SIGMOD'22: SingleStore
SingleStore 的前身是差不多和 Snowflake 同一时间开始做的 MemSQL,最早他们是做一个快速的内存数据库,但是事实证明,做这套的 VoltDB 呀什么的都混得不太好(SAP Hana 商业做的好,混得还行,其它貌似都没怎么卷出来?)。然后他们还做专有部署/Shared-nothing,没有和 snowflake 一样选择做 Cloud(shared-nothing 和 cloud 不一定有冲突,不过懂我意思就行)。这两个合起来,得了,商业上就没那么成功呗。不过事情没做成,技能是不会丢的,一群人积累的经验也不容易丢,何况线下部署呀 debug 呀什么的其实挺考验能力的。
SingleStore 自称卖的是 HTAP,他支持两种模式:Shared Nothing 部署和绑定 BLOB Storage(类似 S3) 部署。尽管 AWS EBS 提供了比较可靠的块存储服务,但是感觉是因为成本和性能的原因,也因为它们比较熟悉 Shared-Nothing 这套,(不知道是不是也有在一套代码上做异地的原因),所以没用 EBS。它承诺开 S3 的时候,成本也下来了,插入性能也好了。当然我实际感觉它开启 BLOB STORAGE 作为缓存的时候,插入侧能力没有那么好,P99 理论上应该会很受限于 S3 的性能。不过感觉对于大部分用户来说,插入 P99 是不是只要能发现原因就行,特殊的用户可以靠加钱来解决,让数据尽量做一个全缓存。我们在后面也会分析这一套架构和 CockroachDB / TiDB 之类 TP 架构的区别。
SingleStore 自称对手是「各种 domain-specific」的数据存储,它感觉有点类似国内在聊的「多模」这个词(产品见 Lindorm),它尝试的是 one-fit all。产品认为,多种数据库在实现层面要把一套东西做很多遍(包括 logging / ETL / 各种相似的优化),而用户需求不外乎是那几个:satisfying a breadth of requirements for transactional and analytical workloads。从结论来看,它也有一定对 flexible 的数据结构的支持。不过具体怎么样也得看市场的态度。笔者认为,这些内容有点大公司实现者视角,在大公司里面,多个团队收编为同一套组件能够提供比较好的组织架构优势,然后看各个组件分层,很多数据库可能做不到专有的类型组件那么优秀,但是很多优化也是通用的。但这些东西对用户来说我个人感觉没那么大意义?除了一套系统 ETL 之类的好做很多,好像用户还不是什么方便用什么?难道用户买它在上面写自己的系统吗(囧)。总之 SingleStore Database Engine 的前面可以是它 manage 的 Service,也可以是用户自己搞出来的安装 binary (还记得最早 MemSQL 是线下部署吗)。
上面是对 S2DB 的一个大致的 overview,下面部分会大改过一下论文中 SingleStore 的架构,先提前说一句这文章写的非常细,架构介绍还是很细致的。
大致思路
- Shared-nothing 模式不用提,肯定是 Cloud Blob Storage 相对 EBS 成本低。不过,S3 对外暴露数据不丢是靠谱的,但是不可用只有四个九,这表示需要做很多东西来 work around ( delta-io 似乎会尝试一直提交?)。所以引入了 local-disk。说没用 ebs 是因为 ebs 延迟 + 成本 + 不一定用的上它的复制。所以在这种情况下,SingleStore 自己做了一套复制,然后在单机上处理这些问题。(不管做的好不好,这个理由应该还是说得过去的)
- 节点分为两种:aggregator , leaf. Aggregator 负责查询,Master Aggregator 负责 fail-over 相关的一些信息
- 用 Hash Partition 来分片
- 为了降低延迟,在 local disk 上做事务,然后 async 移动到 BLOB Storage 端。提交是靠多副本来保证正确性的
- BLOB 端包含数据(显而易见)和日志(支持 PITR)
- 可以设置类似 TiFlash 这样的 Learner,用来支持一些 AP 查询
- SingleStore 的本地复制(不包括 Read-Replica)只会维护 HA,不会维护读流量。见 Figure 2,S2DB 认为读流量走主就行,备只为了 HA,因为这部分不能减少负载(感觉相对于 TiDB,大致 idea 没问题,那对于热点请求、慢节点或者热分区呢?)
