Notes: BigTable
本文很短记录一下 BigTable 论文的一些内容。因为论文比较老了,而且感觉更加注重分布式,单机部分其实 SSTable 影响比较大,但是在今年已经遍地 RocksDB 了,看着多少有点老调重弹。
BigTable 提供了高吞吐量的批处理和及时响应的读,它似乎对非批的更新也有一定支持,比如在 Google Percolator 那里看到的。
BigTable 最早论文还是零几年,系统抽象和现在很多调调其实是反着来的(也可以说现在的调调是反他的):
- 不支持关系模型
- 将底层位置、分布、格式之类的暴露给用户
- value 都是 string
- 不支持多行事务
它在 chapter 3 描述了自己的数据模型,是一个一行多列多 ts 的宽表:
1 | (row: string, column: string, time: i64) -> string |
然后布局数据大概如下:
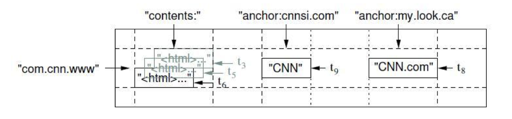
reverse(www.cnn.com) 有三个 CF,每个 CF 如上所示。关于原子性,内容如下:
对同一个行关键字的读或者写操作都是原子的(不管读或者写这一行里多少个不同列),这个 设计决策能够使用户很容易的理解程序在对同一个行进行并发更新操作时的行为。
BigTable 会按照行来分区,分区单位是 Tablet, 列里定义分为family:qualifier, 如上图,anchor 是列族,anchor:qualifier 才能具体的确定一个列。这里还可以在 CF 上指定一些权限、access 方式,比如只读等。
BigTable 的定义中还有个 ts。读会优先读取最新的 ts,然后 ts 本身可以用户指定,这里可以设置一些新的 ts GC 策略,比如保留 n 个版本的或者 n 天的 ts,BigTable 会帮助你做 GC。
回顾一下,这里可以把它的模型当作一个多层的、多行多列的模型。行中的列可以是稀疏的。
组件
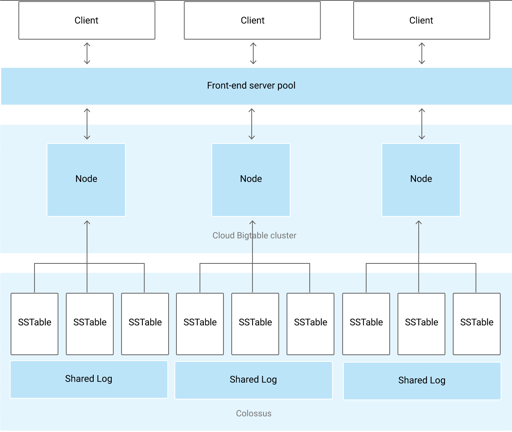
- BigTable 运行在一个多租户的系统上,可能和 HDFS、MR 等混部(论文没有描写,但是我非常好奇这个是怎么隔离的 orz..)
- BigTable 内部文件是 SSTable 格式的,这个格式我不会细写,看 Google 的 LevelDB 就差不多了
- BigTable 依赖 Chubby 做分布式锁服务,这个可以类似 Zookeeper. 它需要 Chubby 来保证至多只有一个 Master、存储 BigTable 的 Metadata;用来给 Tablet Server 探活等
除了上面这些 Building Block,BigTable 还有下列功能:
- 提供给用户的 SDK
- Master Server:给 Tablet Server 分配 Tablets、负责 Tablet Server 的成员变更和负载均衡、对 GFS 来 GC、负责建立表和 CF 的 Schema 操作
- Tablet Server:管理一组 tablets. 存储会下放到共享存储 GFS 中,所以存储不太需要 replica. (不过这里感觉没有考虑那种不太均衡的读负载带来的问题,比方说特别热点的读,写感觉估摸着可以靠创建 Bucket 来解决)。
实际上,对于 BigTable,它的 TabletServer 可以当成一个「无状态的存储层」,控制信息存储在 Chubby 等地方,数据实际落在一个存储层上。此外,这里的数据还是按照 Key 来进行 Range Partition 的。这里的 Key 可以类似的当作 RowKey:CF,为了保证单行事务,感觉同一个 Row 应该是要在同一个机器上的。
Tablet 的定位
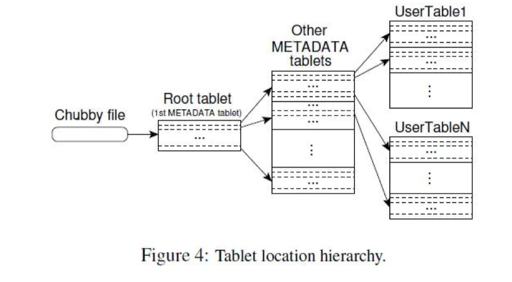
这里使用一个三层 Btree 的模型来定位到具体 Tablet 的分配,这些数据在 BigTable 本身是会存放在 TabletServer 上的(其实我感觉这些东西本身也可以分开存,比如这些路由信息存放在一些相对稳定不会被乱迁移的机器?)。客户端可以缓存这些路由信息,所以实际上访问这个表流量不太大,大部分都被 client 给缓存下来了。
Tablet 的分配
论文没有介绍 TabletServer 的负载是怎么样做负载均衡的,我们也无从得知。
系统依靠 Chubby 来保证整个系统只有一个 Master 进程。Master 进程要维护 Tablet 在 TabletServer 中的分配,同时要保证这个分配和上面的 Figure 4 的 Tablet 位置信息是一致的。Master 启动的时候,大致流程如下:
Master
启动
1 | 1. 在 Chubby 抢到 Master 对应的分布式锁, 表示 Master 是独占的。 |
运行期间
在任何一个时刻,一个 Tablet 只能分配给一个 Tablet 服务器。Master 服务器记录了当前有哪些活跃的 Tablet 服务器、哪些 Tablet 分配给了哪些 Tablet 服务器、哪些 Tablet 还没有被分配。当一个 Tablet 还没有被分配、 并且刚好有一个 Tablet 服务器有足够的空闲空间装载该 Tablet 时,Master 服务器会给这个 Tablet 服务器发送 一个请求,把 Tablet 分配给这个服务器。
出现变更的时候
Master 本身会管理 Tablet 在 TabletServer 上的分配情况。同时,也借助 Chubby 维护 TabletServer 是否活跃、Tablet 的具体分配情况。
TabletServer 本身启动的时候,也会在 Chubby 下面创建一个临时的文件,Master 这样就可以监听 TabletServer 的上线和异常下线。TabletServer 也可以记录
Split 和 Merge
某个 Tablet 或者 Region 可能会太大/太小了,需要 Split/Merge 了。这个时候 TabletServer 会和 Master 联动来做 Merge/Split,来完成 Tablet 的重新分配
Tablet 服务
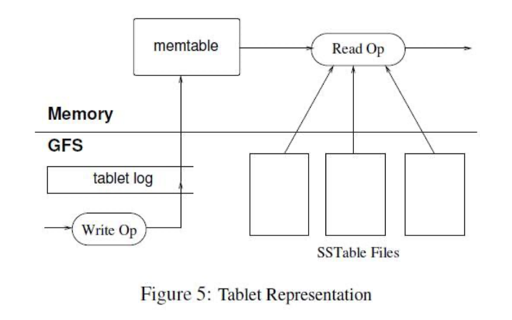
需要注意的是,这里存储都并非 LevelDB 的 Disk,而是一个分布式文件系统。这造成各种操作的 GAP 远比简单的 LSM-Tree 大。
SSTable 这里也要注意粒度问题。
优化
可以进行一些分割,将一些 CF 存储在同一个 SSTable。来提升局部性。METADATA 的数据以这种方式被优化
SSTable 指定一些特定的压缩方式:
很多客户程序使用了“两遍”的、可定制的压缩方式。第一遍采用 Bentley and McIlroy’s 方式[6],这种方式在一个 很大的扫描窗口里对常见的长字符串进行压缩;第二遍是采用快速压缩算法,即在一个 16KB 的小扫描窗口 中寻找重复数据。两个压缩的算法都很快,在现在的机器上,压缩的速率达到 100-200MB/s,解压的速率达 到 400-1000MB/s。
使用 BlockCache / BloomFilter
Log 和恢复流
上面几个都比较好推,下面一个相对来说特殊一些。一台 TabletServer 可能有成百上千的 Tablets,每个 Tablet 会有自己的 Redo log 流和 SSTable。但是都有写入的时候,如果往这么多 Redo Log 流写的话,对下层压力会很大。这里 BigTable 会把日志流聚合,写到 TabletServer 为粒度的日志文件。这让写日志快了很多。
这给恢复和迁移带来了一些麻烦。因为原本恢复逻辑大概是:
1 | 1. 找到自己 Region 对应的 Redo Log |
现在变成了:
1 | 1. 找到之前的 Log 流 |
Tablet 加速恢复
在调度的时候,Tablet 做 minor compaction,把未 Flush 的 Redo Log 刷到 SST,这个会恢复或者调度期带来一些小小的停写,但是能减少调度/恢复期间的时间。
HBase 对 BigTable 的实现
BigTable 论文在 OSDI’06 发布。而 Apache HBase 也在 06 年写下第一行代码。
HBase 被描述为一个持久的、分布式的、稀疏的、多维的表。按照 Column Family 被存储在不同的地方。它的体系结构类似 BigTable:
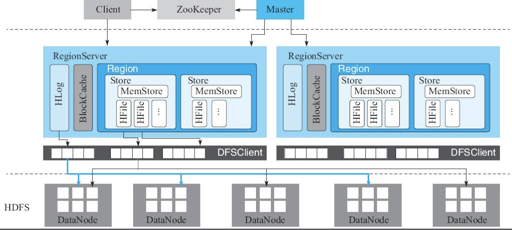
我们有下面的映射关系:
- 分布式文件系统 -> HDFS
- Chubby -> ZooKeeper
- Tablet -> Region
- TabletServer -> RegionServer
对于元信息,它存储在了特殊的表中: https://hbase.apache.org/book.html#arch.catalog 。这个表也会随着 Region 调度被调度。
而对于 WAL,HBase 会存放 WAL,行级别的事务只会写一条 WAL,来保证行操作原子性:https://hbase.apache.org/book.html#wal 。在上面的论文里,Google BigTable 支持单个 WAL 流,而小米的优化提供了多个 WAL,来打散 HDFS 串行写,优化写。对于读,这里会把 Block 缓存在内存的 BlockCache 中。
比较细的地方在于 Region 迁移/Merge/Split 相关的,Merge 和 Split 都依赖迁移操作,这里可能会将要操作的多个 Region 移动到同一个 RegionServer 来操作。
对于 Load Balance,原论文中没有提到,这里提供了一些相对复杂的策略,包括根据负载来迁移:https://hbase.apache.org/book.html#regions.arch.assignment
HBase 的目录在:https://github.com/apache/hbase ,服务器主要路径在 hbase-server 下的 master 和 region-server 的目录分别是
HBase 宕机恢复和原论文差不多,值得一提的是迁移相关的部分。这里可能受到 Region 调度和分裂的影响,所以做的相对细致很多。我们这里会介绍一下 HBase 管控相关的一些信息
HBase 的 ZooKeeper 中,会缓存如下的信息,具体我摘录一些调度有关的信息:
meta-region-server: 存储hbase:meta这张元数据表的 RegionServer 的访问地址region-in-transition: 在 Region 的迁移过程中,这里 RegionServer 会在这里变更 Region 的状态,Master 会 watch 对应的节点,触发更新hbase:meta表的映射。
客户端行为
client 会访问 zk 提供的 hbase:meta 表,这个表大概内容如下:
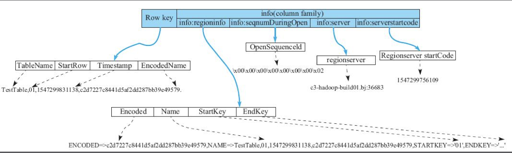
Client 会读取 meta-region-server 这个 ZNode,然后访问 hbase 的元信息,位置信息。访问到之后,具体的路由会被缓存在 client 上。这个内容其实是 <某个对应的 StartKey, EndKey, 分配在什么 RegionServer 的什么 Region>.
关键是访问失效,RegionServer 能够发现对应 Region 不在自己上面,Client 会清缓存然后重新访问 meta-region-server,然后更新缓存。
RegionServer
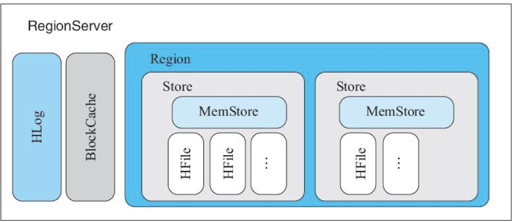
HBase 的写入会有一个 sequenceid, 根据 sequenceid 做一些日志推进。HLog 本身是按照时间之类的滚的,然后可能有复制节点在读取这些数据。当保证没有 Flush 的最后一个 MemStore 也大于某个 WAL 的 sequence 之后,这个 WAL 可以被放到别的地方。
这里的 WAL (HLog) 会写 WAL 文件,WAL 写入之后按照一定条件会切换到写新的文件,当 MemTable Flush 成为 HFile 之后,这里会把 WAL 移动到 oldWALS,等改被这个 WAL 文件没有被 replica 读,并 GC。
上述描述了 Minor Compaction 的流程。Major Compaction 这里是 Tiered Compaction,因为 HBase 本身适合读多写少的场景. HBase 对 Compaction 提供了专门的线程池做任务隔离(我脑洞一下,感觉 Compaction 任务本身也可以下发到别的机器上)。
Region 迁移/分裂/合并
基础: Procedure V2
这个好像是由国人 Committer 张铎老师完成的。这一部分我感觉相当复杂,会涉及 Master、Zk、RegionServer 三方的状态,所以比较复杂.
