Spark: RDD design
以 2023 年的视角来看,MapReduce 是个过度力大砖飞的软件,它强调强制的 2个 Stage (一些其他第三方之类的方案会有别的 Stage),然后 Stage 中间 Sort + 落 HDFS 文件来做 Shuffle,靠 Reducer Pull 来传输数据。这样的计算流很固定、性能比较低效,但是相对来说确实是个力大砖飞的方案。
Spark 之前,首先是微软在 SCOPE 系统和 DryadLinq 之类的地方做出了贡献,包括 DAG 一样的计算流、(类)SQL 的支持,但是 Spark 确实是开源社区很早掏出来的,并且在今天已经茁壮成长为了 DataBricks 这样的巨大公司和拥有了庞大的周边生态,可见这套东西打法还是很重要。Spark 支持的对象有 DataSet/DataFrame 和 SQL 甚至 Streaming / ML 等多个目标的庞大系统。不过我们会在之后的内容中提到 Spark SQL 甚至 DataFrame,我们今天只涉及 Spark 论文中提出的 RDD。
RDD
Spark 最初版本整个在 Scala 上编写,它提供的抽象是 RDD。在论文写作的时候,它只做一些 Batch Exec 的计算,并且论文中提到的优势场景包括 iterative algorithms (eg: 图计算,ML 的训练) 和 interactive data mining tools(给同一份数据发多次 adhoc query). 同时,RDD 的目标是尽量用上内存(利用上内存并不难,但是 MPI 可能需要知道对应机器的位置,此外还需要能够从故障或者 worker failover 中恢复出来)、利用 Intermediate result。
相对于 MPI, Pregel 等系统,Spark RDD 构建的是一种粗粒度的抽象,它:
- 类似 Fp,本身是 immutable 的
- 描述计算过程,同时也有一些相对 internal 的东西, 比如 Partition。也允许有
persist(持久化) 和cache(缓存/物化结果并尽量在内存) - Parallel:因为 RDD 只描述计算过程,同时一些 Map 累的计算流程通常是相同的,所以允许 Parallel 的去执行。当然也可以根据 partition 之类的东西来决定这部分的描述
- Fault Tolerant: 这个 FT 名字有点抽象,并不是和 TP Workload 一样的 FT,而是和 MapReduce 那种没算完或者挂了,就去重新 Exec 对应的任务
上面的部分其实有点抽象。不过后面都会讲。论文先举了两个 RDD 的例子:
1 | lines = spark.textFile("hdfs://...") |
这里的计算流程可以如下所示:可以看到 RDD 要么来自文件输入(lines) 要么来自对之前 RDD 的 transformation。
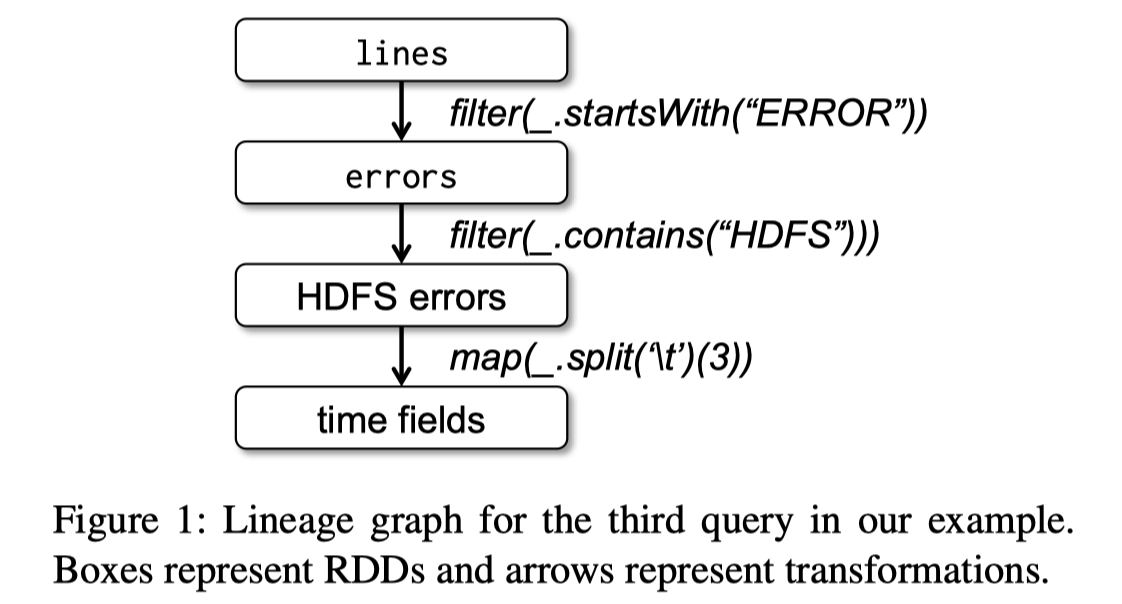
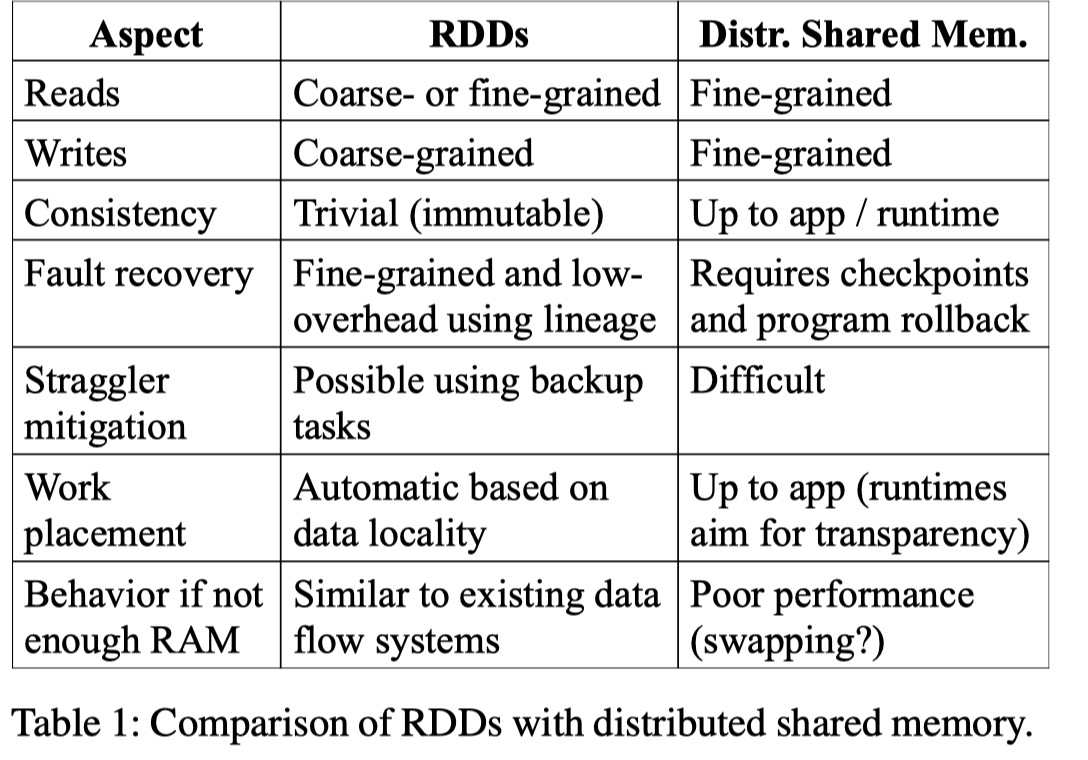
文章也对比了 Spark 和 Distributed Memory 的优势(不过我个人认为 RDD 和 Distributed Memory 完全不是一套东西,也用在不同的场景,我现在觉得 Distributed Memory 是 “Internal”)下面的表格吹了很多有点,但我觉得主要区别还是:
- Spark 自己维护了 lineage,表述数据的构造和血缘关系
- 声明式需要某种计算 vs 具体实现对应的计算
