Database System Concepts 7th
前面使用部分不太感兴趣,直接从第十章开始看
Ep10 大数据分析
偏向大数据一些的基础架构。回头写。
Ep 11 数据分析
偏向利用 Ep10 拿到的结果再做一些分析。回头写。
Ep12 物理存储系统
首先存储是分层的,具体而言是:
- cache
- main memory
- flash memory(SSD)
- 磁盘存储(感觉经常在商业系统存一些冷数据)
- 光学存储器(类似 DVD)
- 磁带存储器
此外存储器还有接口,对应物理接口和一些协议栈:
- SATA 总线
- PCIe 总线
在协议上也有区别
- NVMe 协议
- SCSI 协议
此外,硬件接口也有区别,最常见的是 mSATA 和 M.2. 这个可以去 jd 搜搜,一看就懂。
具体可看:https://sjtu-sjtug.feishu.cn/docs/doccnfdnoqmgt6qqko5GM0tAKkh# 和 《深入浅出 SSD》这两个材料。
存储设备在互联网上可能以 SAN 的形式组织,这种形式提供了盘一样的访问接口,现在也有 ifiniBand 之类的方式。此外还有 NAS 之类的,提供网络文件系统的形式(我在家组了个 NAS 放片,爽的)。
磁盘
以 sector 为形式组织,受限于物理的访问,磁盘生命取决于保存和访问。对外提供的性能大概是:
- 2-20ms 的 seek time
- 旋转时间: 可能又是个位数 ms
- 传输:50-200MB/s
- sector: 可能是 512B
闪存
SSD 性质看看我之前介绍就行,in short,长一点的可以看之前那个:
- 我之前抄的:https://zhuanlan.zhihu.com/p/430451374
- 长一点的,感谢 SJTU:https://sjtu-sjtug.feishu.cn/docs/doccnfdnoqmgt6qqko5GM0tAKkh#
关于性能,可以到数千 MB/s, 同时有一定的并行读写能力。我感觉现在一般大公司内部都一堆 SSD 来 Handle 用户的写入
RAID
上大学的时候背过 RAID0-RAID5 应付考试,现在全忘光了,感觉再背一遍也没什么意思,就主要讲讲思路吧。
- 冗余以提高可靠性
- 这点对现在的人其实有点 confusing,为什么呢,现在的时代很多时候可能单机都不需要考虑数据的靠谱,靠 GFS Style 的备份之类的是更常见的 idiom. 跟群友讨论了下,ebs/GFS 这种感觉目前还是领先地位的,RAID0 RAID1 是可以用的
- 并行以提高性能
- 感觉这个在 SSD 上用处有限,HDD 上倒是好一些?
EP13 数据存储结构
这章感觉也很 trivial,就讨论了各种存储的结构:
- 架设在行存中的数据库
- 架设在列存中的数据库
- 内存数据库/NVM 数据库
行存的数据组织
传统的 RDBMS 会以 Block/Page 为粒度组织系统,本身 HDD/SDD 都是基于块的存储设备。它们的大小通常为 4kB/8kB/16kB。
假设 Page 大小是固定的。定长记录可以从 Catalog 里面知道长度,直接顺序存就行,变长记录可能需要一些特殊方式:
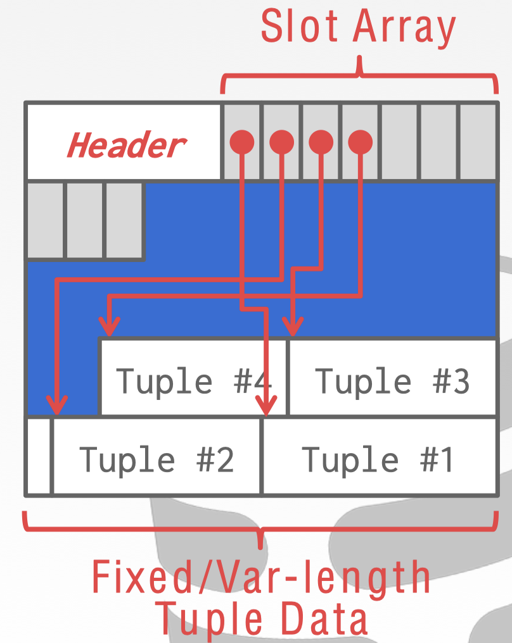
上图是 PG 中的处理形式,PG 的 HeapPage 单个 Page 内会这样组织数据。这里有个很清晰的问题是,在数据删除比较多的时候会怎么重新组织,这个时候它会在 Vacuum 阶段处理这些数据。
此外,MySQL 的 InnoDB Page 内部记录组织会更复杂一些。采用了链表+minmax+稀疏索引的形式。究其原因,InnoDB 对写操作支持要好很多,这些都可以算在写操作的支持里面。
大对象存储
MySQL 的 Page 要求 Btr 的 Page 会至少存储两个 record, 多的纪录会放到 BLOB 对象和 Page 中。
PostgreSQL 有 TOAST 对象,具体如下:https://cch1996.github.io/2020/09/22/postgres-04/
简单来说,TOAST 记录会放在 TOAST 表中。
文件记录的组织
- HeapFile 组织,记录放在文件的人和地方
- 顺序文件组织
- B+Tree 文件组织
- Hashing 文件组织
Record 的组织可以看我之前写的内容的 Tuple 部分:https://zhuanlan.zhihu.com/p/457605514
对于传统的 RDBMS,在 Stonebraker 的文章 中,表示虽然文件系统可能会有一些特殊的组织方式,不会按文件的格式顺序存放所有块,但是直接用文件组织的话,开销是比较小的。新时代随着 SPDK 等技术的发展,这个可能会有一点变化,但是程序员我感觉也不用太关注。
对于 Page 的组织,PostgreSQL 做的简单一些,会放在 Database Cluster 的空间中,PG 除了表文件,还有对应的 _fsm (空间空间映射)和 _vm (可见性映射),通过在 fsm 的标记找到可用的 Page,然后找到写入的 Page。
InnoDB 这个要复杂一些:
- Extent (区):连续存放 64 个 Page,希望提高 Page 分配的局部性
- Segment(段):存放不同类型的数据,比如叶子结点段、非叶子结点段。Segment 会向 OS 申请 Extent 大小的存储空间。
回收的时候,PG 根据 Freeze/Vacuum 和 _vm 的标记来回收,InnoDB 则会根据 Extent 的链表(XDES)来做回收
Partition
数据根据某个 key 划分成多个文件/空间。这种方式能够将单个库拆分、做冷热分离,但也会影响跟这个 key 无关的请求。
Catalog
一般 Catalog 可以全部保持在内存中,存储的时候要持久化。
Buffer Pool Manager
掠过不谈,反正就经典 Pin, Cache Replacement, Dirty 之类的。看 InnoDB 策略、ARC 基本就行了。
这里还有个写顺序和 WAL 的问题,略过不谈,反正 recovery system 可以讲。
本质上就是预测用户行为,然后丢缓存之类的。
面向列的存储
没啥说的,基本参考 abadi 的 Columnar DBMS,存储看我这篇:https://zhuanlan.zhihu.com/p/457889634
Main-Memory DB
感觉这部分讲的还是内存上的,行列都讲,就写的不是很清晰,没啥意思。
Ep14 索引结构
B+Tree 都看吐了,我一个字都不想写。就跟 Btree 比一下简单一些,Btree 省空间一点,但是没啥意义,很容易被抹平。
SSD 上的 Btree Style 索引:
- BwTree
- FDTree
- MassTree
我个人反正感觉这些东西反而很多都没用上,除了 ms 的论文,就 Ark 用了下 BwTree。不知道是这些结构本身不靠谱,还是 TP 系统和 Btree 已经是时代的眼泪了。
Btree 本身是为 HDD 那样的结构设计的,在 SSD 上,Btree 还是有优势的,因为内存和 SSD 还是有 gap 的,而且 Btr 本身会有一些很细的优化,比如 trxn 之类的,但是这套东西也还是很难实现的。以 BwTree 为例:
BwTree 做了:
- Mapping Table: 对 Node 或者写入的映射
- 写入类似 Log 的形式存放,Btree 也预留了空间
- 无锁
主存上的索引类似 ART.
还有 hashing 索引什么的,我感觉这些国内材料比较少,我自己也没写过,就不谈了。
LSM 是新时代的宠儿,因为实现比 Btr 简单,性能不错,写性能很好(设计者认为,读是很好优化的)可调整可预测,还有 RocksDB 什么的。这里还有些 WiscKey 之类的 SSD 友好结构,不过 WiscKey 设计也有一些问题,比如: https://www.skyzh.dev/posts/articles/2021-08-07-lsm-kv-separation-overview/ 。此外 LSM 虽然本身是一个写优化的结构,但是它的思路被放到了很多 HTAP 类似的读写混合系统里面。
这里还提到了 Buffer Tree,我觉得有点类似 FD-Tree, 把更新搞到一个缓冲区(Delta),然后先找 Delta 再找下面,Buffer 满了之后按一定策略来下推。
位图索引(我记得 PG 有这个),本身和列存那套差不多,当然这套东西也可以做到 Btree 上(防止一个 Page 放不下?)。删除记录可能在定位的地方产生洞,这里可以用一个 exist 的位图表示,不过我觉得 TUM 的 PDT 思路好一些,它用了一个偏移量的 B树(Position Delta Tree)来表述。此外:
- 如果只有某个值出现的比较多,可以单独给它一个索引
- 如果叶子结点发现可以位图压缩,那就用
上面这些优化我感觉都是看上去能省空间,但是实际情况有点 confusing 的,暂且不表吧。
空间结构:k-d-B 树。这名字有点复杂,可以先看 k-d 树:https://oi-wiki.org/ds/kdt/#_3 。k-d 树形态上是一个 Binary Search Tree,这里相当于提供了一个 Btree 的形式。
Ep15 查询执行
直接看这个就行,对应本章的笔记:https://zhuanlan.zhihu.com/p/349943902
Ep16 查询优化
统计信息参见:https://zhuanlan.zhihu.com/p/350255430
执行计划的估计可以参考:
- Selinger 的 System R 优化器
- Graefe Goetz 的 Cascades/Volcano Planner
我感觉上面 15-721 的 slide 写的很详细,目测 noisepage 参考 Columbia 抄了个 Cascade Planner。
关于连接顺序的,基本是个 DP。不过复杂度很高,基本是 $O(3^n)$, Selinger 那篇采用了 启发式 做一些优化,比如:
- outer join 最后 Plan
- Selection 先下推 (这个在一些 case,比如 A Join B, 选择在 B 的字段,且 JOIN 可以走索引的场景下,工作的不是很好)
- Projection 先下推
然后有一些 interesting order 或者 physical properties 的方式来施加一些限制。
Cascades/Volcano 框架则有下列的思想:
- 有一些被称为物理等价规则(physical equivalence rule) 的规则,来完成 transform。通常这些规则一般都是原子的,即不能被别的规则组合出来
- 这些规则是和代价估计结合在一起的
- memorization 来存储最优的形式
- 保存一些子结构
有一个很重要的东西是 Join Order 的选择,其实是这样的:
- 表多直接遗传算法了,比如 PG 那种,超过 12个表直接遗传算法
- 传统的 Selinger 那篇文章,只考虑了 left deep tree。有一些复杂的算法会考虑 bushy tree,比如 dpccp
有一个重要的话题是子查询的优化,可以把一些 EXIST 之类的改成 Semijoin,不过这个规则有点啰嗦,PG 有一块就是处理子查询,我看的人一愣一愣的…TUM 有一篇处理任意子查询的论文,这里有个二手博客:https://zhuanlan.zhihu.com/p/60380557
有一个比较重要的部分是物化视图,随着最近 OLAP 系统的火热,物化视图越来越热门。不过老大难的问题是物化视图的更新,最新的参考 Google 的 Napa 系统。老大难的问题是物化视图的选择(类似索引选择)和更新(实时性 — 写性能 — 成本),Napa 用一个 ts 来让你自己选。我们考虑下面的更新:
- JOIN: 相当于单条记录 Join 另一张表,然后增加/删除记录
- Selection/Projection: Selection 可能好处理一些,直接区间操作就行;Projection 可能要记录数据的来源/counting,在其上操作
- Agg: count/sum/avg 这些比较好处理,min/max 可能需要在有序集合上处理。维护 min/max 的插入很简单,但是要在上面处理删除是很难得。
还有一些 advance 的内容,15-721 也有列,包括:
- top-K 优化
- adaptive 的查询处理
- 参数化的查询优化
- 共享扫描、多查询优化
Ep17 事务
事务有着 ACID 的概念,这里我看到过介绍的最好的是 DDIA 那本书:
- A: 事务本身多个操作是可以原子性 abort 的
- C: 对外的状态满足某些一致性约束
- I: 可见性之类的东西受到约束
- D: 提交、掉电之后还在
串行化是假设事务一个接一个执行的情况,这种情况叫「串行化」。而并发控制组件(concurrency-control)会控制事务的访问。对于逻辑上等同于串行化的调度,成为「冲突可串行化」。同时,通过事务的读写关系,能定义事务之间的偏序关系。
这里( https://zhuanlan.zhihu.com/p/293533311)介绍了一种用图描绘冲突的方式,我觉得是一种相当好的定义方式。
这里调度还要考虑「可恢复(reconverable)」和「无级联调度(cascadeless)」:
- 可恢复调度指的是,A depends on B, A commit 了, B 没有 commit, 那么可能 B abort 了,A 就没法恢复了。
- A->B->C,C abort 了,那 B/A 需要级联 abort。OCC 中可能遇到这种情况,S2PL 应该不会。
然后这里介绍了一下隔离级别,可以参考我之前发的那玩意。隔离级别可以用 锁、ts、MVCC 或者组合来实现,这些概念其实是可以杂糅在一起的,具体还是看具体实现。
Ep18 并发控制
这节感觉是有点难度的,讨论了传统的各种并发控制,和一些杂项。然后讨论了一下 Online DDL 之类的。
协议部分见:
然后 Online DDL 基本是 快照读 + 排序 + 追增量。Percolator + F1 是在写的时候做了状态兼容,把追增量这部替换掉了,其实是差不多的。