Notes on Btree Implements: InnoDB
BTree 的实现一直是有范本但工程上很难做的事情,Btree 自上世纪 70 年代被提出后(1972),已经是一个久经考验的结构了(远比 LSM-Tree 古老),但是 B-Tree 的并发一直是介绍材料不多、工程实现难啃的部分。相对于 2021 年常见的 LSM-Tree 而言,[1] B-Tree 实现大部分不是 immutable 的 。[2] B-Tree 大部分和存储引擎、Recover System、事务、Catalog 结合得很紧密,大部分时候不是一个简单的 KV 接口。导致这个常见的数据库结构带上了很多神秘的面纱。
我们希望介绍 MySQL 的 InnoDB 引擎、PostgreSQL 的 BTree 引擎和 WiredTiger 的 COW BTree 结构。来介绍一下常见数据库真实使用的 BTree 范本。
MySQL InnoDB
MySQL InnoDB 基于 Jim Gray 的 Transaction Processing 一书实现。这里实现了一个 MVCC 的 BTree,MVCC 数据采用 N2O 的形式链接,主表数据存储在 BTree 上,称为 Cluster Index;索引数据;旧版本的数据会放到一个 Delta Space 里面。删除和 MVCC 的形式结合起来,做标记删除。
一刻 BTree 的 Page 会尽量存放在一起,具体可以参考 InnoDB 的表空间。同一个索引中,non-leaf page 会存储在一个 Segment 中;leaf page 会存储在一个 Segment 中。Segment 会按照 Extent (大小为 1MB,默认为 64 个 Page ) 为单位,向系统申请存储空间。
Page
数据页包括七个部分,数据页文件头,数据页头,最大最小记录,用户记录,空闲空间,数据目录,数据页尾部。 简单的来说,数据页分两部分,一部分存储数据记录,按照记录的大小通过记录的指针连接起来。另外一部分存储数据页的目录,用来加速查找。
以索引页为例:
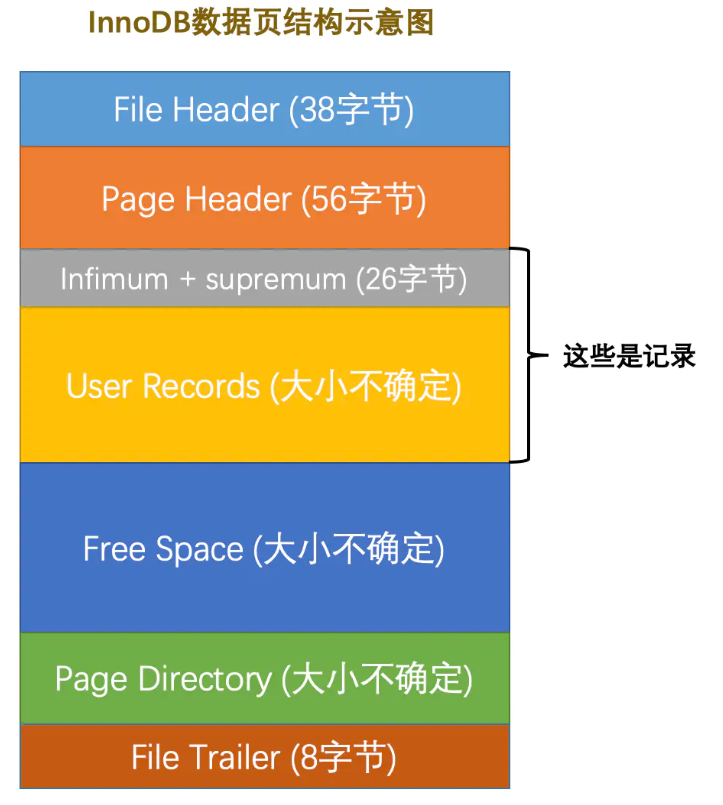
File Header 部分会标志这里是什么页,而 File Trailer 则有 crc 和页面的 lsn。这一组内容由 fil 有关的文件组提供,代码在:https://github.com/CatKang/InnoDB/blob/master/innobase/include/fil0fil.h#L789
page 有关的文件基本上是为索引页设计的,page 开头基本上是存储的页面元信息,Page Header 之类的,它的元信息在 page0page 维护,操作主要在:https://github.com/CatKang/InnoDB/blob/master/innobase/include/page0cur.h
Tuple
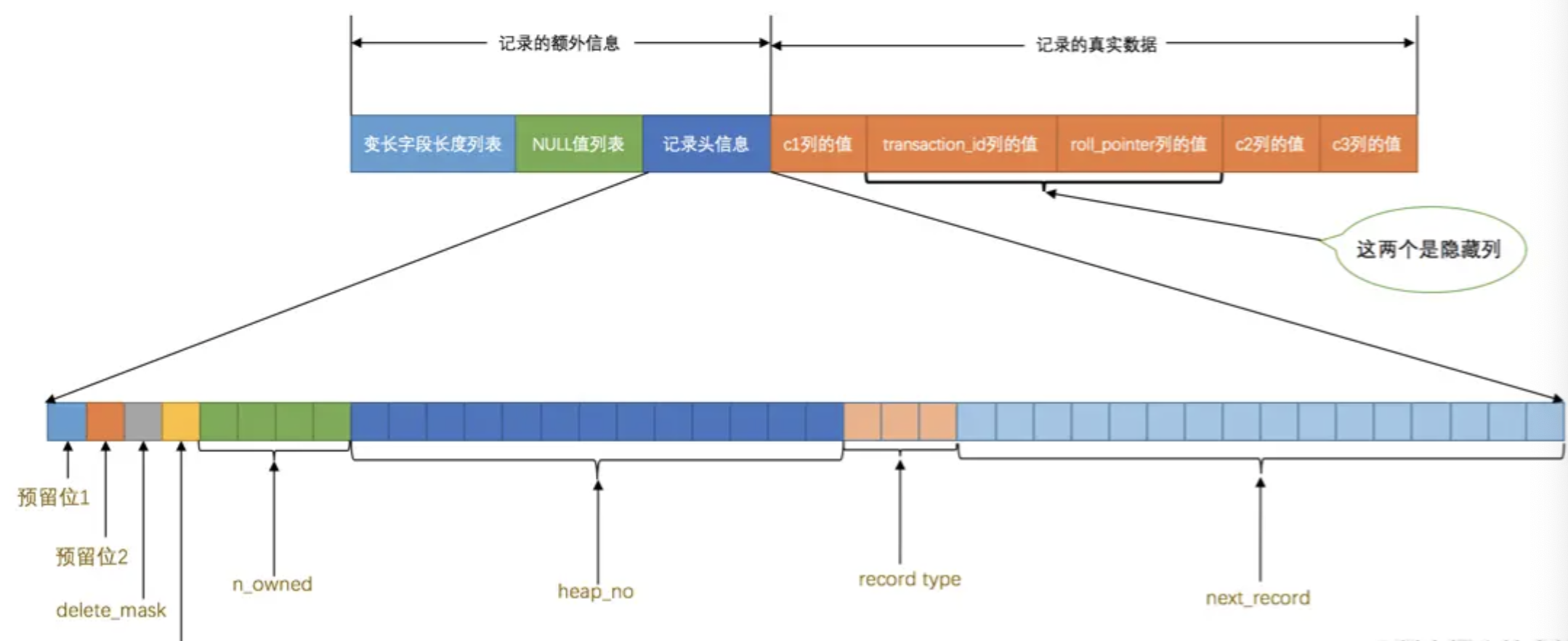
这些 Tuple 之间会根据 next_record 构成一个单向链表,指向下一个字段的 header 之后,真实信息之前,transaction_id 是一个顺序增长的 id,用来表示创建这条记录的事务 id,roll_pointer 指向 undo 上的记录。
Leaf Page / Non Leaf Page
下面的代码实现在 page0page 相关的系统中。
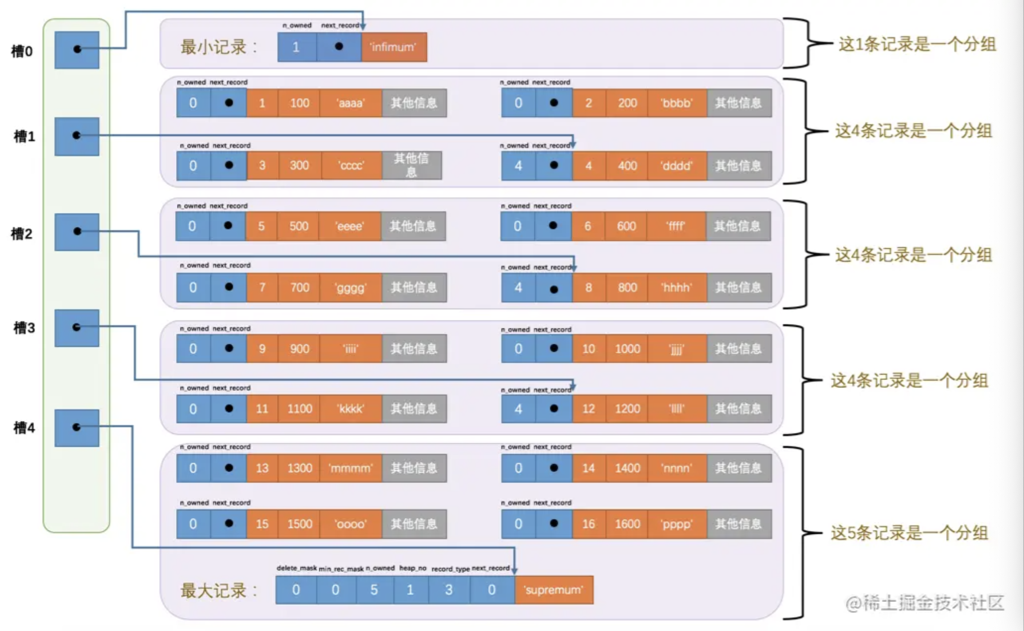
InnoDB 的 Page 内容采取双向链表 + 稀疏索引的形式实现,头部还有一些统计信息,下图比较清晰:
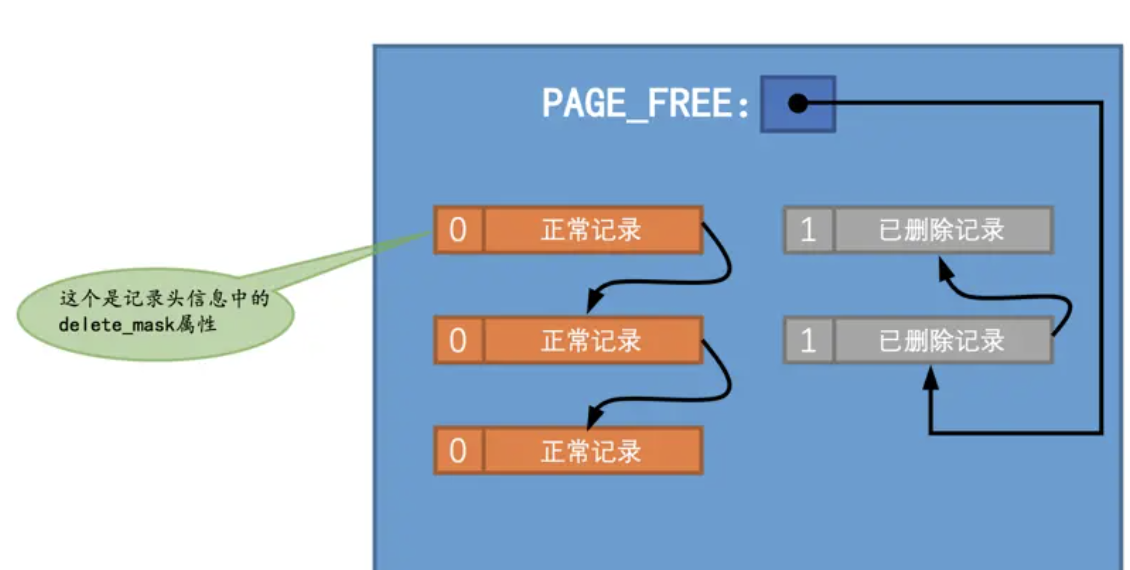
此外,Page 内还有页面的垃圾链表,存放垃圾记录:
对 Page 的操作可以看:http://mysql.taobao.org/monthly/2018/04/03/
对 Page 的操作会被封装在 mtr 里面,这里日志类似物理逻辑日志。写 Undo Page 也会落 mtr。
同一高度的 Page 会组织成双向链表,称为 Page List。
对页面的操作
结合之前说到过的 Page 内部组织,page 的查找和插入、更新操作都在 page0cur 相关的文件中。需要注意的是,对 Page 的操作不是单个操作,而是一组操作,具体而言,比如说对 Page 的插入,这里会拿到一个对应的 cursor,指向插入的前一条记录,详见代码 page_cur_insert_rec_low:
- 找到 Page 的原本的信息,包括一些统计信息
- 在 Page 里找到空闲的空间插入记录
- 修改统计信息,和上一条记录的 next (还记得它们是单向链表吗)
所以这里插入实际上不是单条操作,而是一组合起来的操作。
删除的话,可能直接标记 delete_mark,然后更新一些统计信息即可。
Undo
InnoDB 的 MVCC 实现是 Main-Delta。逻辑如下所示:
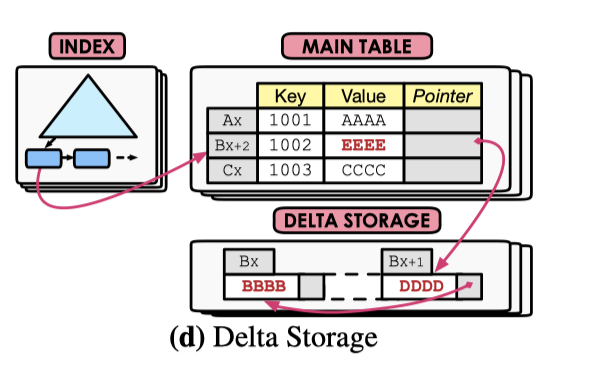
具体而言,对于 InnoDB,如果有表 (a: PrimaryKey, b), 然后 b 被两个事务更新两次,可能会有:
- Cluster Index:
(a: a, b: b2), update by txn2, roll_pointer->u2 - Undo:
u2: <Undo Update, txn1, (a: a, b: b1), roll_pointer->u1>u1: <Undo Update, txn1, (a: a, b: b0), roll_pointer->NULL>
在逻辑上如下图表示:
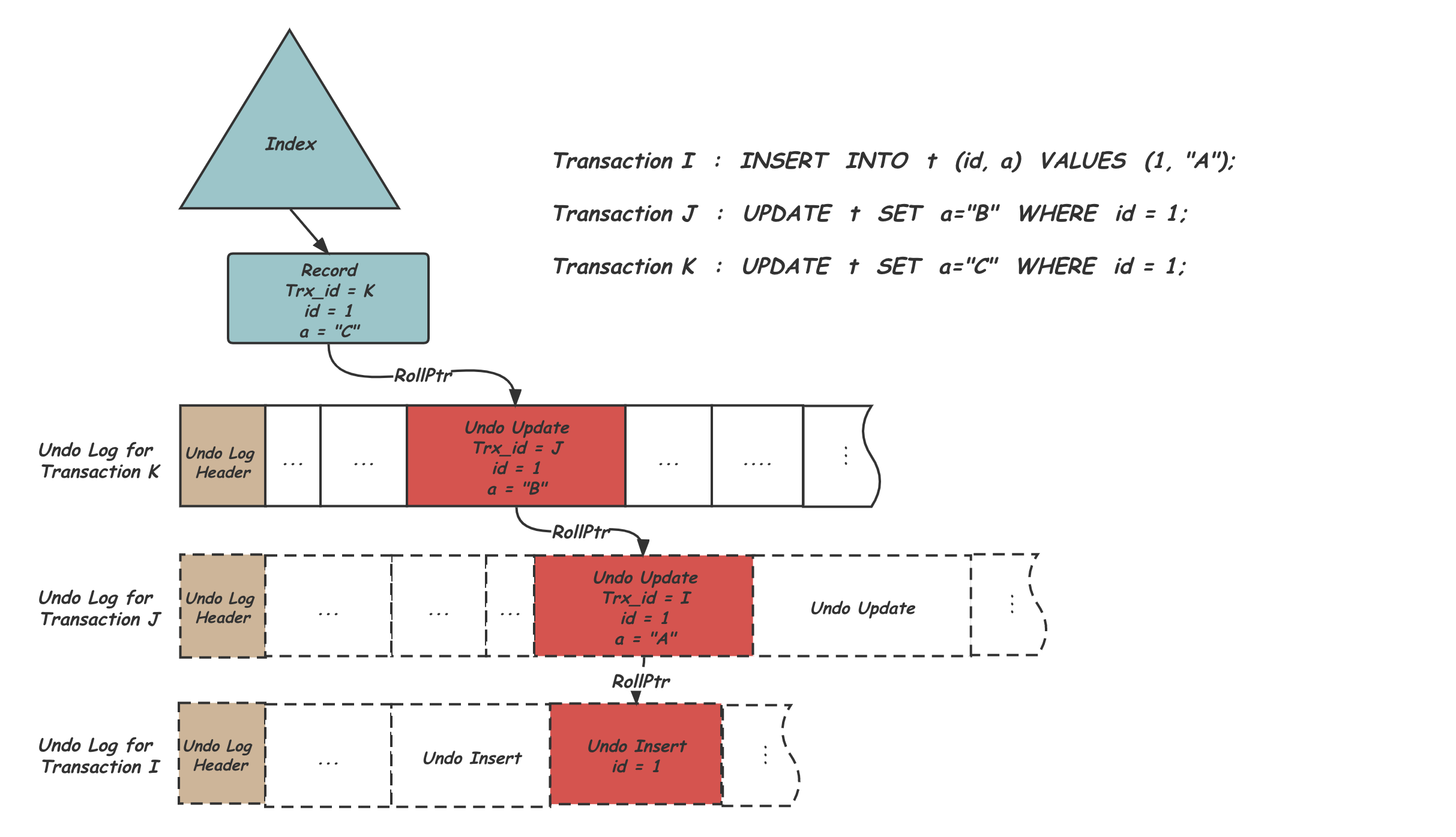
Undo 实际上承担的功能类似:
- 回滚数据库未完成的事务(教科书上的 undo,不过这样其实是最多只需要一个版本的),对应接口在 row_undo,trx_roll_pop_top_rec_of_trx 这条链路
- MVCC 回溯版本链,作为 Undo 的数据,对应接口在在函数row_search_mvcc中,关注trx_undo_prev_version_build 和 row_upd_rec_in_place
物理空间上,Undo 也是由 Page 组织的。一个事务主要记录会保留在一个 Undo Page 上(多余一个的会存在一个 Page 上,但是不讨论),事务的记录会被一个双向链表 history list 串起来,然后按照全局的最低活跃事务和这个 history list 来做多版本数据的 GC。
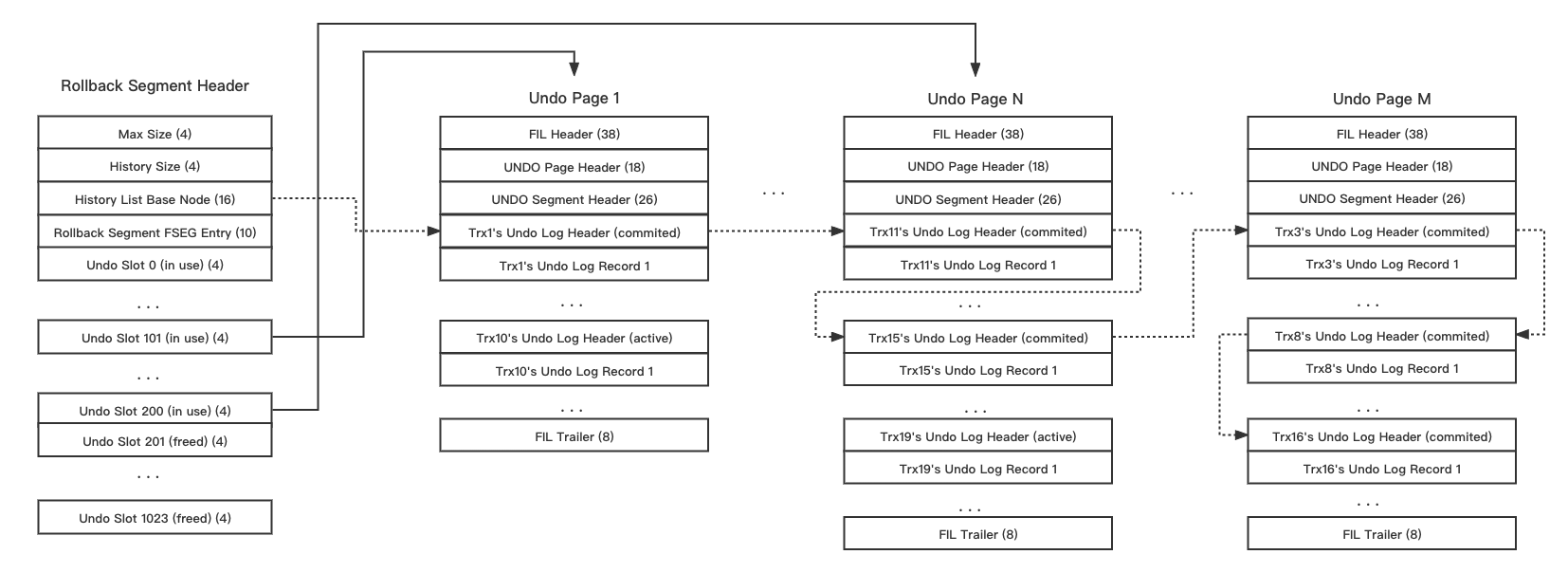
此外,虽然 btr 我们后面才会介绍,但是 InnoDB Undo 不会涉及 secondary indexes,这点在官方文档也有提及:https://dev.mysql.com/doc/refman/8.0/en/innodb-multi-versioning.html
Redo
InnoDB 的 Redo 感觉就和教科书的 Redo 很接近了。这里有一些分类:
- Page 内操作的物理逻辑日志,比如
MLOG_REC_INSERT,MLOG_REC_UPDATE_IN_PLACE,MLOG_REC_DELETE,它们会有一些操作标注修改的页面。 MLOG_FILE_CREATE等空间状态的日志MLOG_MULTI_REC_END等表示一组操作的日志。比如页面分裂的时候,会有一组表示拷贝记录的日志,需要用这样的日志结尾。
Transaction 和 MTR
最后介绍一下事务子系统,希望能把上面的 Btree 和 Undo 内容连起来:
mtr 完成的是 atomic, durable 的多页面操作,它会封装对单个索引(包括 Cluster Index)和 Undo 。mtr recover 的时候,只有 redo,没有 rollback。rollback 都是上层事务的 rollback。
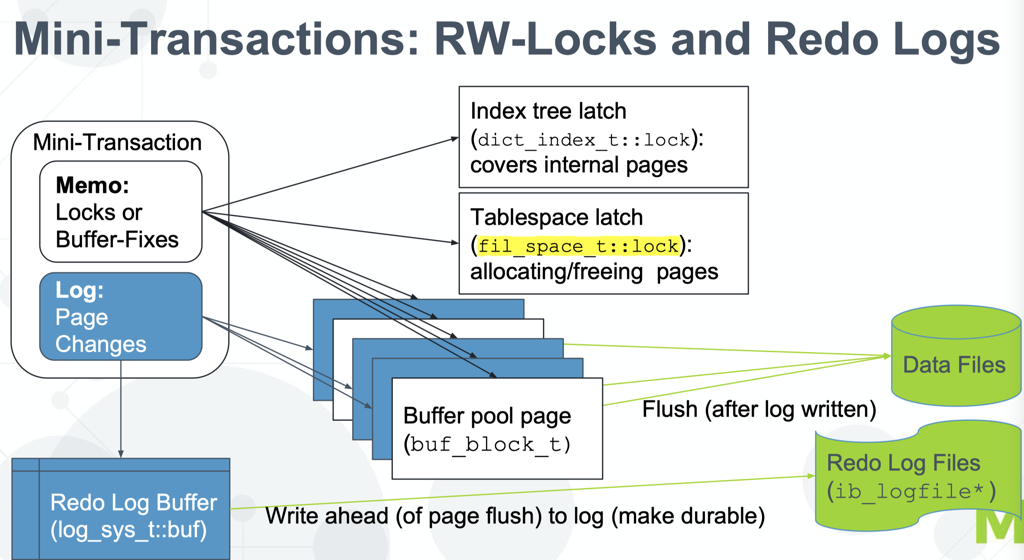
对事务的操作都会丢到 mtr 的 buffer 里面,提交完后原子提交到 redo 中。同时,读取可能也有 mtr。
事务层会有 多个 mtr: 包括索引的 mtr, undo 的 mtr,事务是 mtr 上层的概念。它从 Btree 读取 mtr 中读到数据,然后在这一层上锁。
InnoDB Btree 的操作
下降和 Latch
BTree 访问遵照 Latching Protocol。具体代码在 btr0btr 和 btr0cur 中. btr_cur_t 是 btr 的 cursor,从 btr_cu r_search_to_nth_level 中拿到对应的 cursor。然后这里 btr_cur_t 插入和删除。同时,我们还可以和 page0cur 中的 page_cur_t 结合起来。btree 访问有几种 flag:
在B+ tree上共有三种操作:
- 读(BTR_SEARCH_LEAF / BTR_SEARCH_LEAF):分为点查询和范围查询
- 乐观写(BTR_MODIFY_LEAF):仅影响到一个索引页的增删改
- 悲观写(BTR_MODIFY_TREE):影响到超过一个索引页的增删改(e.g. DELETE SQL导致了页合并)
同时, BTree 有 Latch 的概念,btree 操作很多都有参数 dict_index_t::lock,表示 btree 的锁。Page 的 latch 在 buf 层实现,外部可以在调用传入 buf_page_get_gen 传入参数。叶子结点访问有 btr_cur_latch_leaves
btr_cur_search_to_nth_level 有一千多行代码,逻辑比较复杂,在 8.0 版本中,读取实现逻辑如下:
- 获取 index 的 S 锁:
mtr_s_lock(..) - 然后沿着搜索 btree 路径, 遇到的 non-leaf node page 都加 S LOCK
- 然后直到找到 leaf node 以后, 对 leaf node page 也是 S LOCK (
btr_cur_latch_leaves) - 然后把index-> lock 放开, 释放掉别的 latch (
mtr_release_s_latch_at_savepoint)
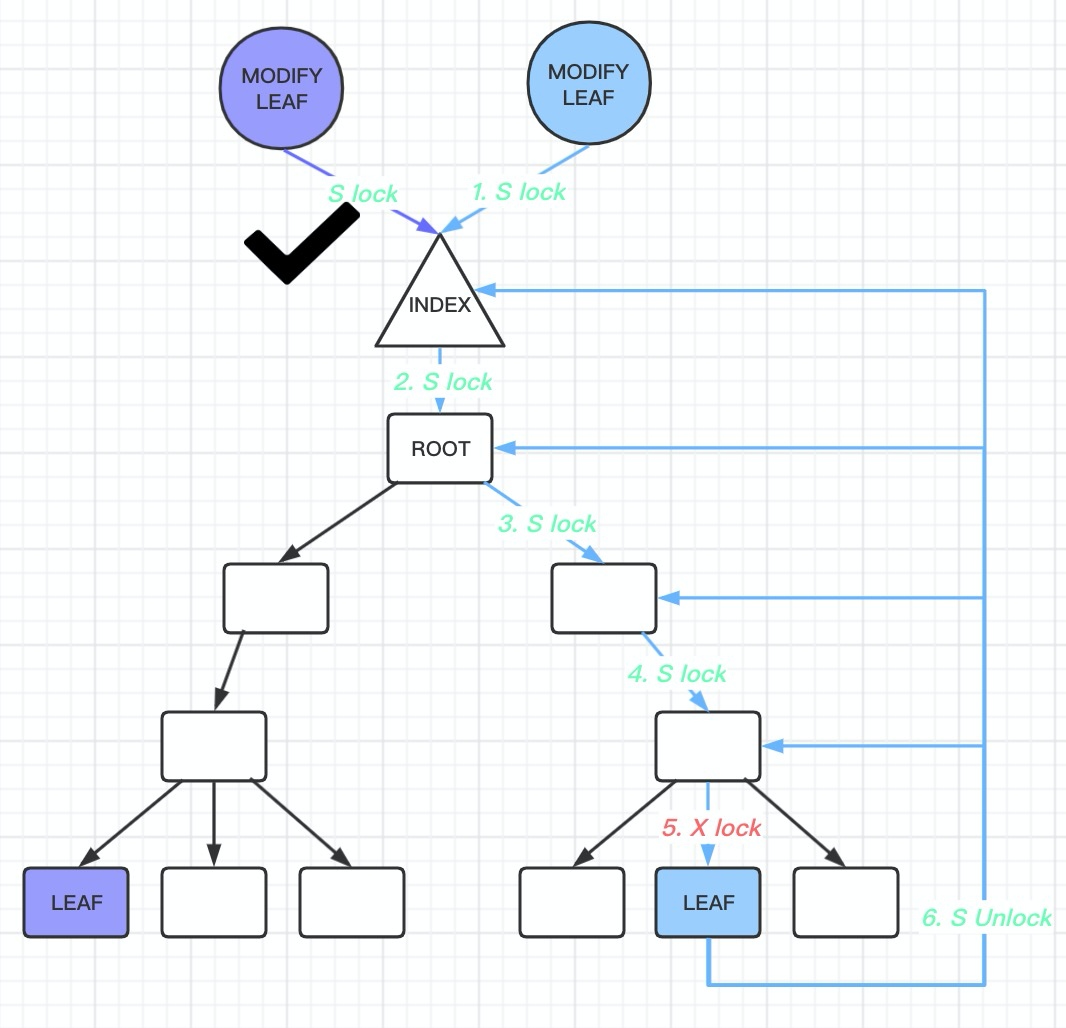
对于修改请求,这里有 乐观 和 悲观 两种:
- 乐观:
btr_cur_optimistic_insert:假设没有 SMO,进行插入 - 悲观:
btr_cur_pessimistic_insert:乐观插入发现叶子会分裂,进行插入
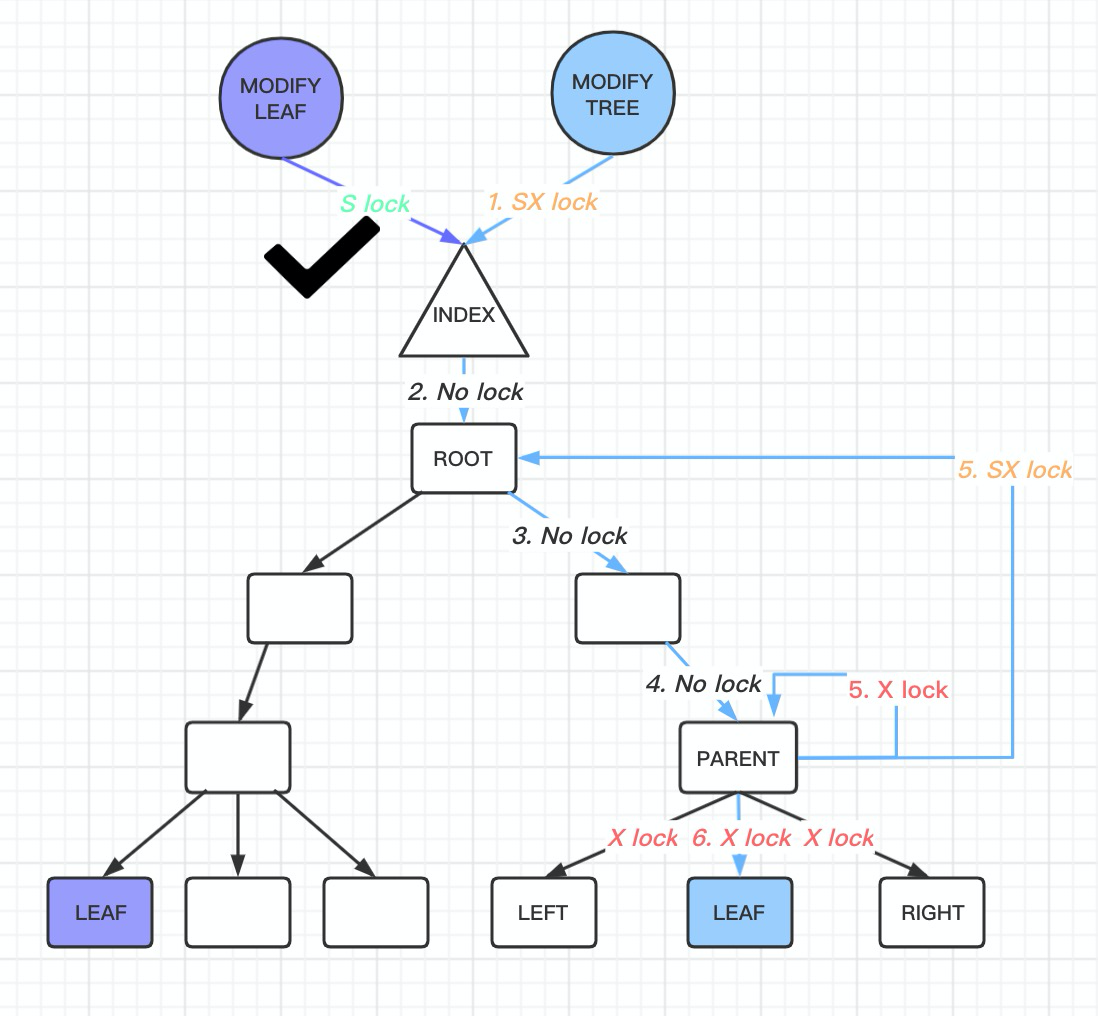
上面内容不会出现在 btr_cur_search_to_nth_level,不过会影响 btr_cur_search_to_nth_level 的参数 btr_latch_mode. 他们插入内容如下图:
- 乐观插入类似查找,也是 S 拿到 index 锁,拿到叶子结点的 X 锁(为了与 S 锁互斥)
- 悲观插入假设自己会引发 SMO ,首先,它会拿到 SX 锁。SX 锁能够与 SX 锁互斥(即与悲观的插入/删除互斥),但不阻塞读和无关的写。然后,下降的时候,因为已经给btree 加上 SX 锁, 那么搜索路径上的btree 的page 都不需要加锁, 但是需要把搜索过程中的page 保存下来, 最后阶段给搜索路径上有可能发生结构变化的page 加x lock。此外,这里叶子需要 X锁,且需要左右兄弟的锁。
Cursor & Persistent Cursor
对于下降函数,这里可能会下降很多次,最终到达叶子结点,但对于一个 Scan,肯定不能每次下降一次。这里要根据 page 上的 cursor 来做一些操作,包括 scan 的 next 什么的,这里有一些优化:
- record buffer:对于连续的记录扫描,在满足比较严格的条件时采用 record buffer,预读几条数据
- persistent cursor(持久化游标,简称 pcur):当进入 InnoDB 层获得记录后,返回 SQL 层前,当前在 B-tree 上的 cursor 会被暂时存储到
row_prebuilt_t::pcur中,当再次从 InnoDB 层拿数据时,如果对应的 buf_block_t 没有发生任何修改,则可以继续沿用之前存储的 cursor(optimistic restore cursor)。否则需要重新定位(pessimistic restore cursor)。如果没有 persistent cursor 则每次都需要重新定位
persistent cursor 代码在 btr_pcur_t,文件在 btr0pcur。btr_pcur_move_to_next_page 描述了它读下一个页面的流程(本页面都扫描完了),这里会获取下一页面,再释放本页面的锁。restore_position 描述了 pcur 回到本页面的逻辑。
上面都比较简单,因为移动到下一页相对比较轻,但是比较复杂的情况是逆序扫描,这里代码在 move_backward_from_page,这里如果搜索了前一个 Page 的话,那么会有问题:先锁右 - 再锁左边会违背 latching protocol,这里会:
- 释放之前的 latch
- 在树上从新搜索之前的值的前一个值,
btr_search_to_nth_level+BTR_SEARCH_PREV
分裂
我们之前介绍了 下降 + 插入的情况。分裂/合并都是 SMO 操作,他们是由悲观的插入来提供的。
Btree 分裂在 btr_page_split_and_insert, 在插入 Page 的时候,会有一些元信息来表示顺序插入的次数,如果插入都是顺序插入或者满足一定条件,那么 Page 会向右分裂;否则会按照 bytes 空间的 50% 来进行分裂。
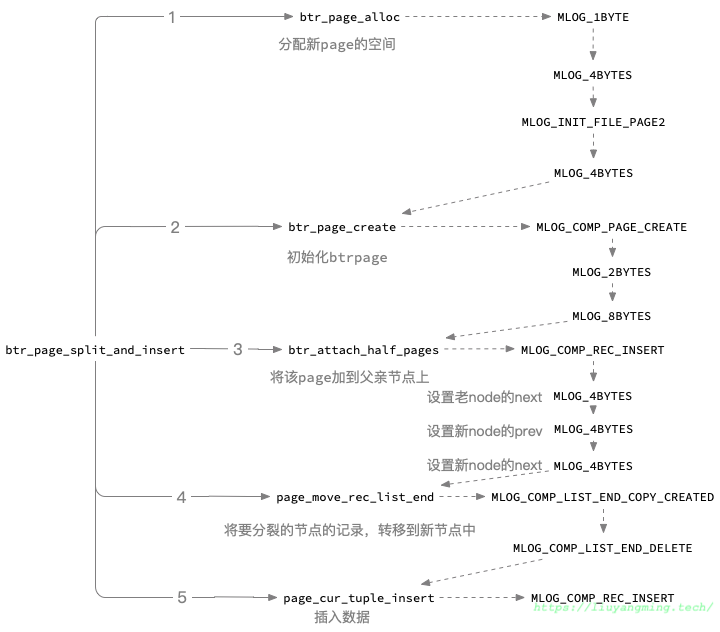
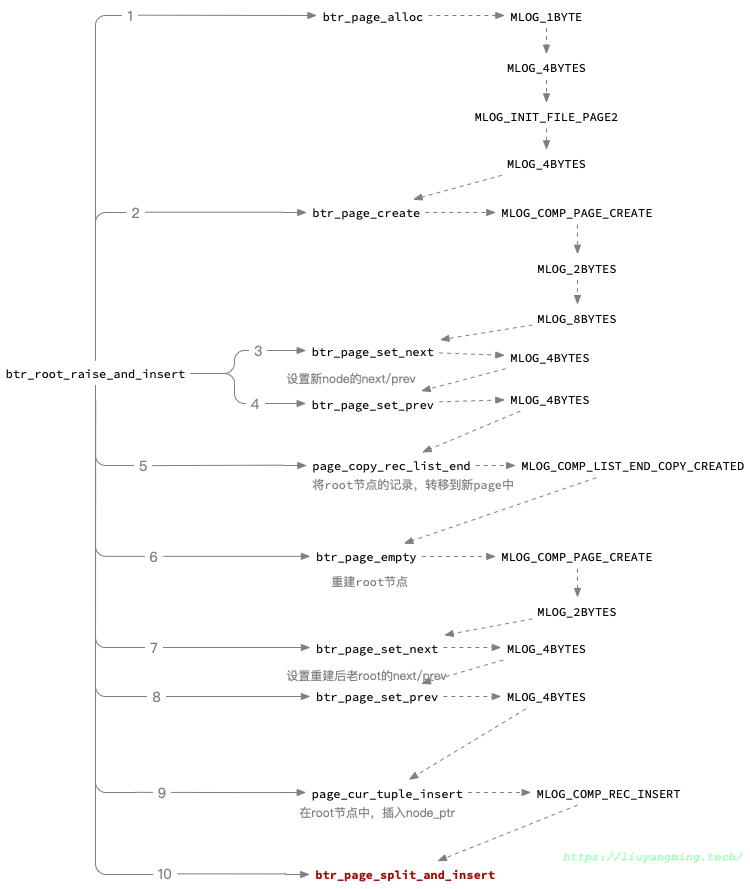
根结点的分裂
在 InnoDB 中,BTree 的 Root Page 是不会更改的。如果是 RootPage 从叶子结点分裂到根结点,具体逻辑如下:
- 产生一个叶子结点
- 把根结点数据拷贝上去,根结点指向它
- 这个叶子结点执行分裂
Insert Buffer
insert buffer 对于 non-unique 的 secondary index 才有用,在写索引的时候,无法加载到内存中的时候,插入 insert buffer 作为缓存。
这块代码其实比较 hack 而且散在各处,比如读取的时候还要查一下有没有 insert buffer 里面的写,然后把数据倒腾进去。
上层的 ICP 和 Lock
对 Btree 的访问本身是没有锁的,锁是在上层拿到的。对于一个查询 + 更新而言,大概逻辑如下:
- 从 btr 查询需要的行
- 给记录加锁
- 申请 undo, 写 undo
- 更新对应的行,这个和 undo 其实是不同的 mtr
- commit
ICP 是查询的时候带有对应的谓词,大概逻辑如下: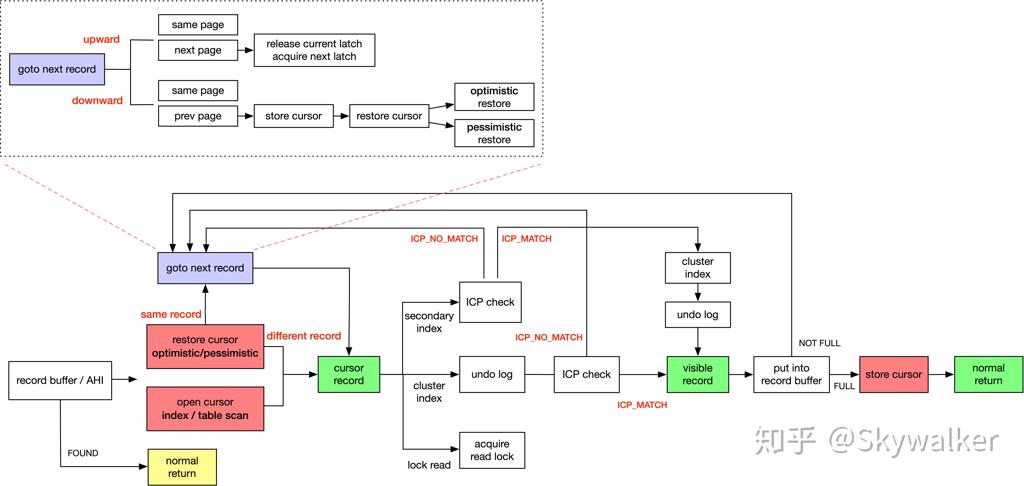
参考
- https://catkang.github.io/2020/02/27/mysql-redo.html
- https://catkang.github.io/2020/02/27/mysql-redo.html
- InnoDB:B-tree index(1) - Skywalker的文章 - 知乎 https://zhuanlan.zhihu.com/p/164705538
- InnoDB:B-tree index(2) - Skywalker的文章 - 知乎 https://zhuanlan.zhihu.com/p/164728032
- InnoDB——Btree与MTR的牵扯: http://liuyangming.tech/05-2019/InnoDB-Mtr.html
- MySQL · 源码分析 · btr_cur_search_to_nth_level 函数分析: http://mysql.taobao.org/monthly/2021/07/02/
- MySQL · 内核特性 · InnoDB btree latch 优化历程: http://mysql.taobao.org/monthly/2020/06/02/
- https://mariadb.org/wp-content/uploads/2018/02/Deep-Dive_-InnoDB-Transactions-and-Write-Paths.pdf