InnoDB Data Locking: Part 1
每一个需要实现锁的人,都需要考虑 Data Locking,在 Btree 上如何进行数据的锁定,特别是 InnoDB / PostgreSQL。这篇文章简单介绍一下 InnoDB 是怎么锁定数据的。本身这篇文章参考的是 InnoDB 官方博客中,Kuba Łopuszański 写的几部分 InnoDB Data Locking 的文章,再加上 阿里巴巴数据库月报一些相关的详细一些的介绍。
Locking 一直是数据库里面非常难的内容,在 InnoDB 里面,难点也在于很多地方:
- 不同层次的(database, table, row)的锁定
- 不同的隔离级别
- 读/写等不同的锁的权限
- 事务冲突
- 需要的时候,维护 consistent read view
- 锁的超时 / 饿死(priority) / 排队
- 死锁处理
- 识别冲突
- 挑选 victim
- 高效,不影响全局
- 识别不同模式的,甚至是锁升级引起的冲突
本身,事务这个抽象暗示着 DB 对外层提供的是一种 total-ordering 的语义。但是为了性能,db 会做到行或者一些级别的锁定,来允许并发存在。同时,为了给性能或者使用开一些口子,DB 甚至(也不能说甚至)允许很多低级别的 Isolation Level。其实单纯从取 snapshot 或者一些小地方来看,性能甚至不一定更好(比如 RC 可能每次读要拿一个 read-view,虽然也有一些性能优化),但是降低了总体冲突的概率。
这里的问题是怎么(高效的)提供锁定和识别冲突并 abort。
表和数据锁定
InnoDB 的数据锁定是 MySQL 面试一大坑,比如经典的 GAP_LOCK 和 next-key locking,比较乐子的是,其实数据库业务部门比大部分如今的 DB R&D 更懂这块的内容,因为他们在生产中会实际和这些东西打交道。
比较常见的内容是表锁和数据锁。表锁是一个 MySQL 级别的概念,但是它可以被转化为 InnoDB 的数据锁然后飘在 InnoDB 上。举博客中的例子:
数据锁定的 sample:
1 | > SELECT |
上面是很明显的数据锁定,我们还可以看到表锁:
1 | con2> SELECT LOCK_TYPE,LOCK_STATUS,OWNER_THREAD_ID |
这里可以看到,performance_schema.metadata_locks 有 SHARED_READ_ONLY 锁的表,这里锁有下面的几种形式:https://dev.mysql.com/doc/refman/5.7/en/performance-schema-metadata-locks-table.html
- The lock type from the metadata lock subsystem. The value is one of
INTENTION_EXCLUSIVE,SHARED,SHARED_HIGH_PRIO,SHARED_READ,SHARED_WRITE,SHARED_UPGRADABLE,SHARED_NO_WRITE,SHARED_NO_READ_WRITE, orEXCLUSIVE.
这里想必在 MDL 阶段也会上 X 锁。
表锁在 InnoDB 中,可能会以意向锁的形式存在(IX IS),其实反过来说,InnoDB 的意向锁也只会在上面表锁的情况下开。我们继续举官方博客中的例子:
1 | mysql> SET autocommit = 0; |
这里观察到了 metadata_lock 的锁和 data_locks 的映射关系。
回忆一下在数据库中 Intention Lock 都是为了满足不同层次的锁定。可以想象,写事务会拿到 IX 锁,然后写;读事务会拿到 IS 锁,然后读。这个时候如果有全局的表锁,会走 InnoDB Lock 的流程,等待拿到锁然后进行操作。(不知道有没有什么特定的优化,应该有吧)
1 | mysql> BEGIN; |
关于锁定,这里希望下表没有超过你的常识(误):

(AUTO_INC 也是一种表锁,两个 AUTO_INC 之间的访问是互斥的)
Record Lock & Gap
这个部分应该是非常恶心的一部分了,因为 InnoDB 切的非常细,直接导致这块细节处理非常恶心而且 bug-prune。
官方博客举了个非常好的例子,再次允许我原封不动的贴上来:
1 | mysql> SELECT * FROM t; |
GAP_LOCK,据伟大的 Graefe Goetz 所说,是一种把 Predicate Lock 转化为记录锁的好方案,InnoDB 的锁有如下类型:
- S,REC_NOT_GAP → shared access to the record itself
- X,REC_NOT_GAP → exclusive access to the record itself
- S,GAP → right to prevent anyone from inserting anything into the gap before the row
- X,GAP → same as above. Yes, “S” and “X” are short for “shared” and “exclusive”, but given that the semantic of this access right is to “prevent insert from happening” several threads can all agree to prevent the same thing without any conflict, thus currently InnoDB treats S,GAP and X,GAP (or *,GAP locks, for short) the same way: as conflicting just with *,INSERT_INTENTION
- S → is like a combination of S,REC_NOT_GAP and S,GAP at the same time. So it is a shared access right to the row, and prevents insert before it.
