Kudu: Storage for Fast Analytics on Fast Data
Kudu 是一个声称「既能快速更新、又能快速查询」的分布式存储。它由 Cloudera 开发,作为 Hadoop 生态中存储的替代品,并在 2013 年开源。Cloudera 使用了 Impala + Kudu 的架构来作为一些替代( Impala 可以视作 Presto 类似的产品,支持在 HDFS/Hive 上做高效的查询,国内的 Apache Doris 也是早期从 Impala fork 过来的)。
Tips: Kudu 和 Impala 都是羊,Kudu 是 「捻角羚」,Impala 是小一些的黑斑羚。
Kudu 的模型以 Primary Key 为主,类似 StarRocks 的主键模型。之后我们也会介绍,不按 Primary Key 查询的时候,Kudu 的性能会光速拉胯。论文写于 2015 年,相对于 Presto 这种同样 2013 左右放出来,但是 2019 年才发表论文的系统而言,Kudu 很多地方显得没有那么详尽。很多地方翻一些工业界使用者的 blog 也能发现一些问题。不过 Kudu 使用好像相对少一些,国内看到网易应该有人用。
Kudu 使用的还是 shared-nothing 的处理方式,同时,Kudu 的文件写入之后也是不可更新的。Base + Delta 的方式被采用以处理这个模型。Kudu Delta 处理的方式相对来说有点类似 Position Delta Tree。阅读 Kudu 论文,我认为应该主要关注「Tablet 存储」的部分,其他部分有的不是很重要,有的我甚至认为非常草台。
Cloudera 当时希望的 workload 是:
- 需要有 streaming ingest 的数据管线,同时支持一些 updates
- 有一些定时作业来分析
- 高吞吐的存储
- low-latency random access
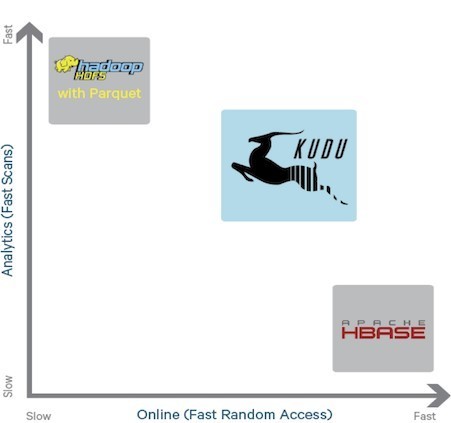
Kudu 提供了对应的 api:
- Row-level inserts / updates / deletes
- Table Scan
Kudu 内部使用 Cfile 格式存储文件。这是 Kudu 给自己搞的适合自己的列存文件格式。
下面是论文的部分,在阅读的时候,我会尽量以论文为主轴,但是参考 Kudu 最新的实现。
Concepts
Table: 有定义好 Schema 的格式的表,一个 subset 的字段会被定义为 primary key。primary key 模型上必须是 unique 的,对 primary key 的删除被定义为快速的操作,否则可能会扫全表,因为它不支持 secondary index。
Schema 中,可以视作 <varchar: T> 的映射,Kudu 似乎不支持嵌套结构,如果有嵌套的结构,应该把这部分内容展开。关于 Kudu 的类型可以参考:https://kudu.apache.org/docs/schema_design.html#column-design
关于 DDL,Kudu 支持一些基本的 schema change,在用户层面需要执行 alter table,Kudu 会给每个 column 维护一个 id,同时 Primary Key 是不能变更的。这里 Kudu 的 Schema Change 系统感觉还是比较简陋的,感觉类型提升什么的支持都不是很好,nested 也不太支持,令人唏嘘。不过,同其他列存系统一样,Kudu 对列也会做一些 encoding,来提升对应的压缩率。
对于写来说,Kudu 前台可以用对 pk 的 Insert, Delete, Update 几种 API。论文成文的时候,系统尚未支持分布式事务,只能在单个 Tablet 内执行事务(可以支持单行事务)。目前 Kudu 已经支持分布式事务,不过支持的好不好另说。
Kudu 有一个 HLC 时间戳系统,参考了文章:
它的写有两种模式:
CLIENT_PROPAGATEDConsistency: 没啥同步,client 生成时间戳做事务COMMIT_WAIT: 会做同步,它声称自己做到了外部一致性。这是一个实验性功能,不鼓励在生产环境打开,同时,多 tablets 事务目前只支持 rc,然后单个 tablet 只支持一个事务。
而读也有不同的模式:
READ_LATESTREAT_AT_SNAPSHOTREAD_YOUR_WRITES
kudu 在读的时候支持 Scan / Projection / Filter。
Kudu 可以用 HLC 生成内部的时间,但也允许用户自己写时间然后给一个时间查询。
Architecture
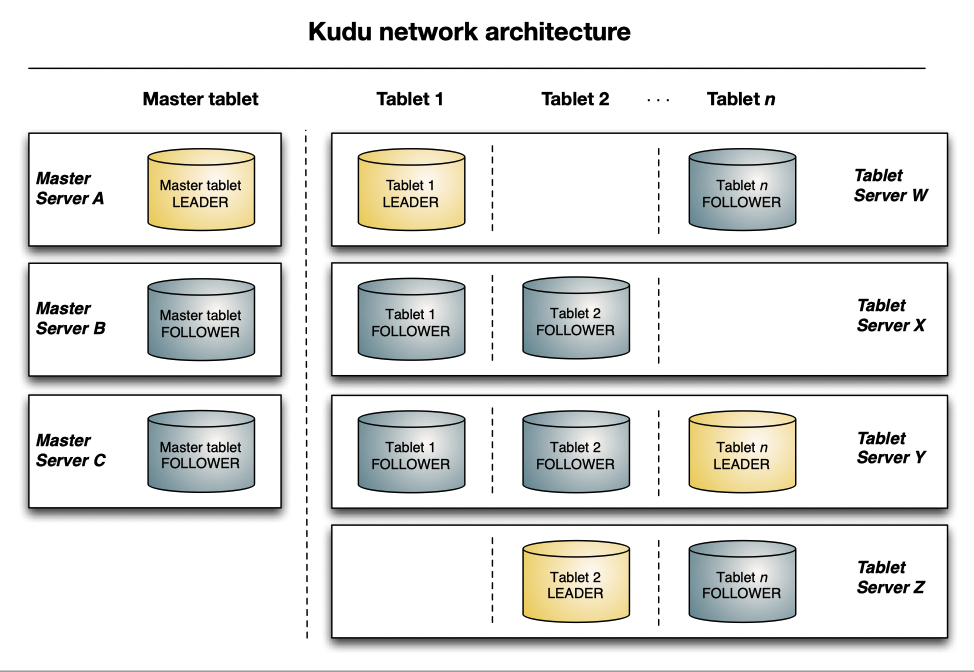
其实上面的架构有点类似 HBase,不同的是,这里还是走了 Raft 而不是 ZK 来管理集群。见:https://github.com/apache/kudu/tree/master/src/kudu/consensus 。走 Raft 管理感觉性能容易拉,但是相对来说能写的比较简单,而且依赖也少了。
当然,如果需要把 Kudu 暴露给 Impala 或者给外部查询,可能这里会需要 Hive Metastore 来暴露这些数据。
Master 节点运行的也是 tablet。和存储数据的节点跑着同一套代码,但建议还是跑在更好的服务器上。
对于 Tablet 服务器,之前有一些配置上的建议:
- 为了获得对大事实表的最优扫描性能,建议保持一个tablet对应一个CPU核的比例。不要将被复制的表计算在内,应该只考虑Leader tablet的数量。对于小维度的表,可以只分配几个tablet
- 建议每个 tablet 最多包含 2000个 tablets,论文中推荐每台机器 10-100 个 tablets,我估摸着可以按照 CPU 和 Disk 数量拍
需要注意的是,Kudu 的 WAL 是 Tablet 级别的(作为对比,写在 HDFS 上的 HBase 最初是一条 WAL 流,然后被小米扩展到多条)。相对而言,Kudu Tablet 间恢复可能比较独立,但是估计 IO 的 admission control 会相对复杂一些。
Partition
Kudu 的 Partition 属于 「没啥意思但是很实用」的类型,它首先会按照 Primary key 来分 partition 到不同 tablets 上。它提供了一种 hash - range 混合的 Partition 策略:
- Range partition
- hash partition
- multilevel partition
本质上,其实 Kudu 抽象比较简单,用户可以想象成:
- 走一到几组不同的 hash
- 然后对 hash 后的 binary 进行 range 分片
1 | 用户指定一个 fn, 把 pk 列 (pk1, pk2, ...) 映射到一个 binary |
Range Partition
对于 range partition,例子如下:
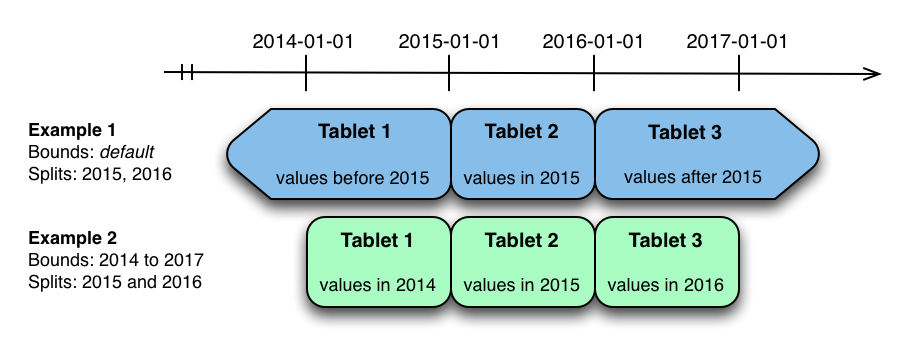
使用的时候,也可以参考 sample: https://docs.cloudera.com/cdp-private-cloud-base/7.1.6/impala-reference/topics/impala-kudu-partitioning.html#pnavId2
Kudu 也允许动态插入 Range Partition。
Hash Partition
Hash Partition 会把行分配到 bucket 中,如下图:
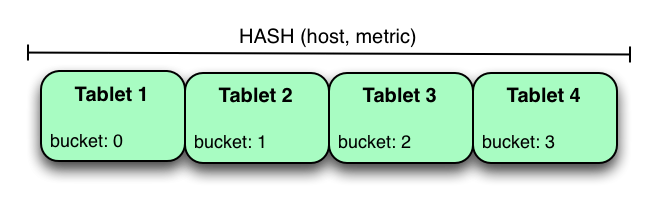
这里可以指定 PARTITION BY HASH(...) PARTITIONS 50 这样。
Multi

这里,可以按照手动指定 range + hash 或者 hash + hash 做分片:
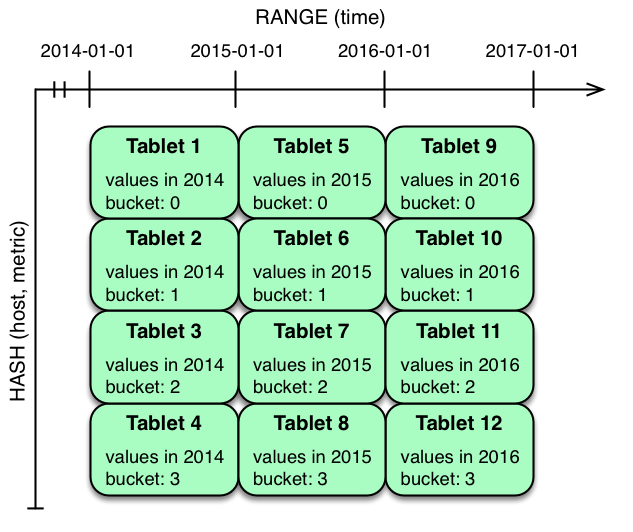
直观的感受还是,Tablet / Partition / Bucket 还是定的比较死的,在网易的博客里讨论过,当数据很少的时候,Kudu 也会按照给定的 Bucket 数量去分区。网易在他们的博客里提到了这个问题。注意,虽然不同 Partition 的 bucket-id 是相同的,但是它们存储在不同的 Tablet 上。
