An Overview of Query Optimization in Relational Systems
这是 1998 年的关于 RDBMS 优化器的论文,旨在指出 70 年代到当时的优化器的变化。SQL 的优化器可以说是一个并不新颖的领域了,虽然新技术常有提出,但是很多还是在 Selinger 优化器和 Cascades 优化器的框架下。
Introduction
DB 的上层可以分为 Query Optimizer 和 Query Execution Engine,15-721 给出过一个比较合适的图:
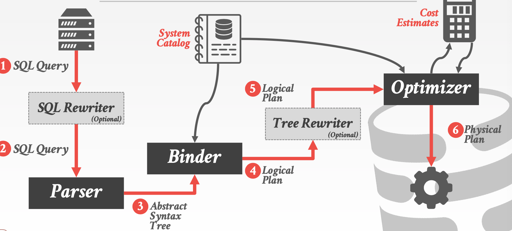
这里区分了 Physical Operators 和 Logical Operators. 这两个并不是一对一关系。Physical 的意思大概是更接近具体执行的步骤,它会被丢给 Execution Engine 执行。
产生一个 Optimal 的 Plan 是一个 NP-Hard 的问题,而优化器本身也有许多技巧来进行优化,不过话说回来,优化器在有的时候也没有承担那么复杂的逻辑,比如在 TP 系统中,所有优化都依赖“索引”,简单的优化器直接做很多基于规则的优化和索引推断就行。
言归正传,论文认为 Query Optimization 需要:
- Search Space: Plan 的生成空间
- Cost Estimation: 估算一个 Plan 是不是好
- Enumeration algorithm: 枚举出对应的 Plan
上面感觉其实在说废话,但是挺重要的,因为 (1) 要包含最好的结果,(2) 要又快又准,(3) 要高效。
System-R Optimizer
这篇论文简短介绍了 System-R 优化器的 Select-Project-Join (SPJ) 部分
System-R 优化器认识到了 Join 的 associative 和 commutative,同时 Join 有两种实现:Nested Loop Join 和 Sort-Merge Join. Scan 可以是 Index Scan (可以在 cluster index 或者是 secondary index 上),或者 Sequential Scan。
这里有一些启发式的部分:Predict 应该尽早被执行。
System-R 优化器依赖统计信息、对 Selection Selectivity 的分析(事后看虽然朴素,不过也比较有启发性了)、具体分析 io-cost 和 cpu-cost 的公式(其实我也不太清楚这个 2020 年有没有很好的量化公式)。通过上面的信息,System-R Optimizer 能够拿到估计中的:
- 物理的 Operation Node 输出的大概数目
- 输出的 Tuples 的顺序
- Operator 大概的 cost
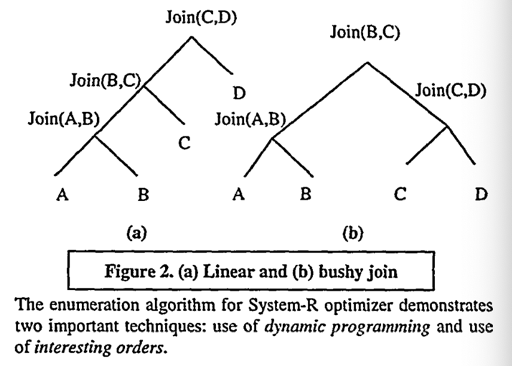
System-R 用 DP 来找到 best plan,只处理左深树来减少 search space,通过 interesting order 来处理顺序。
找 best plan 的时候,算法大概如下:
1 | 1. j = set of join nodes |
这里的 best way to join 实际上还要考虑到只有左深树。基本上就是 Join(subOptimal, {remain}). 然后找到最优的子 plan.
另外,这里有个 interesting order 的内容,简单的说,在上面的 subOptimal 中,不能只考虑“下面几张表 join 的时候最优的是哪棵树“,还要考虑表 Operator 输出的属性的顺序。这个 interesting order 的内容为后续一些 “physical properties” 的设计提供了基础。
Intuitively, a physical property is any characteristic of a plan that is not sharedby all plans for the samelogical expression,but can impact the cost of subscqucntoperations
虽然上述的设计很优雅也很有启发性,但是这些没有讲述什么 logical transformations 和扩展 search space 的部分。
Search Space
SQL 会有很多 transformation 的部分,有的时候我们可以当作这些一定能起到作用,做逻辑上的优化,比如 System-R 很多时候就是这么执行的。但是也有一些很可能能起到作用的 transformation。
这里说的比较绕,贴一下原文:
It should be noted that trunsfonnations do not necessarily reduce cost and therefore must be applied in a cost-based manner by the enum algorirhm to ensure a positive benejit.
在这里面,Optimizer 可能会把 Plan 格式变更若干次。保证开始是一个逻辑计划,最后是一个可以丢给 Execution Engine 的东西就行了。
关于这个我找了找 Starburst 有关的论文:https://zhuanlan.zhihu.com/p/369771981 ,Starburst 会生成一个便于优化的 QGM,便于对整个树做一些逻辑优化。不过批评者认为这些优化不一定考虑到了 Page/Block 相关的信息。
Commuting Between Operators
很多 transformation 用到了算子的交换律。
Generalizing Join Sequencing
在 System-R 优化器中,只会考虑 left-deep tree。但实际上,原则上我们可以考虑 bushy tree,近日的 DPCCP 开始计入相关的内容,正面面对 bushy tree。同时,System-R 优化器将笛卡尔积丢到最后处理,但是实际上这个也可能被显著优化,比方说在 BI 系统中,对笛卡尔积的优化是很重要的。
在一个可扩展的系统中,可能会允许搜索 bushy tree (这个需要物化 Join 结果)或者笛卡尔积。(当然这个也是比较难推断下来具体该不该这么做的)。
Outerjoin and Join
1 | Join(R, S LOJ T) = Join(R, s) LOJ T |
这些操作能让 Joins 在 Join + outerjoins 之前执行
Group-By and Join
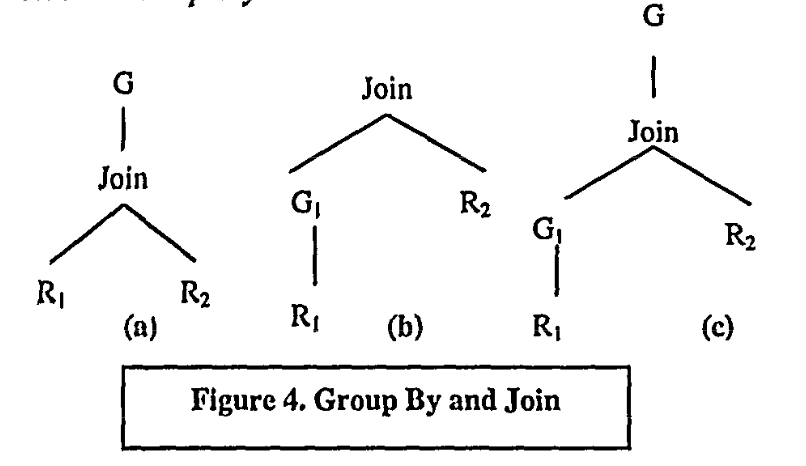
早期的一些优化器中,SPJ 会在 Group By 之前执行. Figure 4 的 Transformation 在 Join 之前即可处理 Group By. 比如在 Select DISTINCT 的时候,这里可能会把部分 Group By 下推,这一定情况下可以减少 Join 的数量。此外,如果 Group By 可以利用 R1 的 order,那么显然是好的。
这里把 Group By 下推给 G1,一定程度上,这可以减少 Join 的数量。不过这也要求能把 Group By 做一定的拆分。
Reducing Multi-Block Queries to Single-Block
Merging Views
对于简单的:
1 | Q = Join(R, V) |
Q 是可以拆开来然后进行 join order optimize 的,不过话又说回来,上一节降到了 Group By 和 DISTINCT 下推,这里的展开可能是反着两个下推的。我们可能要重新执行 Figure 4 的流程
Merging Nested Subqueries
子查询相当相当重要。
1 | SELECT Emp.Name |
(1) 当内部查询部不带有外部查询( uncorrelated ) 的情况下,内部查询只需要执行一次。
如果内部查询和外部查询相关,需要外部查询中的变量,那就麻烦了。例如上面的 SELECT 可以 cast 成:
1 | FROM Emp E, Dept D |
转化的流程取决于内部表达式的复杂度,即有无 quantifiers (例如 ALL, EXIST)、aggregates 或者都没有。(2) 在最简单的场景下,如上面,Table 可以改成一个 Semijoin:
1 | Semijoin(Emp, Dept, Emp.Dept = Dept.Dept) = Project(Join(Emp, Dept), Emp.*) |
当子查询有 subquery 的时候,情况可能需要转化成 LOJ 或者 ROJ:
1 | SELECT Dept.name |
SELECT Count(Emp.*) 是个 agg,这里麻烦的地方是,如果 Dept.name 相等的 Emp 是不存在的,那么这个条件显然是满足的。所以这里的逻辑是:
1 | Select Dept.name FROM Dept LEFT OUTER JOIN Emp ON Dept.name = Emp.Dept_name Group BY Dept.name |
这里相当于 Dept LOJ 内部 agg 的表。这个的优化可以依赖之前提的,后处理 LOJ
Using Semijoin Like Techniques for Optimizing Multi-Block Queries
1 | CREATE VIEW DepAvgSal As ( |
这里面,SQL 可以被优化为 E.did 相关的 view
1 | CREATE VIEW partialresult AS |
这种操作将子查询变更为不重复访问的查询。
Statistics And Cost Estimation
上面的部分介绍了一些 Logical 的 Transformation。对于一个表达式树,我们要考量的资源可能有:
- CPU time
- IO cost
- memory
- bandwidth
Cost Estimation 是希望快捷又准确的计算这些值。System-R 给出了一个基本的框架:
- 对存储的数据做一些分析
- 对每个 Operator,给出一个评估策略:
- 输出数据的一些统计值
- 操作的 cost
关于 (1), 这里有两个问题:
- 我们需要什么数据
- 我们什么时候获取/更新这些统计数据
Statistical Summaries of Data
Base Data
一个关键点是,我们需要知道 tuples 和相关的 pages 的大概数目。这些信息是物理的数据,独立于 expression 的 selectivity 这样的逻辑数据,并且和后者一起做出决策。我们需要知道各个列相关的一些协助预测的信息。
在很多 RDBMS 中,等深(equi-depth)直方图可以用来统计信息。在直方图的单个 Bucket 里,可以当作数据是 uniform distribution 的。如果缺少直方图,可以保存数值的 min/max(需要注意的是,实践中,这里也会处理一些极大极小值,保留次大值之类的)。
我们可能要为所有的 Column 都构建对应的 Histogram,当然,一个查询可能会有多列的 condition。一般我们不会为列的 pairs 维护 histogram,这样会造成巨大的空间放大,但我们可能维护相关的 distinct value(不同的值)。
Propagation of Statistical Information
histogram 可以支持在插入后更新数据,也可以在某个统计信息不是很准的 SELECT 之后,根据 SELECT 的结果,更新数据,不过不太好的一点是,如果有的列被频繁更新,但是很少读取,这些数据可能会失真。当我们有多个条件的时候,可能会取各个 Column 的 Selectivity 的积,这可能导致问题变严重。
不过有的系统可能只会用一些 Column 的统计信息。一些系统在 Join 的时候也可以给 Histogram 做 “Join”,不过这涉及 Histogram 的对齐工作。
Cost Computation
这里要求把 CPU,IO 等考虑上,也提到了分布式系统中,也要考虑 IO 开销(不知道 snowflake 和 ClickHouse 做了吗)。这里还提到对 RDBMS,Buffer Pool 相关的策略对预测影响也很高。
Enumeration Architectures
System-R 优化器会根据表访问方法、Join 方法构建搜索策略。当添加新的 transformation 和新的 physical operator 的时候,希望有一个可扩展(extensible)的 optimizer。这里关注了自底向上的 Starburst 和自顶向下的 Volcano/Cascades,他们的共同点是:
- 使用 generalized cost functions + physical properties + operator nodes
- 使用规则引擎,让 transformation 能够更新 query expression / operator trees
Starburst
Starburst 被构建在 DB2 中,有 Query Rewrite 和 Plan Optimization 两个阶段。它被证明有不错的性能,但是也有一定的问题。
Starburst 会把查询构建成 QGM,其中 box 代表 table 相关的 query block,每个 box 会描述数据是否有序、predicate 相关的策略。
在 rewrite 阶段,系统有很多的 rules,每个 rule 包含<判断 apply 的条件, apply 的流程> .这些 rules 按顺序排布。
在 plan optimization 阶段,QGM 会产生对应的 physical operators,这个产生方法可能有某种 dsl 来描述。每个 Plan 有自己的 selectivity, physical properties,cost。
Volcano/Cascades
starburst 会先生成一组 QGM,Volcano/Cascades 会有逻辑到物理的变化。借助 memo 来做具体的实现。