- SingleStore 实现了异地异步复制,这个也有点类似 Read-Replica,可以被读。这里也允许从异地备份中 failover,但必须要 DBA 来操作
- 在单机上,提供了 Unified table storage. 这里需要支持快速的 Scan,插入和点查。这块理论上可能非 HTAP 会写一堆对应的引擎,SingleStore 这里准备了单一的 table storage 做本地存储支持。它提供的概念类似 LSM-Tree,相对于传统的 LSM-Tree,应该更接近 Mesa 或者 Snowflake 那种概念。这里概念如下:sort keys, secondary keys, shard keys, unique keys 和 row-level locking(相对 Kudu 来说,它这些概念应该做的细和宽泛很多,对外形态有点点类似 SQL Server 的 Columnar 支持?)
- In-memory row store: lockfree skip list, 写写悲观锁、读写不冲突,Row 固定大小绑定 bookeeping 信息,变长字段额外存储
- 有 Partition 级别的 Logging,会有一个进程来 checkpoint
- (看下来感觉是 in-memory tp system,有点类似 Hekaton?哦结合他们之前做 MemSQL 的,感觉一切合理了起来…)
- 列存表被组织为 [表 - segments - data files] 的三级概念,不过感觉 segment 是 frozen 的,元信息存储在一个 RowStore 中,包括这些文件的位置,encoding,Column min-max 等,也有一个 delete bit-vec
- 上面的部分是所有 AP 系统差不太多的,但是这里针对点查更新做了优化:允许 Seek,不需要 decoding 所有的 row (例如利用 LZ4 + RLE,见:https://www.singlestore.com/blog/winter-2022-universal-storage-part-5/ )
- Sort Key 可以手动指定键排序
- 类似 snowflake,这里也会有后台的进程去做 Compaction
- 每个 ColumnStore 中,都有一个行存的表作为前台写,然后有一个 background flusher 靠事务移动到 ColumnStore 中(这块我感觉和 SQL Server 没有什么区别,直接去看那篇好了)。
- In-memory row store: lockfree skip list, 写写悲观锁、读写不冲突,Row 固定大小绑定 bookeeping 信息,变长字段额外存储
- 执行层 co-locate JOIN 请求,分区裁剪,也支持 Codegen
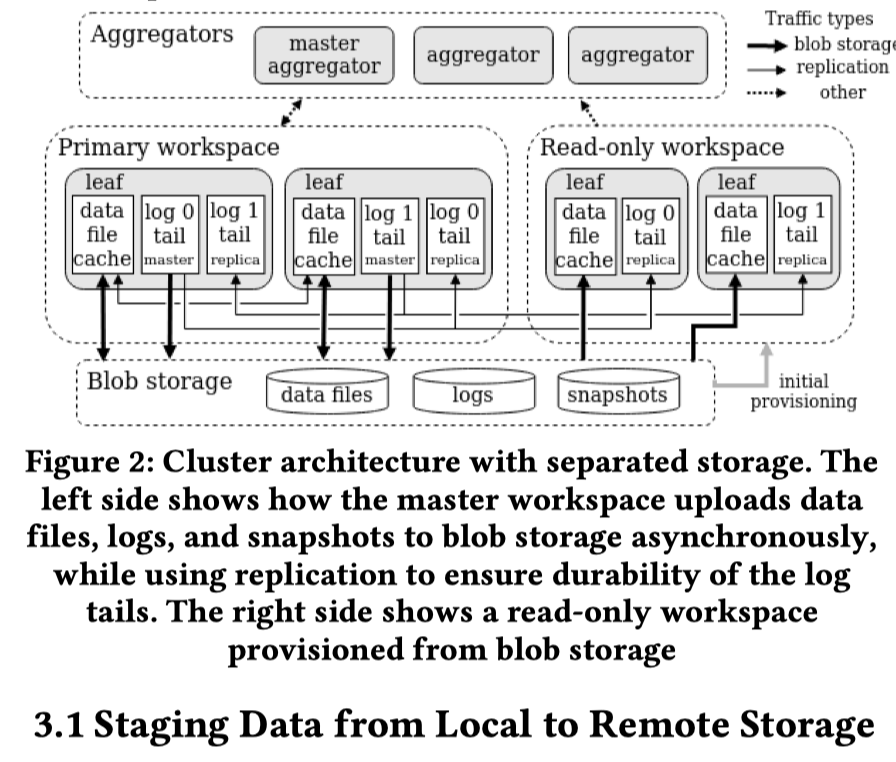
存算分离的架构
S2DB 允许本地多副本写来提交,然后声称这样更可控(确实)。在 Log 系统有下面一段,我复制一下原文,因为不是百分百确定意思:
The in-cluster replication is fast and log pages can be replicated out-of-order and replicated early without waiting for transaction commit. Replicating out-of-order allows small transactions to commit without waiting for big transactions, guaranteeing that commits have low and predictable latency.
我个人猜测,这个应该是有个 mtr 或者操作级别的日志组,然后复制的时候不需要等事务完成,而是等待 Page 或者 Log Buffer 攒满,不知道我理解对不对,感觉很 trivial 嘛…
这里写多份的时候,为了低延迟开了个挂,只要3副本内存写完了就行。这里论文说了还是有一定概率会丢内存数据的。这里它写了个很有意思的原因:
While SingleStore supports synchronously committing to local disk as well, this tradeoff often doesn’t make sense in cloud environments where loss of a host often implies loss of the local storage attached to that host. For this reason, S2DB doesn’t synchronously commit transactions to local disk by default.
考虑到它不挂载 EBS,确实很有意思…
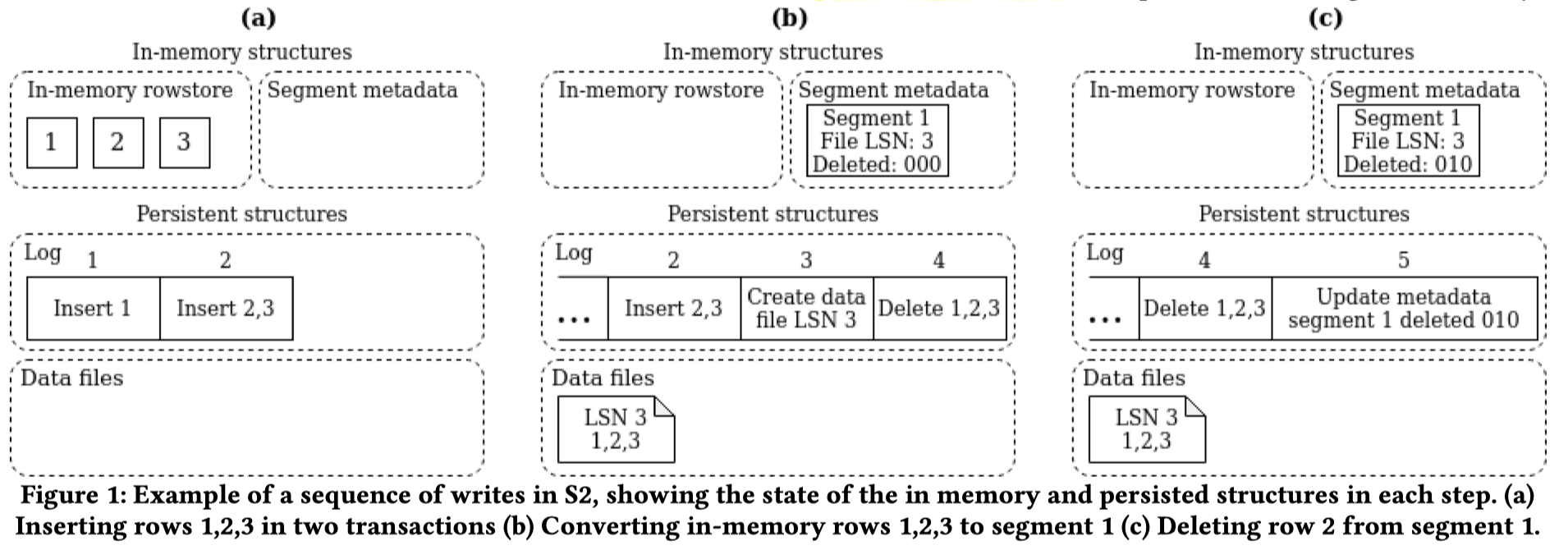
观察上面几张图,这里 (a) -> (b) 是一个 flush,(b) -> (c) 是一个删除,我们稍微详细一点介绍流程:
- Flush: 这里首先有一点 Log is database 的感觉,先创建 Create data file LSN 的标记,然后 name datafile,数据文件也可以从 Log 中恢复
- Column 中的删除:可以注意到,这里删除标记到了 Meta 里面。其实 Doris / StarRocks 的主键模型删除也是标记到 Meta 的 RocksDB 存储中的,Delta-IO 可写 Log 可写额外文件,iceberg spec 得写文件。而在 SingleStore 中,Meta 被存储在 RowStore 中。
上述是一个单机写入的流程,考虑到共享存储层,这里需要再次前进:
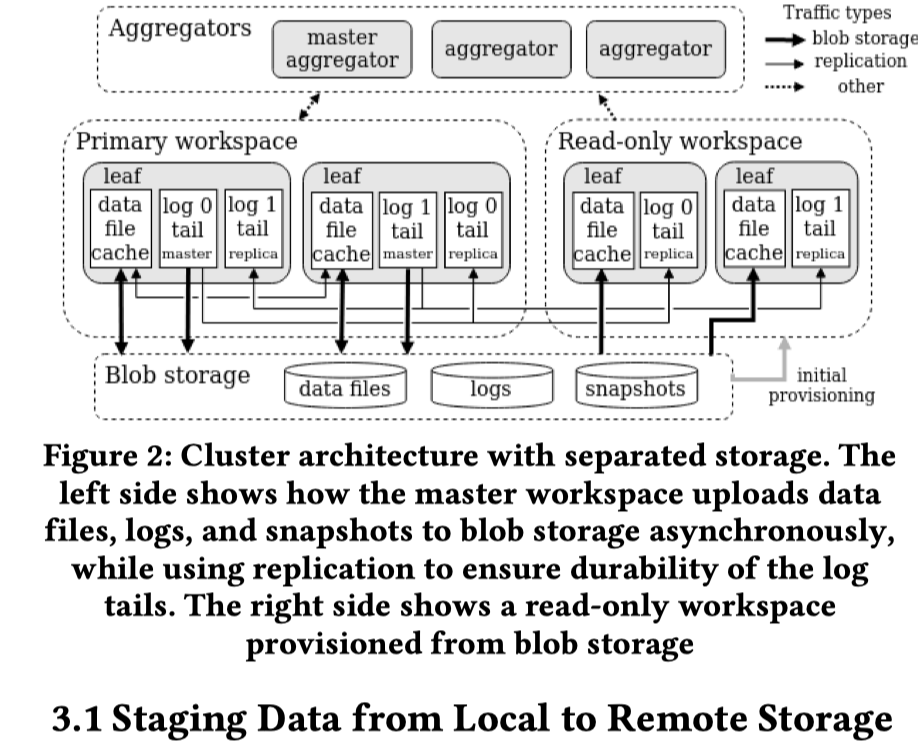
- Committed Log 会被上传到远端,应该有一个 Safe LSN 的机制(类似 Aurora),能够把某个 LSn 之后的上传到远端。
- 新的 ColumnStore 数据文件会被异步尽快上传到远端。然后 Cold Data 就可以被隔离了(我有一点比较好奇,就是这个文件是 master 声称然后同步给所有节点的,还是 replica 接到日志也可以声称?不过一下没找到。就是,LSN 提交之后,数据文件没上传,感觉也要能恢复?这个时候也要 detact 出文件在本地还是在远端吧?感觉这个没描述的很清楚?)
