Fast21 RocksDB Design
离 Google 开源 leveldb,给我们一个很精巧的玩具实现,已经过去了很久很久。Facebook 开源的 RocksDB 成了工业界使用 KV 构建软件的默认标准。RocksDB 是一个功能非常完备的 KV 引擎,它被使用在各种大规模的分布式系统中和单机引擎中。
本文是 FAST’21 中 Facebook 发表的文章,描述了 RocksDB 在 2012 - 2020 的演进。
10年前,Facebook 的工程师拿到 LevelDB,只是针对 SSD 和大规模分布式系统使用,同时想优化一下 Compaction,于是他们添加了 Compaction。很多年后的今天,RocksDB 有了非常丰富的功能、非常丰富的 Tunning 体验。或许这也给了我们一些构建软件上的暗示:先做好一件事情,再慢慢做好别的事情。
论文的尾部附了一张 2012 - 2020 的 RocksDB 功能年表,读起来令人感叹:「前往无限的彼方,那是成为神的漫长道路」

文章的开始介绍了 RocksDB 的一些经验:
- 在写入/读取等各个方面的配置/tuning
- 不同负载上都能支持
- 配置 / Metrics / 完善的 debug tools 和迁移工具等
RocksDB 本身非常配置化。网上很多地方介绍的是它的主要链路,但是它很多组件都是可配置的(论文只提了亮点,我后面会提更多):
- WAL Treatment
- Compaction Strategy
- RUM Conjunction
- Dostoyevsky
- 可以有高读写吞吐
这里 RocksDB 也有不同的 workload:
- Database (最主要的应用): crdb, tidb, MyRocks…
- 读写混合负载
- 读:点查 + Iterator
- 会有 Transaction 和 Backup
- Stream Processing: eg, Flink, Kafka Stream, Samza, Facebook Stylus
- 重写
- 读:点查 / Iterator
- 会有时间窗口和 ckpt (其实我不是很熟悉,之后可以看看 Flink)
- Logging / queueing service: Facebook LogDevice, Uber Cherami, Iron.io
- 重写
- 读:点查 / Iterator
- 支持 HDD,比如 Logging 根本不用那么好性能,不过感觉 queue 还好(话说我感觉 queue 和 Stream 本质区别是啥样的呢…)
- Index Service: Facebook Dragon, Rockset
- 应该是类似分析 / 训练用的 Servicing 引擎
- 重读
- 读 Pattern 为 Iterator,相当于是 batch scan
- 负载应该是训练出来的东西 bulk load,灌入数据
- Caching on SSD: Netflix EVCache ( 这里还写了 Pika,但我感觉 Pika 不完全是 in-memory cache 了,还是算 DB)
- 重写
- 读:点查
- 可以丢弃存储的对象
下面给了个负载表格,其实很有参考价值
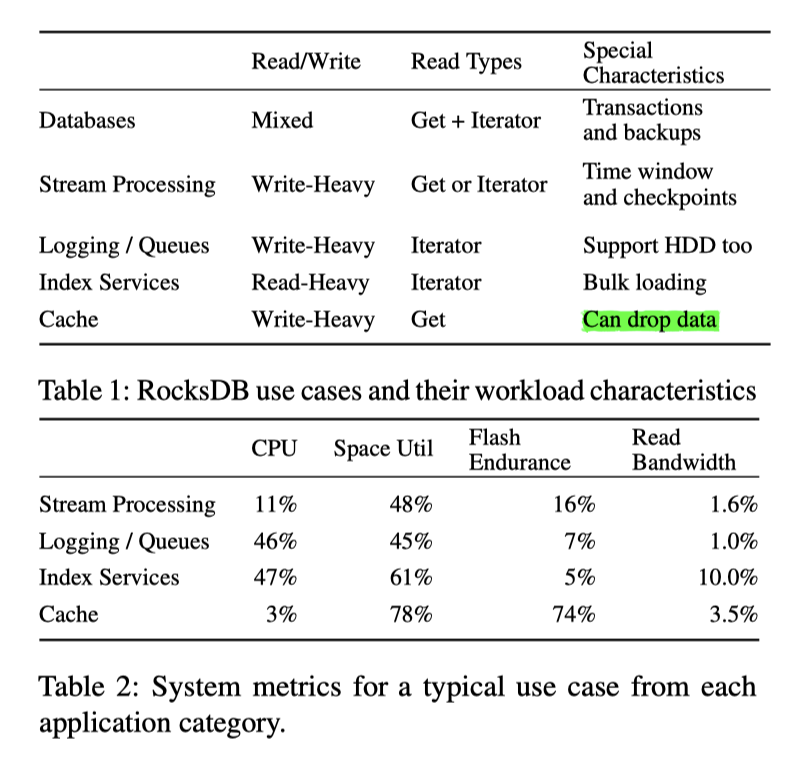
可以看到,RocksDB 这些负载都可以支持,非常强悍。
同时,所有系统都需要 checksum(虽然 RocksDB 可能会要求用户自己在上层维护正确性),同时也要把错误合理抛给上层。这些东西 xjb 写软件是不会碰到的,但是做一套严格的存储系统,还是非常必要的。RocksDB 会做一些逐个key的 checksum,也会后台检验、发送数据的时候校验等。
除了上述存储系统功能,这里还有:
- Monitoring framework
- Performance profiling
- Debug tools
这里 RocksDB 本身可以上报一些信息,然后被使用到框架中。
上述这些东西都是 RocksDB 漫长开发的一部分,本论文讲述了 RocksDB 八年的开发史和 design choice.
文章的编排是:
- SSD / LSM 的基础 / LSM 怎么适配各种应用
- 主要的优化在 12 - 20 年的流变
- RocksDB 在大规模分布式系统(shared-nothing 系统,多租户,升级,备份等)中的经验教训
- Failure Handling / CRC 等处理,这部分实际上是非常工程经验的。RocksDB 的部署中出现了很多 failure 相关的经验教训,在构建鲁邦系统中,这些都需要学习的
SSD / LSM
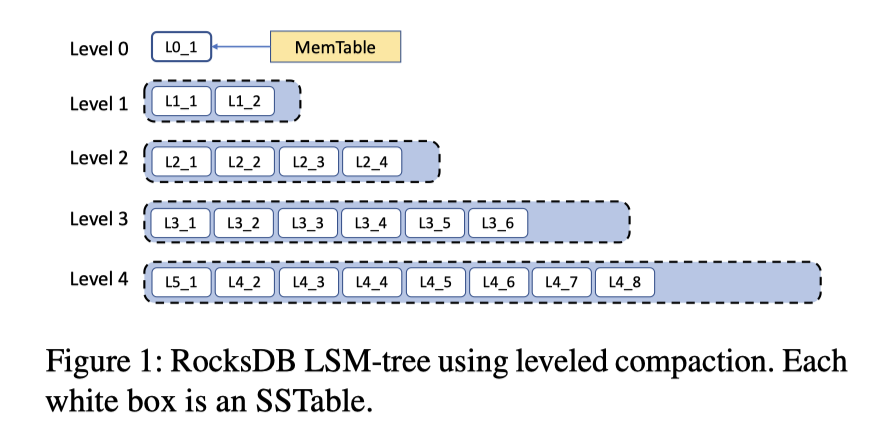
LSM 本身被认为是顺序写,相对来说对 SSD 会友好一些(不提 WiscKey)。RocksDB 的主要架构如上图:
- WAL
- MemTable
- SSTable
- (在任何 Compaction 下)L0 都允许重复的 Range
- SST 有对应的 BF (后面也摸出了很多别的索引)
- 多种 Compaction,如下图。RocksDB 用 Compaction 的方式来协调 RUM / 写放大之类的参数,来实现一些具体的 tunning / 优化。
- Level: 正常的 LevelDB 那种压缩。
- Tiered: Universal Compaction。RocksDB 使用了 L0 层的特性来实现它
- FIFO: 对 In-memory caching 使用,按照一定顺序清量压缩,purge 掉一些旧的文件。适合用来实现一些类似 cache 这样可以 discard 的功能。
Compaction 优化史
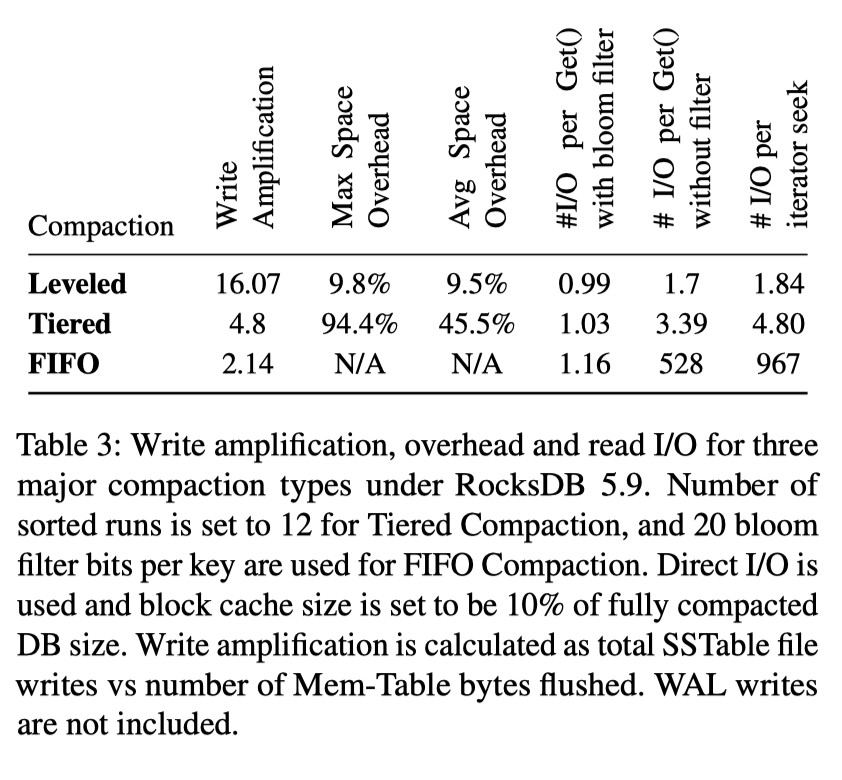
Compaction 方式的选择可以根据应用的性质甚至客户的 b 需求来选择。同时,论文以历史演化、时间顺序的方式,介绍了 RocksDB Compaction 的演进。
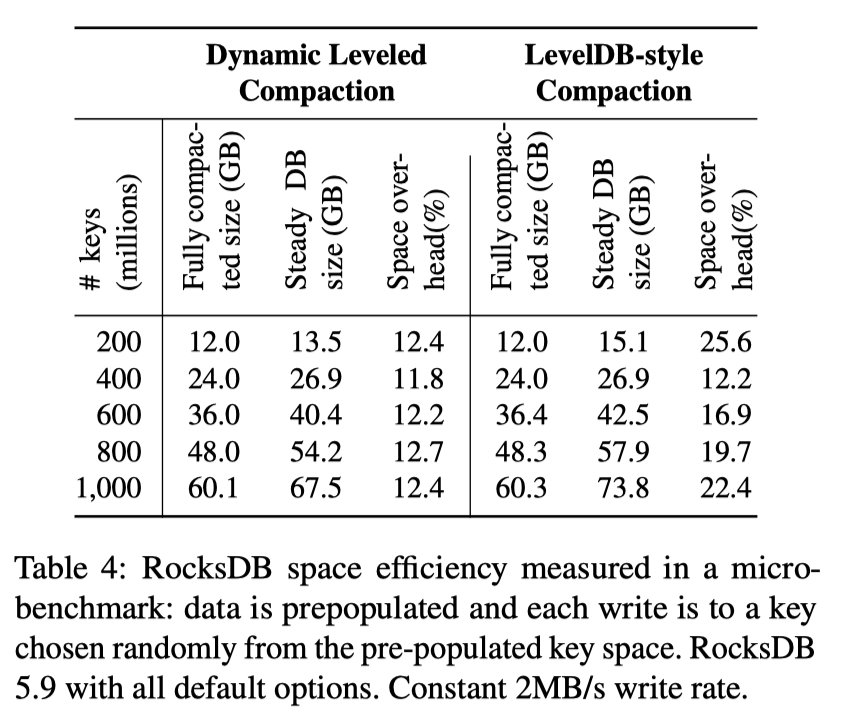
最早的时候,LevelDB 实现了 Leveled Compaction,这种方式自然 WA 很大。RocksDB 实现了并行 Compaction 后,磁盘受到的压力更是变大了。所以,最早期,RocksDB 优化的目标是 WA。关于 RocksDB 观察到的放大,除了 Table 3,还有下图:

这里统计了各层的 WA,更有意义。同时,WA 除了 LSM 层的放大,还有一些 WAL 的放大,因为 SSD Block 是 4/8/16KB 等大小对齐的,所以 WAL 写 + Sync 在 block-io 层其实是很重的,可能会有成百倍的写放大。同时,Leveled Compaction 会大概对应 10-30 倍写放大。总之,RocksDB 希望优化 WA。
这里 RocksDB 引入了 Tiered Compaction,即 Universal Compaction. 下面是 ZippyDB 和 MyRocks 引入 Tiered Compaction 之后的情景:
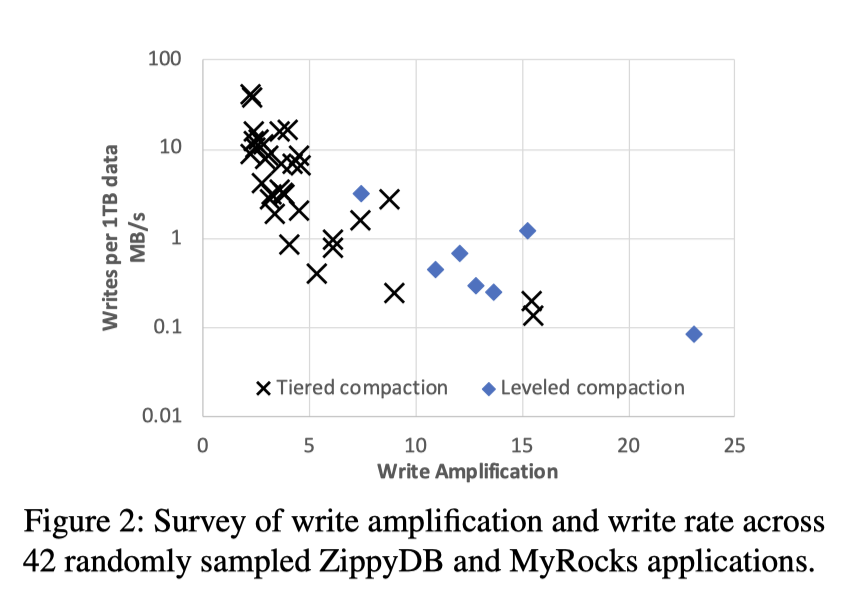
RocksDB 的使用者在写入剧烈的时候,通常会使用 Universal Compaction,读要求高会使用 Leveled Compaction。
WA 优化完了,下面优化 Space。读者可能懵逼了,Leveled Compaction 不是本来 Space 放大就很小吗?这里其实还涉及一篇论文:
https://research.facebook.com/publications/optimizing-space-amplification-in-rocksdb/
RocksDB 的设计者们认为,实际上,对大部分用户来说,RocksDB 上层和 SSD 写开销都用不到上限,大部分应用根本不会那么极端的去写。对大部分应用来说,利用空间是比较重要的事情,这样可能能提供更多的资源利用。
因为 Leveled Compaction 已经是空间优化的了,所以 RocksDB 搞出了 Dynamic Leveled Compaction:
- 每层的大小会根据最后一层的大小动态调整
- 相对配置死的 Leveled Compaction,更有空间利用率
- Leveled Compaction 如果配置死,很多时候会 fallback 到很奇怪的情况,比如先落深层,再落浅层,然后工程上放大其实比较大,RocksDB 说最大有大改 90%。对于 Dynamic Leveled Compaction,用户可以获得很稳定的压缩率
- 开启了这个功能之后,在 UDB 中,空间占用比 InnoDB 降低了 50%。
RocksDB 接下来希望优化 CPU(我估摸着多少因为之前多线程写有些粗暴了)。不同配置的机器、不同的负载,CPU / SSD 瓶颈其实是不一样的。虽然这么说,不过以前 HDD 或者 SSD 比较糟心的时候,瓶颈一般会出现在盘上,但随着盘性能变好,在有些配置上,可能瓶颈会开始出现在 CPU 上了(RocksDB 论文里也说,他们盘一般不是那么好打满,大部分情况瓶颈不一定在盘上,不过我觉得瓶颈在盘上可能是个很古怪的事情,例如 queuing 算不算盘上 io 造成影响大呢?)。如图:
至少,在 Facebook 部署 ZippyDB 的场景中,CPU 开始一定程度上成为瓶颈:
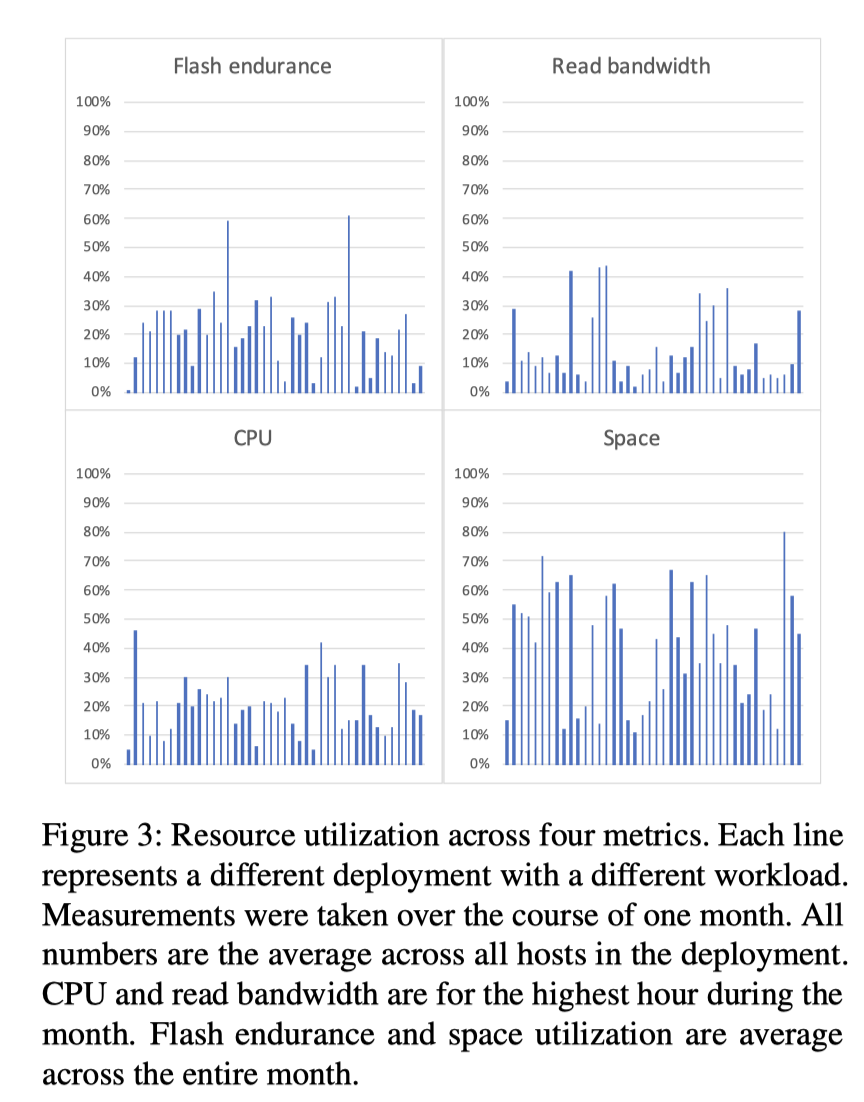
在这种情况下:
- 可能可以采用更轻的压缩策略
- 不适合 SSD,因为可能擦写太多搞坏 SSD 了
RocksDB 可以配置压缩相关配置,和 Hash-map 相关的 memtable / File,来优化 CPU
RocksDB 和新技术
- Open-channel SSD, multi-stream SSD, ZNS:
- 提供了更好的 SSD 管理,降低 Query Latency,减少 flash erase cycles
- 只有少数应用能有优化,同时维护麻烦很大
- 见 RFC: 这部分目前在外部维护。未来可能会抽出一个 FS 层(类似 arrow::fs? )
- https://github.com/facebook/rocksdb/pull/6961
- In-Storage Computing:
- 并不知道收益有多大
- API 相关的设计暂时不好决定
- Disaggregated (remote) storage:
- 能够利用好 CPU / SSD 资源 (池化?)
- 需要处理 IO Latency 和下层 QoS
- (是不是可以参考 CloudJump ?)
- Storage Class Memory (已经亡故的傲腾?)
- 扩展 DRAM,但是实现 block cache 和 memtable 会比较难
- 设计为主要存储:通常 IO 没那么是瓶颈(虽然感觉延迟有问题,但是感觉因为延迟换,成本也太高了)
- 作为 WAL:可能需要额外设计一部分 Staging Area,类似 WAS?
回顾
目前,SSD 的价格还没有那么低,尽管大家画饼他的价格会很低,但是 SSD 存储密度之类的还是不如 HDD,同时价格还是没有那么廉价,所以对大部分用户来说,节省空间和 WA 还是比较重要的。
不管怎么样,RocksDB 都提供了足够多的选项。此外,对于大 Value,RocksDB 还开发并重新开发了 BlobDB,来减少大 Value 造成的 WA。
在大规模分布式系统上的经验
RocksDB 本身并不是一个大规模分布式系统,只是一个用到挂载盘的库。但是 RocksDB 的用户很多是需要妥善维护的大规模分布式系统,文章在下面几点上进行了介绍:
- 资源管理
- WAL 处理
- 文件批量删除
- 数据格式兼容性
- Configuration Management
资源管理
对于 Shared-nothing 架构,单台机器一般会有很多 RocksDB Instance,每个服务一个 Shard。在实践中,Shard 的量级一般是数十甚至数百的。这个时候,资源共享和限制就变得很重要了。这里可以配置的资源有:
- MemTable / Block Cache 的内存
- Compaction 的 IO 带宽
- Compaction 的线程数目
- 磁盘总用量
- 文件删除率
- 这里和 SSD TRIM 状态有关,见后文
RocksDB 允许定义一个库的局部资源管理(Resource Controller),来管理资源,eg:
这允许作出一些上层控制定义。此外,这里是库级别的处理,机器级别的处理会难得多,因为涉及一个全局资源的管理。因为每个 Instance 在当前实现也不会管别的信息,这里提到了两种 admission control 和资源策略:
- 一开始使用 Compaction 率低,只有有 lag 才拉大频率
- 不一定能控制好,而且这个会导致一般的资源利用率比预期低
- 在多个 Instance 中间共享资源开销
这里也提到,对于 CPU 资源,可以适当使用池化的内存,这样可以让系统线程数不至于过多。(感觉这种事要求做更精细的调度,然后从系统层移动到 RocksDB 层)。
WAL 管理
单机数据库通常需要开启 sync 模式,但是分布式数据库可能写了三副本,在单机的要求上,可能人家集群优化的不好,导致要开 async。同时,可能也有分布式系统只把 RocksDB 当成存储,然后写自己的日志,这个时候也会把 sync 关掉。这里引入了下列模式:
- NO-WAL
- Buffered WAL
- Sync
文件删除限制
文件这个概念是在 os 和 fs 层引入的抽象。像 XFS 这样的 SSD 处理的比较好的 FS,一般可能会在删除文件的时候给 FTL 之类的发 TRIM。TRIM 可以透过文件层告诉 SSD,这部分数据已经不需要了,去 issue SSD 来进行可能的回收,降低需要的 OP 的开销
这种方法,在 Compaction 的时候也有问题,就是删除文件大量 TRIM 可能触发 SSD GC。这里通过用户测很奇怪的推断 batch del 的行为,来防止触发 GC,其实还是蛮怪的,网友评价:
格式兼容性
RocksDB 每隔一个月会发一次小版本,由于 CD 的情况,新版本如果有 bug,也需要回滚。这个提出了格式兼容性的要求。RocksDB 除了开发新功能一般会保证格式不变,同时,不能删除旧版本代码中对格式的兼容。
RocksDB 也会采取前向兼容,这个就更难了。这里会有一些类似 Protobuf 之类的机制来保证,RocksDB 至少能打开一年内的未来写的文件。这个感觉需要在设计上下功夫,同时感觉也可能和各种配置之类的有关。
(我个人的体验是:先写好新格式代码,测试完善后再上线,上线之前,新旧版本都支持读这份格式)。
Manage Configurations
LevelDB 的配置管理是比较简单的,LevelDB 会把 Version 相关的逻辑做到 VersionSet 里头:
RocksDB 有很多可以更改的配置,这些配置已经非常复杂了,首先,在正确性校验上,RocksDB 在 New之后可能会记录配置,然后,之后打开的时候,会根据用户的 Options 对比这些配置,查看:
- 打开的配置和这个文件是否兼容
- 如果不兼容,可能会有一个 rewrite 工具,能够迁移到兼容的配置上
此外,一个很复杂的事情是,RocksDB 的参数很复杂。本来这些东西可以默认参数(DynamoDB 论文里说他们都没啥对外参数,虽然我觉得很玄)。同时,他们作为一个库,只能提供参数出去,让上层去填。这个地方维护这些参数还是很复杂的。RocksDB 团队表示,会考虑 automatic adaptivity,但是这样动态调整参数也是非常复杂的。
Backup & Replication
RocksDB 有几种 copying 方式:
- Logical Copying
- 源端:Scan 出来(尽量不 fill cache 或者填充一些不需要的 Compaction Statistics)
- 目标端 Bulk Loading
- Physical Copying: Copying SST and Ingest
- 提供自身的工具,去做 SST Ingest
- 这里需要借用文件的语义,所以 RocksDB 认为,Block Device 上做,这套便捷程度还是不如 FS 上做。
RocksDB 甚至提供了一个 Backup Engine,因为 Backup 可能有多份:http://rocksdb.org/blog/2014/03/27/how-to-backup-rocksdb.html 。用户可以在 Backup Engine 上做自己的实现。
这些东西在 API 上都有一定的复杂性:
- 把一个 Ordered Seq 给重放
- 不是那么在意 Order 的重放
这里有一个问题是,不同于 Dgraph 的 Badger,目前 RocksDB 还不能 Take 一个 user-defined Timestamp,然后 Out-of-Order 写。
错误处理
错误处理是只要在大公司碰过 SB 硬件就一定会遇到的问题。RocksDB 有比较多的经验来做相关的错误处理。
RocksDB 在错误处理上有两个层次:
- 给所有可能 corrupt 的地方做 checksum
- 检查错误,尽早发现错误,防止静默错误影响副本或者在别的链路上影响集群
- 维护抛出错误的合适语义
RocksDB 面临着下面的错误:
- SSD 盘故障
- 由于性能原因,用户可能不会开启 DIF/DIX 等校验方式
- 内存 / CPU 故障:发现原因较少,不过我姑且也碰到过几次
- 软件故障(嘿嘿,很常见的,我碰到过很蛋疼的)
- 网络传输的时候产生的问题(网卡等)
根据 RocksDB 的统计:
- 在 FB,每 100PB 数据,一个月会出现三次 corrupt
- 40% 的情况下,这些 Corrupt 已经扩散到了别的机器上
- 网络系统可能会有每 PB 17次 checksum mismatch (fb… 这么牛逼的吗)
基于以上的情况,FB 认为,需要尽早找到 Corrupt,来减少因为 Corrupt 产生的 Downtime。在分布式系统中,还是能够用正确副本代替错误副本来修正数据的:
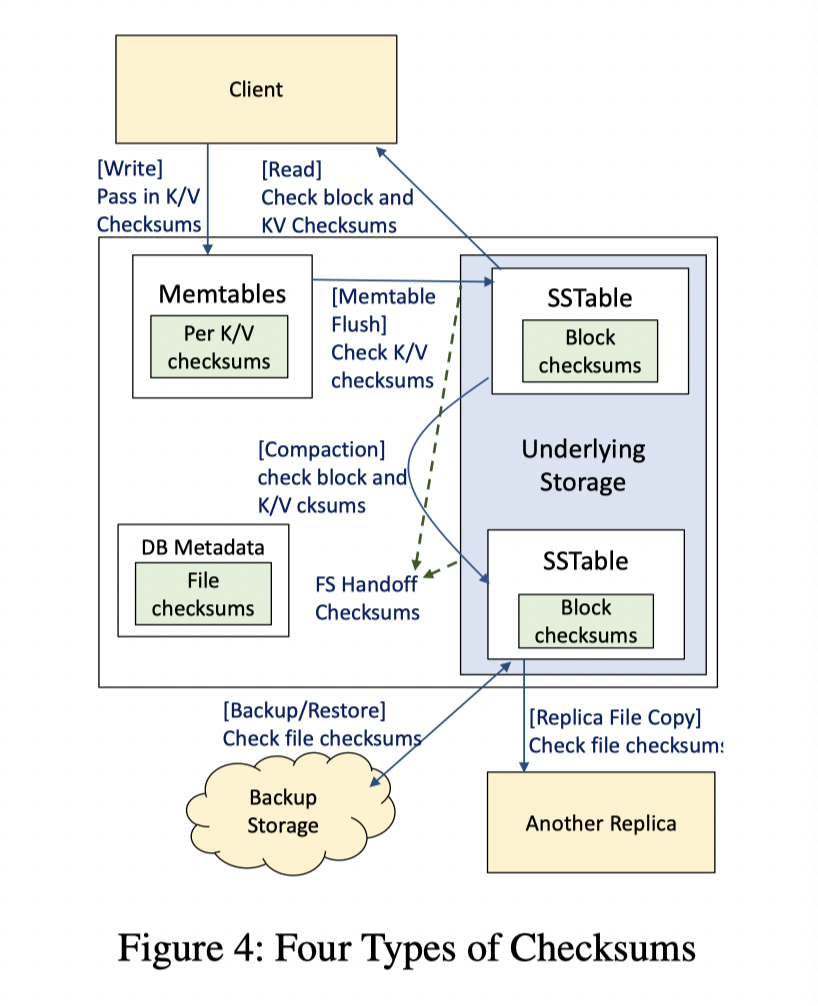
这里在 LevelDB 的 Block Checksum 和 WAL Checksum 之外,提供了不少层次的 Checksum,如上图。:
- Block Integrity:
- SST Block 和 WAL Block 会带有 crc
- 每次读,包括 SST Ingest,bulk loading 都要验
- File Integrity:
- SST 文件本身会被 Crc 一层,因为有的时候会走文件整个传输,但是 WAL 目前还没有
- Handoff Integrity:
- 数据算完了会给 Write API 一份,在收到一端做 check。这个在 Oracle ASM 之类的系统实现了。
RocksDB 会做上面的保护。除此之外,内存逻辑上,MemTable 之类的没有保护。RocksDB 会编码 Per-Key-Value-Pair 的 checksum,来完成上层的保护,防止写入的时候出现错误。
此外,RocksDB 的哲学会:
- 尽量返回错误
- 如果是无法单机恢复的错误,上报给用户。