perfbook notes: defered processing
Data ownership
一种避免 Locking 开销的方式是,让数据属于某个 CPU/Thread,回到并行设计的策略,你会发现这个是完美贴合的:
Interestingly enough, data ownership covers each of the “big three” parallel design techniques: It partitions over threads (or CPUs, as the case may be), it batches all local operations, and its elimination of synchronization operations is weakening carried to its logical extreme.
这里有几种方式来做这些操作:
- data 全是线程自身的,不需要同步方案
- Data 来自一个共享区域,但是每个线程 manage 其中的一部分(想象一个固定 slot 的 bucket)
- function shipping,用一些方式来访问别的地方 own 的数据
- Designated Thread,特定的线程访问这些数据
关于 (1) 我们可以回顾 Counter 的方案,counter 数据是线程/CPU 自身的。只能自己单线程添加,但别的线程可以去 read。在 Linux Kernel 中,也有这种情况:某个 CPU A 在 interrupt disabled 的情况下,可以读取一些自己的变量;别的 CPU B 在拿到了这个 CPU A 的 per-CPU 锁的时候,才能读 CPU A 的这些变量;而 CPU A 在更新的情况下,需要 interrupt disabled + CPU A 的 Per-CPU lock。Per-CPU 的 memory allocator 也是一个很好的例子。
function shipping 类似 counter 那节的信号 counter。通过一些通信的方式,来获取(拿走)别的线程的数据,这通常可以引入一些 concurrent queue 或者 message queue 一类的东西。这里还会涉及到一个「哪些线程管自己的数据」这种问题。其实这个可以参考线程池之类的,走 queue 分配,tokio 应该有不错的博客描述它们的方案。
还有一种方式是 Designated Thread,即一个/多个特定的线程访问特定的数据。这个可以参考 eventually,最终一致性的 counter,即有一个 eventual 线程扫所有线程的 counter,把他们移动到 global。这个就用一个特定的线程来并发。这个思路在非 counter 也很常见,比如 rpc 可能会有特定的线程来扫数据,处理回调。
有一种提升并发的方式,就是将共享的并发同步点,变成私有的数据。
Data ownership is perhaps the most underappreciated synchronization mechanism in existence. When used properly, it delivers unrivaled simplicity, performance, and scalability. Perhaps its simplicity costs it the respect that it deserves. Hopefully a greater appreciation for the subtlety and power of data ownership will lead to greater level of respect, to say nothing of leading to greater performance and scalability coupled with reduced complexity.
Deferred Processing
对于并行系统来说,deferred processing 能减弱对同步原语的需求,并大大提升性能。这里会介绍:
- Reference counting
- hazard pointers
- sequence locking
- RCU
这里举了一个 Practical 的例子:
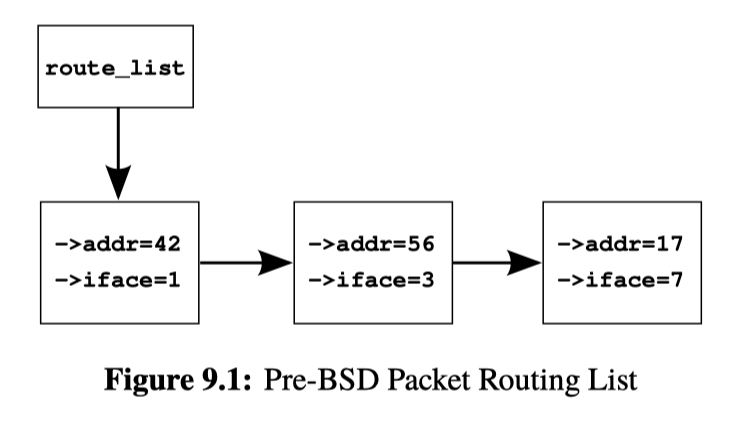
这里提供的是一个链表,链表有 lookup, add, del 的需求,单线程代码如下:https://github.com/paulmckrcu/perfbook/blob/master/CodeSamples/defer/route_seq.c
显然,网络栈相关的代码是不太会单线程的,所以需要并行方式来处理。
Reference Counting
rc 作为一个常见方案是很常用的。Arc 和 shared_ptr 都是一种并发的 RC,关于它们的语义,boost 有很精彩的介绍:https://www.boost.org/doc/libs/1_63_0/doc/html/atomic.html . 据传,RC 可以追溯到上世纪四五十年代里面计算机硬件管理的流程上,要用的地方贴个条,没条了才能关。
perfbook 给了一个不是很完善的实现:https://github.com/paulmckrcu/perfbook/blob/master/CodeSamples/defer/route_refcnt.c
RC 会需要对一个 atomic 的计数器,通过 faa 来增加/减少 counter。我们之前讲到 faa 的限制,实际上可以参考下图:
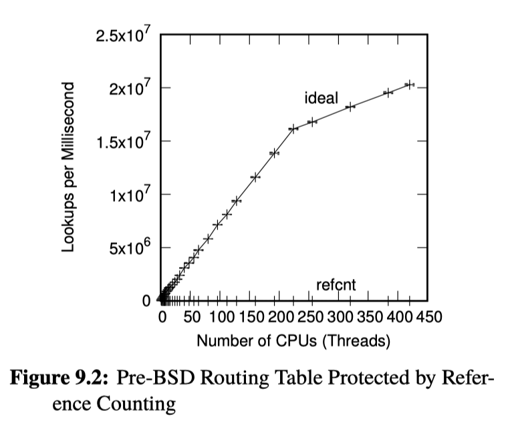
这里 ref-cnt 随着 CPU/Thread 增多,不太是 scalable 的。
Ref-cnt 还有个问题,就是说,我们假设有一块 RC 的内存,那这个 count 本身和 data 放在一起的话,可能是不合适的,所以一般实现上,控制块和数据块可能是分开的。这点也启发了后续的一些内容。
Hazard Pointer
hzdptr 思路和 ref-cnt 有点类似,不过:
Rather than incrementing an integer stored in the data element, instead store a pointer to that data element in per-CPU (or per-thread) lists. Each element of these lists is called a hazard pointer [Mic04].
这里 hazard pointer 遵守规则:
- 如果被 free 了,后续再也不会增加这个被 free 的线程的读者
- 不维护计数,而是每个线程维护一个 hazptr 列表(实际上就类似计数)。某个元素的引用计数 等于 所有线程的列表中,指向这块内存地址中 hazptr 的总量。
- Batch 访问,来减轻计算 (2) 中引用计数的开销。
下面是使用的时候:
- Hazptr 在访问的时候,都要记录到本线程的 hazptr 列表中,这里会调用 API
hp_record或者hp_try_record来注册。它会注册到本线程的列表中。在访问的时候,这里抽出了一个 grace 值,HAZPTR_POISON,实现为0x8,这个值用来表示 hazptr 的特殊值。当写入或者删除的时候,需要靠这个值表示「被删掉了」或者「状态未决」。 - 在摘除的时候,不会直接 free 内存,而会走
hazptr_free_later,注册到一个 free 列表中。hazptr_free_later同时有一个计数器,如果里面元素过多的话,会触发hazptr_scan,做真正的删除(这里体现了 Batch 操作) hazptr_scan会把全局的引用列表扫出来,然后和本线程的 free 列表对比,看看有没有被引用的,没有被 hazptr 引用就可以 gc 掉了。注意:free 列表中的对象在被 free 之后就不再会被引用,而且至多被 free 一次。
上述就是风险指针的流程,具体的实现会复杂很多,主要是有很多并发的小 corner case 要处理。
hazptr 代码可以参考:
- Folly: https://github.com/facebook/folly/blob/main/folly/synchronization/Hazptr.h
- perfbook: https://github.com/paulmckrcu/perfbook/blob/master/CodeSamples/defer/hazptr.h 和 https://github.com/paulmckrcu/perfbook/blob/master/CodeSamples/defer/hazptr.c
对上述这些 api 的使用,可以参考 perfbook 的例子:https://github.com/paulmckrcu/perfbook/blob/master/CodeSamples/defer/route_hazptr.c 。这里注意到,由于 hazptr 列表可能被修改,一旦遇上了 HAZPTR_POISON,这里就会重试。不过这也不是必须的,这里提到:
In certain cases, restart can be avoided by using link counting as exemplified by the UnboundedQueue and ConcurrentHashMap data structures implemented in Folly open-source library.
下面是性能相关:
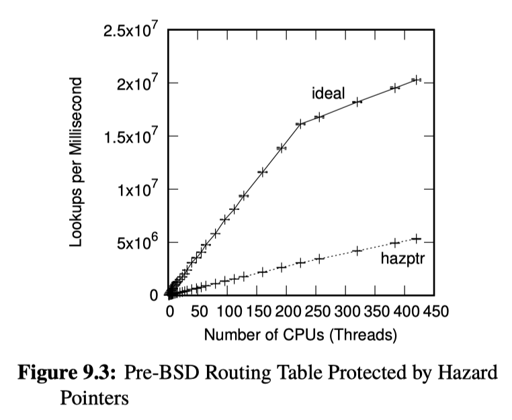
可以看到,由于利用了 Batching,hazptr 相对来说性能提升不少。
Sequence Locks
Sequence locks are used in the Linux kernel for readmostly data that must be seen in a consistent state by readers. However, unlike reader-writer locking, readers do not exclude writers. Instead, like hazard pointers, sequence locks force readers to retry an operation if they detect activity from a concurrent writer.
这个方式可以理解为有点类似在数据库 OCC Validation 中做的那样。它需要在数据上有一个对应的 seq,这里会允许多读者、单写者,并且读者如果是需要重试的,这个其实也可以对比 OCC。结论就是,和 OCC 类似,没有更新的时候,性能会非常好。
perfbook 上的 seqlock 有点邪门,它不关心「有没有读到一个一致的快照」,它在开始更新的时候会把 seq 设置为奇数,然后更新完成会设置为偶数。
对于读写,这里接口有:
read_seqbegin和read_seqretrywrite_seqlock和write_sequnlock

这个实现是非常简单的:https://github.com/paulmckrcu/perfbook/blob/master/CodeSamples/defer/seqlock.h 。它提供了一种不阻塞,而是重试读的「乐观读写锁」。
当然,用我们之前 Lock 的视角分析,这个方案需要更精细的设计,因为这里读可能会被不停的写入饿死,正如系统描述的:
Both the read-side and write-side critical sections of a sequence lock can be thought of as transactions, and sequence locking therefore can be thought of as a limited form of transactional memory, which will be discussed in Section 17.2. The limitations of sequence locking are: (1) Sequence locking restricts updates and (2) sequence locking does not permit traversal of pointers to objects that might be freed by updaters. These limitations are of course overcome by transactional memory, but can also be overcome by combining other synchronization primitives with sequence locking.
不过,它的好处是,没有写入者的时候,系统是 scalable 的。
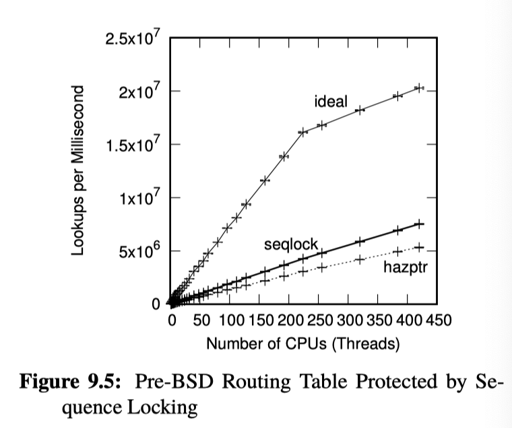
RCU
Perfbook 的作者是 RCU 的提出者,所以他花了比上面内容合起来嗨唱的篇幅来介绍 RCU 技术。当然,这也是值得的。RCU 实际上是有很多变体的,包括 Double Buffer 这种。
对于 RC,它把 faa 的巨大开销丢给了读者,让读者不 scalable;hazptr 减小了同步开销,但是线程需要记录相关的 ptr,读内存需要有 WRITE_ONCE 之类的接口来写入,这也可能有一定开销;seqlock 避免了读相关的 contention,但是写非常拉胯。需要注意的是,它们可以视为「在同一块内存空间上的并发」。这些接口在读的时候,也需要引入 memory barrier,来做同步。
RCU(read-copy update) 提供了 API,允许通过增大更新代价,来让读可扩展。书后面介绍了经典的 RCU、基本的 RCU 概念、内核 Linux API、RCU 的用处。
从一个指针开始的 RCU Introduction
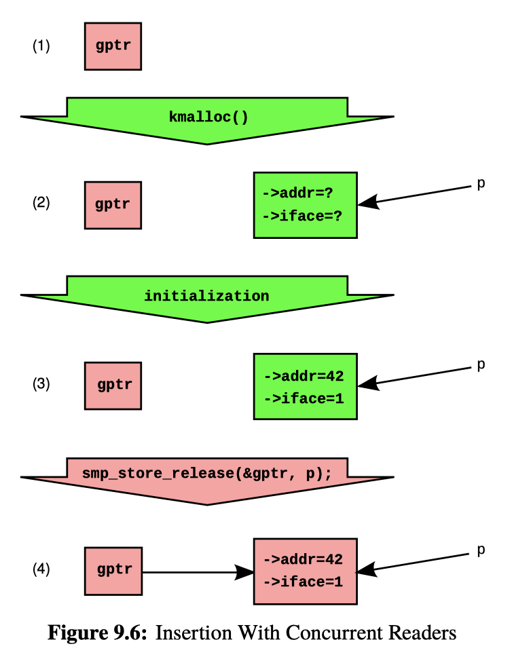
这里的模型是一个指向结构体的指针,然后实现 Insert 和 Delete。
Insert 相对于用 atomic 接口读写指针没啥区别,Figure 9.6 则是正常的 std::atomic 指针那套(这里用的是内核的各种接口,不过意思懂就行)。
Delete 就有区别了!区别在于,gptr 设置是很方便的,但之前可能有读者在读,所以这里涉及一个 GC 的过程。这里要「等待之前读者(pre-existing readers)完成,然后再 free」
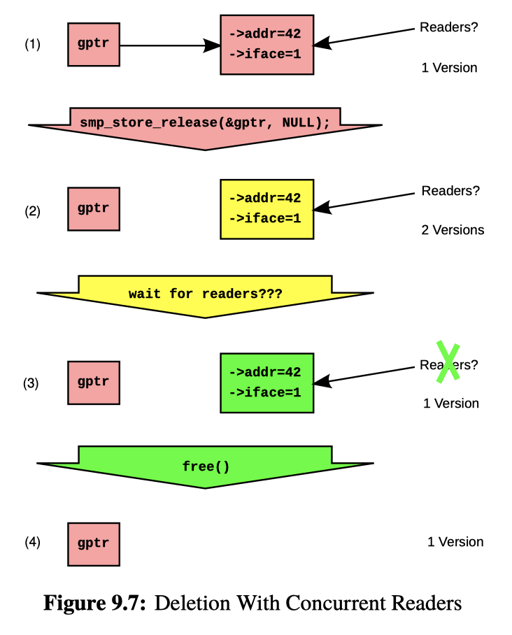
这里有个问题:如何「等待之前读者完成」?
- 首先想到的是 RC,不过我们之前介绍过了 RC 的缺点,hazptr 也有一定开销
- memory synchronization 比较昂贵,通常会引入 mb,所以用 register,比如查看别的线程的 PC。这种方法就太 hacking 了
- 等待固定长度的时间,等到理论上没有 reader 了。这个在实时系统可能有用,但是太 hacking 了
- 不释放了,leaking memory! 给我摆!这可以由 GC 来各种处理。
- 停止程序,直到 pre-existing readers 完成…这不是回来了吗?答案是,这里相对 RC 那种读者 GC,这里需要 变更值 + 同步 + 写者 GC。当所有线程完成时,RCU 完成了 grace period,可以 GC 了。
方案 (5) 和内核正好有一些地方匹配,还记得 spin_lock 可能会关中断吗:
The spinning threads will not relinquish their CPUs until they acquire the lock, but the thread holding the lock cannot possibly release it until one of the spinning threads relinquishes a CPU. This is a classic deadlock situation, and this deadlock is avoided by forbidding blocking while holding a spinlock.
这样系统就会类似一个非抢占的系统,那么,主线程要做什么呢?答案是 context swtich 到每个线程上,这样就能保证它们完成了,如图:
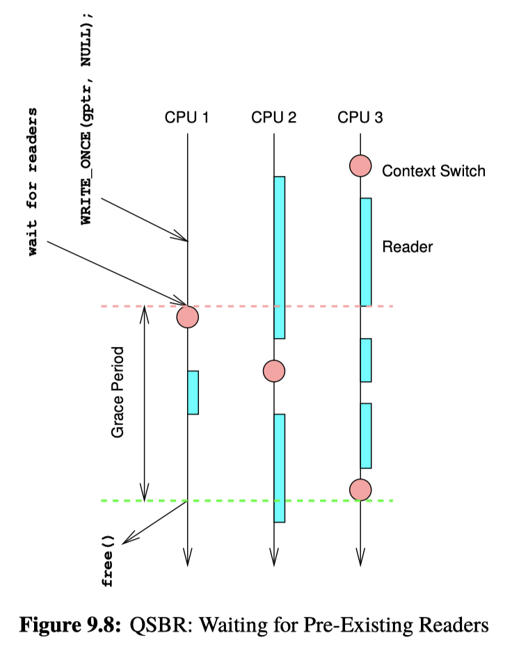
This approach is termed quiescent state based reclamation (QSBR) [HMB06].
所以,最简单的实现是,进 RCU 读区域关中断,删除的时候,需要 synchronize_rcu(),来 context switch 到每个 CPU 上,保证度过临界区。
那么,在这里,RCU 特点是,读可扩展,不用鸟写者。接口类似:
rcu_read_lock和rcd_read_unlock,在我们上面例子是开关中断synchronize_rcu, 保证所有读者完成,在我们上面例子是调度rcu_ assign_pointer()andrcu_dereference(), 发布指针。
RCU Fundamentals
这里是 RCU 需要依赖的基础:
- 插入:publish-subscribe mechanism
- 删除和内存回收:waiting for pre-existing RCU readers enabled deletion
- 并发更新:maintaining multiple versions of recently updated objects
Publish-Subscribe Mechanism
我们之前靠 atomic 更新指针来发布,实际上 RCU 需要这种机制,来保证「旧的版本不再被读到」。
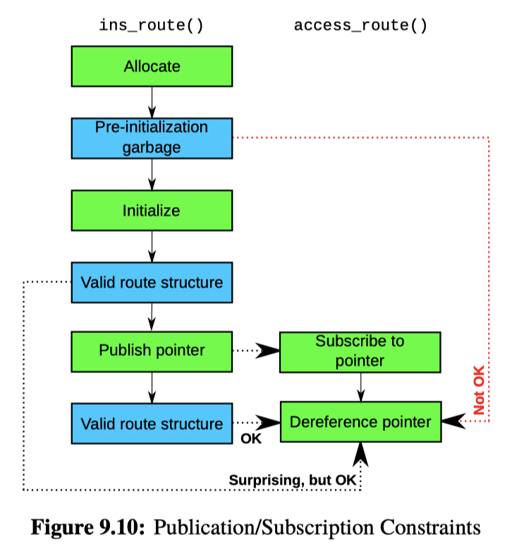
这里需要保证:
- pointer 的 pusblish,即
rcu_assign_pointer是原子的 - pointer 的 deref ,即 subscribe 是原子的,表现为
rcu_dereference
这里可以视作是一组发布-订阅的 api。
Wait For Pre-Existing RCU Readers
RCU 读区域被称为 RCU read-side critical section,由 rcu_read_lock 和 rcu_read_unlock:
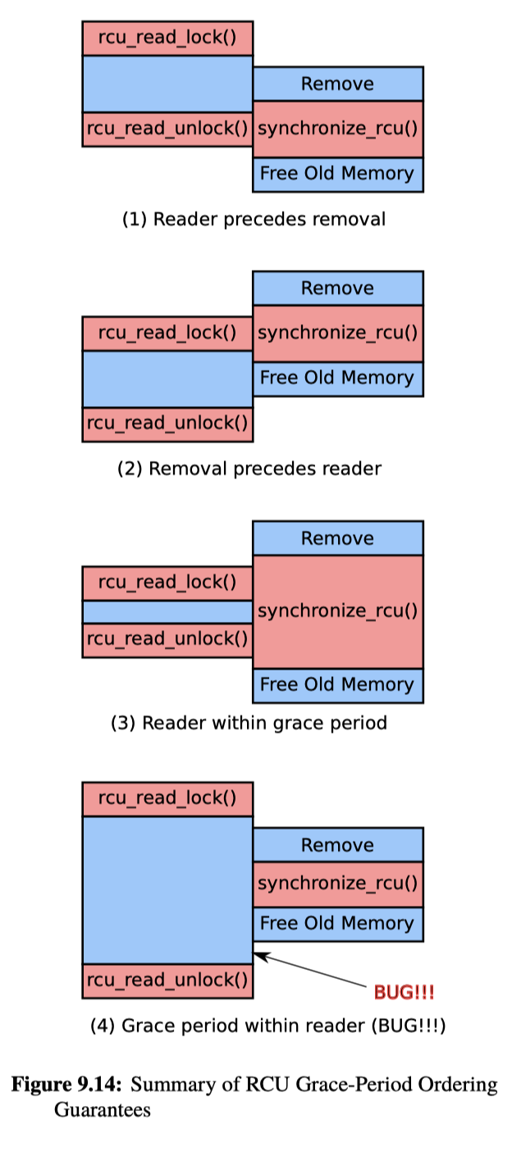
synchronize_rcu 会在发布之后,等待之前的读者完成。这里我们聊到了 context switch。而 DoublyBuffer 可能会用 lock 和 cv 来做,语义上是差不多的。
Maintain Multiple Versions of Recently Updated Objects
这里之前举的例子都是单个值的例子,实际上,并发的写也是可行的,只要能维护多个版本。
当然,这里可能要和别的方法结合,如图 9.15,这里 RCU 不会保证「读到一致性快照」:
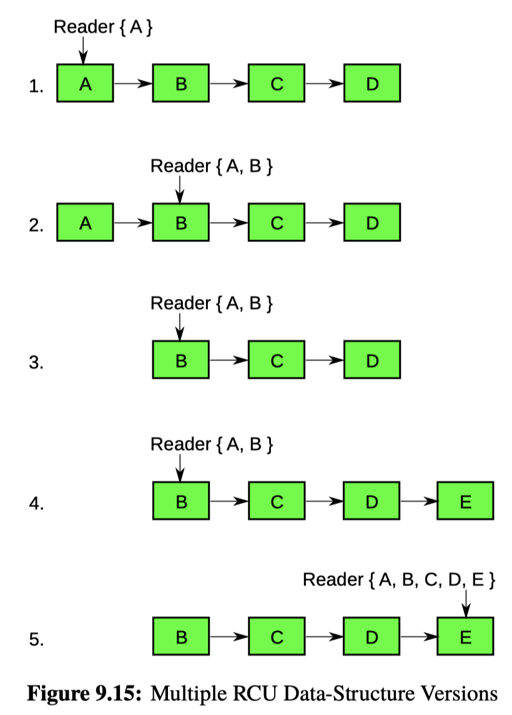
当然,很多 RCU 使用的情况是 point get,在 point get 下,这种情况通常是可以容忍的,如文章所述:
In summary, maintaining multiple versions is exactly what enables the extremely low overheads of RCU readers, and as noted earlier, many algorithms are unfazed by multiple versions. However, there are algorithms that absolutely cannot handle multiple versions. There are techniques for adapting such algorithms to RCU [McK04], but these are beyond the scope of this section.
Kernel 的 RCU API
Linux 并不是有一个 RCU API,而是有一组…Paul 在 LWN 写过:https://lwn.net/Articles/777036/
这里还提供了 callback 和 barrier 相关的内容,如:
The asynchronous update-side primitive, call_rcu(), invokes a specified function with a specified argument after a subsequent grace period. For example, call_rcu(p,f); will result in the “RCU callback” f(p) being invoked after a subsequent grace period. There are situations, such as when unloading a Linux-kernel module that uses call_rcu(), when it is necessary to wait for all outstanding RCU callbacks to complete [McK07e]. The rcu_barrier() primitive does this job.
除了经典的我们刚才介绍的一些 API,这里还有 srcu, s 即 sleepable,它使用类似 blocking api 来实现 rcu 机制。
此外,RCU 还有各种 list 有关的 API。
RCU Usage
https://lwn.net/Articles/263130/ 这里小标题特别好:
- RCU is a Reader-Writer Lock Replacement
- RCU is a Restricted Reference-Counting Mechanism
- RCU is a Bulk Reference-Counting Mechanism
- RCU is a Poor Man’s Garbage Collector
- RCU is a Way of Providing Existence Guarantees
- RCU is a Way of Waiting for Things to Finish
还有各种 performance 图,直接看就是了。
Which to Choose?
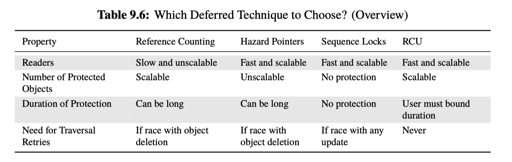
在 folly 的 hazptr 也写了一下这些具体的区别:https://github.com/facebook/folly/blob/main/folly/synchronization/Hazptr.h