Transaction, OCC and modern hardware
事务处理很多成果是在上世纪完成的,在本世纪初,关于事务的研究是相对较少的。占主导地位的是 2PL 协议,作为最标准的并发控制实现。但是,本世纪关于事务有着不同变化:
由于应用上的不同需求,相对上世纪,本世纪的应用有了显著的变化:显然,上世纪没有这么大规模的、高事务提交的互联网应用,现在的应用可能有数 M甚至数百M 的 qps,希望 ~10ms 的时间内完成一个事务。
同时,新时代也有硬件性能的飞速变化,这点主要体现在:
- CPU 单核撞上了功耗墙,但也拥有了更多的核心;
- 缓存大量提升,L3/L2/L1 Cache 变得大了很多;
- 存储也有同样的提升,SSD 取代了 HDD 成为了硬件的宠儿,NVMe 等协议提供了助力,同时也有 SPDK 等 Bypass 的技术;
- 同时,分布式事务的实现变得更加重要了。
应用侧的需求、硬件的提升甚至软件栈变薄,给事务处理带来了一些变化。然而,最著名的靠谱开源数据库 MySQL、PostgreSQL 使用的还是上世纪九十年代的模型;比较常见的 Google Percolator 等模型在单机事务上还是比较简单的;H-Store/VoltDB 的方式似乎没有很主流的被采纳。
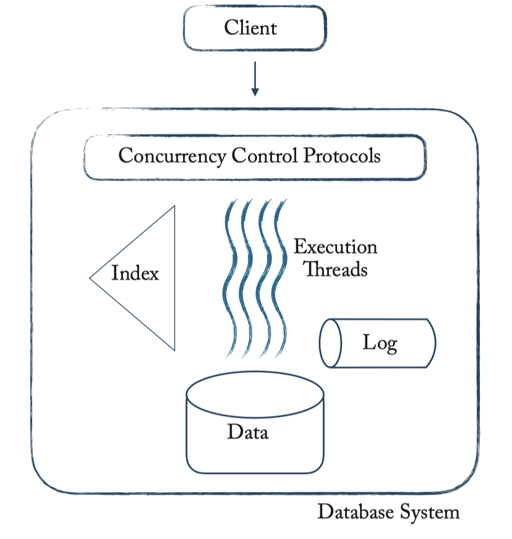
我们可以套用到 MySQL 这样传统的 RDBMS 中:
- ARIES 那样的 Undo Redo Log
- MV2PL, 采用 Delta Space 存储变更的版本
- 采用 Btree 索引
- 并发本身和 2PL 有关,模型是线程(PG 甚至是进程),然后本身 Btree 之类的也会有一些 Latch Protocol
它可以很方便的做一些内部的优化,比如说:对于 counter,它可以维护计数器锁,使用 Page 相关的逻辑物理日志,来达到细粒度的更改。
同时,并发控制可以分为乐观的/悲观的,大概划分如下:
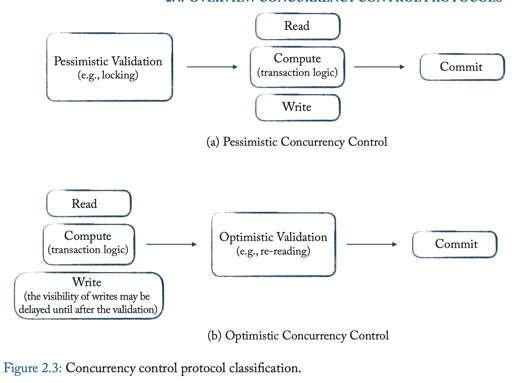
OCC 本身是一种乐观并发协议,1981 年 <On Optimistic Methods for Concurrency Control> 中被提出。在近十年中,因为模型的变化,使用者认为,它在低数据 contention 的情况下会有良好的性能。
本文主要关注并发控制部分,并主要关注单机事务。
On Optimistic Methods for Concurrency Control
本论文是 OCC 的提出,在 1982 年发表在 TODS (Transactions on Database Systems) 上, 本论文提出的方法是基于时间戳的方法,并且提出了基本的模型。需要注意的是,类似 T-Tree,当时 Memory/Cache 之类的模型和现在也略有不同。
Optimistic 表示:
Most current approaches to concurrency control in database systems rely on locking of data objects as a control mechanism. In this paper, two families of nonlocking concurrency controls are presented. The methods used are “optimistic” in the sense that they rely mainly on transaction backup as a control mechanism, “hoping” that conflicts between transactions will not occur. Applications for which these methods should be more efficient than locking are discussed.
作者认为,事务本身因为访问盘的 latency gap 和 多核心等原因会需要并发执行,而 2PL 有几个问题:
- Lock 会给读或者不产生冲突的事务也带来开销
- Deadlock
- Lock 需要等待事务执行完毕才能释放
- Lock 只有在 worst case 才有用
也就是说,可以手动推导出下列的前提:
- 正在执行的事务本身需要的数据数量占数据总量较小
- 修改热点概率较小
在这个前提下,可以使用 OCC 的方式,来高效执行,并且避免死锁。当然,死罪可免,活罪难逃,遇到活锁的情况下,可能可以退化为悲观的事务等方法来处理(Doug Lea 在设计一些数据结构提到过类似的方法,提供 global lock,如果重试失败集采,那么使用 Global lock)。同时,这里读事务会几乎不带来开销。(What about MVCC?)
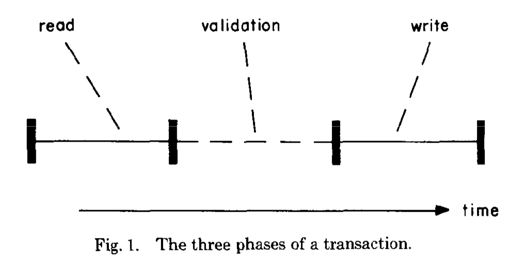
这里切分为了 read/validation/write 三个阶段,值得一提的是,这里大部分还是 read 在内存操作,write 阶段切换一下 read 的时候的指针,然后 read 本身读都是原子的。因此作者认为,write 本身是非常快能完成的。文中表示了 Write 阶段很快而且是串行的。
Read/Write 阶段
这里需要提供下列的原语
1 | create -- 创建对象, 返回 handler |
然后,需要在 read 阶段提供 tcreate , tdelete, tread, twrite 等方法,使用上面的原语来操作。同时,事务开始和结束分别使用 tbegin 和 tend 操作。事务的内部结构里保存了 WriteSet 还有 DeleteSet、ReadSet,同时有一个 copy 数组。具体操作就读的时候拷贝到 copy 数组,创建删除之类的处理好对应集合,把 handler 丢到 Set 中。
当 Validation 完成之后,这里逻辑就基本上是把 WriteSet 和 DeleteSet 去 apply。然后我这边截取一段假设,这里论文使用了串行 write,因为:
Note that since objects are virtual (objects are referred to by name, not by physical address), the exchange operation, and hence the write phase, can be made quite fast: essentially, all that is necessary is to exchange the physical address parts of the two object descriptors.
Validation Phase
这里只描述了 Serializable 的验证,论文使用了时间戳有关的协议。对于一个给定的事务 T(i), 都能找到一个 t(i) 来表达事务执行的时间。事务读写的时候,需要保证 t 的顺序,即是事务的顺序。那么,这里可以给到一些条件,对于 t(i) < t(j)
一: T(i) 在 T(j) 读阶段之前完成了写阶段
应该不需要怎么理解,很 trivial
二:T(j) 在进入 Write Phase 之前, T(i) 完成了 Write Phase ,且 WriteSet(i) 和 ReadSet(j) 无交集
这里后来怎么改都行,但是不能读到之前改的地方
三:T(i) 的 WriteSet 和 T(j) 的 ReadSet / WriteSet 都没有交集。且 T(i) 在 T(j) 之前完成 Read Phase
这里有点点复杂,是说 T(i) 的没有影响到 T(j) 的事务。
下图也同样说明了这三条规则对应的时间范围:
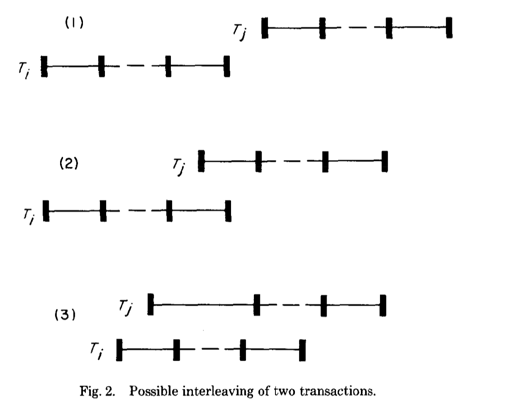
Rule3 还是相对复杂一些,关于这点可以从 CMU 的 slide 里面偷一下图:
Transaction Number
对事务 T, 需要找到对应的时间戳,这里选用的是 Validation 的时间戳。
Here we use the simple solution of maintaining a global integer counter tnc (transaction number counter); when a transaction number is needed, the counter is incremented, and the resulting value returned. Also, transaction numbers must be assigned somewhere before validation, since the validation conditions above require knowledge of the transaction number of the transaction being validated.
这里也讲了为啥不在 Read 或者 Begin 的时候拿时间戳。如果 t(i) < t(j), 但 T(j) 更早进入 Validation,那就需要等待 T(i) 了。在 Validation Phase 拿到 TS 能自然满足这个条件
一些工程考量
如果读事务很长,那么,它很有可能 Starve,这里解决方式是留一些事务的 WriteSet 到内存中(类似 MVCC 了):
We solve this problem by only requiring the concurrency control to maintain some finite number of the most recent write sets where the number is large enough to validate almost all transactions (we say write set a is more recent than write set b if the transaction number associated with a is greater than that associated with 6). In the case of transactions like T, if old write sets are unavailable, validation fails, and the transaction is backed up (probably to the beginning).
此外,这里活锁导致问题的时候,可以用全局锁或者降级到悲观的方式来处理。
Serial Validation
论文中,Validation Phase 和 Write Phase 都是串行执行的,Read Phase 是并行执行的,但是后续会串行 Validation 然后写(我感觉这个也太怪了…)。记 tnc 为 全局事务counter,那么有:
1 | tbegin() { |
上述情况很容易验证是合法的,因为 tend 整个就是串行的,(3) 之所以不需要是因为进这个阶段就读写完了。
对于单核系统+验证/写入本身会非常快的场景,上面差不多就够用了,但是多核系统或者要 I/O 的话,可能我们就希望并行处理了。
有一种优化的方式是,进入临界区之前,读一下 tnc, 作为 midTn,然后先做一次验证。读取 tnc 之后,后续的提交事务 ts 都是大于 tnc 的。这里先模糊做一次 [StartTn + 1, midTn] 内的检查(是开始到现在已经提交的事务),再进临界区的时候,再拿到一个具体的 FinishTn,做验证。
这里的核心逻辑就是检测 [StartTn, FinishTn] 这个 Window 中的写没有和本事务的读冲突。
因为查询没有编号,所以这里不需要给查询作 tnc increment.
再回顾一下这一段,这里本身把 Validation 串行操作了,其中关键的部分在于 tnc 的读取和增加,再之前的 Rules 中,Rule1/Rule2 是显而易见的,这里通过 tnc 递增和验证区间来保证;拿到这个 id 之后,再去检查读写。
Parallel Validation
在这里,validation 阶段将会变成并行的。这里将会使用所有的三条规则。
关于 Rule2, 验证规则和之前是相同的,对 Rule 3,这里需要维护一个 active 事务集合。那么,validation 如下(这里分别记 < 和 > 为临界区的开始和结束)
1 | tend() { |
显然,这里是没问题的~
概念补充
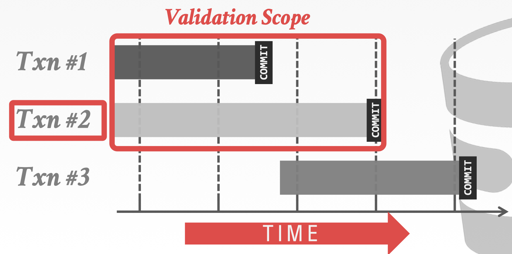
这里有一个 Validation 顺序的问题,实际上,原论文描述的就是一种 BOCC(Backward OCC) 的算法,当事务进入 validation 阶段的时候,它会与之前进 Validation 的事务验证。
Backward Validation: Check whether the committing txn intersects its read/write sets with those of any txns that have already committed.
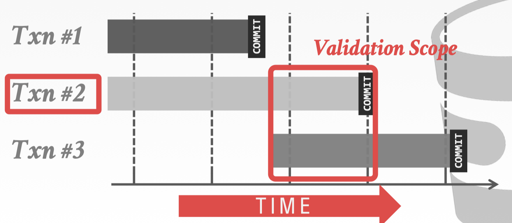
Forward Validation 在提交的时候广播自己的 WriteSet,让读取的事务来做一些判断。读取事务可以当即判断,也可以 Buffer 一些,最后一起判断。
Forward Validation: Check whether the committing txn intersects its read/write sets with any active txns that have not yet committed.
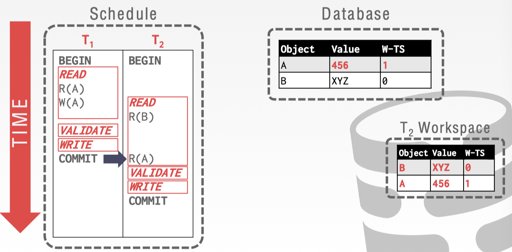
此外,我们还可以考虑基于版本的 OCC,每个数据项和一个写入版本相关联,读取的时候拿到一个时间戳,成功提交的事务会带一个唯一的时间戳写入。验证的时候通过 ts 比对来进行验证:读取的 w-ts 和现有的 w-ts 一样,就没啥问题,这里 15-445 slide 演示了相关的例子。
具体一些细节可以在: https://wangziqi2013.github.io/article/2018/03/21/Analyzing-OCC-Anomalies-and-Solutions.html 这里看看。
OCC 评估
<Main Memory Database Systems> 里面描述了一种现状:关于性能,实际上大家各执一词,有的时候 Benchmark 的结果甚至是相反的。我们可以大概知道 OCC 在低冲突的情况下,有相对好一些的性能。我可以大概复述一段这个车轱辘话:
有的比较认为,悲观事务 Blocking (wound-wait?) 优于 悲观事务重启 (wait-die?),但一些研究有相反的结论。在另一些对比中,乐观并发模式比 基于锁的并发模式更优,有的则相反。有一个比较令人信服的结论由 Agrawal 等人的出,他们表示,在低数据竞争的场景下,乐观并发性能更优,但冲突增加的时候,由于 rollback 和 restart,出现了更高的冲突率。
<Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores> 这篇论文发表于 VLDB’14. 本身是描述 OCC/2PL/TS/MVCC/H-Store 等协议在 1000核心的模拟器下并发的。采用硬件寄存器来并发有比较优的效率:
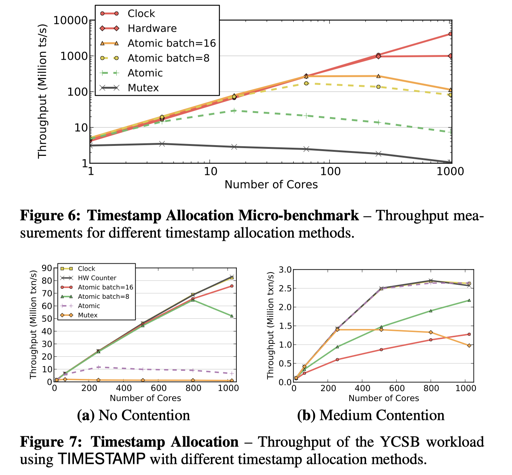
需要注意的是,这里的 counter 肯定不是线性增长的,atomic counter 可以参考下列性能表:
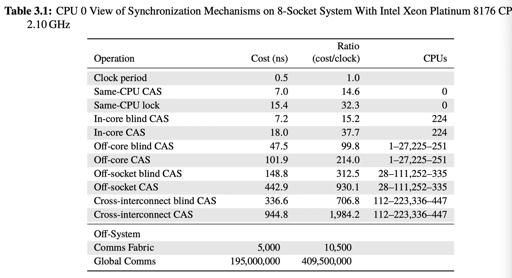
这篇文章显示,OCC 的拷贝数据、ts 申请等方式会带来不小的瓶颈。这里的问题是能否 Partition(counter 层次的 Partition),更高的性能可能导致一些语义上的变化,比如不原子递增的 counter,甚至类似 snowflake 那样带有 id 的 counter。
本文中,OCC 性能受制于时间戳分配、拷贝到 private space、高冲突下的 abort。
我觉得这篇文章有一定的参考价值,但是意义没那么大,因为很多东西和实现细节关系很大,本身是有很多优化和商榷空间的,文章中瓶颈在 timestamp 分配上也是可以理解的。
MVOCC
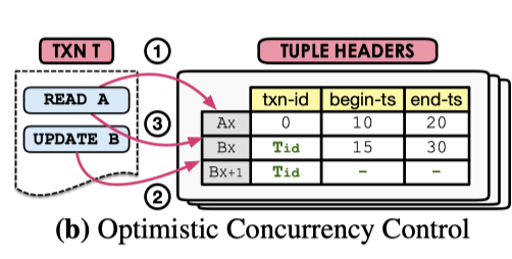
对于 MVOCC 而言,可以给每个数据带上一个 begin-ts 和 end-ts,这里就不用拷贝事务的 private space 了,取而代之的是 GC 问题。
还需要注意的是,MVCC 并不是万灵药,它不会在任何场景都能提供优化。它提供的更像是一种对抗 读/写混合的防颠簸。
在 benchmark 中,论文测试了下列三种负载:
- read-only (100% reads)
- read-intensive (80% reads, 20% updates)
- update-intensive (20% reads, 80% updates).
论文里记号如下:

在低竞争的测试下,MVOCC 有着尚可的性能,报告如下:
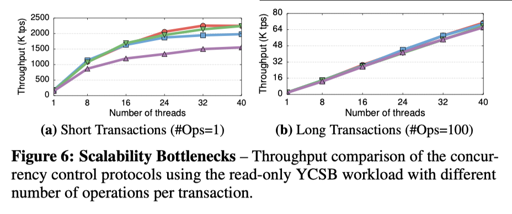
很符合直觉的,在高数据竞争的情况下,有如下 case:
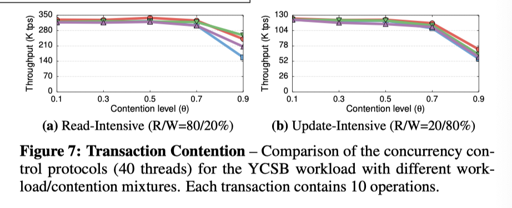
再混合负载下,给出一定写,增加读,MVOCC 本身受读事务干扰较小,而随着写冲突增加,它可以立马性能下降给你看:
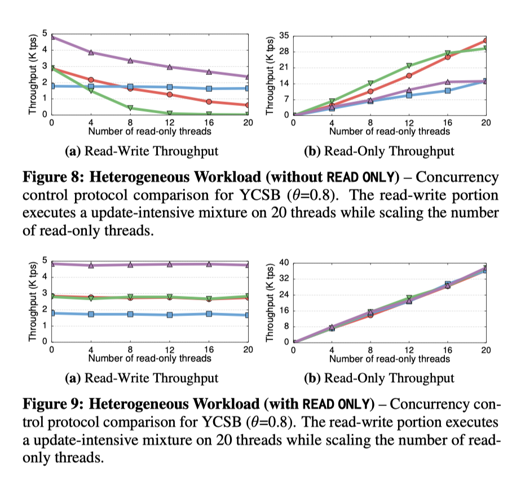
论文还有 TPC-C 测试等,如下图:
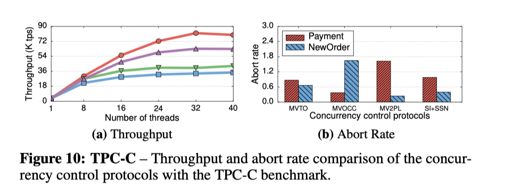
笔者认为,本文给的策略还是相对靠谱的,感觉比较靠谱的是类似 Hekaton 那样,在同一套模型上支持乐观 + 悲观的形式,方便适合各种何样的负载。
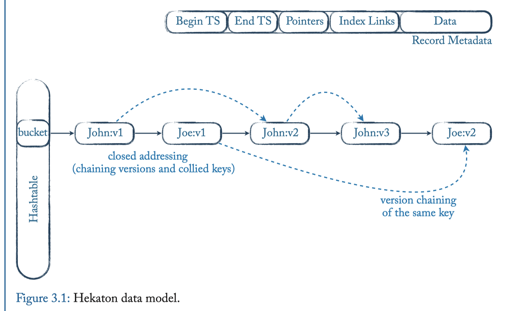
Hekaton
本协议是一个基于验证的协议,本身是 MVCC 的. 论文乐观的假设了碰到的冲突的事务都会成功,并且用无锁并发来实现这样一个模型:
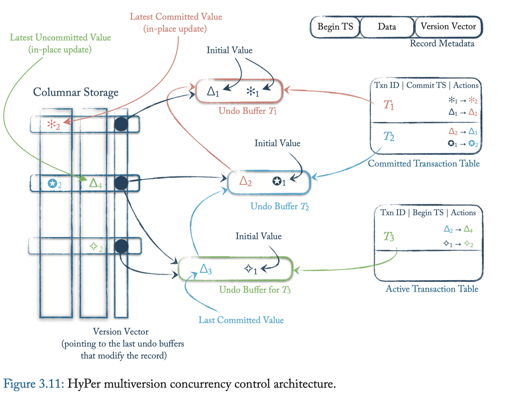
HyPer
本协议是一个基于验证的协议,本身是 MVCC 的. 有趣的地方是谓词锁的实现。
这里用再次 Scan 的方式来验证,同时,它会保留谓词锁,而不是数据的锁,来减轻开销。
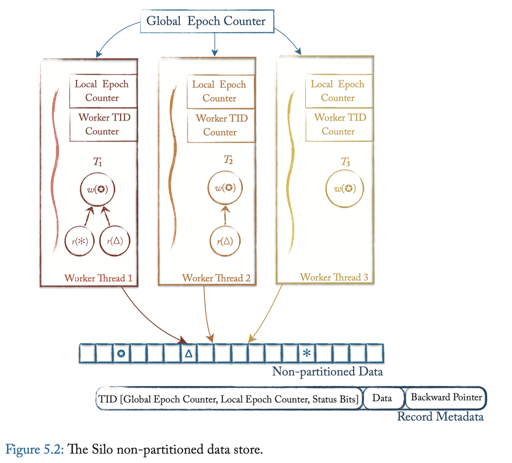
Silo: Speedy Transactions in Multicore In-Memory Databases
本协议是一个基于 TS 的协议. Silo 本身是设计在新硬件上的,特点是 Batch 来取 Ts
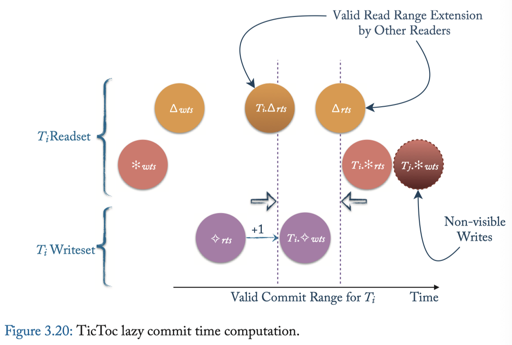
TicToc
本协议是一个基于 TS 的协议. 之前的协议可能都要拿到一个具体的 ts, TicToc 做出的优化是,拿到一个大概的 ts 范围,而不取具体的时间戳。
参考
[1] On Optimistic Methods for Concurrency Control
[2] Transaction Processing on Modern Hardware
[3] https://wangziqi2013.github.io/article/2018/03/21/Analyzing-OCC-Anomalies-and-Solutions.html
[4] An Empirical Evaluation of In-Memory Multi-Version Concurrency Control
[5] Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores