Parquet Part1: Basic
Parquet 是一个由 Google Dremel 格式启发而来的列存格式,在大数据领域通常作为存储格式,被 iceberg 等湖、各种查询引擎能够合理的使用。Parquet 的格式定义在https://github.com/apache/parquet-format ,由于大数据事实标准语言是 Java,所以其 Java 实现( https://github.com/apache/parquet-mr ) 较为完善。C++ 实现目前在 arrow 的仓库下:https://github.com/apache/arrow/tree/master/cpp/src/parquet 。它的功能实现的不是很完善,具体可以见: https://arrow.apache.org/docs/cpp/parquet.html
Parquet 在最早被描述为 HDFS 上的格式,所以有 HDFS Block/File 相关的概念。
此外,有一些地方会专门在自己仓库里实现了一些 parquet 特性,在 2011 年这格式被提出来的时候,相关处理逻辑还是比较复杂的,可能有的人自己实现了一套,又和自己的数据结构很紧密,比如 Impala 实现了一套 parquet 有关的逻辑。这里我将会介绍一下 parquet 和官方的代码,带大家走进黑暗的格式
Format
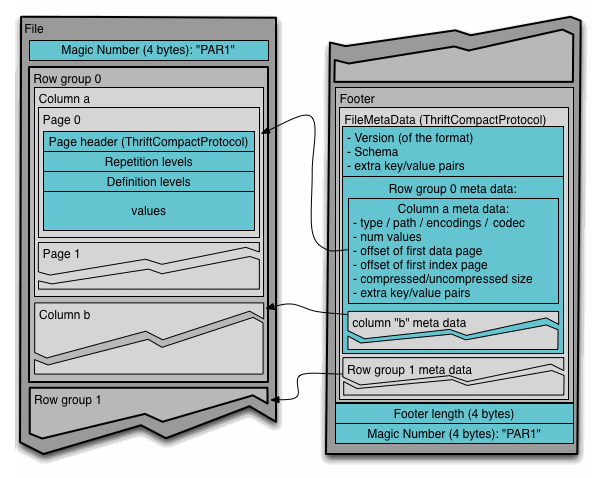
Footer 部分
这图大概如上所示,然后官方介绍的很好:
- 读这个,首先要找到 tailer,发现满足对应的 magic number 和 footer length。反过来说,metadata 只在 结尾,允许整个文件只写一次,
Footer有文件的元信息,用 ThriftCompactProtocol 描述,这里相对 thrift 原本 binary,可能会有一些 varint zigzag 什么的- version 应该是 Parquet 内部的信息,在 thrift 里面标明了格式的版本,这里有个有趣的 issue,逻辑问题来自于 file 低版本的时候,Page 可能没带版本。
- Schema 代表 RowGroup 的 schema,所有 RowGroup 都需要是这个 Schema。schema 感觉其实可能不小,有 name / type (在递归定义中的 path) 等,还有一些子节点相关的信息。这里还有一个很重要的信息 field id, 这是上层传下来的,唯一的字段的 id,上层可以用这个字段来做一些 schema evolution 相关的逻辑
- Schema 类型只是 Parquet 的类型,其中外部的 SQL / 用户类型实际上和 Parquet 内部这些类型不一定能对上,类型需要额外做一层映射 / Hack,可能会借助额外的 Attributes。
- Extra key/value pairs 可以塞一些信息,在 arrow 的 compute 模块里,用它来塞了一些和计算有关的逻辑。这块我觉得有点矛盾,因为一个读者必须拿到 writer、收集一些信息或者什么的,才会好放进去,我看一般的库基本没有暴露这个接口出去的,感觉基本上是给一些能改得动 parquet 的人开洞用的。
- 剩下会给出每个 RowGroup 的元信息,里面包括每个 Column 的元信息。这里的单位是 RowGroup,没有 Page 粒度的信息。它相当于在 parquet.thrift 里面的
RowGroup里面给了定义。每个 RowGroup 有所有 Columns 的定义,这里会有- 指向数据块头的
file_offset,数据页头也是个 thrift 结构,这里可能会 duplicate 一份(结构上有一个optional ColumnMetaData,在标准上允许你写或者不写,估摸着看实现),这个结构叫做ColumnMetaData。我们之后介绍数据页的时候,会介绍这里。- 注意
ColumnMetaData上有一个num_values,这里代表的是「包括 nulls,这个ColumnChunk对应值的数量」而非「这个ColumnChunk对应行的数量」。这个地方我说的可能有一点难理解,比如对于optional i32的平坦数据,这里等价于行数,而对于repeated <optional i32>,这里代表内层的数量。PageHeader的num_values也同理。 - 总文件的
FileMetaData、RowGroup 的元数据、DataPageV2 会有num_rows,表示对应行的数量。在有嵌套的情况下,这个不等于num_values.
