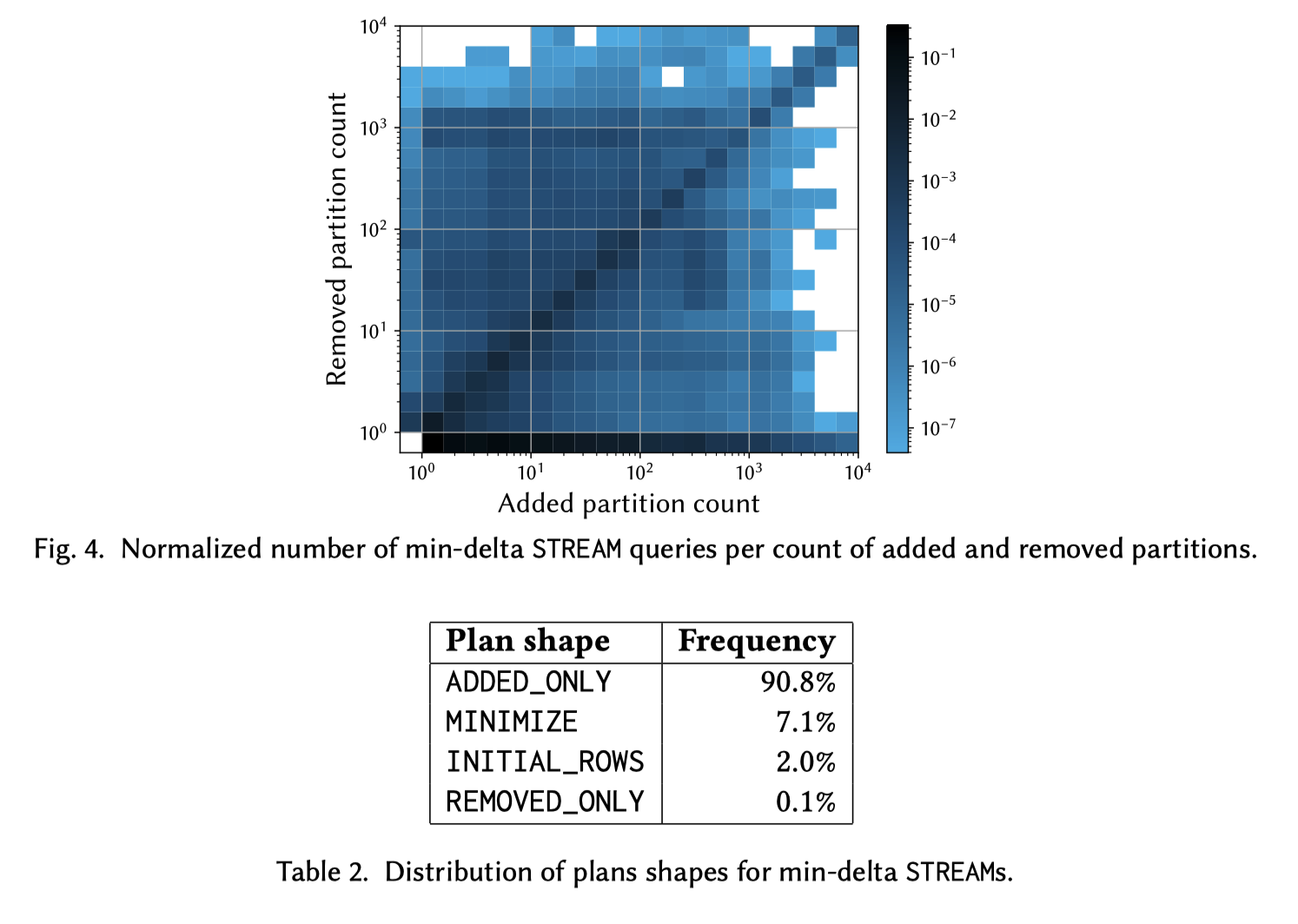
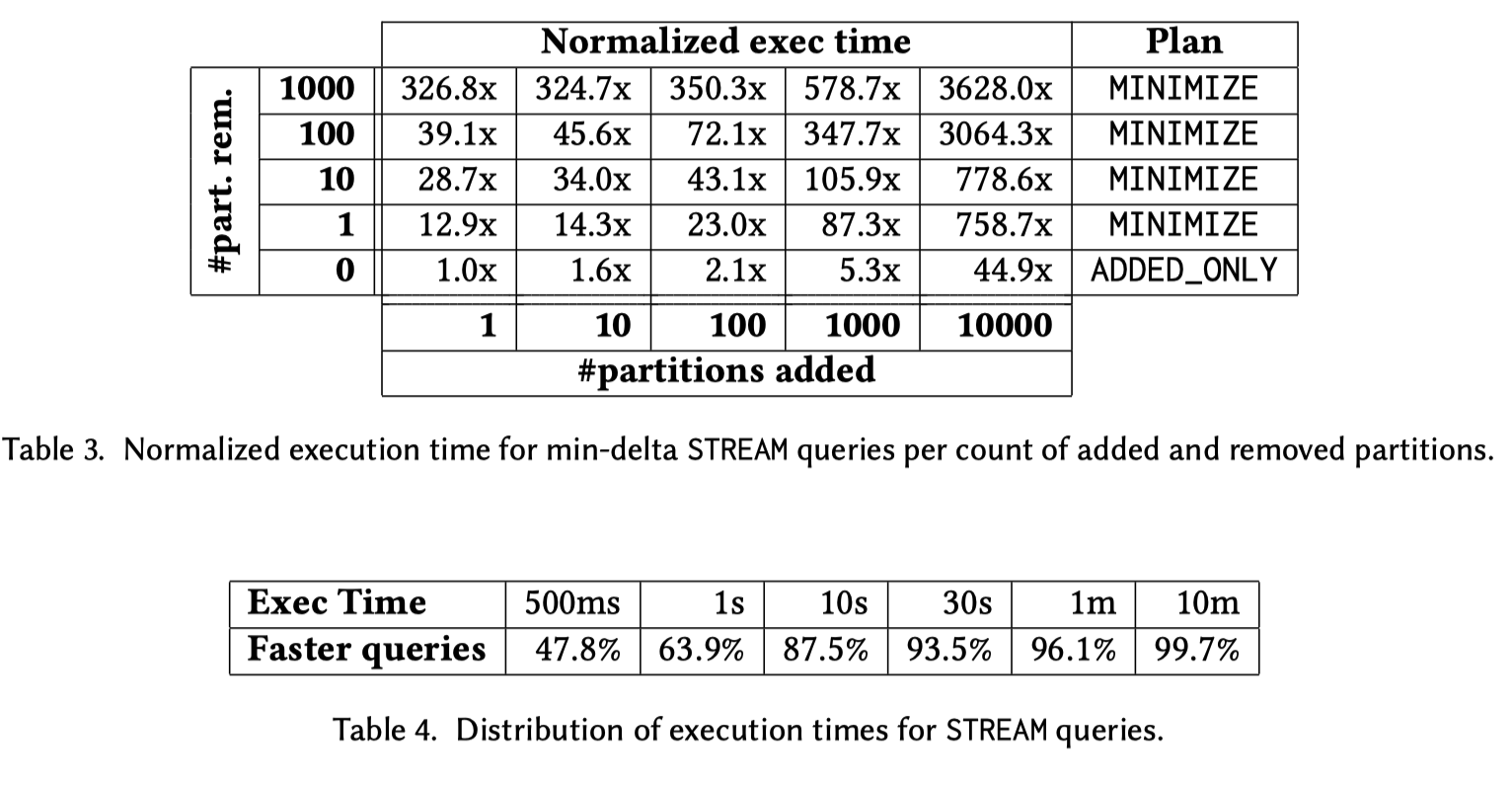
批话环节
这篇文章描述的内容还是很朴素的,我当时以为有啥大招,但是还是硬扫。这块难度应该不在存储上,对查询改写、优化器甚至上游调度开销会比较高。而且很多东西还是 Open Problem。期待厂商还是能把这套机制和 Live Table 之类的结合起来,或者提供一些 Streaming 的算子,抽象出一个更高效的框架。