[VLDB'17] An Empirical Evaluation of In-Memory Multi-Version Concurrency Control
本文是一篇关于 MVCC 的综述,将 MVCC 分为了 protocol, version storage, index-management, gc 四个部分, 在 Peleton 上实现了各种 protocol, 进行试验,然后 benchmark。benchmark 结果是:protocol 上看争用,读多写少争用多的话,2PL/OCC 反而不太行;N2O 几乎总是比 O2N 好,不过 O2N 可以GC;Delta 占用的空间小一些(Delta 类似 MySQL Undo log buffer);Txn Level GC 好一些,但实现难度高一些。
当初第一次看的时候大概懂了大意,不过当时对 MVCC 没看过什么代码,也没有什么基本理解,最近看 WiredTiger/PostgreSQL/InnoDB 的时候感觉理解了一些 context,回头写一点总结,也混杂一些我对 WT/PG/InnoDB 的理解。
关于 MVCC,有的地方实际怀疑它是否牺牲了空间以换取了不知道有没有的性能,关于这些争论,我个人想法类似 Hekaton 论文里面的理解:MVCC 可能在冲突低的情况下降低了性能和局部性,但是增强了系统对抗一些混合负载的能力。同时,MVCC 方便支持一些 Time-Traver 查询(类似 MySQL / PG 的 PITR 系统)。
之所以有这篇论文,是因为 MVCC 虽然历史悠久,但是几乎所有新系统都自己嗯造了一套,所以需要衡量一下对应的 design choice 和 trade-off
DBMS Meta-Data
论文讲数据分为下列数据,感觉是作者在 Peloton 实现的数据:

事务需要一个独立的,单调递增的标记来识别,文中记作 $T_{id}$ .
同时,物理的版本包括了 txn-id, 两个时间戳和版本指针,事务 id 类似 Hekaton 的,最高位表示是否有 write-lock,然后论文用 CAS 做修改,我们可以对比一下 PostgreSQL 和 InnoDB 的记录:
- PostgreSQL 的 xmax(类似 end-ts ) 充当了 txn-id 作用,表示对对象上锁。论文里可能有多个 in-flight 的事务在同一条记录上,所以感觉引入一个 txn-id 也没啥问题。此外,PostgreSQL 的行还引入了 info bits,避免查事务表来确定
txn的状态,所以相当于上面 txn-id 和 end-ts 做到了一起,PG 有一个c_tid,相当于上面的 pointer,指向自己或者更新的版本。

- PostgreSQL 的 txn-id 和时间是 32-bit 的,所以最大也就4亿,占有空间小,但是需要 FREEZE (冻结版本)和 Vacuum(回收)来处理。InnoDB 可能需要用户提供的 gtid 什么的。它只有一个类似 ts 的字段,因为比它小的就会走 undo chain。PG 需要 x-min, x-max; 但 InnoDB 用 txn-id + roll_pointer 做了逻辑上一样的事情。那删除会怎么样呢?InnoDB 记录刚被删除会挂上一个 delete-mark,然后指向 undo 上的 delete 记录。
- InnoDB 只有一个 txn-id,大于就读它,否则就走上文 pointer 的字段,如下图。这些字段被称为 hidden columns。此外,InnoDB Undo 实际上存放的是逻辑日志
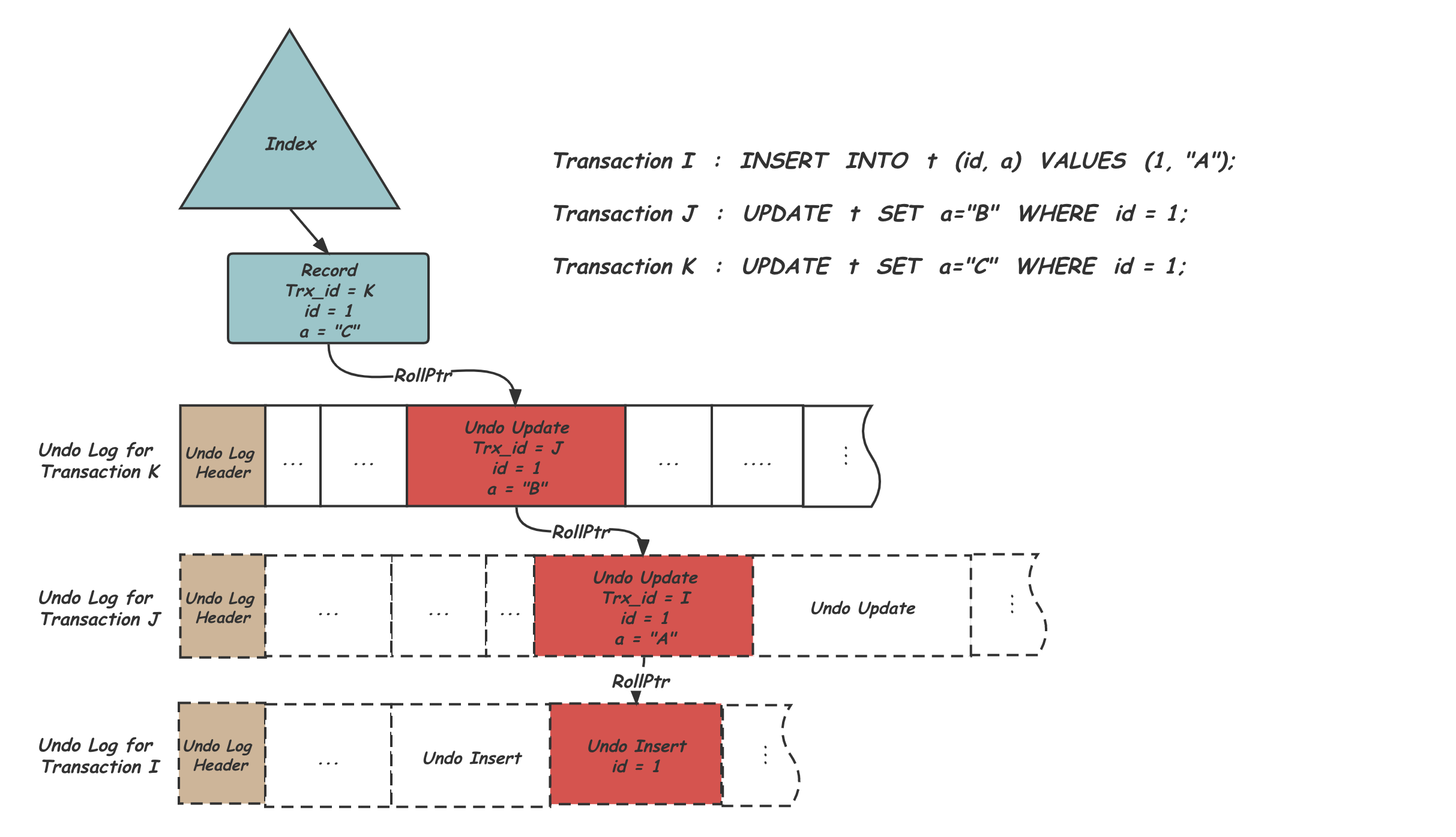

总的来说,感觉这篇论文还是偏内存数据库一些,然后考虑了并发更新什么的。
Concurrency Control Protocol
在论文中,cc 相当于定义了:
- 是否允许 txn 访问或者更新一个 tuple
- 允许 txn 来 commit 自身的提交
经典的 Concurrency control 包括我们熟悉的内容:
Transaction, OCC and Modern Hardware: https://blog.mwish.me/2022/01/28/Transaction-OCC-and-modern-hardware/
事务: 并发控制协议: 2PL && TS: https://blog.mwish.me/2020/11/15/transaction-concurrency-control/
可能是出于实现粒度和学术追求,论文只考虑 Tuple Level MVCC + Serializable。实践中,感觉这些级别还是比较高,有比较多的场景还是 SI / RR + SELECT for update 这种。同时,论文也放弃了中心化的 Lock Manager,这样的东西很容易成为一个性能上的瓶颈。
MVTO
类似 TS 协议: https://blog.mwish.me/2020/11/15/transaction-concurrency-control/#TS
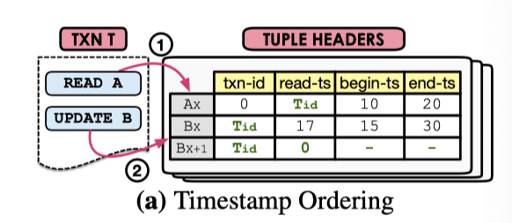
论文 figure 2.a 做了一个图示,读会更新对应的 ReadTS, 这是一个额外需要的字段,读会增加这个字段的内容,然后写的时候写入的版本不仅需要自己是唯一的写,要比最大的读取版本高,否则就视作读了不合法的数据。
实际上,这里感觉只有读最新的版本会对事务更新产生影响,然后这个并发感觉需要控制的比较好。
MVOCC
我写过一段比较长的文章来介绍 OCC,参考:https://blog.mwish.me/2022/01/28/Transaction-OCC-and-modern-hardware/#MVOCC
MVOCC 有一点好,就是 OCC 是 read - verification - write 三个阶段。对于 MVOCC 而言,可以给每个数据带上一个 begin-ts 和 end-ts,这里就不用拷贝事务的 private space 了,取而代之的是 GC 问题。
论文描述了它的 MVOCC 算法,原先的实现中,靠拷贝读写集 + 验证来解决,而现在可以当作读的 ts 和提交 ts 之间做验证,看这段时间有没有被别人改过。相对 OCC,MVOCC 很多时候甚至直观一些。
- Read phase: 拿到一个读取用的 txn-id 和 ts,用来读取数据,写入的时候只能写入没有写入冲突的数据。读取记录到 read-set 中
- Validation phase: 拿到 commit ts, 看 read-set 有没有被别人更新(因为 ts 是递增的,进 validation 说明,只有发现 commit-ts 在 read-ts 和自己的 commit-ts 之间的记录,才需要改掉)
- 提交,把 MVCC 记录提交
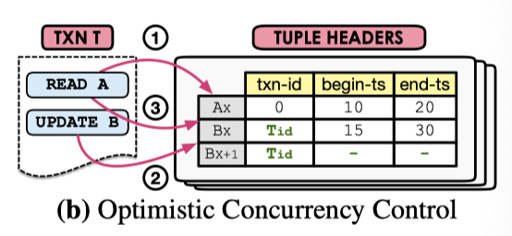
显然,上述算法…可能饿死 long runing read-only txn…
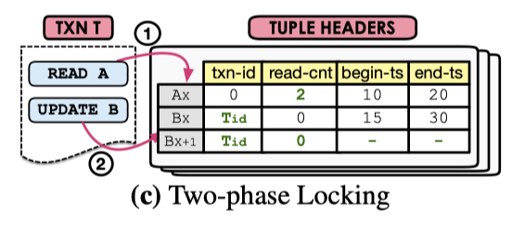
MV2PL
作者的实现中,它使用了 no-wait 来实现 2PL 的冲突处理,在读的时候加读锁,写的时候加写锁。这些都在 tuple 上用计数器实现,本质上有点点小类似 ts 协议,只不过 ts 是读的时候 inc counter,2PL 是写上写锁 + 写锁和读的计数器互斥。发现有别人在写就直接 abort 自己,满粗暴的。
Serialization Certifier
类似 SSI,识别 dangerous structure,来做处理。
讨论
- MV2PL / MVTS 的读要改 counter / lock,有一些负载,同时会导致一些伪阳性的 abort。
- MVOCC 的算法可能导致长读事务饿死
相关的,有一些优化的提案:
- speculatively read uncommitted versions. Hekaton 用了这个. 如果事务冲突少, 这是良药, 否则就是毒药。为了做 cascading abort, 这里还要做一些 dependency graph 之类的,这难免会是个有些中心化的结构。
- eagerly update, Hekaton 也做了这个优化,缺点同 (1)
Version Storage
这里的内容包含:
- 数据库怎么存储不同的物理版本
- 每个版本包含的信息
DBMS 可以包含一个 latch-free 的同一个 tuple 的版本单链表(latch-free 的双链表是很难的),版本链的头可以是 newest 或者 oldest 的事务。
Append-only Storage
在 PostgreSQL, Hekaton, MemSQL 采用的是这种策略:
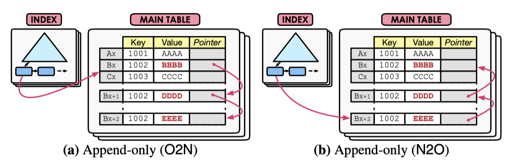
O2N 和 N2O 分别是旧到新 — 新到旧。
O2N 的好处是,没有更新索引字段的话,索引是不用修改的,但是这个时候 DBMS 可能要走很长的版本链来查找记录,然后走 chain 查找还是比较慢的,所以这里依赖比较频繁的 GC 来保证性能。
N2O 需要在索引值没变更的时候也更新索引,造成了一定的开销。
另一个问题是对 non-inline attributes 的处理,比如 MySQL 的 BLOB 或者 PG 的 TOAST,不同的版本可能可以共享同一个 BLOB,DB 维护它的 RC,来避免 BLOB 上的开销。
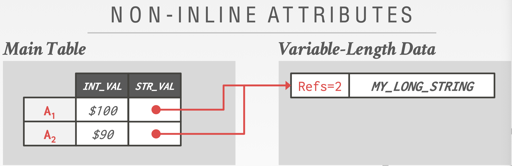
PostgreSQL 的 TOAST 有类似的技术:
The TOAST management code is triggered only when a row value to be stored in a table is wider than
TOAST_TUPLE_THRESHOLDbytes (normally 2 kB). The TOAST code will compress and/or move field values out-of-line until the row value is shorter thanTOAST_TUPLE_TARGETbytes (also normally 2 kB, adjustable) or no more gains can be had. During an UPDATE operation, values of unchanged fields are normally preserved as-is; so an UPDATE of a row with out-of-line values incurs no TOAST costs if none of the out-of-line values change.
Time-Travel Storage
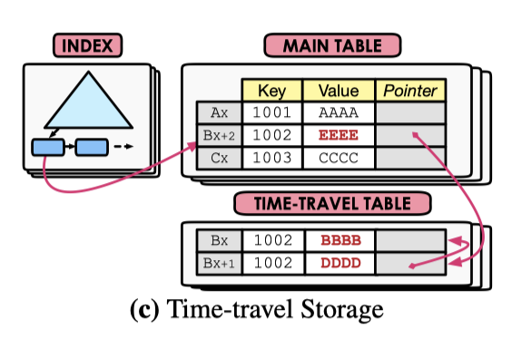
类似 Append-Only Storage,但版本分成了主表和别的存储,存一个主表,Time-Travel Table 存放不同的版本。需要更新的时候,这里需要在 time-travel table 中申请空间,然后把数据拷贝过去,然后改主表。没改 index key 的话,index 是不需要更新的。
Delta-Main Storage
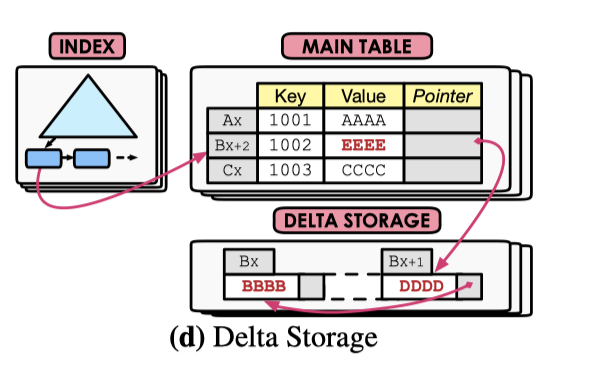
HyPer, MySQL 和 Oracle 使用了这种方法,相对 Time-travel Storage,这里存储的是 Delta 的内容,而非全部内容。对 Update 密集的负载,这种逻辑相对来说性能很好,但是对读来说,这会有一定的问题。
笔者认为,这里可以考虑类似 logging 那种 physical / logical 类似的区别,不用和 time-travel 分太开?
讨论
这里具体的 pros & cons 只能做一个 case by case 的分析,对于 TP workload, append-only 在没啥 overwrite 的情况下工作的不错,因为有着不错的局部性,有版本链就炸给你看。这种方式同时也加重了 index 管理的难度。
PostgreSQL 是现实 Append-Only Storage + N2O,写入的数据会更新 xmax 和 ctid,指向最新的数据,索引不会更改。当索引引用的 Tuple 最新版本被删,然后所有事务都读不到它的时候,所以会标记 LP_DEAD 来实现懒惰删除,等待 vacuum 进程 GC。
InnoDB 使用了 Delta-Main 的方式,主表是一个索引,Undo 段负责回滚。Undo 写的是逻辑更新,其实就是 delta 存储。
WiredTiger 会
TBD
Garbage Collection
GC 是 MVCC 比较重要又比较 hack 的一块,也有 Purge/Vacuum 这些关键词来描述他们。大部分面向用户的介绍材料很少提及 GC 是怎么工作的。
总的来说,GC 大概分为三步:
- 识别不再需要的版本
- 把他们从 version chain 摘除,然后处理索引对应的情况
- 回收空间
可能系统会有一个活跃事务 txn-id 下界,会根据这个回收,也有系统会有一些细粒度的回收,比如 HyPer / SAP HANA 的回收,或者 crdb 的 protect ts。当然,txn-id 作为中心化 allocator 本身会比较费。有一些粗粒度的方式,比如用 epoch 来批量做事务的回收。
本论文讲 GC 分为:
- Tuple Level GC
- Transaction-level GC
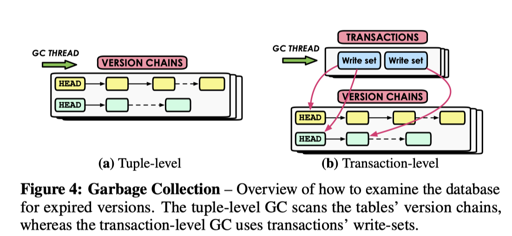
Tuple-level Garbage Collection
这里细分为 Background Vacuuming (VAC) 和 Cooperative Cleaning (COOP)。
VAC 会有后台的 GC 进程来清除。有一种草台的方式是这个进程检测有哪些版本进行删除,然后清除,这种方式对于比较大的库来说性能肯定拉了。文中提出了两种优化方式:
- 把对应的失败版本注册到某个 lock-free 的地方,然后清除进程直接清除这些版本
- 标注哪些数据块需要清除,然后跳过不需要 GC的那些块(PostgreSQL 的实现逻辑类似这样)
Cooperative Cleaning (COOP) 会在 N2O 系统中,遍厉的时候回收。PG 感觉因为 Tuple 位置是固定的,所以虽然 N2O,但是没办法这么做。还有个问题,就是这种回收如果没 touch 到对应的版本,就不回收了。Hekaton 碰到过这个问题,解决方式是加上了个 VAC。
最后,这节源论文介绍很少,但我个人意见是,这里 pattern 还是挺多的。比如 Compaction 的时候回收、标注回收的 Page、把回收的版本挂起来等等。
Transaction-level Garbage Collection
事务 track 对应的读写集,然后在单个事务或者一堆事务的 epoch 结束的时候做 GC。缺点是 track 空间,优点则是及时的回收。
讨论
Tuple-level Garbage Collection + VAC 应该是最常见的实现方法。增加 GC 的线程一般都能提升 GC 系统的性能,而 long-running txn 可能会影响 GC,这需要一些细粒度的 GC 实现。
PostgreSQL 和 MySQL InnoDB 都维护了事务的列表、最低和最高的事务水位,我们用 txn-table, active-txn-list, min-txn 和 max-txn 表示。
PostgreSQL 的 Vacuum
对于 PG 来说,它做的是一个比较复杂的多阶段的删除,用的 Tuple-level GC + VAC,具体可见 Vacuum 相关的材料(Lazy Vacuum, Full Vacuum)
- 对于事务的记录,PostgreSQL 维护在 clog 里面,这可以当作一个事务表。它根据事务 id 的顺序存在各个 Page 上,缓存在内存的 slru 中。当事务推进的时候,可以 Truncate 前面的事务记录来回收空间,推进系统事务
- PostgreSQL 的
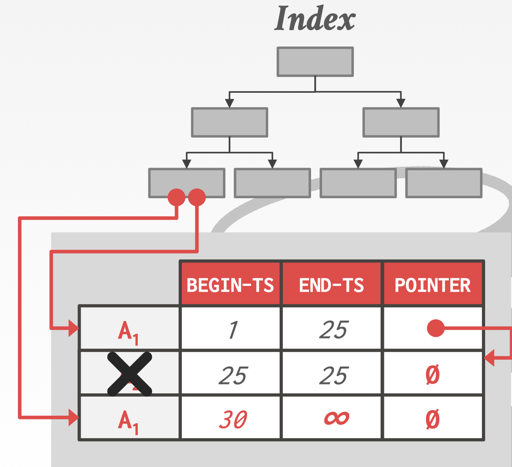
xmax如果被标记且 tuple 没有被上锁,那么这个 tuple 是被删除的,如果xmax小于min-txn,那这个 tuple 在逻辑上不会被任何事务看见,虽然物理上它还存在 - GC 过程中,PostgreSQL 会扫描所有 dead 的 tuple,然后清除它们,这里首先有一个 visibilitymap, 对应代码在
backend/access/heap/visibilitymap。如果某个 Page 被改了,有 Tuple 可能需要 GC,就会给 vm 记一下,然后这样的 Page 才需要被清理,这段过程中,索引的数据会被清除,如下面的图。 - 索引数据清除之后,Heap Tuple 的数据会被标记删除,但是 slot 上的位置还是会留着。
- 更新对应的 VM,移除 clog 等事务表信息。
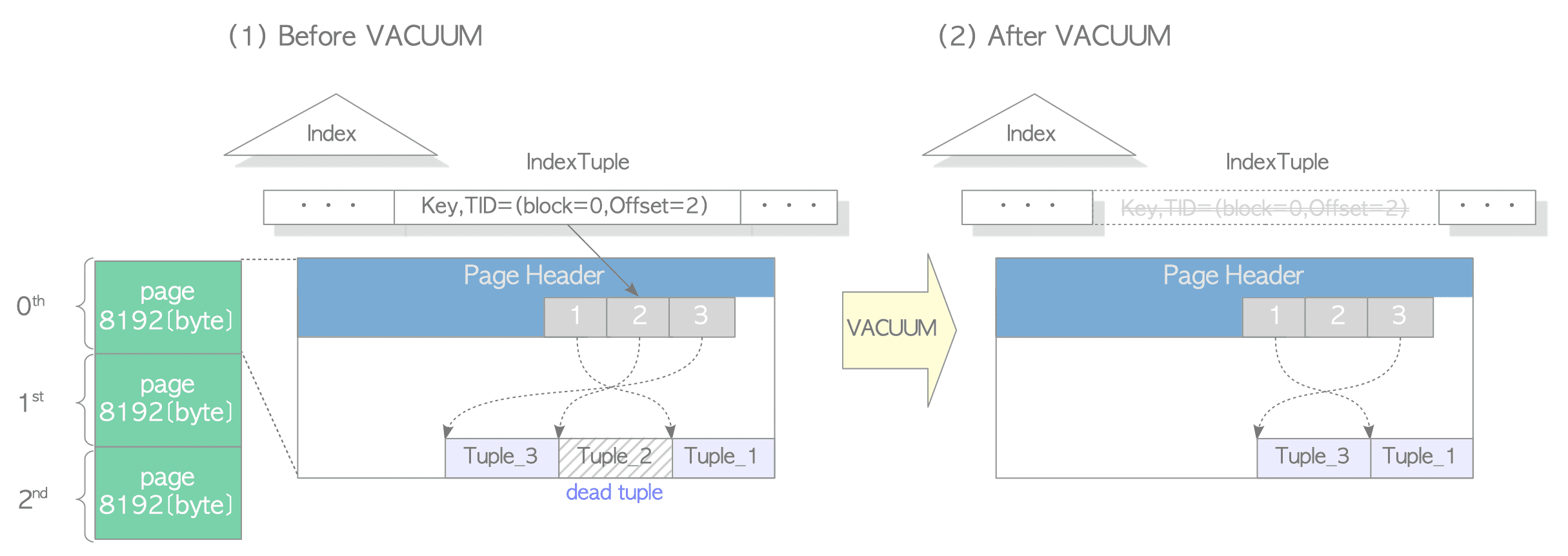
InnoDB 的 Purge
对于 MySQL InnoDB 来说,它的 GC 在 Purge Undo 里,Index Page 的回收我不是很熟悉,就不献丑了,前面已经说过了
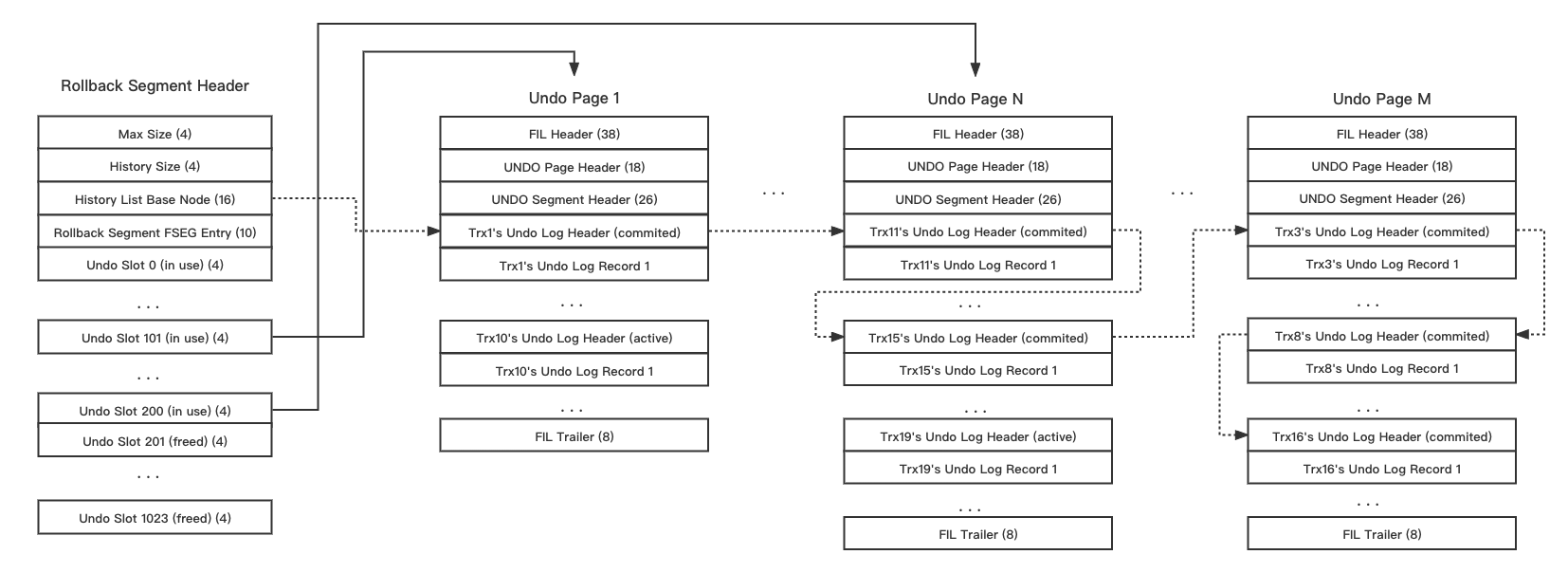
InnoDB 的 Undo 存在 Page 上,对这个 Page 的操作是需要写 mtr 和 redo 的。事务可以申请需要写 undo log,然后系统会给它分配对应的 undo page。同时,没有清除的事务会挂在 history list 上。通过扫描 history list,来回收这些版本。
其他
WiredTiger 的 GC 比较简单,在 Reconcile 的时候,每个 tuple 会把「所有事务都可见」的数据当作 base,把不可见的版本 GC 掉
Index Management
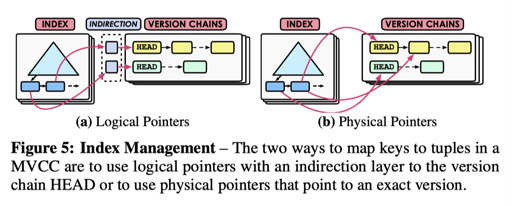
DBMS 的索引更新和实现有关,比如 MySQL InnoDB 有 Cluster Index 和 Secondary Index,然后可能还有 Covering Index。PostgreSQL 则是 index + heap table。
「更新」也是个很奇怪的事情,我们可以区分一下:
- 更新的字段跟索引没关系
- 更新了索引的字段
实际上,在 MVCC 系统中,很多索引字段被更新了,基本上要插入一条新的记录,同时旧的记录也要保留,这给 checkUnique 带来了不小麻烦。PostgreSQL 做了一个 LP_DEAD,来给这种被更新的索引做优化,andy 的 slide 也提到了这个问题:
论文引入了 indirection 和 direction 的方式:
- indirection 引入了一个间接层,这个间接层可以是 TupleID 或者 Primary Key. 相对来说,PrimaryKey 空间开销大一些,TupleID 维护则复杂一些。这个怎么理解呢?
- 索引存的是
<IndexKeys, PrimaryKey>,那么,根据 PK 可以找到唯一的主键。当然,如果 pk 很大,这里空间放大会有,如果 pk 是 int 之类的,感觉也没啥开销啊(
- 索引存的是
- direction 则是 PG 的方案,直接指向物理空间
讨论
作者评价如下:
The logical pointer approach is better for write-intensive workloads, as the DBMS updates the secondary indexes only when a transaction modifies the indexes attributes. Reads are potentially slower, however, because the DBMS traverses version chains and perform additional key comparisons. Likewise, using physical pointers is better for read-intensive workloads because an index entry points to the exact version. But it is slower for update operations because this scheme requires the DBMS to insert an entry into every secondary index for each new version, which makes update operations slower.
这里还有个 Index Only Scan 的问题,你看,对于数据 (a, b, c) 有索引 (b), 然后用户只 get b,本来是个很简单的问题,但你的索引上如果不维护 MVCC 信息的话,可能就寄了。
这里可以参考 PostgreSQL 的 Index Only Scan,借助了我们上一节说的 vm 系统:
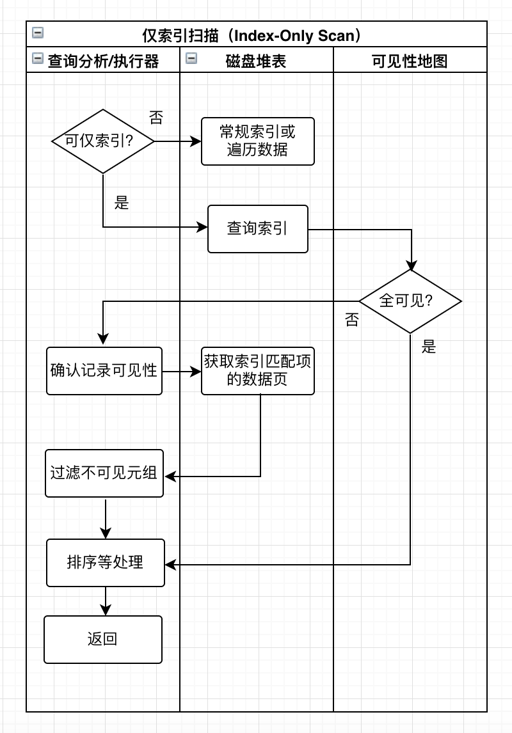
参考
PostgreSQL 部分:
InnoDB 部分:
MySQL · 源码分析 · InnoDB的read view,回滚段和purge过程简介 http://mysql.taobao.org/monthly/2018/03/01/
MySQL · 引擎特性· InnoDB之UNDO LOG介绍 http://mysql.taobao.org/monthly/2021/12/02/
感谢原论文:An Empirical Evaluation of In-Memory Multi-Version Concurrency Control