在这里,每个 Task 会被分成多个子任务,这里增加了一个 Procedure V2 的模块,然后会把任务写成一个 Task,分成多步来执行。这里可以看:
- https://www.slidestalk.com/HBaseGroup/HBaseProcedureV236713
- http://www.nosqlnotes.com/technotes/hbase/procedure-v2/
对于 Region 状态迁移,这里切分成了下面的状态,以写 MasterRegion 为分布式的 Coordinator,来推定最终的状态。当然实际上这个是很难的,我们可以对比一下 TiKV + PD (即基于 Multi-Raft 的方案):
- TiKV 分成了多个 Raft Group,每个 Raft Group 是一个自洽的小圈子
- Raft Group 会给 PD 上报心跳,根据心跳来决议最终的状态
- Region 本身,会有一个 Epoch,根据 Epoch 来决定最终的状态。PD 在做分裂的时候会发送一个 Task,然后发送 Region 分裂的任务,这个任务上调度会是幂等的
那么,TiKV 这个可以参考:https://pingcap.com/zh/blog/tikv-source-code-reading-20
那为什么 Procedure V2 这些这么复杂呢,因为它调度有好几部分:
- Master 的内存
- 存储的路由表,即
hbase:meta - RegionServer 的状态
这个可能 Master Assign 了一个任务,然后 RegionServer 执行了一部分,然后挂到 zk 上,这个时候 Master Crash 了,然后 Master 拉起来之后,可能要根据 Heartbeat 或者什么重建。这个时候,不过不一致,可能会返回 RIT 错误。
Procedure V2 框架会做什么呢?它会把 MasterRegion 当作 Coordinator, 决定最终的事务状态。然后如果状态不一致,它会尝试推进或者尝试 Abort,做了一个分布式的状态机。(感觉有点像 saga 或者 tcc?其实挺 Hack 的)
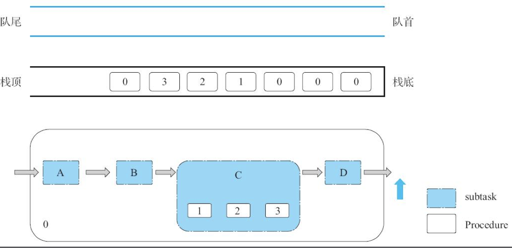
这个地方可以分成多组状态,然后实现了 rollback 等操作,来推进或者回退。
Region Split/Merge/迁移
这里可以看看:https://blog.cloudera.com/apache-hbase-region-splitting-and-merging/ 和 https://popesaga.github.io/2020/11/13/HBase%20%E5%AD%A6%E4%B9%A0%EF%BC%9ARegion%20%E8%BF%81%E7%A7%BB%E3%80%81%E5%90%88%E5%B9%B6%E3%80%81%E5%88%86%E8%A3%82%E5%92%8C%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1/#Assignment-Manager-V2
还是挺复杂的,要考虑:
- Procedure V2 的恢复
- 分裂、合并的策略,包括触发条件(负载均衡、查找到具体分裂的点),可以参考
StochasticLoadBalancer策略 - 分裂、合并的过程中,会从一台 WAL 涉及到2台 WAL,对应的 HFile 也需要迁移或者 GC。
最后的话
这里的 lessons 一节相当有意思,我觉得句句金句。这里说的大致内容还是说,分布式系统的设计要依赖简单的接口,在加入接口之前要想到用户怎么用,然后尽量把依赖和自己都搞简单一些,因为反过来说,很多软件本身很大,但是它的一些边角功能可能相对没那么靠谱;同时,要添加功能的时候,要想到用户可能怎么用,过多的功能和配置会把你的系统搞得很恶心,所以很多时候提供一个简单的 kernel 也挺好的(当然,在现今内卷和细化的环境下,大家也会做各种搅屎棍功能)。
论文的 lessons 还讲到一些 checksum 之类的问题,我觉得郭宽在知乎的答案其实是相对靠谱的:https://zhuanlan.zhihu.com/p/338893564 。
当初看 BigTable 之前,感觉里面的东西可能比较旧了,而且单行事务的模型可能相对 TiKV 或者 Spanner 那套已经比较 Naive 了,不过 BigTable 仍然很清晰的描述了怎么在共享存储上构建系统。一些比较细节的问题是:Region 成员变更、Region 的 HLog 流、HLog 切分、备份的时候出现新 Region 和旧 Region 不在同一条 HLog 上。这些问题现在做云上一些共享存储的系统还是会碰到的,也是可以参考的。
像一些新的系统可能会把 Log 接到一些异构的系统,比如 BookKeeper 之类的系统上。不过我感觉很多实现还是跟论文讨论的差不多的。
References
- OSDI’06 BigTable: https://research.google.com/archive/bigtable-osdi06.pdf
- BigTable 的翻译:https://arthurchiao.art/blog/google-bigtable-zh/
- HBase Book: https://hbase.apache.org/book.html
- 《HBase原理与实践》 胡争、范欣欣著。
- HBase Compaction: http://hbasefly.com/2016/07/13/hbase-compaction-1/