InnoDB Link_buf
InnoDB 在 MySQL 8.0 之后,提供了 Lock-Free WAL 的机制,顺序申请 LSN,然后把内容拷贝到 Log 应该写入的 Buffer 中,最后写入 Disk,然后通知上层。同时,Page Flush 和这套机制是联动的,FlushList 和这套日志流程需要联动。
为什么需要贴这块呢?相对于一般的 mpmc,mpsc 等队列,WAL 是一个在数据库中很常用,与 concurrent-queue 有共同点,但是也有不同的内容。因为它涉及内存拷贝和 IO。
我们先简短介绍一下从别的文章抄来的代码入口,InnoDB 对内容的修改会走 mtr,mtr 会有对 buffer 的锁和 Page Change 的 Logs,Log 在 mtr 执行阶段会 buffer 在 mtr 的内存中,在 commit 阶段会移动到 log_sys_t::buf 中,这里会通过 log_sys_t::buf 来写,日志会被拷贝在 Log Buffer 中,当配置 innodb_flush_log_at_trx_commit=1 的时候,这里会在 txn-commit 的时候持久化日志。
写入 Log 是在 mtr 提交的时候:
- 分配 LSN
- 等待内存的 Ring Buffer 匀出足够的空间,然后 Link 到对应的结构中
- 拷贝到内存 Buffer 中
在这之后,Page 的写入就被写入到内存的 Log Buffer 了,随后,脏页需要被加入 flush list,这个时候,为了维护脏页写入的顺序,会有:
redo_log_mark_dirty_pages: 标记页面为 dirty- Link 到对应的结构中
- 由 Recent Closer 线程来处理
需要说明的是,Flush 和 LSN 强相关,因为 ckpt 依赖 LSN,这个可以说是 Recover 层的原因,InnoDB 的 Page 会有下面两个参数:
oldest_modificationnewest_modification
这两个词含义和字面意思差不多,mtr 修改单颗 index 可能会修改多个 Page(虽然概率上可以当成大部分乐观的场景,它只会修改一个 Page,但是涉及 SMO 或者什么的时候,可能会修改多个 Page),它在 mtr commit 的拷贝 log 阶段需要持有这些页面的锁。这个地方会尽量让 flush list 按照 oldest modification 的时间下刷,在 8.0 之前的版本,甚至是按照这个顺序下刷的:
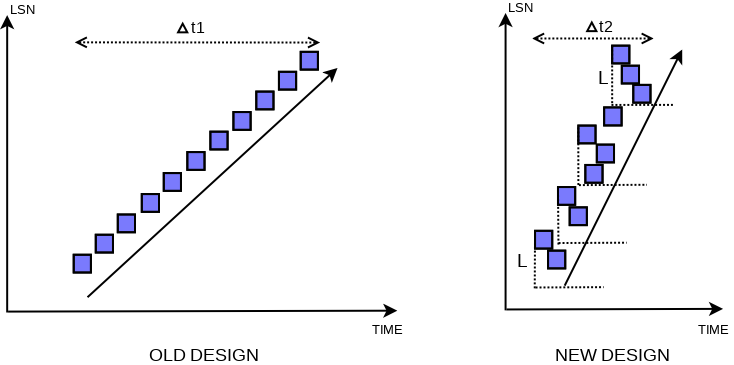
这个和 checkpoint 的和 Recover 的处理有关,checkpoint 的时候,从某个 Checkpoint LSN 中恢复,可能要考虑 LSN 和恢复之间的关系:
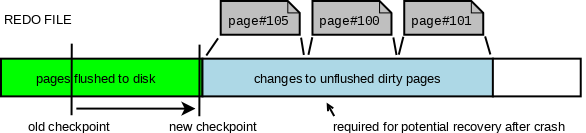
否则的话,这个可能恢复的时候,需要一些特殊的处理机制:

在新的 Design 中,这里大概会维护一些乱序度,然后让对应 Page 在 L 的区间内保证一定的 Order。
系统中,维护了下面的变量:
- (
Link_buf)recent_written: 记录内存拷贝的 write. 护写log buffer的完成状态,recent_written中维护的最大LSN, M表示, 所有小于这个M的LSN都已经将它的redo log写入log buffer. 而这个M也是(如果这下crash, 可能会触发的)崩溃恢复的截止位点, 同时也是下一个写log buffer操作的开始位点. - (
Link_buf)recent_closed: 维护 flush LSN 的递增性质 - 额外的后台线程(
log_writer/log_flusher,log_flush_notifier,log_checkpointer, …
这篇文章不会介绍太多 Buffer Pool 无锁 flushing 的细节,因为写文章的时候我也没完全搞懂。
代码入口
具体而言,这块相关的代码在 log0buf.cc 里面,这里面也有不少的描述,然后一些头文件定义在 log0log.h 里面,log_t 类型在 log0types.h 里面. 外界调用在 mtr 的代码中:
1 | /** Write the redo log record, add dirty pages to the flush list and release |
LSN 分配
我们不过度牵涉 mtr 的细节,首先这里需要 reserve 对应的 lsn:
1 | @see @ref sect_redo_log_buf_reserve |
这里会利用 fetch_add 来拉大对应的内容,这里有个区别是 sn 和 lsn:
- sn 是逻辑的 bytes
- lsn 是物理上的 bytes bias
1 | Log_handle log_buffer_reserve(log_t &log, size_t len) { |
可以看到,这里用 fetch_add 添加了对应的 sn / lsn,分配了日志对应的 start_lsn 和 end_lsn,然后这部分算是 LSN 分配完成了,不过,在同一个函数中,还有:
1 | if (unlikely(end_sn > log.sn_limit_for_end.load())) { |
这一部分是要等待 Log 分配足够的空间。这个空间大小是怎么会是呢?
等待 LSN
(这里可以参考 InnoDB REDO LOG BUFFER管理 - 丁凯的文章 - 知乎 https://zhuanlan.zhihu.com/p/358690853 这篇文章,写得比较细)
log.sn_limit_for_end 是个 atomic variable,它的更新受锁保护,但是读的时候可以直接 fastpath 读,来保证读的性能:
1 | /** @{ */ |
这里在 log_wait_for_space_after_reserving 里面,会走:
1 | log_wait_for_space_after_reserving |
这个地方,关键的函数是 log_write_up_to, write_lsn 是写入 buffer 的 LSN,这里保证这部分内容能够被写入.
这里其实有个很 confusing 的地方,就是这个地方保证的是环状 Log 的总空间和 Log Buffer 的空间,出现问题概率非常低。这个和后问 Link_buf 之类的空间不完全一致(严格来说应该比它大很多,
Link_buf
我们提前介绍一下 Link_buf, 首先,我们可以看到,上面的拷贝是一个申请 LSN,然后各个 mtr 分小段 copy 的模式,那么,这个地方势必有几个 Log 水位,不考虑 ckpt 那些东西,就看内存的话:
- 已经 Flush 的 WAL
- 拷贝完了的 WAL
- 正在拷贝和分配了没拷贝的 WAL
这个时候,会有下面的水位图:
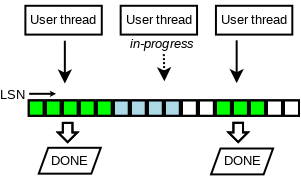
Link_buf 用来维护和推进这些水位,它把数据划分为 slot,并且保证数组元素(slot)更新是原子的, 以环形形式复用已经释放的空间,并启用单独的线程负责数组的遍历和空间回收, 线程在遇到空元素(empty slot)时暂停。
和:
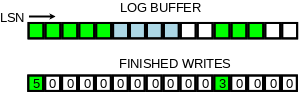
这里可以维护 write_lsn 和 ready-for-write 的连续 LSN:
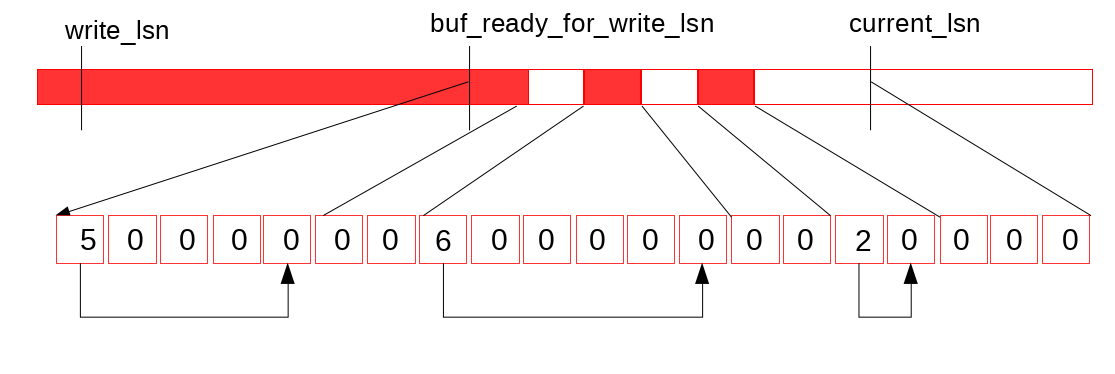
这里它维护了几个水位和一些中间的状态。
关于 Link_buf,这个类型只有三百余行,内容可以参考:http://mysql.taobao.org/monthly/2019/05/08/ 。需要特别注意的是,Link_buf 很多约束是需要上层来保证的。
Link_buf 会分配一块比较大的内存(见后文)然后用于 Link,我们先看看 API:
1 | /** Add a directed link between two given positions. It is user's |
我们可以借助官网的图片来理解这些 API:
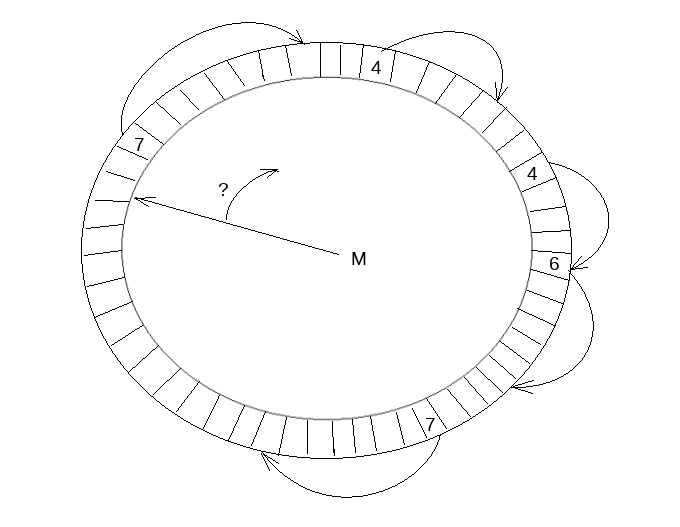
tail: 其实是连续的队列的开头,用来开始跳转,这个是一个 atomic 的 lsn 或者别的位置标记has_space判断有没有连续空间,因为Link_buf这块的内存可能会少于可分配 LSN 的内存advance_tail_until和advance_tail都会尝试推进 tail,其实相当于推进空间。这个可能会传一个停止条件进去。add_link: 添加一个 Link, Link 是什么呢?就是如上文所述的 4->, 4-> 的标记。
还有一些内部实现的 API:
next_position: 跳转到下一个地址clain_position: 把本地址置 0
这里感觉 lock-free 也不难,因为假设
- 并发
add_link- 上层保证了 from - to 的分配是 sn 分配的,同时,用户插入的一定是
has_space的,之前没有 overflow 的之后必定不可能 overflow,所以操作成功的没有冲突
- 上层保证了 from - to 的分配是 sn 分配的,同时,用户插入的一定是
- 在
advance_tail的情况下,已经存在的写是已经has_space的,这里只会消除完成的写。极端情况并发advance_tail的时候,可能推进不原子,所以只能有一个线程在advance_tail,观察下列代码可以轻松得出这个结论
1 | template <typename Position> |
Copying Redo Log
这节内容可以参考:http://mysql.taobao.org/monthly/2021/09/04/
1 | write_log.m_handle = handle; |
write_log 是一个函数对象,这里对每个 block 写入这个内容,具体的:
1 | /** Write the block contents to the REDO log */ |
首先介绍一下 mtr_buf_t:
mtr_buf_t是由一个双向链表组成的动态buffer,每个元素是512B大小的buffer(512B刚好匹配一个log block大小)。随着mtr_buf_t存储的数据的增加,它会自动生成新的512B的buffer,并加入双向链表中。
这里会走 log_buffer_write ,拷贝内容到 log_buffer 中。
也就是说,这个内容不是完全「一次性拷贝」的,而是按照 block 粒度拷贝到公共 log buffer,然后调用 complete 的,这里涉及两个函数:
- log_buffer_write
- log_buffer_write_completed
log_buffer_write 会完成拷贝,拷贝有什么难的呢?答案是这里会把 block 转化成 innodb 物理 Redo Log 的格式,还是要一些转化的。这里会拷贝到公共的 log buf 中。
log_buffer_write_completed 相对来说复杂一些,我们首先看一些别的定义:
1 | /** Default value of innodb_log_recent_written_size (in bytes). */ |
和:
1 | /** Number of slots in a small buffer, which is used to allow concurrent |
这里会等待有足够的空间然后 add_link:
1 | void log_buffer_write_completed(log_t &log, const Log_handle &handle, |
Log Writer && Log Flusher
这部分代码在 log0write.cc,这里为了冲突,拆分成了多个线程来做 Log 的写入。
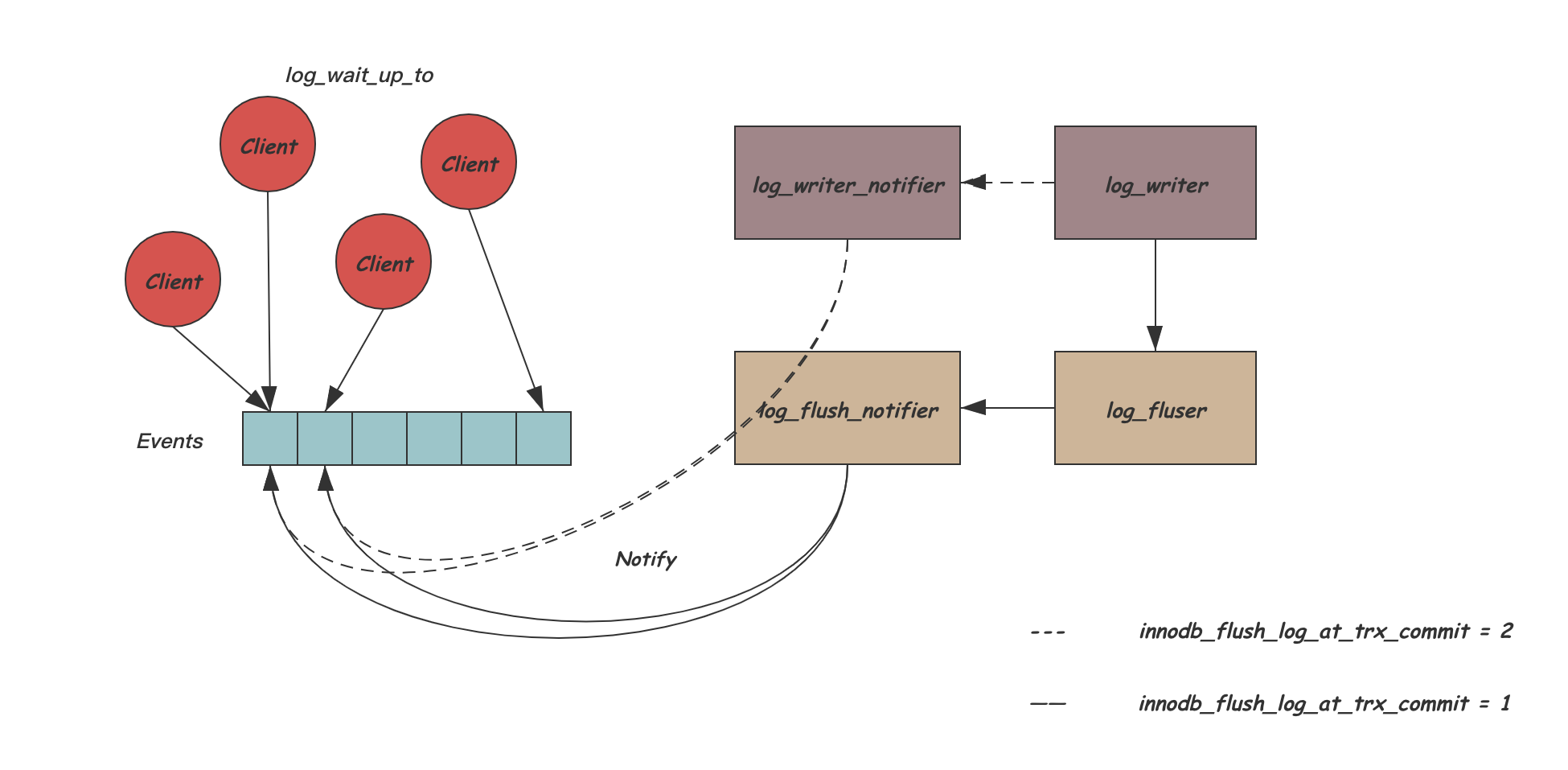
(图片来自 CatKang 的博客)
首先,我们关注 Log-Writer Thread,他会用 Link_buf 去追那些完成的操作,把它们 Link 起来,具体的条件是:
- 遇到的都是连续的(见
Link_buf的图) - 不大于一定大小(可能 4k)
收集完之后,它会标记出对应的数据,然后映射到磁盘结构上,标记 Header 之类的内容。这里有个小细节是 incomplete block 在其中的处理,具体可见:InnoDB:redo log(1) - Skywalker的文章 - 知乎 https://zhuanlan.zhihu.com/p/386710765
这里 Log Writer 会通过:
1 | log_advance_ready_for_write_lsn |
等调用来推进。
References
- https://mysqlserverteam.com/mysql-8-0-new-lock-free-scalable-wal-design/
- http://mysql.taobao.org/monthly/2018/06/01/ (上面这篇的翻译)
- https://catkang.github.io/2020/02/27/mysql-redo.html InnoDB Redo Log 的一个 general,包括各层,本文只是其中一个小碎片
- InnoDB Redo Log 调整,允许动态调整 Redo Log:http://mysql.taobao.org/monthly/2022/09/03/
- Rsygg 神文 InnoDB 确定 checkpoint-lsn 的一处细节:https://github.com/rsy56640/triviality/tree/master/content/innodb-ckpt-lsn
- InnoDB 5.7 版本的实现,没全部看完,简单过了一遍,拥有一定参考和对比价值:http://liuyangming.tech/06-2019/LogBufferAndBufferPool.html
- InnoDB REDO LOG BUFFER管理 - 丁凯的文章 - 知乎 https://zhuanlan.zhihu.com/p/358690853
- http://mysql.taobao.org/monthly/2021/09/04/
- http://mysql.taobao.org/monthly/2019/05/08/
- InnoDB:redo log(1) - Skywalker的文章 - 知乎 https://zhuanlan.zhihu.com/p/386710765