- Master 可以上传 RowStore 的 Snapshot。
- 这里还有个 workspace 的抽象,允许对一份数据有不同的资源。上图有一个 Read-only workspace。这里会从 Blob 拉文件 / RowStore 的 snapshot,然后允许从远端机器 tail log(感觉是因为提交本身和共享存储不绑定,所以要这么搞)
论文的评估中,文章 novelty 在于不需要在 Shared-Storage 做提交,降低了系统稳定性中对共享存储的依赖。这本来是好的,不过文章也说了,这个感觉相当于要自己多管理一层状态,尤其是在 failover、membership change 的时候。文章提了个很有意思的数字,Aurora Storage 成本大概是 S3 的四倍。
笔者认为这算是工程上大力出奇迹。S3 / EBS 上存储能抽象掉很多麻烦。比如写在 EBS 上,可能你就当成数据本身很靠谱了。SingleStore 这样需要手动管 SSD,而且还有很多问题。不过鉴于他们做 MemSQL 出身,可以能比较熟悉这一套。再次感叹一下工程基础好的好处。
架构带来的收益
- 本地 SSD 的性能(本质上是把容错、下层依赖的东西试着一定程度上从主读写链路干掉了,这块性能我其实没测过,懂的可以讲讲)
- BLOB存储日志带来的功能。这里它觉得即吃到了 SSD 写的好,又能用廉价存储来存操作日志。可以 PITR、Time Travel
- 创建 Read Only 节点
这些感觉大家都做了,不过他们要是能做的很好,那确实真的很厉害啊…
Unified Table Storage
SingleStore 的特点是要支撑 HTAP 的负载。压缩呀什么的大家都是一个做法,也没啥新东西。但是它在 Secondary Indexes 这里描述应该是比较详细的,看完大致可以摸清楚这方面的一些详细设计。此外它还提供了 Row-level Locking 来避免冲突。这些东西本身并不是很新,但是它这里写的还是比较完善的。再次注意,这边语义还是快速的点查/插入/Scan.
简单来说,在 ColumnStorage 层,它做的优化是:
- Delete + Insert 给 key 标记删除取代 Merge-on-Read(在新层写 Tombstone),因为在新层写 tombstone 对(blind的)写入本身友好一些,但是对点查很不好。所以感觉一般支持 pk 模型之类的分析数据产品都是 Delete + Insert。
- Delete 被标记在 Meta 中(感觉它这里设计是不会有大批 Delete,比如某个 Select 每隔2行删一个数据,还是这种能被他们非常好的压缩?不然这里写入 Meta 会很大。Delta-io 在这方面格式设计上做了一些 workaround)
Secondary Indexes
LSM 上做 Seconday Index 一直比较 hack,在 LSM-based Storage Techniques: A Survey 里面也有提到。S2DB 这里的亮点是提供了一个分布式上的索引解决方案:
- 在 Segment 层引入 inverted index,提供[索引列 — row-offset-within-segment]的映射
- 在全局引入
的 Global Hash Index,索引指向这个 key 的 Location. 没有支持 Ordered Index 是因为…还没实现。物理结构上 Global Hash Index 也是个 LSMTree。 - 当 Compaction 发生的时候,这里允许 Lazy Deletion。即物理上删除的文件还在 GHI 中(估计访问的时候还要回查 Meta),来通过一部分的读减小写放大
- 写放大是 $O(log(N))$ 的级别
- 只存储 Hash 和 Unique Value。Value 存储在对应的 Inverted index 里,看图。
- (其实我有点好奇,GHI 放大这么大,以至于要这么优化吗…)
- 这个架构大大优化了 Point Read on Secondary Index,因为只需要 O(log(Segment)) 的 Complexity,减少了对 Segment 的访问(比如每个 Segment 访问 Bloom Filter)。
- 允许并发读多个索引然后 merge,类似 PostgreSQL 访问多个索引那套?
- 考察这个结构,这里数据 Layout 都是到具体位置的映射,而不是指向某个 key。这个部分分别有不同的好处坏处:
- 好处:读对应的 Secondary Index 不需要回表,减少一次查询
- 坏处:物理结构变更带来的后台写放大(merge inverted index,处理 deleted)和前台读放大
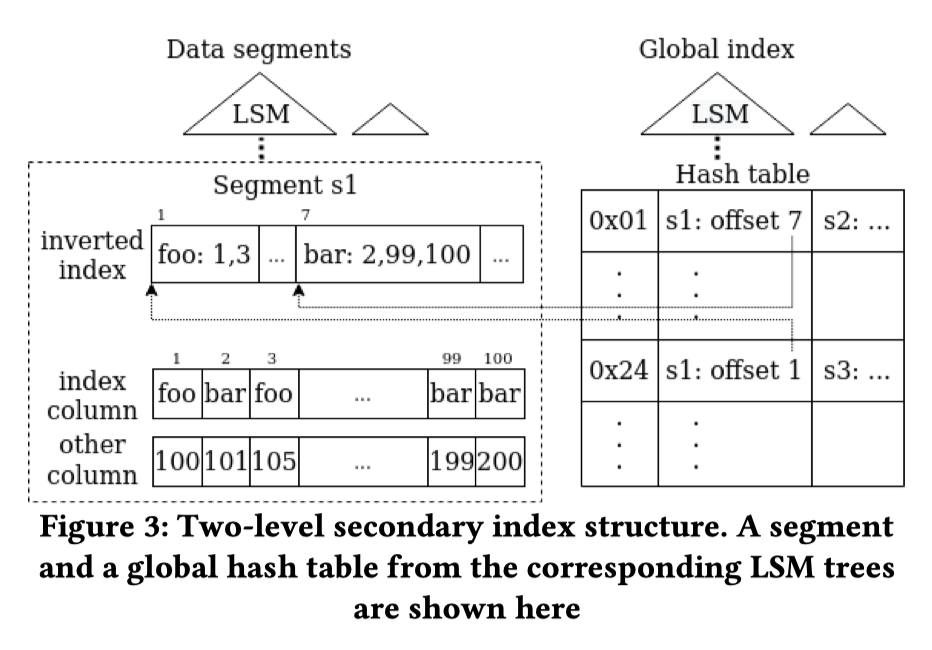
下面介绍两个在这套上面的扩展:
- Multi-column secondary index
- Uniqueness enforcement
这两个都用同一套模型实现。
(不过比较好奇 RowStore 这套怎么做的,硬 Scan?)
Row-Level Locking
(感觉这块类似 SQL Server)
- 需要均衡 Flusher,Merge 任务和前台工作
- 在 RowStore 上实现了 row-level locking. 这里考虑到一个事实:提交之前写都会在 RowStore 中标记(Meta 删除呢?答案是会先进 RowStore。感觉这块有点点类似 Kudu.)这里做的类似 ARIES/IM:严格把 RowStore 的 Primary Key 当锁。
- 允许 Flush / Merge 和前台操作 Reorder,这块它说的比较虚,我感觉其实也类似 Kudu,先前台操作,然后后台把前台操作移动到新的 Segment 上
Adaptive query execution
这里支持分片请求,分区裁剪,也支持 Codegen
访问 S2DB Unified Table Storage 有下面几层:
- 找到需要读的 Segments
- 下推 Filter
- 选择性 Decoding
感觉所有 AP 产品都一个样,呵呵了。
Segment Skipping
- GHI 和 min-max 都可以使用
- O(log(N)) 的时间,N -> Segment
- S2DB 会 adaptively 的选用 Secondary Index,如果 lookup 太多,他就会转化成硬 Scan。
- 如果小表 Join 大表,而且可以用到 Secondary Index,那么 S2DB 会用 Join Index Filter 来做 Dynamic Filter。
Filtering
在执行层,S2DB 有下列不同的 Filter,假设有一个 (col1 = val1) 的 eq expr:
- Regular Filter: 根据前一个表达式的执行结果,来 (masked) decode col1,执行表达式
- Encoded Filter: 直接在 compressed value 上执行。
- 对于 Dictionary 这样的数据来说,如果 ndv 很小,那么效果非常好,反之不怎么好
- Group Filter: 先一把 decode 所有 filtered column,然后全部执行。如果 Selectivity 很高的话(即 filter 过滤性能不太好),这样性能很好。同时,只有某几个中间的 Filter 过滤好的话,也会比较好
- Secondary index Filter: 走 Secondary index 读
S2DB 会对表达式执行做采样,然后根据采样结果来 Exec。此外,这里还会 Reorder Filters,来加快相关的执行。
(这几套除了 Secondary Index Filter, Velox 或多或少都有?)
Reference
SingleStore
- [SIGMOD’22] Cloud-Native Transactions and Analytics in SingleStore
- SingleStore Blog: https://www.singlestore.com/blog/winter-2022-universal-storage-part-5/
CRDB
TiDB
- 什么?比 MySQL 性价比更高的 TiDB Cloud Serverless Tier 来了?https://zhuanlan.zhihu.com/p/596570801
- 基于 Raft 打造物理一致性云原生存储引擎 https://www.bilibili.com/video/BV1B44y1o7H5/
其它
- Andy Pavlo 关于复制的一些评论,可以帮助理解这篇文章:https://ottertune.com/blog/how-amazon-rds-replication-works-and-why-the-faas-database-problem-wont-happen-in-aws/