- RDD 在内存不够的时候也可以 downgrade 成类似 MapReduce 那种模式(利用 Spill 和 Shuffle)
别的都是虚头巴脑的,感觉扯来扯去浪费时间。
这里论文还描述了一下不适合 RDD 不适合 Streaming 或者小亮多次更新的应用,看见 DataBricks 的 Live Table,我陷入了沉思。嘛,技术是发展的,Delta-IO 提供的数据湖本身也是一种绕弯弯的方案吧。
Spark Programming Interface
Spark 的 Cluster 模式如链接所述:https://spark.apache.org/docs/latest/cluster-overview.html 。本身把 worker 部署的时候部署在机器或者容器上,有 standalone, Yarn/Mesos 调度, Kubernetes 模式。这里有几个(全宇宙都一样的)模型:
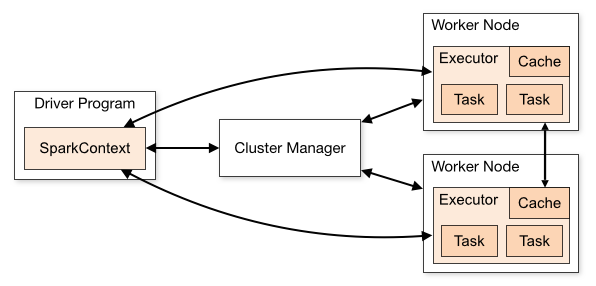
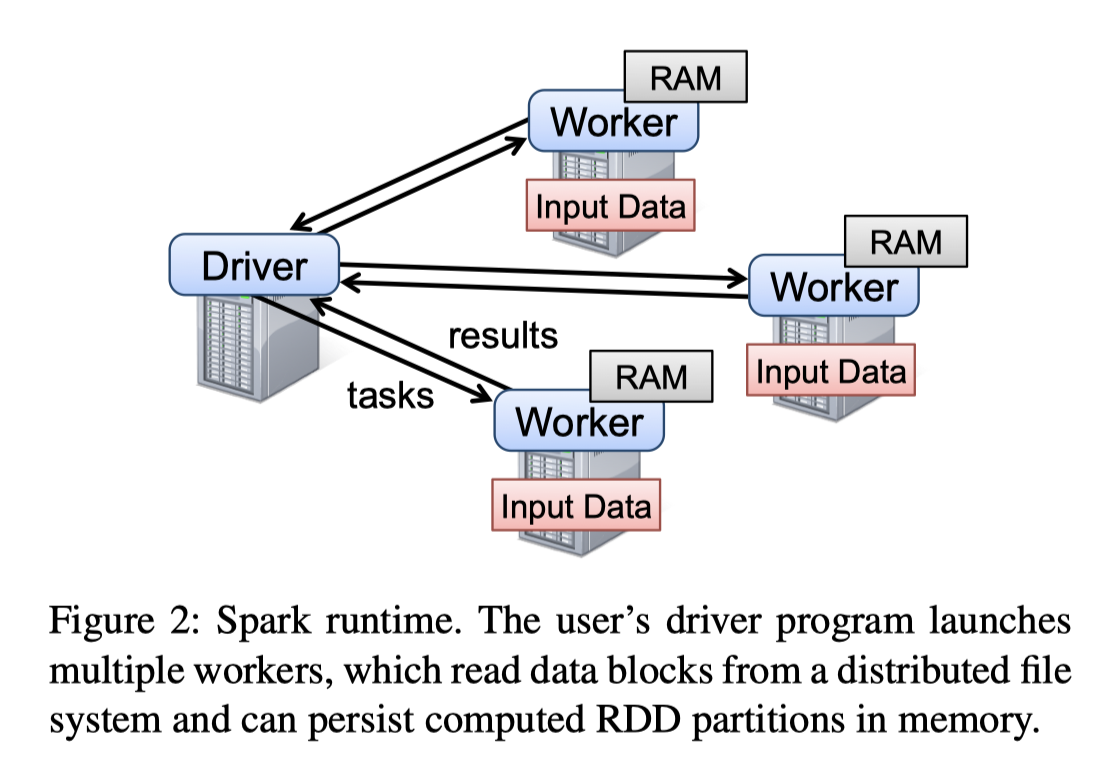
用户可以用 Scala 编写 RDD,RDD 是带类型的对象 RDD[T], 对 RDD 操作分为 transformation 和 action,里面内容其实非常好理解(我感觉一些带副作用的在这里反而显得有点怪):

这里会显得有点混乱,但是其实很简单,首先这些功能差不多都是函数式或者 db 类似的原语. 这里有几个值得注意的:
joinunioncogroupcrossProduct: 令人熟悉的数据库老朋友sort: 懂得都懂(其实类型上 sort 还没有,我感觉类似会有个 properties 的东西在里面?)partitionBy: 需要注意的是,这里指定的是类似「物理执行」的属性,这点感觉其实对性能之类的相对来说比较重要,举个例子,比如本身可能走 shuffle 的计算,在 Partition 之后就不一定要走 Shuffle 了。
论文这里提供了一个 PageRank 的例子,其实 MR 之类的都会在这介绍 PageRank,什么公共靶场. 这里需要注意的是,它把 links 给 cache 下来了,然后在每一步都可以用这个基本的 RDD,而不需要重新计算。这里有个 Python 的例子:https://github.com/apache/spark/blob/master/examples/src/main/python/pagerank.py (注意 cache 和迭代)
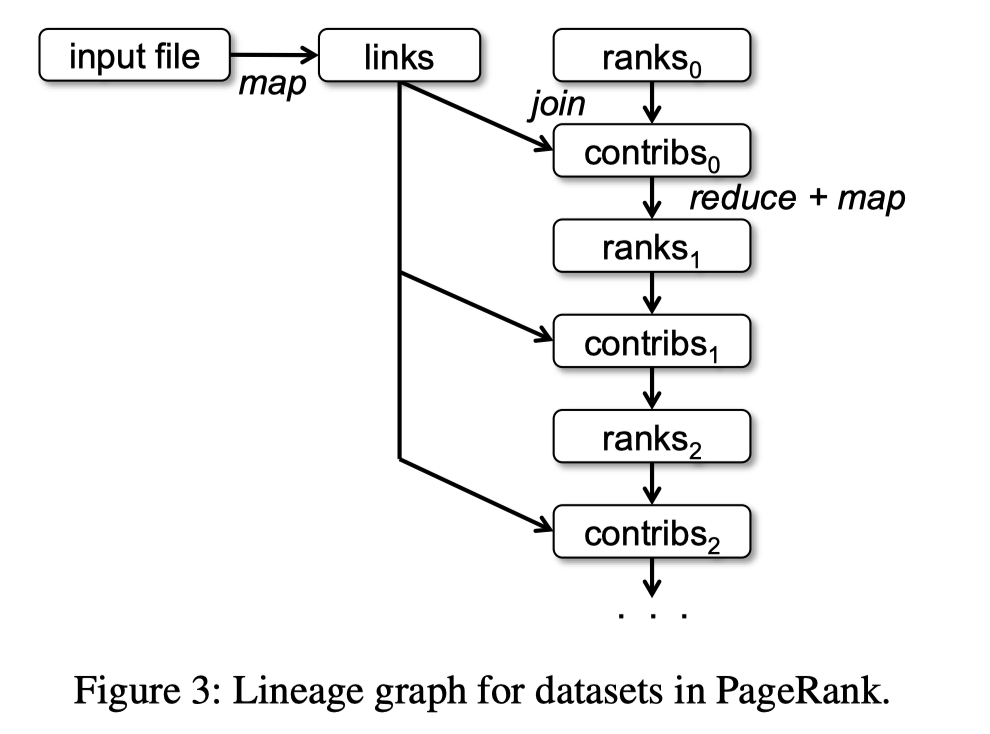
需要注意的是,作者认为这里 links 很大,所以没有去 broadcast 它,这里也提到,如果负载比较明确,可以去 partition 一把:
1 | links = spark.textFile(...).map(...).partitionBy(myPartFunc).persist() |
对的,其实 Spark RDD 还带了一组比较物理性质的操作:

Spark 的操作可以指定 numPartition 和对应的 partitioner, 甚至去 repartition,不过这里需要注意 partition 本身不生成 RDD ( repartition 肯定会)。它有:
- List Partition
- Hash Partition
- Range Partition
上面几种,具体还是看业务了。cache / presist 本身是个 lazy 的操作,会在执行的时候才处理,Cache / Persist 的对象是 RDD 的结果
RDD 的组成
作者在这里认为,RDD 包含:
- Partitions
- Dependencies (对应的数据源)
- Compute Function
- Metadata About Schema
我个人觉得其实有点像数据库的 Physical Plan 一类的东西(或许 Spark SQL 的论文会告诉我有什么区别)。
关于 RDD,几个要关注的操作是:
- dependency and shuffle
- plan 构建
- cache / persist
我们先讲 dependency & shuffle. 也是 Spark 的核心之一。
Dependency and Shuffle
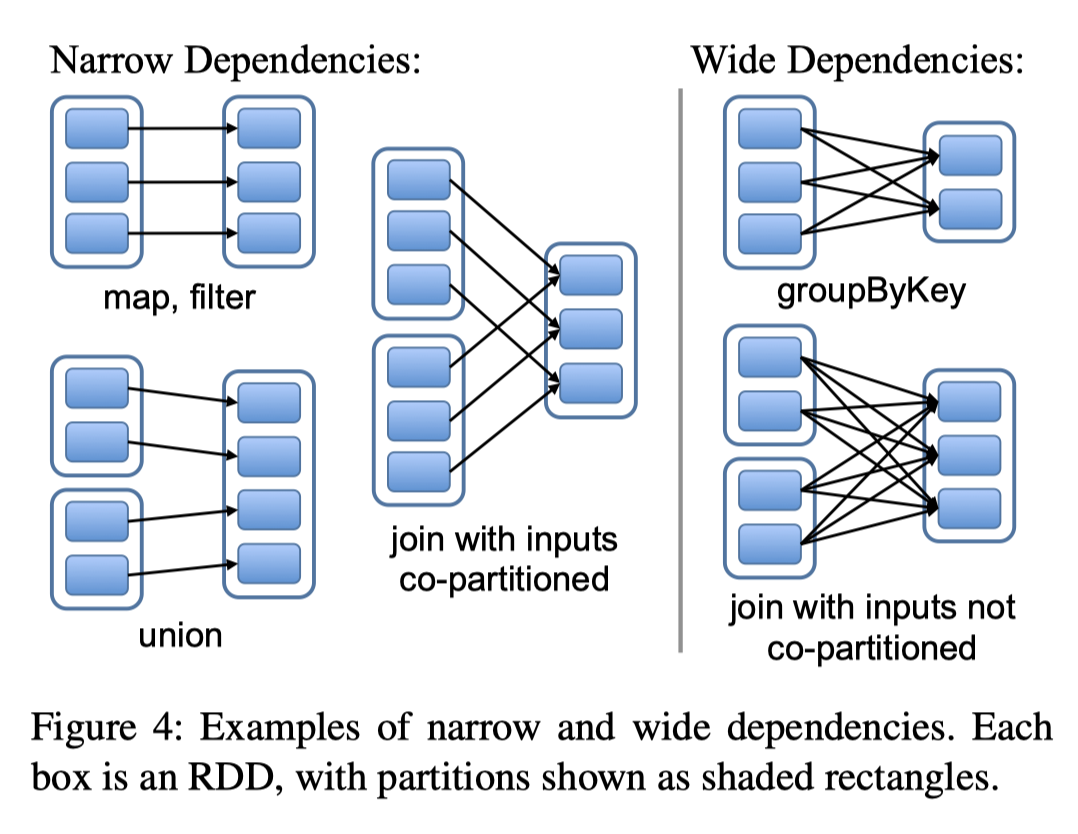
Spark 会根据操作类型来判断是否要 Shuffle,这里的判断方式其实看上面,意外很简单,它把 Spark 区分为 Narrow Dependencies 和 Wide Dependencies:
- Narrow Dependencies: where each partition of the parent RDD is used by at most one partition of the child RDD
- Wide Dependencies: wide dependencies, where multiple child partitions may depend on it.
这里我特地贴原文,因为它含义还是比较清晰的,因为这里一对一 和多对一的单位是 RDD中的 Partition !
- OneToOne、ManyToOne 之类的关系显然肯定是 Narrow Dependencies
- 多对一参照 Partition,co-locate Join 这种可能会是 Narrow Dependencies!
我们下面区分到 Shuffle 的实现,Shuffle 在 MapReduce 中也能见到,它是一个部分整个写过去,另一部分整个读的操作。这个操作还是相当重的,而且可能涉及排序。这里考虑分成 Shuffle Write 和 Shuffle Read 的阶段,写的时候可能走排序或者 Hash + Agg,读的时候可能还需要再走一个类似多路归并的操作。
在 VLDB‘20 上,LinkedIn 的工程师提供了一个 Spark Shuffle 的方案,Spark 3.2 的时候被 Merge 进去了。之后写篇单独文章介绍这个 Shuffle 的流程好了。
Stage
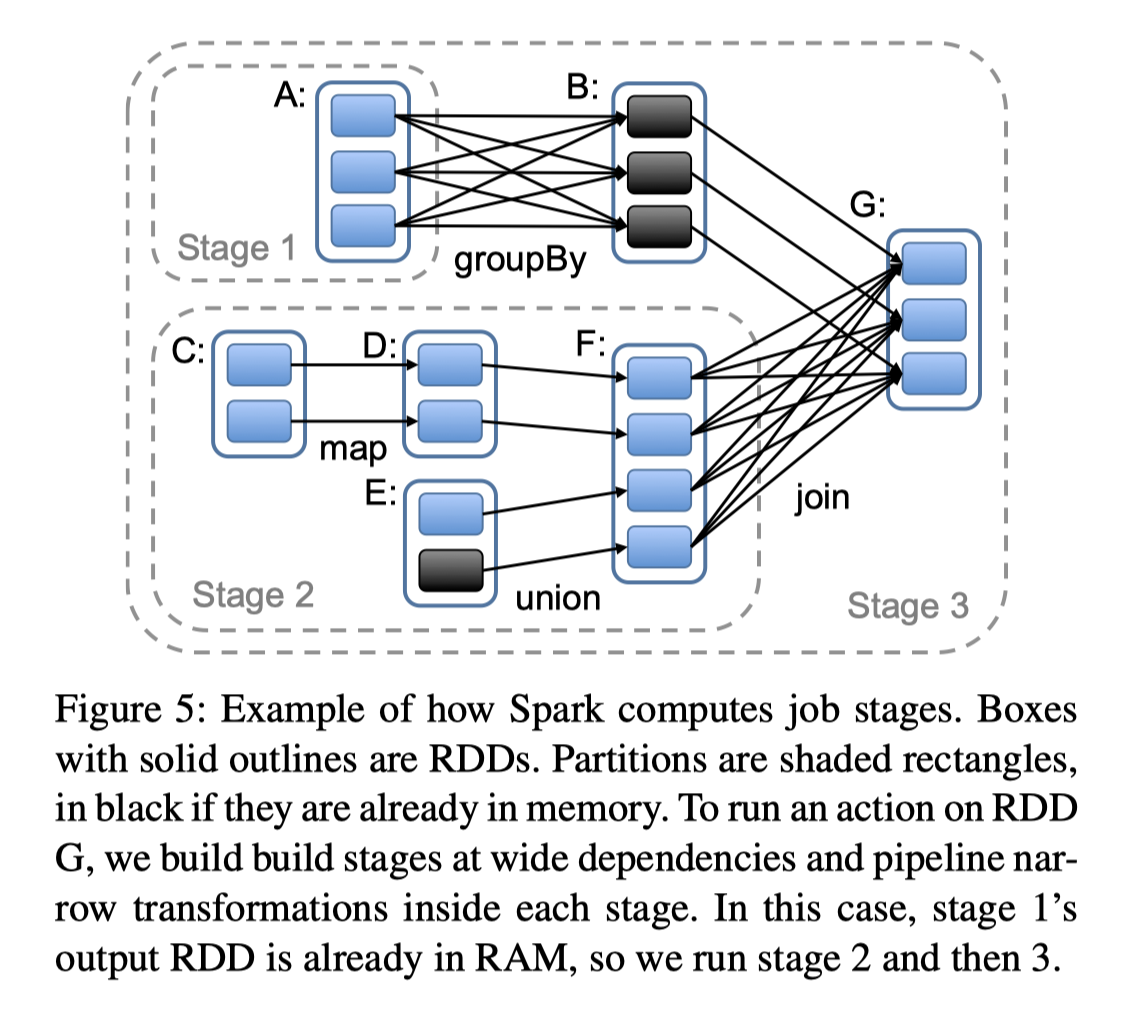
Spark 会按照 Wide Dependencies 拆分成多个 Stage,Stage 内并行执行(有点类似 Push-based Execution Engine?)
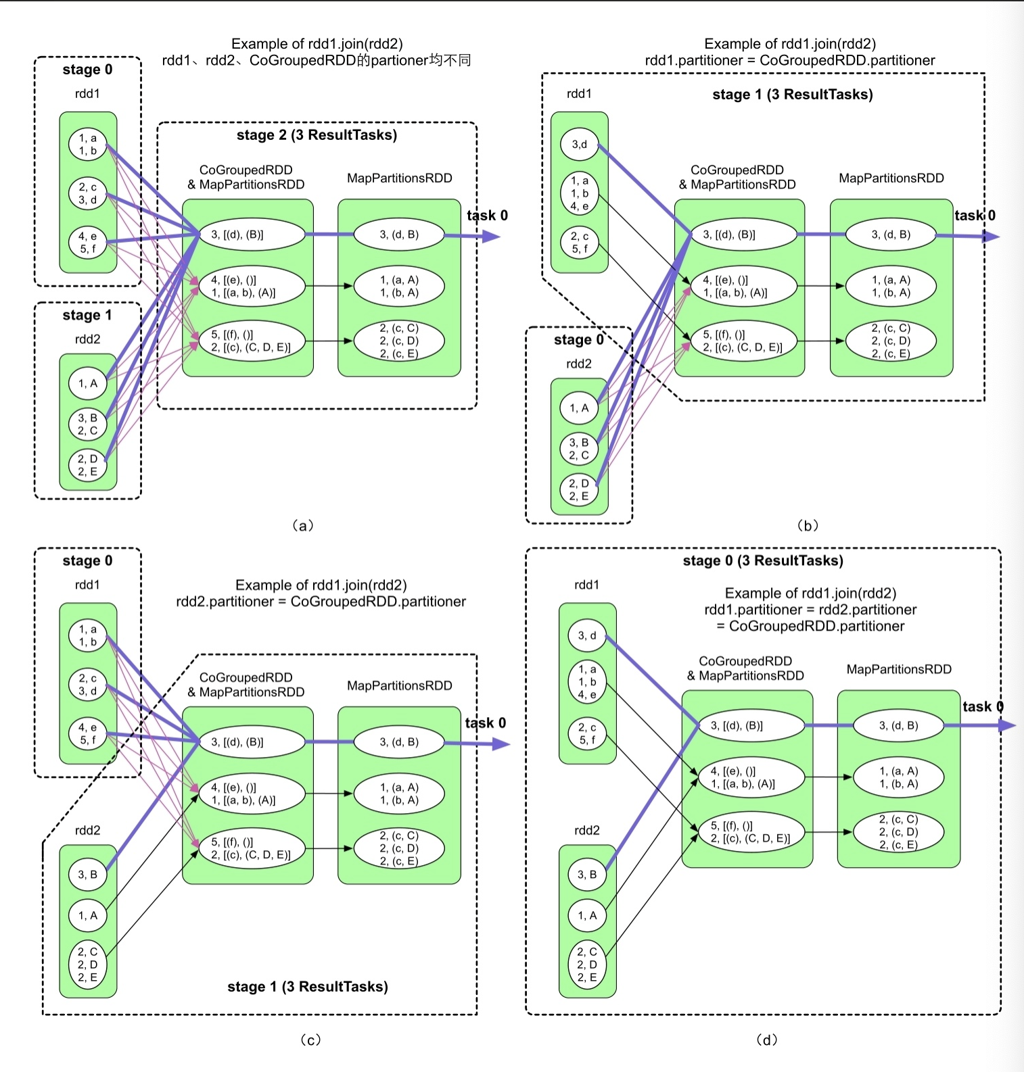
总结
本文关注 Spark 计算和 Shuffle,省略了内存管理、代码生成等部分,因为我感觉这些东西要么我们之前讲过更现代的方案,要么 Photon 自己做了,没必要在意这么老论文是怎么 codegen 、内存管理的。
Spark 感觉论文里也提出了力大砖飞的方式。此外,对于 Shuffle 等地方的优化,本文也只是提到,没有深入(入门阶段先 move-fast 先扫一遍,之后懂得多了再补回来吧)。关于各个 transform,其实本来应该大有可以讲的地方,不过目前点到为止算了。
Spark 还有一套比较大的杀手锏是 Adaptive Query Execution,它能根据大小来动态调整执行的资源,来处理大数据场景的 skew,这是个比较重要的优化,但本文也略过了,实在深感惭愧。
References
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
VLDB’20 Magnet: 领英Spark Shuffle解决方案 - Sovnlo的文章 - 知乎 https://zhuanlan.zhihu.com/p/397391514
关于Spark 3.2.0 push-based shuffle - 斜杠代码日记的文章 - 知乎 https://zhuanlan.zhihu.com/p/443752106
大数据处理框架Apache Spark设计与实现(https://book.douban.com/subject/35140409/) 许利杰、方亚芬 / 电子工业出版社