FAST'16 WiscKey
FAST’16: WiscKey
WiscKey 是 LSM-Tree 上分离 Key-Value 的一种方案。作者的思路是:
- LSMTree 的 Compaction 有很大的写放大,实际上,Compaction 的时候,value 不那么会被用上,同时,由于写放大,它也没有办法很好利用 SSD 的性能。
- 解决方案是将 Value 从 LSM-Tree 中分离出来,同时,实际的场景中,key 的大小并不会很大。为了做到第二点,需要做的事情有:
- 拆分出一个 vLog (value log) 组件,并将 value 落到 vLog 里面
- 需要一个 GC,来回收掉旧的 vLog
- 不再需要 wal,一切用 vLog 来 trade off
- 维持 consistency
当然,论文对 value log 的内容提出了指导性的设计,但是 Consistency 有关的部分其实是写得比较含糊的,感觉很多具体内容还是要看 badger 或者 Titan 之类的实现,才能了解的比较透彻。
Introduction
论文的出发点是有两点:
- Compaction 可能会带来非常大的写放大和性能损耗。其中,value 的 Compaction 会带来很大的写放大。写放大比例可能和 Compaction 模式有关。Tiered Compaction 每层会写放大一次,Leveled Compaction 可能会放大数次。这导致了对 SSD 的狂写放大,带来了性能损耗。
- LSMTree 论文提出于 90 年代,那是一个 HDD 占主要地位的年代。HDD 的顺序写性能可能是随机写性能的百倍。LSM-Tree 相对来说,所有写入都是顺序写,这导致了很高的写性能。但是 SSD 没有必要这样去写 value,这回造成很高的写放大。同时,SSD 有很大的并行度,相对来说需要良好的设计来利用这些并行度。同时,SSD 暴写是有损耗的,很容易写坏设备。还有问题就是说,SSD 随机读/顺序读虽然还是有差距,但是相对 HDD 来差距会小很多。
所以论文提供了最初的 idea:
The central idea behind WiscKey is the separation of keys and values [42]; only keys are kept sorted in the LSM-tree, while values are stored separately in a log. In other words, we decou- ple key sorting and garbage collection in WiscKey while LevelDB bundles them together.
这种 idea 带来了一些 challenge:
- Scan 的时候可能会有一些性能 loss,因为 value 没有任何 locality,如何解决这个问题。(Get 的时候也会有一点,不过这个相当于是一种 trade off 了,可以后文介绍)。WiscKey 靠 prefetch 和利用 SSD 并行度来解决这个问题
- GC: WiscKey 的 GC 利用 vLog 上的顺序读写来优化性能,并希望自己的 GC 是轻量级的
- Consistency: WiscKey 利用 vLog 和 vLog 记录的设计来做 consistency.
下面是 benchmark 部分,这个就,听他吹一吹就行:
With LevelDB’s own microbenchmark, WiscKey is 2.5×–111× faster than LevelDB for loading a database, depending on the size of the key-value pairs; for random lookups, WiscKey is 1.6×–14× faster than LevelDB.
WiscKey 性能不总是比 LSM-Tree 好,在小 key 占多数的的 point get、range query 中,性能是下降的(当然,如果 vLog 值是顺序的,可能有好些的 locality, 但是不现实),不过,论文作者认为这些情况比较少发生:
However, this workload does not reflect real-world use cases (which primarily use shorter range queries) and can be improved by log reorganization.
LevelDB 的读写放大和硬件利用
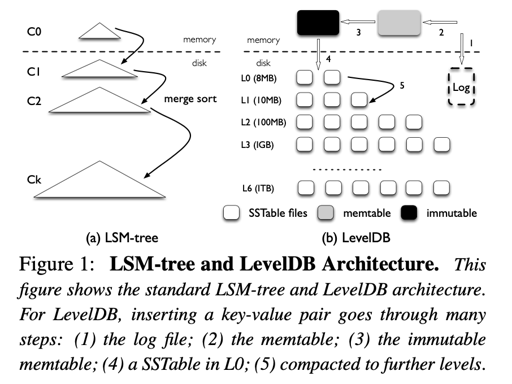
LevelDB 就不讲了,写放大和 LevelDB Compaction 有关。读放大其实相对来说 trick 一些,这里的分析方式如下:
In the worst case, LevelDB needs to check eight files in L0, and one file for each of the remaining six levels: a total of 14 files. Sec- ond, to find a key-value pair within a SSTable file, LevelDB needs to read multiple metadata blocks within the file. Specifically, the amount of data actually read is given by (index block + bloom-filter blocks + data block). For example, to lookup a 1-KB key-value pair, LevelDB needs to read a 16-KB index block, a 4- KB bloom-filter block, and a 4-KB data block; in total, 24 KB. Therefore, considering the 14 SSTable files in the worst case, the read amplification of LevelDB is 24 × 14 = 336. Smaller key-value pairs will lead to an even higher read amplification.
这里是算上了 index block 和 bloom fliter 的情况,最后读了一次 data block。这里提供了一个 1KB 的 key-value 的 pair, 然后点查 100000 次。
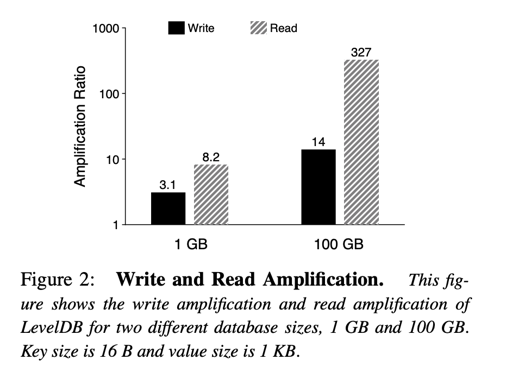
上面的图有点反直觉,不过实际上原因是说,随着数据集增大,LevelDB 的层数变深、SST 变多,读可能会需要访问越来越多的 SST 的 index blocks, 同时,这些 blocks 不一定都能 fit 在文件元信息的 cache 中,导致读性能的下降,读放大增大。写入很好理解,就不解释了。
(论文随后和 B+Tree 对比了一下,不过我感觉由于 BTree 的刷脏之类的逻辑,感觉读写放大都没这么好比较,就不贴了)
下面是硬件相关的内容,可以看到,sequential 相对来说很容易打满读带宽。而 rand access 需要并行 + 每次 issue 较大的块的话,相对来说也能把带宽打满。
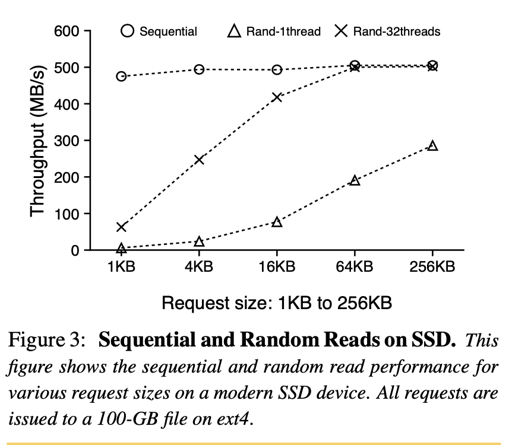
作者认为,综上所述,compaction 和 random access 浪费了很多读相关的带宽,这点可以被好好利用。同时,即使不是 sequential access, 带宽也是能被打满的。这代表了后文的优化方向。
WiscKey
WiscKey 提出了几个基本的设计思想和设计目标:
- WiscKey 分离了 key-value
- 为了高效 range-query, WiscKey 用并行随机读来最大化利用 SSD 的带宽。
- WiscKey 利用 GC 等事务来优化 vLog
- WiscKey 可能通过牺牲一致性的方式来优化写性能
Design Goals:
- 低写放大
- 低读放大
- SSD 优化
- 兼容类似 LevelDB 这些语义,提供丰富的 api
Key-Value 分离
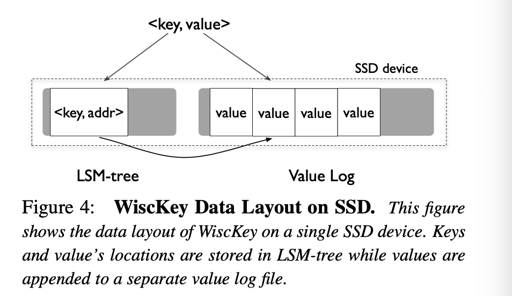
WiscKey is motivated by a simple revelation. Compaction only needs to sort keys, while values can be managed separately [42].
实际上,这里的 sorting 只需要 key,不需要 value。由于大部分 workload 中,value 可能占的地位多一些,这样能让 SST 中,保存更多的对象,压缩更少的次数。Compaction 的时候,能减少 Compaction 相关的写放大。
这种模式也减小了读相关的放大。虽然在 WiscKey 中,读也会走到 vLog 上,不能利用 <key, value> 一起的局部性,但是能保证较小的 LSMTree Level,用这个来节省走一堆 index block 的读放大。这里可以有:
For example, assuming 16-B keys and 1-KB values, if the size of the entire key-value dataset is 100 GB, then the size of the LSM-tree is only around 2 GB (assuming a 12-B cost for a value’s location and size), which can be easily cached in modern servers which have over 100-GB of memory.
Figure4 给出了 WiscKey 的基本设计,需要注意的是,这个设计是没有考虑 GC 的,后面还得改呢=。=
LSM-tree 的 addr 差不多是 (<vLog-offset, value-size>) 这个格式。那么这个时候,逻辑大概如下:
1 | delete: |
优化 Range Query
LevelDB 提供了 iterator ,这有一些对应的 api:
Seek(key)NextPrevKeyValue
在 LevelDB 里面,这几个操作都是比较朴素的,Key Value 拿到 iterator 现有的东西,返回 Slice. Next 要么直接下一个,然后走下前缀压缩相关的逻辑,要么跳到 Index 上再找个 data block. 这里有个好处就是,range scan 再单个 SST 上还是有一定局部性的。反正 value 都存在一起。
WiscKey 这里降低了局部性。解决方案是,如果发现查询是一个 range 相关的查询,这里会提前拉出一堆 key 对应的 addr, 然后 issue 并行读。这里会有一批相关的线程来完成这些读相关的操作:
The corresponding value addresses retrieved from the LSM-tree are inserted into a queue; multiple threads will fetch these addresses from the vLog concurrently in the background.
GC

LevelDB 是怎么 GC 的呢?答案是 Compaction 的时候把不再需要的数据干掉。因为它的 key-value 是在一起的,所以这里是相对轻松的。
WiscKey Compaction 的时候没有动 vLog, 它需要根据 vLog 来做 GC。这个时候,它肯定需要走 LSM-tree 来查看 key 是不是不再需要的了,所以 vLog 要能够索引到 key. 如 Figure 5, 这里在 vLog 中编码了 key, 现在格式是:(key size, value size, key, value).
vLog 这里提供了 tail 和 head. 当 GC 的时候,这里从 tail 拿几 MB 的 kv pair, 然后走 LSM-tree 查看数据可不可以被 GC。这里会把还需要用的数据放到 head 处,然后调整 tail 的位置。这里为了保证正确性,需要有这样的顺序:
1 | 1. 将有效的值 append 到 head 上 |
其实 (3) 这个地方是有一致性问题的:有效数据你想怎么更新呢?感觉这里还挺麻烦的,没有 snapshot 的话倒是还好,如果考虑 LevelDB 的 multi-version 的话,感觉问题还不小…
WiscKey 可以配置 GC 触发的 pattern,比如定期触发之类的。同时,删除少的负载会很少触发 GC。
Crash Consistency
还记得 vLog 是什么样子吗?(key size, value size, key, value)。有了这个,实际上就相当于 wal 了。(那这个和 LevelDB 区别是什么呢?实际上 LevelDB 一个 memtable 对应一个 Log file,而 WiscKey 把这个玩意抽开了)。这实际上就能保证 consistency。
当然,数据是可能有 corrupt 的。WiscKey 发现 log corrupt 的时候,可以在 LSMTree 中表示无该记录。
优化
Value-Log Buffer
这个就很简单,把 vLog 写到 buffer 里,写满了再刷,这个就,一致性/性能 trade-off 了。
Optimizing the LSM-tree Log
这里,我们刚刚说到,tail 会在 GC 的时候调整。这里的 head 是持久化的,那么我们考虑,recover 的时候,实际上只要从 head 开始,把它当 ckpt,往后扫 log 来恢复。
Implemention
vLog 可能有不同的访问模式,这里用 posix_fadvise() 来交给文件系统处理
同时,对于 Scan,WiscKey 维护了 32 个线程来处理。
These threads sleep on a thread-safe queue, waiting for new value addresses to arrive. When prefetching is triggered, WiscKey inserts a fixed number of value addresses to the worker queue, and then wakes up all the sleeping threads. These threads will start reading values in parallel, caching them in the buffer cache automatically.
这里用 fallocate(2) 来处理 disk 上的空间: https://man7.org/linux/man-pages/man2/fallocate.2.html
Evaluation
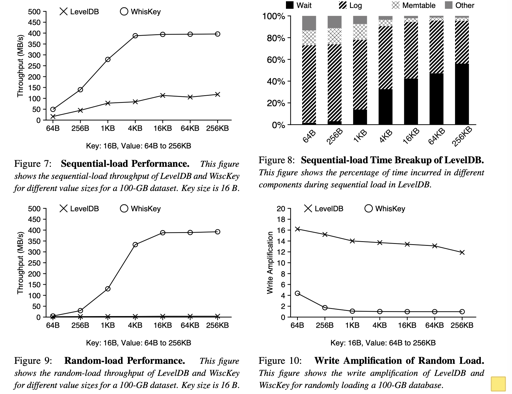
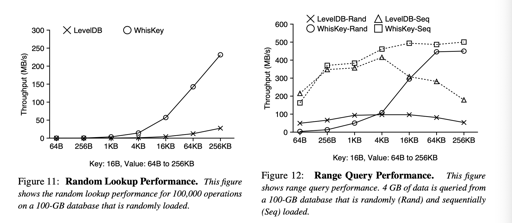
可以看到,不知道出于什么原因,作者很逆天的把 WiscKey 写成了 WhisKey, 我搜了下,没找到原因。值得关注的其实还是 Figure 8 等一些 LevelDB 性能瓶颈出现的地方了。
我的一些问题
- GC 相关的写放大感觉是没有很好的衡量的,vLog GC 可能比较省写放大,但是能省多少读写放大呢,这个有很好的 tunning 吗?
- Consistency 怎么能很好的保证呢?假如 GC 的时候,那我们要更新所有的 LSMTree 的 index,这可能暗示