Hash Parition 方式类似静态分片,从代码可以看到:
- https://github.com/apache/kudu/blob/77d3ea465bb1a1fa778cccd8432553032f51bd27/src/kudu/common/partition.cc#L1361-L1384
- https://github.com/apache/kudu/blob/77d3ea465bb1a1fa778cccd8432553032f51bd27/src/kudu/common/partition.h#L136
这里针对 hash 设置了 range,然后对提前切分好的 hash range 来分片
Kudu 的 Parition 可以引入一些 Pruning: https://github.com/apache/kudu/blob/master/docs/design-docs/scan-optimization-partition-pruning.md . 这个 Pruning 类似不把 Task 发给被裁剪的 bucket。
Partition 还有一些小问题,对于 Kudu 的热点写,如果写的是某一个 Partition,那么 WAL 能比较好的处理。有一种 backfill 的场景,即 scan 数据回填,这种场景因为低缓存命中率,所以性能会比较差。
Replication
Kudu 走的是 shared-nothing + Raft 的模式,其实我不理解为啥走 Raft… Kudu Raft 实现应该比较简单,它的 WAL 走的是 Raft,各台机器的状态机允许不一致。
虽然表面说走了 Raft,但是 Kudu 实际上类似 ZooKeeper 的 A-linearizable,写的时候走 Raft,读的时候可以本地读。不知道它这个和事务怎么协同设计的(直观感受就是看这玩意不如花时间去折腾 MongoDB,因为它这几方面的设计都非常草台,让我们不要折磨自己,跳过它们吧)。
相对来说,Kudu 的 Compaction 是个本地的程序,不涉及全局的 Raft。似乎这个是各个机器自己处理的:
Kudu does not replicate the on-disk storage of a tablet, but rather just its operation log. The physical storage of each replica of a tablet is fully decoupled.
比较傻逼的是,在它的文档里,对 config change,它还是靠单步变更实现的…额我只能说他开心就行:https://github.com/apache/kudu/blob/master/docs/design-docs/raft-config-change.md
Kudu Master
之前说到了,Kudu 的 Tablet 由 Raft 来同步 WAL,因为 Raft 的存在,所以其实 Tablet 的分配是比较靠谱的,集群能够从这里面建立出信息,同时相对 HBase 来说,少了处理 RIT 的麻烦。
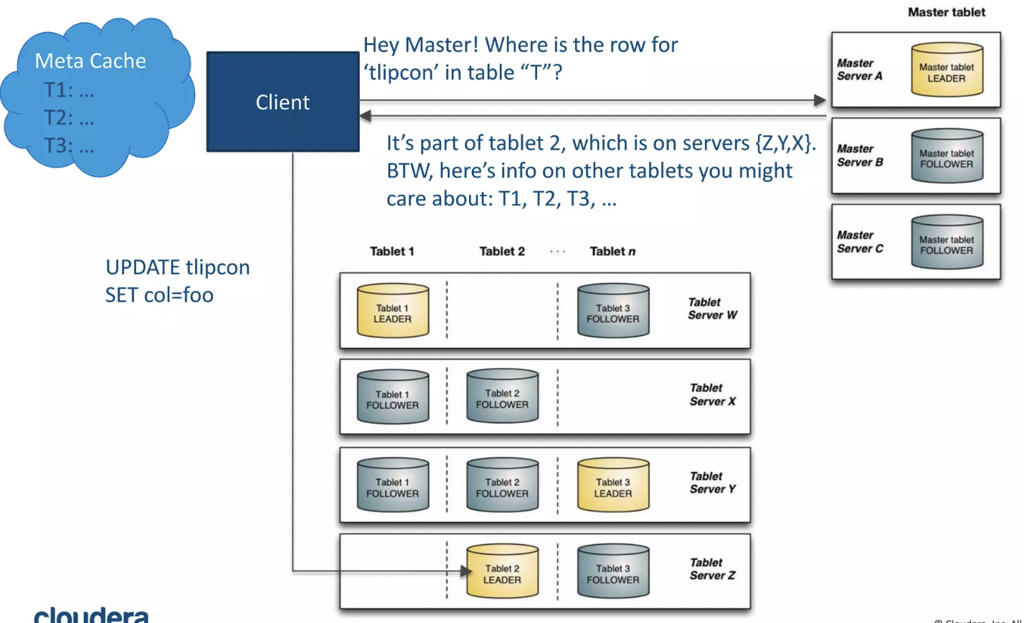
这里 master 可以:
- 作为 tablet directory
- 存储元数据,作为一个 meta service,并处理 DDL 等操作
- 在创建表的时候,这里会异步的 pick TabletServer 去 Assign Tablet
- 在删除表和 DDL 的时候,这里会需要让子节点状态完成
- 类似 HBase,这里的状态推进是幂等的
- 监控 tablet server,适当的调度 tablets
在实现的时候,它类似 GFS Master,把目录信息全部缓存在内存中。然后不同于 Tablet,读在这里不可以走 Replica 去做不一致的读。
上面说到的部分我们可以进行稍微细致一些的描述,Kudu 的 Master 会维护成 sys.catalog 表。写、读严格遵照 Raft 的 syntax。这里维护了下列的信息:
- [Table Id] -> TableInfo
- [Table Name] -> TableInfo
- [Tablet Id] -> TabletInfo
而 TableInfo 则包含了 [tablet-start-key] -> TabletInfo 的有序 key-range mapping。
创建和删除表都被视作原子的多个 step,创建包含 preparing, running 等多个状态,这里会先推进 preparing,再推荐 writing,然后返回给用户,然后这里不会创建 tablets。直到 Table Assignment 阶段才会删除
对于删表,情况也差不多,这里会对表标记 “deleted”,然后对表发送的请求将失败。但是 Tablet 会走 DeleteTablet 请求异步的进行删除。
在 Table Assignment 阶段,这里会挑选机器,然后发送 CreateTablet 请求,并带有一个超时。CatalogManagerBgTasks 会监听信息,如果返回了对应的心跳,那么 Tablet 创建成功,否则需要挑选另一个 Tablet Server 了。
CatalogManagerBgTasks 是一个很重要的线程,它会维护心跳,然后根据心跳来:
- 把很久没发心跳的 tablet 切成 replaced 状态
- 给每创建的 tablet 挑选状态,启动 leader,然后启动它们
- 移动删掉了的 tablets
Tablet 的故障恢复依赖 Raft,除此之外,这里还有个类似 DNS 的服务,当拉起新的 master 的时候,需要让 leader 指向同一个 DNS CNAME。
Master 还负责当 Tablet Directory,client 的缓存有可能是旧的,这里没讲述有没有 epoch 来维护这些信息。只是说,发到的不是 tablet master 的话,会重新访问 Master。
Tablet Storage
tablet storage 是 Kudu 最重要的一部分,因为…这是有自己东西的一部分,你看前面的内容不是烂大街的吗(笑)(当然要做好也要一番功夫)。Tablet Storage 是 Kudu 比较独特的一部分,它可以被视为一个单机的引擎,因为感觉除了 WAL,不是很 Care 分布式的那堆逻辑。
看 Tablet Storage 的时候,需要注意这个模型还是有限制的,Primary Key 在其中占有非常重要的地位
Tablet Storage 是每个 Table 下的每个 Tablet 一份的。主要支持:
- Fast Columnar Scans: 这里实现了 CFile,自己的列存格式,然后引入了 bitshuffle 等 encoding 方式来做编码
- Random Updates: 对 primary key 能够快速更新,random access 希望有 $O(lg n)$ 的 complexity
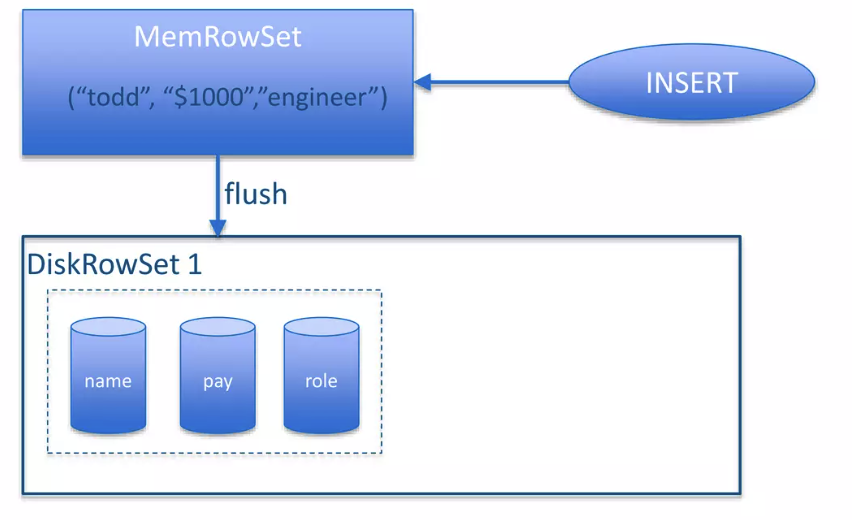
类似 LSM Tree,Kudu 组织了 RowSets:
- MemRowSets: 在内存里的 RowSets
- DiskRowSets: 盘上的 RowSets
MemRowSets 采用了一个 MVCC 的 B-tree 实现,参考了 MassTree,具体实现于:https://github.com/apache/kudu/blob/master/src/kudu/tablet/concurrent_btree.h
其实这个实现有点类似 SkipList,基本上也是 append 作为写。然后需要注意的是,这里利用了 SIMD 和 JIT 加速(或许类似 ART ),然后 MemRowSets 是一个行存。
NOTE: other systems such as C-Store call the MemRowSet the “write optimized store” (WOS), and the on-disk files the “read-optimized store” (ROS).
DiskRowSet
CFile
DiskRowSets 由 CFile 组成,准确的说,在一个 DiskRowSet 内,每列都会有一个 CFile。CFile 是一个逻辑文件,Kudu 引入了一个 BlockManager 层,可能会把多个 CFile 映射到同一个物理文件上。
它由不同的部分组成,包括:
- Header
- Footer
- 不同种类的 Block: 类似 data blocks, nullable data blocks, index blocks, dictionary blocks
压缩和 encoding 以 Block (类似 Parquet 的 Page) 为粒度进行。每个 Block 可以选择自己的 encoding 方式。此外,这里还有对应的 Index:
这里用类似 Position Delta Tree 的方式组织 Index,有下面两种对应的 Index:
- Positional Index: 类似 PDT 或者 Parquet 中某列的 Offset Index
- 如果对应的数据有 sorted order,那会有这些数据的稀疏索引
数据会写到 「Leaf Block」上,Kudu 会维护逻辑的 Internal Block,然后最后按 Post-Order 写入:
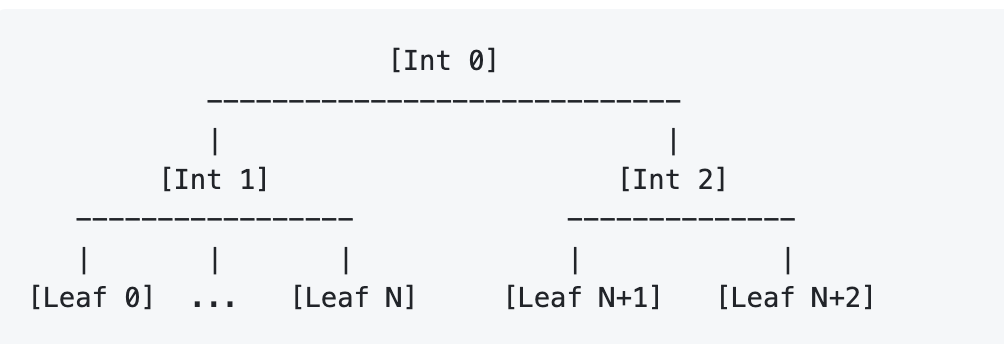
例如下面就会写 [Int 2] [Int 1] [Int 0]
我从网上抄了个好心人画的图(Ref 5):
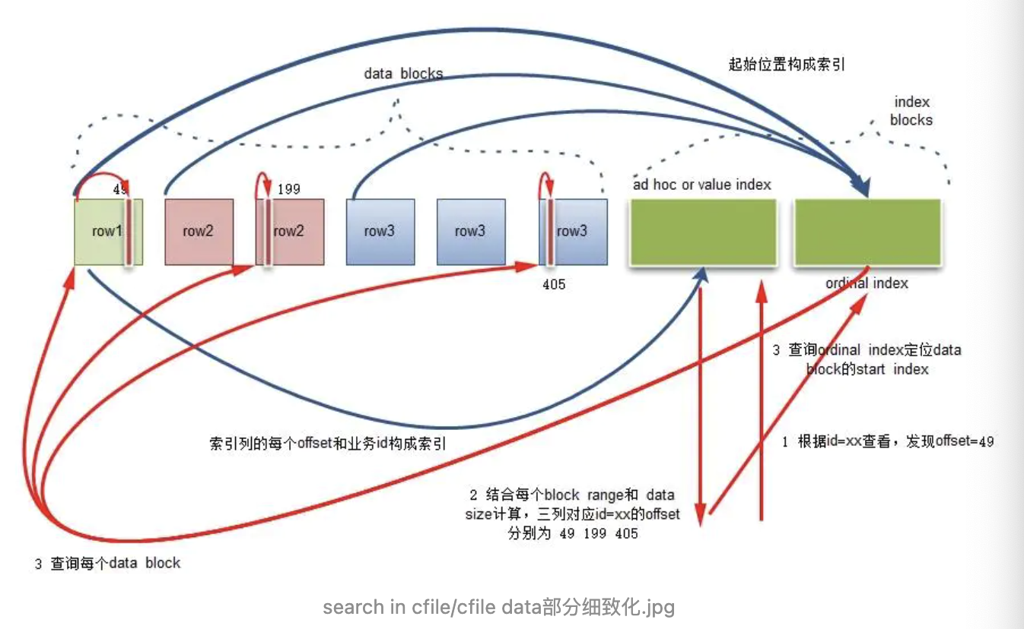
其实和 Parquet 差不多,不过 Parquet 估摸着没 Btr,得线性或者二分
BloomFile
BloomFile 是独立的 CFile 文件,额外存了一份,作为需要的列的 BloomFilter。有了 BF,那么上面那图操作进行之前,还要查一下对应的 BF 了。
BF 会被处理到 4KB 的 Page 中,然后快速查询。
DeltaRowSet
DiskRowSet 由 MemRowSet flush 而来,类似 RocksDB,我们也能知道对应的 min-max 值,用以支持后续的 compaction。
作为 Primary Key 模型,不同于 RocksDB / LevelDB,虽然 DiskRowSet 可以跨范围,但是单个 Primary Key 只可能出现在一个文件中:
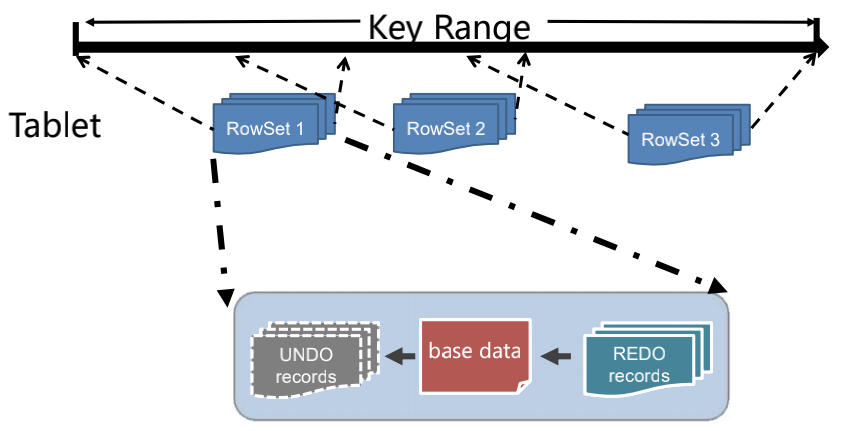
Kudu 区分了几种更新操作:
- Update
- Delete
- REINSERT
Update 和 Delete 没有落在 MemRowSet,这点需要注意。然后 REINSERT 是和 Delete 对应的,如果有删除数据后来又重新插回去了,会纪录一条 REINSERT。这里保证了 BloomFilter 查到的东西相对靠谱,归属同一个 DiskRowSet。
这里更新记录 也是从 Mem 来的,如下:
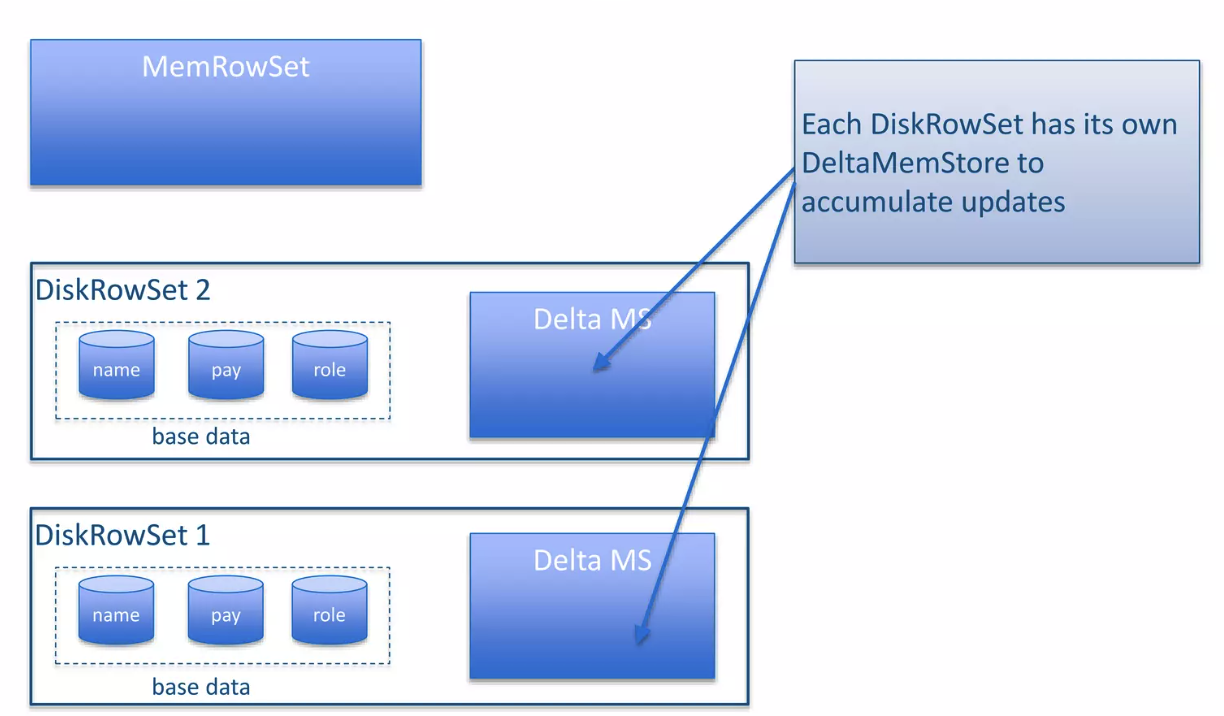
Delta MS 是内存的部分,这里会按照 (row_id, timestamp, RowChangeList) 维护:
- RowId 很特殊,类似 PDT 中的概念,是文件中对应的行号。注意,某一行被删除,这个 RowId 仍然留着
- timestamp 很好懂
- RowChangeList 是对这一行各个列操作的物理日志
Mem 的变更也是存放在同样的 btree 中,同时,这里可以根据 index 来找到对应的行号。这里可以 Flush 成对应格式的 Redo 文件,如下图:
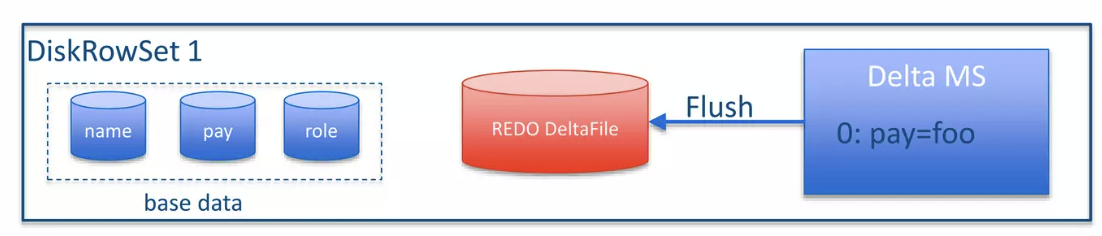

Compaction
Compaction 的时候,可能会有多个 RowSet 做 Compaction,也可以是单个文件做 Compaction。这里需要注意的是,为了满足 MVCC,Base + Redo 文件可能会变成 Base + Undo 文件
Redo 记录我们之前应该介绍过,下面简单讲讲 Undo:

不同于 ARIES,一般 Kudu 会生成单向的 Redo 记录,然后当 Compaction 发生的时候,RDBMS,如 PG,可能会存一堆 Redo,然后找到一个最近版本恢复。在 Kudu 中,文件生命周期大概是:
- Redo -> Base / Undo -> 被合并或者回收
这样避免了维护每个旧版本的文件视图和对它们的 ref(作为对比,RocksDB 的 VersionSet)
Compaction
Compaction 可以被分为 Major 和 Minor 的
Delta Compaction
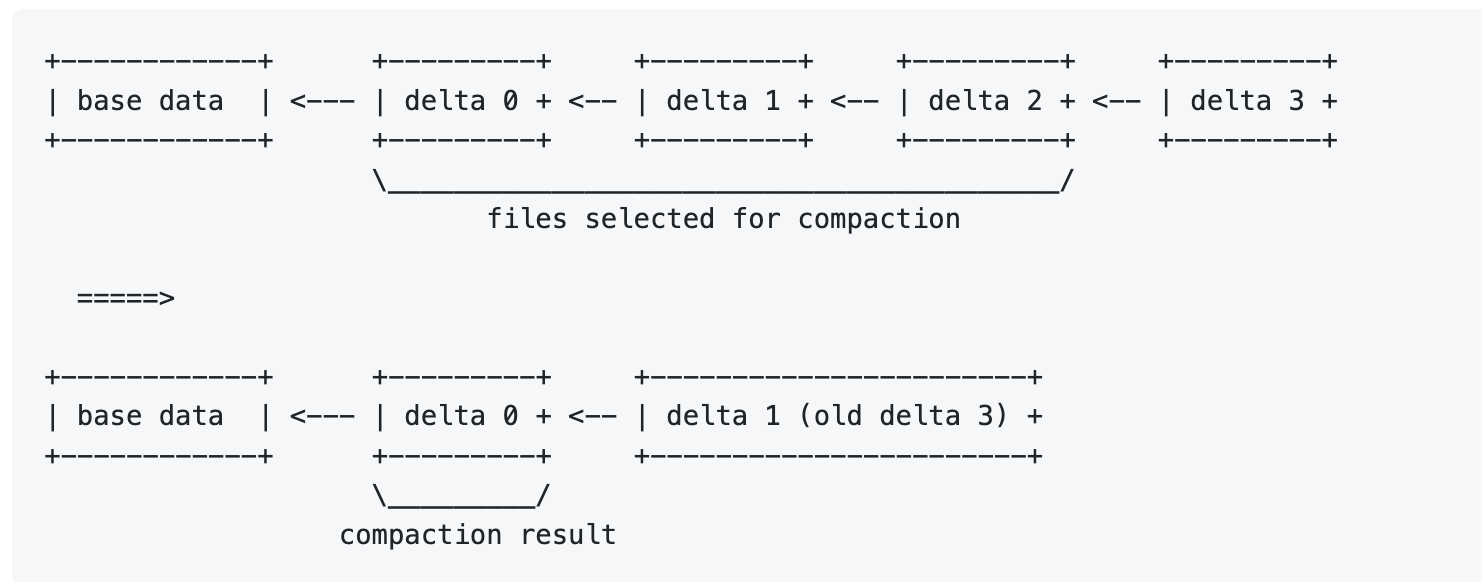
Minor REDO delta compaction: 合并 delta redo 成一个 redo,量级很轻,减小对应对 Delta 的 IO。实现逻辑就是原封不动的合并多个 Delta,应该能通过 IO 来提升压缩率,减少多文件 IO 和 fds
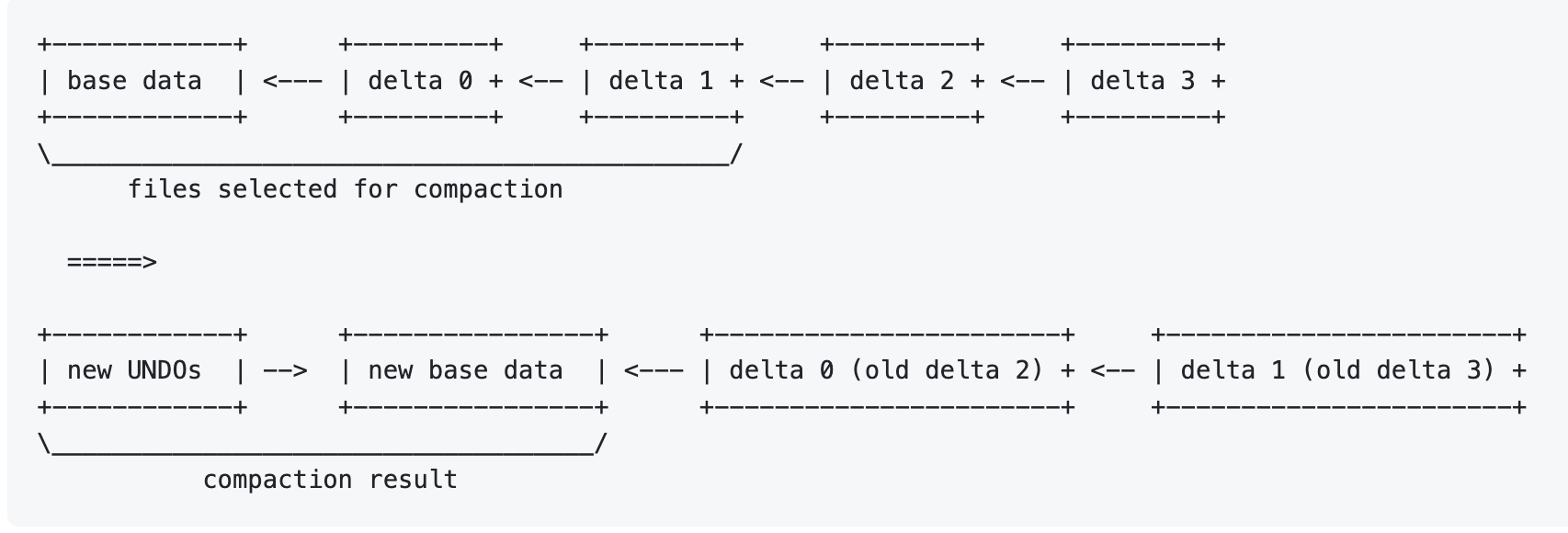
Major Redo Delta Compaction 如上图,这个地方要重写 base 文件,然后把原本的 redo 变成 undo。同时,这个地方也不会改变 row id。这里有一个特殊的地方,就是可以单独处理频繁更新的列,剩下的仍然在 redo delta 中。
需要注意的是,compaction 完成之后,即可以移除之前的文件。
Range Compactions
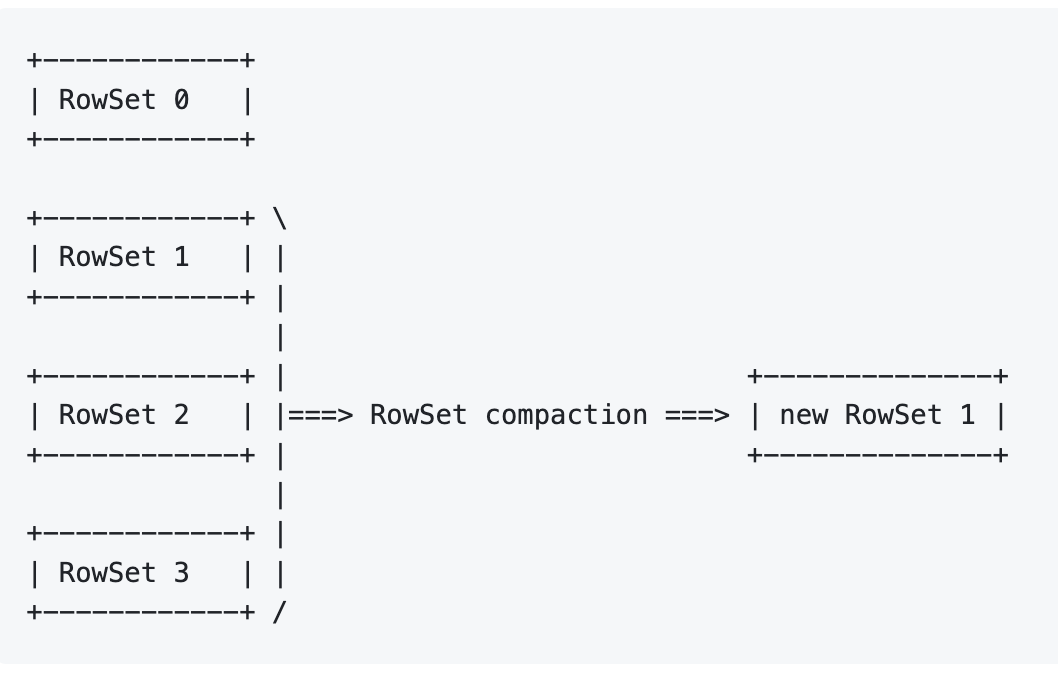
这个有点类似 RocksDB 的 Compaction,但它的操作其实相当重,我们可以讨论一下对应的问题:row_id 会改变,假设:
- 某个模型跑的好好的,需要 Compaction 了
- Compaction 进行的时候,写入还在不断进来
- Compaction 完成了,RowSet 的写基于了之前的 row_id
- 寄!
Kudu 采用了如下的实现策略:
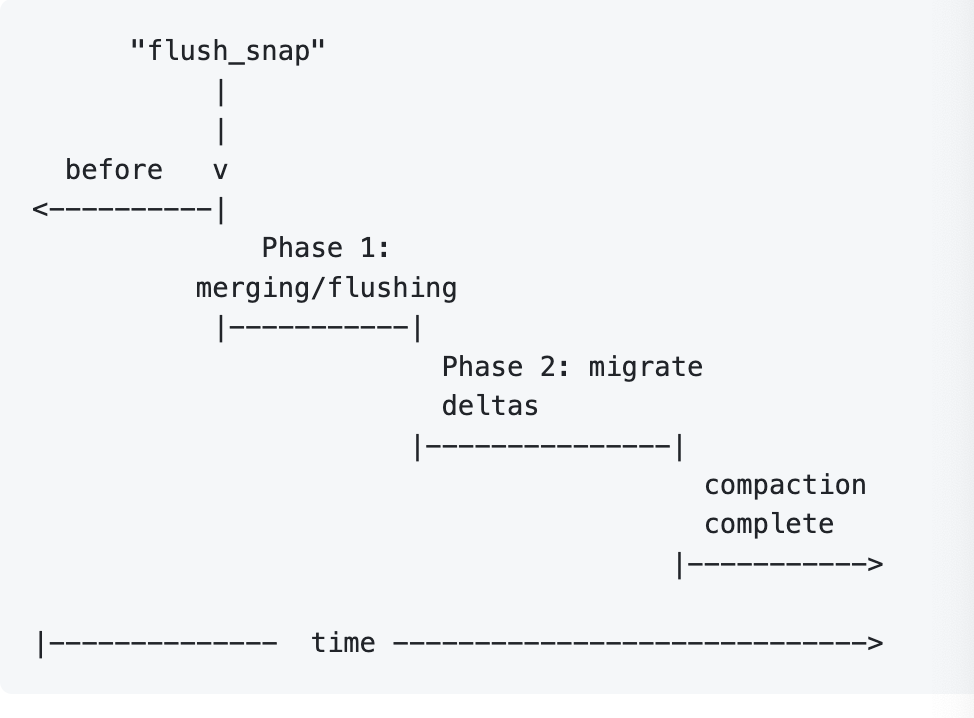
这里,它加入了一个双写的 RowSet,然后Compaction 的时候,对应的变更会即写旧的又尝试写入新的,相当于把旧的写在新的 row_id 重放一遍。
机制
在 Kudu 中,Compaction 被建模为一个最优化模型,这里会根据 width 和 depth 来进行压缩:

如上图,这里会挑选合适的范围,然后去 compaction
具体的讨论见:https://github.com/apache/kudu/blob/master/docs/design-docs/compaction-policy.md
References
- Kudu paper
- Index Skip Scan Optimization: https://kudu.apache.org/2018/09/26/index-skip-scan-optimization-in-kudu.html
- Apache Kudu 在网易的实践 https://www.infoq.cn/article/kgwyqb5wer5wl8cquweq
- https://www.slideshare.net/cloudera/apache-kudu-technical-deep-dive
- Kudu CFile 解读:https://www.jianshu.com/p/789c286e7077