- 注意
- 会有一些 PageIndex 相关的偏移量,这里可能指向 OffsetIndex 和 ColumnIndex. 注意,这里指向的是 RowGroup 的 Index。
- 会有字典页相关的记录,如果采用了字典编码,ColumnChunk 的第一个页面会是字典页
- 记录了总行数,未压缩的大小(未经过压缩,但已经 Encoding),压缩后的大小,RowGroup 对应的位置(即这个 rg 之前的总行数)
- 有一个特殊的
SortingColumns,标识这个 RowGroup 按照什么排序。这里类似数据库的SortingColumn,会有一些nulls_first的处理什么的。这里还有一些和类型相关的排序要求ColumnOrder,会把类型编码到对应的逻辑中。注意,sorting 是 RowGroup 级别的 sorting,格式应该没有强制整个文件用一样的 sorting (我觉得这里很鸡贼,schema 用的是同一份,但是 sorting 却并不是…)。
- 指向数据块头的
给出一张总图:
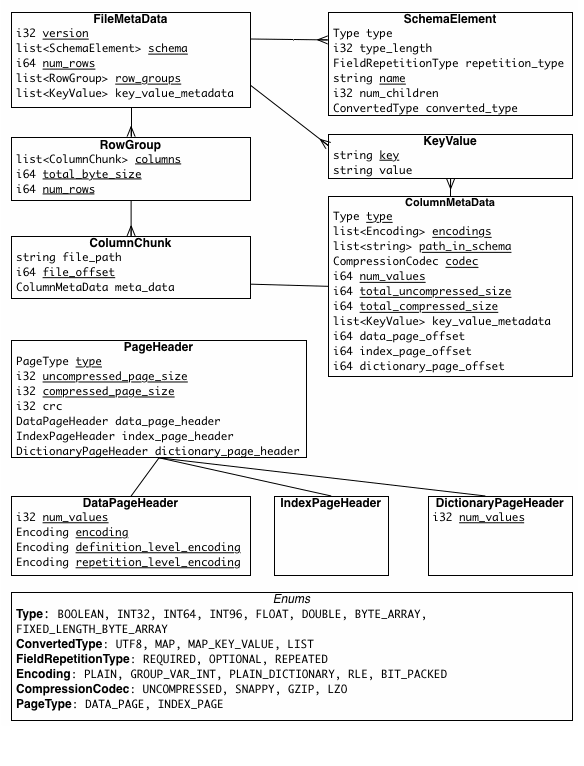
数据部分
元信息中,ColumnChunk 会包含对应的 file_path 和 file_offset,这点 允许数据分布在别的文件. 数据文件的分布大概是:
- RowGroup 包含一个或者多个 ColumnChunk
- ColumnChunk 包含一个或者多个 Page,也包含了各种元信息
注意,ColumnChunk 的元信息(ColumnMetaData)也存放在 ColumnChunk 的尾部,在 IO 完成后写入。
类型系统和逻辑类型
基础类型
Parquet 只支持一组很小的基础类型,叫做 Type,我们需要把它和后文的 LogicalType 区分开来:
1 | /** |
这里物理为啥最低支持 INT32? 因为作者似乎认为 i16 i8 能比较好被压缩。(2023.2.2: 目前似乎在讨论在 spec 里面加入窄浮点数)。
这个字段配合一个 LogicalType,共同组成了需要的类型:
1 | /** |
这里它有个 ConvertedType,基本上是兼容旧屎山了,属于旧代码。有一些特殊类型需要注意一下:
- Decimal/Time 可能根据精度/代表的东西不同,物理的表示是不一样的
- 对于 struct,外头相当于只会把叶子结点编码,但是还是有一些复杂类型的,比如 LIST 和 MAP:
- List 相当于 2个元素,
LIST<int>里面,外面的 List 是一组标记,里面 int 又是一组标记 - Map 则相当于三个,
Map<K, V>里面,MapKV都是标记
- List 相当于 2个元素,
有一点需要注意的是,只有 Leaf 节点拥有 Type,它不可能是 Map, List, Struct. 中间的节点可能会是:
- List, Map, Struct 之类的嵌套类型
- 别的对应的逻辑类型
嵌套结构定义其实还挺啰嗦的,这段代码看着还是很恶心的,但是很清晰,可以试看下图:
List (最外层的 optional 是 List 是否 optional, 里面的是 List member 是否 optional) :
1 | <list-repetition> group <name> (LIST) { |
上述是理想场景的 List,下列是读取的时候会遇到的一些奇怪的东西的兼容性:https://github.com/apache/parquet-format/blob/master/LogicalTypes.md#backward-compatibility-rules
Map 的 Key 则需要一个字段,而且必须要 non-null:
1 | <map-repetition> group <name> (MAP) { |
To be honest, 我总觉得存 Map 的话,做不到二分,不过 arrow 的 Map 应该也是这么草台的?
这里也要考虑兼容性:https://github.com/apache/parquet-format/blob/master/LogicalTypes.md#backward-compatibility-rules-1
Sort Order & Statistics
- 这个地方我不确定自己完全看懂了,因为 Sort Order 在 C++ 实现的时候很 Shit,必须要有 SortOrder 和 Comparable 的信息才能够生成对应的
- 至少在今天(2023.2.2),parquet-format 页面上的描述不是很清晰。但是 parquet.thrift 的定义是十分清晰的
我直接介绍一下 Parquet-format 的定义,避免说车轱辘话:
- LogicalType Order: 由 LogicalType 定义的 Order,这套东西最好做到标准上,不然应该不太合法
- 目前标准上给每个 LogicalType 都有 Order 相关的定义,如果是用户映射的类型,可能要注意相关的定义
- Type:按照 Type 的定义来行为。其中 INT 强制有符号比较,bytes 类的类型强制 byte 比较
- 比较 Trickey 的是浮点数类型,这里 Spec 应该写了如何处理,比较 Trickey: https://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift#L888
在 C++ 版本代码中,如果不可比较,就不会生成任何 Statistics。这个显然是有问题的。
Statistics 在 Parquet 中「永远」 是 optional 的,下面我把兼容性字段裁剪掉了贴一下 Statistics:
1 | /** |
max_value 和 min_value 都是类型自定义的,按照对应的内容解析。
SchemaElement
SchemaElement 是 Parquet Schema 的最重要部分之一,没 Statistics 你还能活,没 SchemaElement 就笑嘻了。理解 SchemaElement 也能帮助理解 Nested Type 的处理:
1 | /** |
上面的结构中我去掉了兼容性有关的字段,和类型 Specific 的字段。可以从 Type 和 LogicalType 的存在性来理解。这个结构会以 depth-first 的形式出现在 FileMetaData 的 Schema 中:
1 | /** |
可以感受一下 Leaf Schema 和 non-leaf 的区别。
Data & Page
DataPage 和 Dictionary Page 是系统的重要部分,承载数据。RowGroup 中,每一列会有一个或多个 Page 存在。Page 会有一个 PageHeader,里面可能包含 DataPageHeader 或者 DictionaryPageHeader 或者 DataPageHeaderV2,而 RowGroup 没有 Header,RowGroup 靠偏移量指向每列的第一个 Page。关于 Page 的其他信息,则可以在 PageIndex 中找到,后文再提这些信息。
PageHeader 会有一些 size 之类的元信息,不过本身 RowGroup 的 Metadata 也有一份这些信息。
数据可能会有编码之类的,Encoding 和 Compression 都以 Page 为粒度,在 Page 解析的时候会读到对应的标记。为什么呢?因为压缩的时候,这里会有一定的 fallback 策略,row group 不一定有同一个策略。
里面 repetition level 和 definition level 会紧随在 Page Header 后,这里也会标识他们的长度,这两列会以 RLE 形式被压缩。之后就是 values 的具体编码了。当然,这两个不一定会写入:
- 如果没有 nested 定义的话,是不需要 repetition level 的
- 如果路径上没有 nullable 的字段的话,是不需要 definition level 的
具体读取和写入的时候,会按照 ColumnChunk 为单位写入。具体而言,Page 就是某列 Column Chunk 内一批数据而已。
依照 ColumnChunk 为单位写入是一个很蛋疼的事情,arrow 的 parquet 实现中,提供了 buffer 和非 buffer 的 io,如果用户是先写完第一个 Column,再写第二个 Column,那么就可以:
- 写完第一个 Column 所有内容,写完多个 Page,进行 io,写到文件。当然也可以一个个 Page 写进去。
- 第二个 Column 开始同一个步骤…
所以如果按行或者 vectorized data 写的话,io 其实不太可能完全按照第一个 Column —> 第二个 Column 这样写,所以实际上可能是:
- RowGroup 所有的写都 buffer 在内存里
- 监测到要切 row group,然后一起 buffer 写了
这里还会有 Statistics,包括 Page 包含多少行数据、里面对应 min-max 为何。这部分其实有一部分和 Page Index 功能是重叠的。
V1 vs V2
DataPage 有两个版本 V1 和 V2,目前,大部分地方没有广泛使用 DataPageV2。
这两个格式主要区别是 rep-level 和 def-level 的处理,V1 中,两个 level 会和数据一起被压缩;V2 中,两个 level 并未被压缩。此外还有些比较微小的区别,具体可以看 thrift 的定义了。
在内存中,DataPage 内存存储方式都是:
1 | (optional 的 16位数组) rep-levels |
levels 的长度由 Header 来标识。
切分 Data & Page
官方可以根据 Row Group Size (推荐 512M - 1GB) 和 Page Size(推荐 8kB)来切分。值得一提的是,感觉这个格式基本没做 Random Access 优化,读取都是 Page 为单位的。
CRC32
Page 会对「上面的数据」做 crc,Page 本身不会做 CRC。
另外,我翻了一下绝大多数实现,截至 2022.10.19,parquet-mr 只有 DataPageV1 和 Dictionary Page 会写 CRC,C++/Rust 版本基本都没写 crc。考虑到之前很多地方落在 S3 / HDFS 上,其实可以理解,但引入了本地 SSD 缓存之后,恐怕没有 CRC 真的就死路一条了,笔者正在给 C++ 标准的 Parquet 实现 crc。
Encoding
Parquet 官方规定的 encoding 数量不多,而且实现看上去有点大病。比如字典的实现是:
- 先死命往字典里放
- 字典空间过大了就 fallback 到 PLAIN
- 这个地方 fallback 到 PLAIN 这个说法比较让人困惑,因为每个 ColumnChunk (RowGroup 内的单个 Column) 是只有一个字典页的,这里编码的时候,会不断往字典里面添加内容,然后之前的页面会缓存下来。如果发现过大,这里会写完之前的字典 + 数据页面
看上去就很傻逼。
不过,有的地方字典会规定是有序的,Parquet 并没有规定字典本身是有序的,但在字典页面上提供了
编码的格式见:https://github.com/apache/parquet-format/blob/master/Encodings.md
PLAIN 格式:啥都没有,直接写数据
- 关于变长的字段,这里会有 BYTE_ARRAY: 写4B -> 写数据
- 字典会有
PLAIN_DICTIONARY和RLE_DICTIONARY。字典压缩本身会压完一列,然后在数据页之前会有字典页,字典页推荐用 PLAIN 格式。- 同一个 ColumnChunk 共用一个字典,但是可能里面有的页面不用字典编码。
- RLE: parquet 推荐的是 RLE + Bit-packing 混合模式,这个地方是「走 RLE 或者走 bit-packing」,这段在 RFC 里面介绍非常鬼畜,建议找代码注释读。
- DELTA: 先走 delta,再走 bit-packing,数据在 bit-packing 层会被压到一堆 miniblocks 里面
- Delta-length byte array: Delta 编码以下所有字符的长度,再把内容拼贴
- Delta Strings: 前缀压缩
关于编码的选择,parquet 没有做任何实现和规定,建议运行的时候 xjb 选吧。Encoding 的格式会标注在 Page 的里面,因为可能同一个 ColumnChunk 的不同 Page 编码方式不一样。
Page Index

我们注意到,Metadata 只有 rowgroup 层面的信息,Page 层面的位置和大小,都需要走 PageIndex。这个可以做一些细粒度的裁剪。 Metadata 的 Column 中,会有地方指向这几段。
PageIndex 希望让点查、Range Scan on sorting columns、Selection 能够以跳过不需要扫描 Page 的方式节省 IO / 计算的资源,同时 full scan 不用扫描这部分数据,让这部分尽量没有开销
PageIndex 描述在 FileMetaData 之前,也就是接近文件尾部的地方。
PageIndex 是以文件中整个 Column 为粒度的数据,PageIndex 包含两个部分:ColumnIndex 和 OffsetIndex:
- ColumnIndex 会标志某个 RowGroup 的某个 Column 内的各个 Page 的 Range 信息,包括 min-max 。
- 这里有点类似 RocksDB,每列可以存放压缩的值,比如 “ab” “db” 可以存 “a” “d”.
- Statistics 的问题见
Sort Order一节,其实目前的实现还是有比较大问题的.
- OffsetIndex 会标记各个 RowGroup 对应的 Page 的偏移量
这部分的 Page 类型为 INDEX_PAGE, 对应 thrift 结构如下:
1 | struct PageLocation { |
别的字段都比较简单,boundary_order 专门记录了 Page Index 的顺序性。至少是 RowGroup 内的顺序性。
BloomFilter
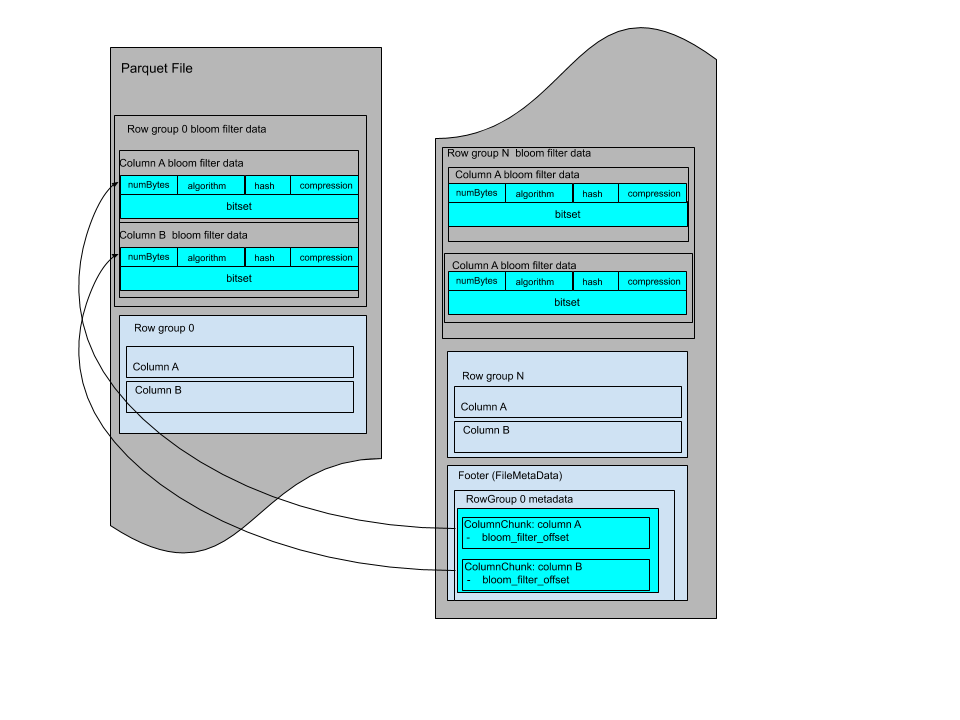
BloomFilter 官方实现有两种位置。官方有一个 RowGroup 的 BloomFilter,对需要构建的列构建 BF。值得一提的是,代码实现中,这里需要提前 guess (或者预知)行数,来提前分配 BloomFilter。
这里的 BloomFilter 算法和 RocksDB 的类似,具体数学可以参考:https://github.com/facebook/rocksdb/wiki/RocksDB-Bloom-Filter#the-math . 不过看了一下代码后,感觉 RocksDB 做的要细很多。
Nested Structure and NULL: Serde
nested 和 null 都是靠 definition level 和 repitition level 来完成的。对于两个 level,这里会用 RLE 进行编码,然后存放在 Page 上,每个 Page 包含的逻辑内容大概是:
- Page Header
- Repitition Levels
- Definition Levels
- 具体的值
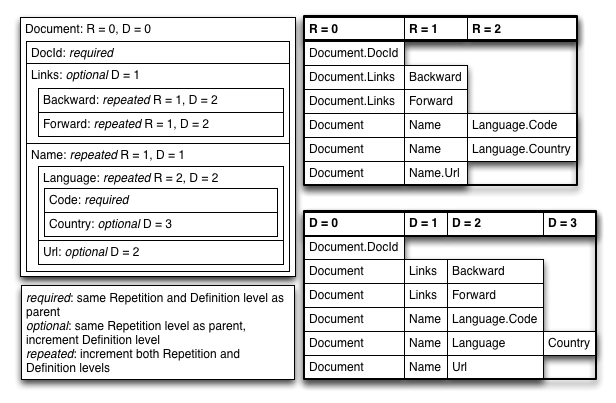
给一个 Dremel 论文中的 schema 定义:
1 | message Document { |
Repetition Levels
先 repetition levels, 这里只需要保存有值的字段:
1 | DocId |
repeatable 的字段是:
1 | Links.Backward |
可以看到,对于一个 Name.Language.Code,它既可能是属于新的 Name , 也可能属于 Name 下新的 Language。 那么,对于 repetition 来说,就是「它在哪个级别 repeat 了」。
那么,如果是某个值「父亲不存在,导致应该存在的值不存在」的话,比如:
1 | Document { |
这个时候,LinkID 是残缺的,这里可以补一个 NULL 的虚拟记录,然后标注一下 r 就可以了
definition levels
对于某个字段,它的路径上有多少值是「可以不存在」的,可以不存在即 Schema 定义为 nullable 或者 repeated 的字段。这个字段也包括自身(如果自己是 nullable 或者 repeatable 的话)。这个路径也需要理解一下:
- 对于非嵌套的字段,如果它是个 optional 的,且为 null,那么自己的 definition levels 就为 0,否则为 1
- 嵌套的字段取决于父级对应的字段,parent的一行 数据的某一列至少有一个 d (这话有点模糊,我指的是,如果父亲是 null,这玩意也得带个 d,虽然这行数据不存在)

编码和解码
这里可以看到,其实不是所有字段都需要 r/d 的,比如 DocId 就可以都不要;Name.Language 可以不要 d。然后这个编码还是有父子层次的概念的,比如有几条 Name.Language.Country 取决有几条 Name.Language,这个记录可以看看我们前面的定义和 Schema 定义。Parquet 读者在读的时候会创建一个 Struct 对应的 Reader,来递归读取。
编码的算法大概如下:
- 首先,会根据 Schema 构建出一颗树,来表示对应的结构。这个树的构建方式使用 dfs,大概如下:
- 对构建出来的树扫描的时候,带上 r, d,然后构建
我们讨论一些特殊情况:
- 如果正常的一条路径全部没有 null,那么
d = 路径上(包括自己) nullable 和 repeatable 的数量,r = 路径上(包括自己) repeated 中的某一个。 r 和 d 都是 是「自己级别的 max」 - 如果一个路径自己是 null,父亲不含 null,那么
d = 路径上(包括自己) nullable 和 repeatable 的数量 - 1,即 父亲的 d,或者上一个 nullable / repeatable 对象的 d,r 和 (1) 则一样,但最大是一样的,都是「自己级别的 rep-max」 - 从 1/2 其实可以看出来,null 可以通过 d 来确定,d 如果小于路径上 nullable/repeatable 值总数,就可以是 Null
- 如果某个路径父亲是 null,那么 d 会更小,d 会等于非 null 父级的 d,r 则是父亲级别最大的 r。相当于某个级别开始为空的话,d 会是父级别的 d-max,r 会是自己的 r
上面这些内容非常重要,因为 arrow 的代码实际上是靠这套规则来实现的。
Reference
Google Dremel数据模型详解(上) http://static.kancloud.cn/digest/in-memory-computing/202157
Google Dremel数据模型详解(下) http://static.kancloud.cn/digest/in-memory-computing/202158
https://blog.twitter.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet
专门解释 Parquet / Dremel 格式的文章:https://github.com/julienledem/redelm/wiki/The-striping-and-assembly-algorithms-from-the-Dremel-paper
Rust 版本的 Parquet 为了解释发了几篇文章,其实介绍的比较好:
- Arrow and Parquet Part 1: Primitive Types and Nullability: https://arrow.apache.org/blog/2022/10/05/arrow-parquet-encoding-part-1/
- Arrow and Parquet Part 2: Nested and Hierarchical Data using Structs and Lists: https://arrow.apache.org/blog/2022/10/08/arrow-parquet-encoding-part-2/
还有一些二手评论: