Constant Time Recovery in Azure SQL Database
传统的 ARIES 算法一直是「数据库的成人礼」,Azure SQL 之前用的是 ARIES 算法实现恢复。但是在有长事务的时候,恢复会比较恶心,特别是在 Undo 阶段。要拿到长事务修改过的每个地方给他嗯 Undo 回来,直到这个长事务 Log 开头,然后这些 Log 也不能 GC 掉,这个显然就很 waste of time。
Azure SQL 曾经遇到过一个大事务,改了一堆元素,恢复的时候花了 12个小时。后来 Azure SQL 在原先 ARIES 的基础上实现了并行恢复,让这个时间变快不少。不过这个可以看出,混合负载下恢复确实是成问题的。
此外,公司内部的数据库可以跑在一些核心硬件上,利用各种规模效应,来降低成本;核心服务甚至自己有一套硬件设备,但是,作为云上的 TP 数据库,可能需要考虑:
- 数据规模变大,可能会导致单机数据规模变大,恢复时间变长
- 云上硬件不一定好,增加了各种出现问题的概率
- 可能会有各种云上软件升级、调度之类的事情,导致出问题频率变高
论文在 SQL Server 中设计了 Constant Time Recovery(CTR) 的恢复机制,将 MVCC 和 Undo 结合,实现了常数时间恢复的恢复算法。然后进行了不少工程优化,包括小事务优化等,因为没有大事务的情况下恢复本身很快,所以它尽量只让大事务走这套机制。有了这个恢复算法后,带长事务的系统恢复时间大大减少了。
之前的设计模型
SQL Server 之前使用的是修改过的 ARIES,具体而言,它的数据模型是数据 + Log,数据和 Log 是分开存储的,Log 遵循 ARIES 的语义,如下图:
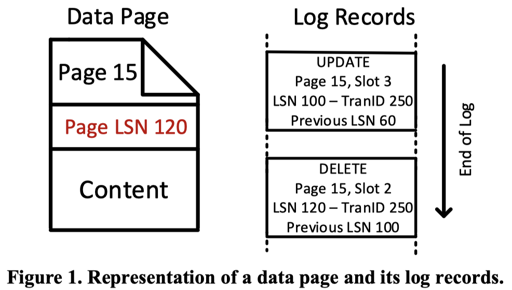
它的数据在内存中逻辑上是 MVCC 的,模型是 N2O + Main/Delta。这里它的 Delta 是一个 volatile 的结构,因为 crash 之后它认为不需要之前那些数据了,详见 Figure3:
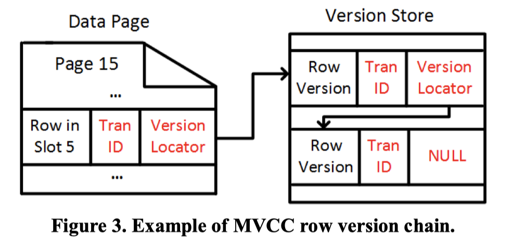
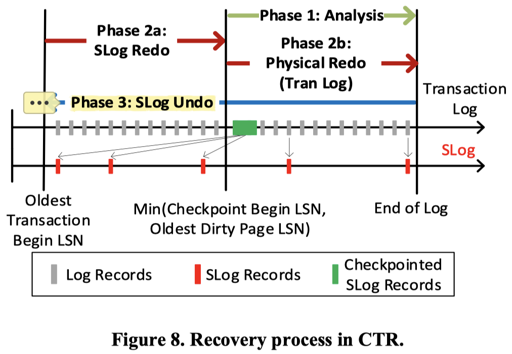
在系统中,它会走一个 Recover 的流程,类似 ARIES,但是有一些小小的区别,如 Figure2:
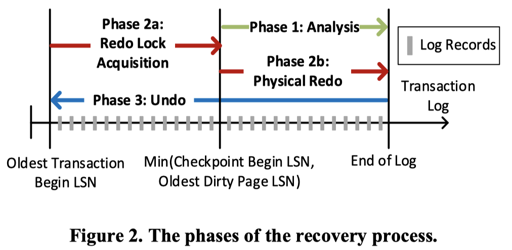
我们都很熟悉 ARIES 的流程,所以会看到 Phase 2a: Redo Lock Acquisition 这玩意比较奇怪,怎么会是呢?因为在 SQL Server 中,它在 Redo 完了就可以 Serve 外部系统了。那没 Undo 完的怎么办呢?Redo 的时候会占上该获得的锁,这个时候请求的事务会被这些锁 block 住,直到 Undo 完成。这相当于用 Phase 2a 的恢复时间换来了没有锁的各个 Tuple 的恢复时间。
Constant Time Recovery
这个算法目标如下:
- Database recovery in constant time, regardless of the user workload and transaction sizes.
- Transaction rollback in constant time regardless of the transaction size.
- Continuous transaction log truncation, even in the presence of long running transactions.
具体而言,这个算法把对数据库的操作分为了下面的类型:
- Data Modifications
- System Operations
- Logical and Other Non-versioned operations
Data Modifications
对于 Data Modifications,就是 Row/Tuple 的修改,由外部事务驱动。这里改动如下:
- 由一个 volatile 的内容存储版本,改成和 InnoDB 那样的持久化存储。这个估计实现就类似 InnoDB Undo 那套
- 版本链可以装 aborted 的版本,无论在 main 还是 delta 中。abort 的版本可以被忽略
- 每个 Row 上会有一个 TxnID,可以识别出它是否被 abort,来判断是否可读取
那么实际上,恢复的时候,只需要知道哪些事务 abort 了,并不需要手动 undo 这些。而多余的版本由 GC( Cleanup ) 来回收。
System Operations
这里通常是空间(Page) 的 alloc 或者 dealloc,SMO 操作。这些操作本身不那么带版本。它们其实不一定会被事务完成之后 undone,一般会有一些后台线程来回收这些数据。
Logical and Other Non-versioned Operations
这里操作包括 Logical 的操作,比如 Lock acquisition;或者是一些需要在 Recover 之前就 aware 的行为,比如修改 Catalog 的操作。这些操作是非版本化的,但仍然是可回滚的。CTR 使用了一个独立的 SLog 系统来承载这些操作。
Persistent Version Storage
这个我看了下,和 MySQL 的 Undo Space 没啥区别。这里通过 <PageID, SlotID> 定位具体的 Row,有点类似 PG HeapTuple 那套。然后修改操作反正也和 MySQL mtr 差不多。一些优化如下:
The off-row PVS leverages the table infrastructure to simplify storing and accessing versions but is highly optimized for concurrent inserts. The accessors required to read or write to this table are cached and partitioned per core, while inserts are logged in a non-transactional manner (logged as redo-only operations) to avoid instantiating additional transactions. Threads running in parallel can insert rows into different sets of pages to eliminate contention. Finally, space is pre-allocated to avoid having to perform allocations as part of generating a version.
还有一个优化点是 in-row version store:
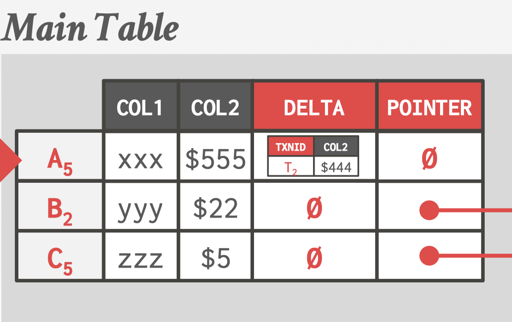
这里是一个 trade-off,将 row 空间放大和修改做到本地做权衡,这种方式能很好的优化 Deleted 的结构,在 main 标记删除即可。

当然,这里有个问题,就是这些空间放大会不会有影响。SQL Server 似乎会判断 Delta 会不会很大 和 这样标记会不会影响分裂 来决定是否做成 inline 的
Logical Revert
这里其实就是,对于 Data Modification,某种意义上说 Redo 完就行了,然后查的时候,MainTable 扫一扫,如果某个版本 abort 了就不要读它,就行了。如果最新的版本是个 aborted 的,那么可能有下图的优化:
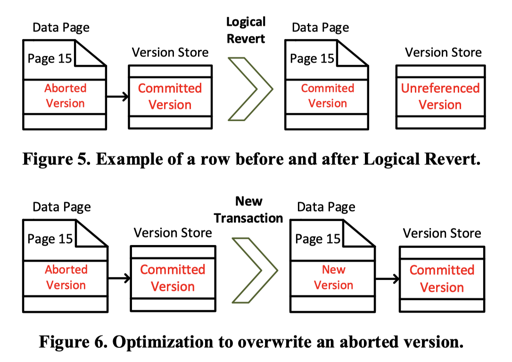
- Logical Revert,把 Version Store 的内容提到主表中,缩短链长。这由一个 System Transaction 完成,而且是只修改单个 Row 的操作,所以会非常非常短
- Overwrite: 新事务直接覆盖掉主表的 aborted version
Transaction State Management
一般事务内部会 keep 内存的事务表集合,之所以只要在内存中,因为这些可以根据 Log 全量构建。MySQL 的模型和 SQL Server 修改后差不多,但是它有 Undo 流程,所以不需要引入额外的结构。
SQL Server 因为会在 Main/Delta 中直接有 aborted 的结构,所以必须引入一个 aborted 事务表,来进行操作。这个 aborted 事务表的增/删也要落 Log。当某个事务 aborted,它会被加入表中,当它修改的所有 rows 不可见了(由 Cleanup 操作完成),这个东西会在事务表中被回收掉。
CTR 引入了一个 Aborted Transaction Map,来存储这些信息,ATM 还会随着 ckpt 存储下去,加速恢复:
CTR stores the aborted transaction information in the “Aborted Transaction Map” (ATM), a hash table that allows fast access based on the Transaction Id. When a transaction aborts, before releasing any locks, it will add its Transaction Id to the ATM and generate an “ABORT” log record indicating that it was aborted.
As part of the Undo phase, any uncommitted transactions will also be marked as aborted, generating the corresponding ABORT log records, and added to the ATM.
Once all versions generated by an aborted transaction have been reverted, the transaction is no longer interesting for recovery and can be removed from the ATM. Removing a transaction is also a logged operation, using a “FORGET” log record, to guarantee that the content of the ATM is recovered correctly.
读者肯定会有一个疑问,ATM 会不会疯狂膨胀,下一小节就是讲这个的。
Short Transaction Optimization
ATM 会带来两种问题:
- 任何一个小事务,如果 abort 了,要记 log;如果清理完了,还要记 log。相对原本 ARIES 来说,空间和延迟都会放大
- ATM 本身可能膨胀
总之,引入 ATM 让系统能够常数时间恢复,但是这会对性能造成不小的负面影响。这里引入了一个动态抉择方案:「只有大事务会走 CTR,小事务就走原来的,因为不影响」:
To optimize for both scenarios, CTR dynamically decides, based on the transaction size, whether a transaction should be marked as aborted, using the CTR mechanisms, or undone using the transaction log.
其实我觉得很合理,这么修改以后,整个算法不是「常数时间」了,但是解决了根本问题。
Non-versioned Operations
上面介绍了正常的 data-modification 版本化语义的操作,这里再来介绍一下 non-version 的操作,这里有下面对应的流:
- 逻辑上的锁和 SMO 操作,对 Page 的申请/释放等
- 对 Catalog、Schema 之类的系统的修改
- 对系统启动/关闭之类的 metapage 的修改
这些东西是非版本化的,SQL Server 抽了一条额外的流来优化。
SLog: A Secondary Log Stream
SLog is a secondary log stream designed to only track nonversioned operations that must be redone or undone using information from the corresponding log records.
本质上又是一个 Log 流存储系统,如下图:
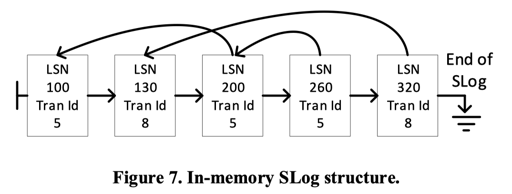
它们会存储到内存中,然后 Batch Flush 下去:
When a checkpoint occurs, all in-memory records with LSN ≤ the Checkpoint Begin LSN get serialized and written into the transaction log.
这个时候可以再度引入变更了的系统:
Leveraging System Transactions
这里还是同样的问题,全丢 SLog 本身太占内存了。这里把 Page 分配/释放丢给了原来的 ARIES 系统来做处理。
Redo Locking Optimization
原先的 SQL Server 为啥要 Lock 呢?因为它希望只对 要 Undo 的地方 Lock。那新的 CTR 协议里, RW 节点的恢复中,我这 SLog 处理完就没事了,那为啥还要 Lock 呢?这里做的非常工程化:如果是分布式的 RO节点,Replay Log,那它也不知道这个事务后来咋样了,所以还是要的。还有一些分布式事务的场景,也是需要 Lock 的。
这里引入了一些细粒度的锁,让这种场景下事务完成—通知变得高效,同时让这个锁是 Multi-Version 的,不影响一些不阻塞的读。
Aggressive Log Truncation
TBD
Background Cleanup
TBD