- X → is like a combination of X,REC_NOT_GAP and X,GAP at the same time. So it is an exclusive access right to the row, and prevents insert before it.
- X,GAP,INSERT_INTENTION → right to insert a new row into the gap before this row. Despite “X” in its name it is actually compatible with others threads trying to insert at the same time.
- X,INSERT_INTENTION → conceptually same as above, but only happens for the “supremum pseudo-record” which is imaginary record “larger than any other record on the page” so that the gap “before” “it” is actually “gap after the last record”.
INSERT_INTENTION 是个很坑爹的东西,我们先理解 GAP:
- 锁的类型是个 flag,S 和 REC_NOT_GAP 直接按位
|就行 - InnoDB 的锁和叶子结构是(半)绑定的,之后我们看 Lock 分裂/继承的时候也会看到。在 InnoDB 的 Page 上,会有 Infimum record(下确界)/ supremum record(上确界)
- GAP 锁定的是记录之前的 GAP
- InnoDB 的实现中,资源只有一个点(物理的 record),但是有不同种类的权限,
GAP,REC_NOT_GAP, 和都有
这里的互斥关系如下图:

INTENTION_LOCK 是一个很恶心的事情,考虑一个事实,在 InnoDB 申请锁可能会在 Page 相关的结构上做一些标记,然后物理上插入这行记录。在插入的时候,实际上的流程如下:
- Latching the page
- 找到数据对应的位置(innodb page 对应的稀疏链表)
- 检查锁(但不上锁):then latching the Lock System queue for the point to the right of insertion point and checking if there is any *,GAP, S or X lock.
- 如果没有冲突的锁,直接插入这条记录,然后不上锁。依靠记录的 txn 标记来识别
- 有冲突的锁,就发起一条
INSERT_INTENTION提交到锁队列中
- 如果是有锁的情况(包括自己的锁)这里会需要做一些锁继承相关的操作。具体的继承细节在后面讲,这里简单说就是比如原先是自己的 S 锁,然后插入之后,区间从一个 gap 被拆成新的一条记录 + 一个新的 gap。这个地方要注意锁保留权限
举官方博客的例子:
1 | mysql> BEGIN; |
