Parallel Data Processing with MapReduce: A Survey
上次写 MapReduce 的文章还是在很久之前,记得大四下学期毕业写 6.824 的时候写的:https://blog.mwish.me/2020/01/28/MapReduce-%E7%AE%80%E8%AF%BB/ 。谁知道这门课都改名叫 6.8540 了。
Parallel Data Processing with MapReduce: A Survey 这篇 SIGMOD‘11 的论文在 MapReduce 发表几年后总结了一下 MapReduce 的优劣。我们会带着这篇论文的 Point 去看看一些后续的分布式计算。
MR 在 04 年推出的时候算是组了一堆垃圾机器,然后拼凑的一个满足 Google 搜索等计算需求的系统,Scalable 上其实问题没那么大(不讨论具体算子的话),但是 performance 和 efficiency 上可能没那么尽人意,毕竟三副本写、落盘等方式在 2023 年好时代的软件工程师看来其实是优点让人困惑的。不过事实证明,这套东西受到了很多人的欢迎。虽然大部分人觉得这套东西其实是一个历史的退步,MapReduce -> Hadoop 这套东西也慢慢被后来的东西取代了,但是这中间出现的很多名词和概念还是有延续性的,毕竟如果讨论到分布式计算的各种算子, Shuffle / Sort 这些东西的优化其实也可能是根据这些最早的概念一步步来的。包括一些 Push/Pull 之类的讨论,和论文提出的一些远见,感觉概念还是有延续性的。在看 Spark RDD 之前我们还是先来回顾一下古老的 MapReduce 吧。
Architecture
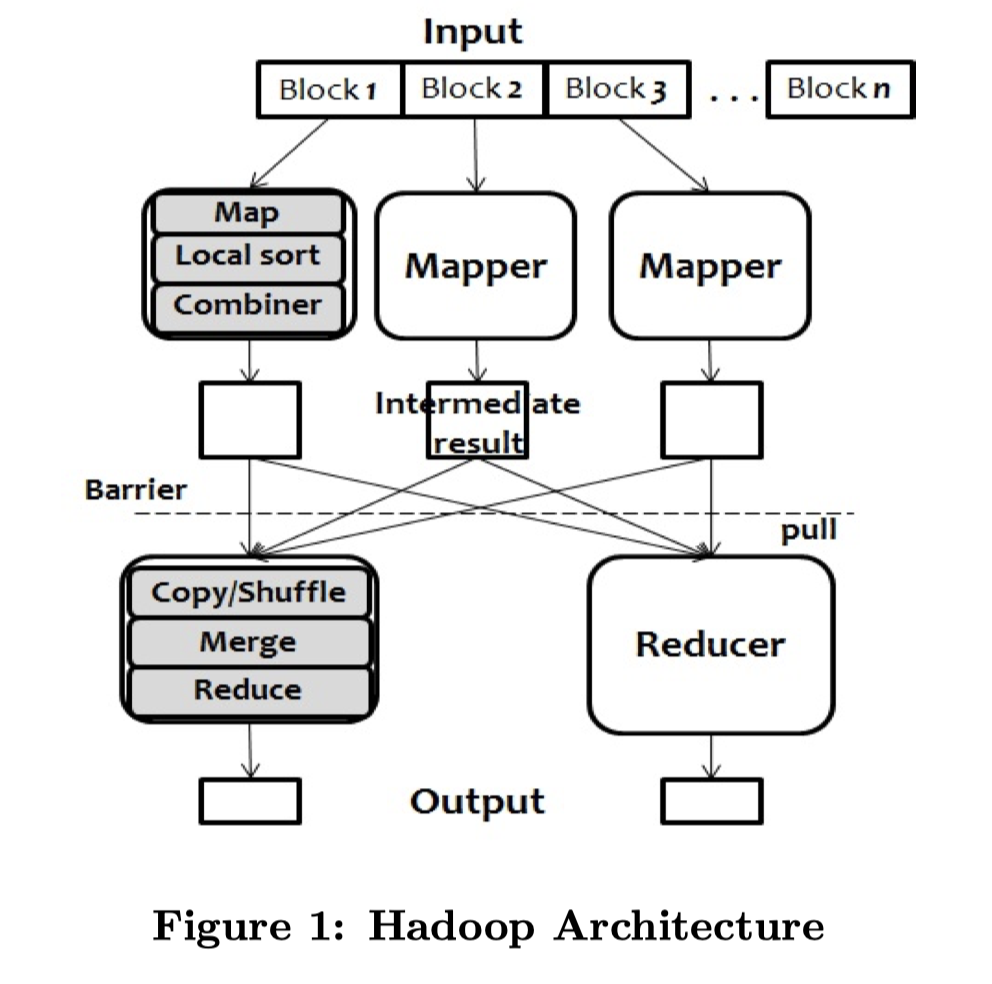
MapReduce 的架构很简单:
- 把程序(可能以 Binary 等方式)分布到 Mapper / Reducer 上,编写 Map 和 Reduce 函数
- 程序分为 Map 和 Reduce 两个 Stage,数据 Stage 都读取并落到 GFS 上,为了容错写三副本,读也走 GFS (HDFS) 来读取
- Map Stage 的分布和 Input Block 还有 Map 的机器有关。Block 被分配给 Mapper,执行尽量无状态的 Map 函数,然后可能会走一个本地排序来做一下 Map-Key 的 Group By。最后走一个 optional 的
Combiner(类似 Map 端预 Reduce 或者别的逻辑)来提前减少数据量 I/O 带宽- Map Stage 的结果存放在 本地或者多副本的存储上,然后按照 Reduce Task 的数量做一个 Partition,这里 Partition 成 R 份,通常是
hash(key) mod R的形式。这里可能会有一个 Buffer 和 Spill-size,处理的时候内存装不下可以 Spill 文件或者合并 - 可能会有一个 shuffle 的流程,在 Map 写下去之前,会走 Hash Shuffle 或者 Sort Shuffle,把数据排序一遍写入,避免 Reduce 阶段打开过多的 Reader,和加速下游 Reducer 读取数据。
- Map Stage 的结果存放在 本地或者多副本的存储上,然后按照 Reduce Task 的数量做一个 Partition,这里 Partition 成 R 份,通常是
- 在Map Stage 任务执行完之前,Reduce Stage 不能工作. 这里其实可以有一些更 flexible 的模型,比如 Mapper 直接把数据 push 到 Reducer,但是这样 Reducer 挂了事情可能就会变麻烦了,所以可以落一次盘
- 在 Reduce 阶段,一般一条 Record 只会发给一个 Reducer (Recall: JOIN). Reducer 以 Pull 模式去走 IPC 拉数据。这里有个类似 External Merge Sort 的方式来读取 — Merge 数据,因为需要读取多份奇怪的数据。最后把 Reduce 结果输出到 HDFS。在原论文中,Reducer 拉到数据需要排序一遍。
- Stage 内 Task 和机器数量可以不相等,MapReduce 框架会监控看你执行的快不快。执行快的节点可以多执行几个任务,执行慢的可以设置超时然后换人跑。这也实现了对应的 Fault Tolerant 和自动的 load balance。
- Hadoop 系可能有 Yarn 之类的框架,来给定对应内存的申请,然后把任务、调度和对应的任务绑定。
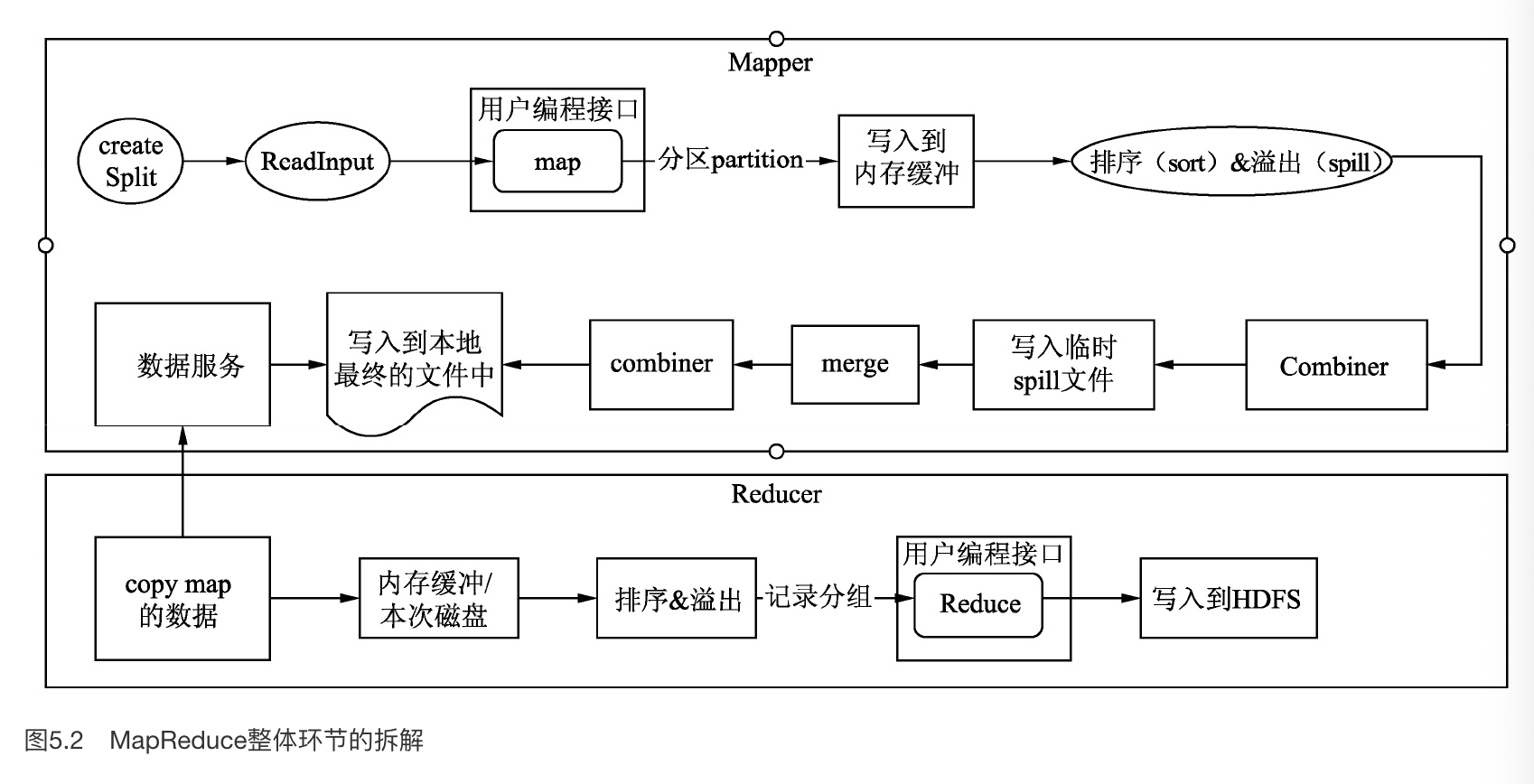
MapReduce 可不可以只有一个阶段呢?比如 Filter 或者 Project 可能会只有 Map 阶段,
Pros and cons
首先 Stonebraker 这些做数据库的人觉得贼几把不爽,自己优化的好好的突然来一波人写了个很挫的架构然后还很受欢迎。接下来又一些博客的对线。历史其实是很清晰的,想必在座的各位都知道这二十年都经历了什么破事。
Anderson et al also criticize that the current Hadoop system is scalable, but achieves very low efficiency per node, less than 5MB/s processing rates, repeating a mistake that previous studies on high-performance systems often made by “focusing on scalability but missing efficiency” [32]. This poor efficiency involves many issues such as performance, total cost of ownership(TCO) and energy. Although Hadoop won the 1st position in GraySort benchmark test for 100 TB sorting(1 trillion 100-byte records) in 2009, its winning was achieved with over 3,800 nodes [76]. MapReduce or Hadoop would not be a cheap solution if the cost for constructing and maintaining a cluster of that size was considered.
(题外话,随着硬件发展 MotherDuck 甚至在网上发博客说大数据不存在了,意思是除了大公司的数据其他小公司的跑个单机嵌入式差不多得了。我不置可否不过也很好奇他们准备怎么赚钱)
比较有意思的是,这里抽象出了一个模型,模型有下面几点:
- Efficiency
- Fault Tolerant
这里的观点是,MR 有着很强的 Fault Tolerant,取而代之的是碎成渣的 Efficiency,因为它要很频繁的去做 Local File IO (不考虑输入端和输出端)或者作为 checkpoint。作为对比,Efficient 的代表是但是的数据库,取而代之的可能是对 Batch Job,对重任务的重试不友好。随后,作者报菜名的介绍了一下 MapReduce 的优点和缺点:
优点
(这一段我看的比较困惑,可能没做过计算是这样的)
- Flexible: ??? 至少你可以无视数据格式造大便
- Independent of storage: 呃呃呃….这个可能是跟绑定存储的 MPP 比较的吧
- Fault tolerance: 这个我还是认可的
- High Scalabity: 其实我不是很懂 scalable,感觉 DOP 无脑往大切也不太好吧,但至少对一些需要并发的 Batch Job 可能确实是优势?(2023 年的机器和 2004 年已经不一样了。。。)
缺点
- No high-level language
- No schema and no index
- A single fixed dataflow
- Low efficiency
- External Sort-Merge
- Materialization of intermediate results
- write to distributed file system (?)
- block-level restrarts
- one-to-one shuffle strategy (?)
- simple runtime scheduling
对 MapReduce 的改进
这节主要介绍了(作者认为的)MapReduce 的问题,我本来蛮期待这节的,但是读着读着发现写的还是太早了,很多改进的系统都已经死了。读这节的时候,主要还是关注,在 2023 年这个节点,大数据系统是怎么克服这些问题的。
High-Level Languages
微软的 SCOPE, Apache Pig, Apache Hive 都包含上层语言相关的改进,包括 Spark 的模型也支持 DataFrame 和 SQL 两种形式。这里比较著名的是微软的 SCOPE 上的 DryadLinq 和 Spark SQL。都能够把 SQL 转成自己的执行流。
我们之前介绍过 Hive,Hive 支持 Hive QL,支持 adhoc query。Hive 如果后台是 MR,它收到 SQL 会编译产生一组 Stage,然后 Stage 代表对应的 MR Job。
Schema Support
Schema 有好几层含义,这里主要指的是 MapReduce 论文中本身处理的是纯文本或者二进制,所以过于 flexible 的问题,实际上这里的解决方式有上层提供 Schema 和提供一定的格式。实际上很多格式本身就是「大数据 / Hadoop 系」搞出来的,比如 Avro、Parquet、ORC 这几个格式都多少是从「大数据社区」孵化出来的。
关于这个,感觉 Schema Support 本身也是讨论烂了的内容了。
Flexible Data Flow
Flexible Data Flow 主要在于 Map / Reduce 模型本身的优化和改进,比如一些算法本身要维护一些处理数据的状态。
一些改进,比如 Map-Reduce 要读多个输入的时候(比如 Join),可能会有一个 Map-Reduce-Merge 的模型.
不过,现在的版本宠儿是 Spark / Dryad 这样的类似 DAG 的流。通过 点(计算)和边(TCP / 内存 / 落文件这样的通信)来构成对应的计算。这些东西一起受到 Runtime 的调度。
Blocking Operations
MapReduce 的计算流类似 BSP 模型,不执行完上一部就不能执行下一步,这样也不是很好处理增量的请求和 Online Processing( Google 当时用 MapReduce 跑批,然后走 Percolator 的小 TP 请求来插入新的数据),也不支持 Streaming 这样的东西,这里也有一些对应的更新的模型。我个人感觉这里模型本质上还是说,MR 这类东西只适合跑批,需要在同样的模型上支持一些轻量的操作。
我个人感觉 Lakehouse / Delta-Lake 这种(包括 Paimon 这种 Flink Table Format):
- 一个通用的 Table Format,有比较适合插入的结构
- 一个强劲的 meta
I/O Optimization
Parquet / ORC 这种结构在 I/O 等 Optimize 上效果显著。
Scheduling(TBD)
调度有问题主要是 MR 论文的调度太 sb 了,这里提到了估计估算等,我感觉这里主要关注 Yarn 的调度等。这个之后专门写一篇博客吧。
- 对任务本身的起止重试等进行估计
- 还有一个问题是,如果 MR 的集群是共享的,那么多租户这一个层次的调度。
- 如果有相似的计算,避免重复计算(共享请求)
Joins
Map Reduce 本身只支持一个 input,所以 Join 是一个在上面需要绕弯弯解决的问题。这里有几种对应的方案:
- Map-side Join: 实现方式类似 RDBMS 的 SMJ, 根据 key 来做 partition,然后被 Join 到一起。另一种是对应的 broadcast Join. Map-side join 一定程度上能减小对应的网络和传输开销。broadcast join 也可以在 Map 阶段搞定
- Reduce-side Join: 最通用的 Join. Map 来做对应的标记,然后来做 key-equality join.
- Map-Reduce-Merge: 在 Reduce 后加一个 Merge 阶段,类似 Filtering-Join-Agg 的模式
我们以 Hive 为例子,Hive 会有:
- 发生在 Shuffle / Reduce 阶段的
- Map: 读取 A, B 的数据,然后根据 Join 条件发往 Reduce(可能走 Shuffle),检测 Key 相同的,做 Join
- 发生在 Map 阶段的:Map 侧完成操作
- 有一个 Stage 读取小表,然后存 HashTable 到文件系统。然后任务中 Map 阶段读它,做 Join
- 可以做 Bucket Map Join, Table 1 和 Table 2 的 bucket 成倍数关系可以快速 Bucket 裁剪
- 可能需要处理 Skew Data,特殊分配一个作业处理 Skew 的数据
References
- Hive 性能调优实战 林志煌 煮
- Parallel Data Processing with MapReduce: A Survey