- SELECT 的时候,全部带上 S 锁. 这个地方注意 supremum 的锁。这里也申请了一个 IS 的表锁
- DELETE 的时候,生成一条 X 的删除锁
- INSERT 的时候,没有生成锁,因为没有冲突
Lock Compression
performance_schema.data_locks 并不是一张具体的表,而是从 <space id, page no, heap no> 恢复出来的。锁只是一个内存结构。
InnoDB 在内存中会有一个压缩位图,Hedengcheng Slide 有一张很好的图:
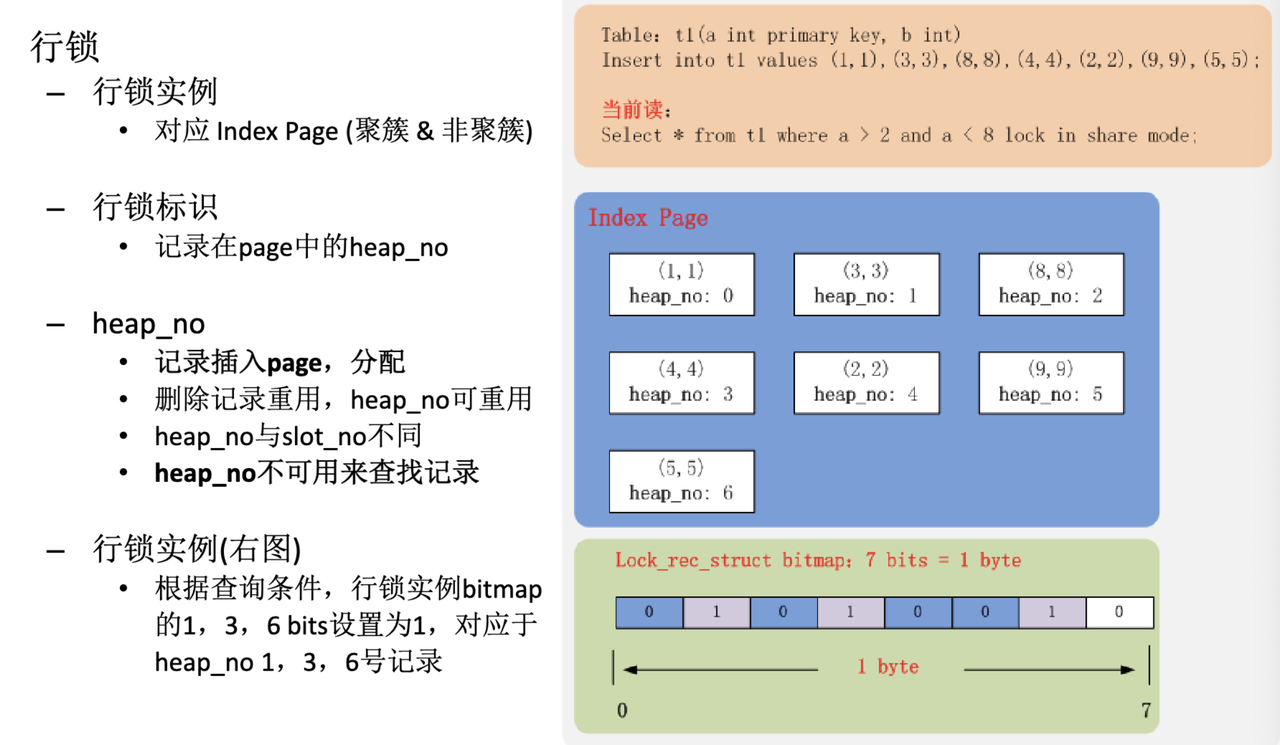
这里我们注意到几个事实:
- 依赖
heap_no来维护 bitmap 的大小和对应的顺序 - 可能第一次上锁的时候会申请一个比较大的 bitmap,后面上锁开开销就会减小。
Implicit Lock
这坨东西和 implicit lock 有什么关系呢?有,implicit lock 就是在这种王八蛋时间突然冒出来的。还记得我们的插入的时候,其实一开始没有 INSERT_INTENTION 锁吗,我举个让这个锁飘出来的例子:
1 | (client1) mysql> INSERT INTO t VALUES (4); |
这个地方可能本来的优化中, client1 插入后是没有一把锁,在 Delete 之后锁就出现了. 这种因为优化导致暂时不出现,但是你发现问题的时候要查它找冲突的锁叫做 implicit lock。后面在 Secondary Index 一节,会有比较多内容介绍这个。
Lock Spliting
在申请锁的时候,我们常见的有锁的升级(Upgrade),同时,在 InnoDB 的结构下,也会有从 A 类型的锁切到 B 类型锁的 Pattern。
考虑到几种 Pattern:
- 读锁升级到写锁
- 从 S|REC_NOT_GAP 升级到 S
对于 (2) InnoDB 在申请资源的时候,会按照集合做减法,尝试只 acquire S - S|REC_NOT_GAP = S|GAP 的锁
Btree 分裂和锁继承
这部分知识在这篇文章中很详细:http://mysql.taobao.org/monthly/2016/06/01/
为什么合并不需要呢?答案是 next-key locking 是真的会找到下一个 key, 但是这个 Page 内部也需要表示 「Page 内最大已经被锁定」。
这里在 Page 分裂的时候,也要处理对应的 GAP 和 Locking。
Secondary Index & Implicit Lock
Secondary Index 和 Lock 结合起来…非常复杂。首先要知道:
- Secondary Index Page 上也是有锁定的
- MVCC 中,Secondary Index 会保有最新的数据,这里可能会影响 ICP
这里官方博客举了个非常好的例子:
1 | CREATE TABLE point2D( |
然后查询:
1 | con1> BEGIN; |
这个锁 非常符合预期。回滚这个事务,删除 x :
1 | con1> COMMIT; |
这个地方表面上也符合预期,但是回顾一下,对应的 x/y 呢?
1 | con2> BEGIN; |
这里 con2 就 hang 住了,再去 con1:
1 | con1> SELECT ENGINE_TRANSACTION_ID trx_id,INDEX_NAME,LOCK_TYPE,LOCK_DATA,LOCK_MODE,LOCK_STATUS |
多出来了 implicit lock,邪恶吧!这里逻辑流程如下:
- InnoDB 删除会推高 Page 的最大 trx id
- Secondary Index 查找的时候有一个 read_view,发现 Page 上修改的 trx 大(
page_get_max_trx_id(page)),就要走逻辑去查这个 trx 是不是还持有锁:row_vers_impl_x_locked - 查看是否冲突,上 implicit lock
这段逻辑是很清晰的,现在让我们调个个,看看如果 先读 Secondary Index,再删:
1 | con2> BEGIN; |
con1 hang 死了,这个时候 con2 查锁:
1 | > SELECT ENGINE_TRANSACTION_ID trx_id,INDEX_NAME,LOCK_TYPE,LOCK_DATA,LOCK_MODE,LOCK_STATUS |
这个地方,我们之前 Delete x 没有在 y 加锁,怎么会是呢?答案是这里会尝试在 y 上加锁,没有的话就 implicit lock 那种模式了 ( lock_sec_rec_modify_check_and_lock )
关于 MVCC, read_view 和锁
实际上,之前演示的部分都上锁了。read_view 读取其实看隔离级别不一定会一直持有锁。
比如 InnoDB 的 semi-consistent read ( http://mysql.taobao.org/monthly/2018/11/04/ ) 。会尝试第一次不上锁,直接读 Undo Chain。
插入和已经存在的记录
如果发现已经存在的记录:
通常INSERT操作是不加锁的,但如果在插入或更新记录时,检查到 duplicate key(或者有一个被标记删除的duplicate key),对于普通的INSERT/UPDATE,会加LOCK_S锁,而对于类似REPLACE INTO或者INSERT … ON DUPLICATE这样的SQL加的是X锁。而针对不同的索引类型也有所不同:
- 对于聚集索引(参阅函数
row_ins_duplicate_error_in_clust),隔离级别小于等于RC时,加的是LOCK_REC_NOT_GAP类似的S或者X记录锁。否则加LOCK_ORDINARY类型的记录锁(NEXT-KEY LOCK);- 对于二级唯一索引,若检查到重复键,当前版本总是加 LOCK_ORDINARY 类型的记录锁(函数
row_ins_scan_sec_index_for_duplicate)。实际上按照RC的设计理念,不应该加GAP锁(bug#68021),官方也事实上尝试修复过一次,即对于RC隔离级别加上LOCK_REC_NOT_GAP,但却引入了另外一个问题,导致二级索引的唯一约束失效(bug#73170),感兴趣的可以参阅我写的这篇博客,由于这个严重bug,官方很快又把这个fix给revert掉了。
摘自:http://mysql.taobao.org/monthly/2016/01/01/ . 你或许会发现,这里上的是数据锁,而不是意向锁。这里原因代码说的比较清晰。
1 | lock_type = ((trx->isolation_level <= TRX_ISO_READ_COMMITTED) || |
感觉和谓词锁有关,属于读写联合机制。
Not in this article
下篇文章这里需要介绍 InnoDB 的 8.0.18 新的死锁检测算法、调度,还有 8.0.21 的并发队列和锁拆分.
References
- https://dev.mysql.com/doc/refman/8.0/en/internal-locking.html
- https://dev.mysql.com/blog-archive/innodb-data-locking-part-2-locks/ 这一系列的文章
- InnoDB 事务锁源码分析 - 宋昭的文章 - 知乎 https://zhuanlan.zhihu.com/p/412358771
- MySQL 引擎特性-死锁检测 http://mysql.taobao.org/monthly/2021/05/02/
- MySQL · 引擎特性 · InnoDB 事务锁系统简介 http://mysql.taobao.org/monthly/2016/01/01/