VLDB'17 Fast Scans on Key-Value Stores
VLDB’17 Fast Scans on Key-Value Stores
尽管 KV 模型中,Scan 是一个非常常见的需求,但是大部分时候,Scan 其实效率是很不尽人意的。以 LevelDB 为例,它的 Scan 需要构建 Iterator, 然后把 Memtable, L0 层,其余层的 overlap 都可能读到对应的内容,并且可能需要合并相同 User Key 的数据。此外可能还需要 Manual Compaction 来维护 Scan 的效率。
Fast Scans on Key-Value Stores 论文介绍了一个 kv-server 的模型, 它在尽量少降低 get/put 的效率的情况下,支持了高效的 Scan 查询。论文比较清晰地介绍了一下 kv-engine 的各种设计取舍,推导出了文章介绍的 TellStore 的系统实现。需要注意的是,这里 Scan 经常是一个全表扫的模型,而上层通过 range partition 来限制 scan 的范围。
Abstract and Introduction
KV 模型和 KV-Server (下简称 KVS) 在今天市场正在扩散,原因归功于简单的模型和在这种模型下面不俗的性能:大部分时候,Get/Put 的性能是可预测且高效的,可以在常数时间内完成。但是大部分时候,KVS 的 Scan要么 没有对应接口,要么性能不佳:
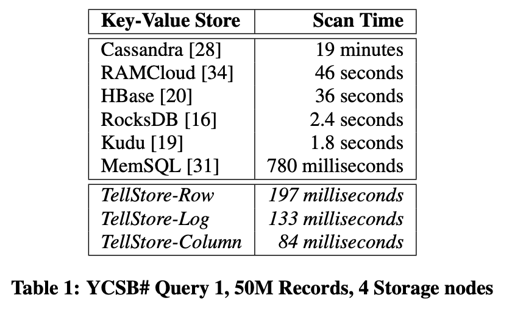
论文实现了 TellStore, 即 benchmark 看上去很牛的那些。
论文认为,本质上,Scan 的高性能和 Get/Put 操作的高性能是冲突的,Scan 需要扫一定部分的数据:
- Scan 如果需要比较好的性能,需要很高的 spatial locality
- Get/Put 如果需要很高的性能,需要 sparse index 来定位。
- Version / GC 可能影响效率。而多 Version 的处理可能也会对 Scan 或者 Get/Put 性能造成影响。
论文提出了 SQL-over-NoSQL 的架构,并且说明了这种架构下,如何高效同时支持 Get/Put/Scan。最后,论文介绍了它们实现的 TellStore。
Architecture
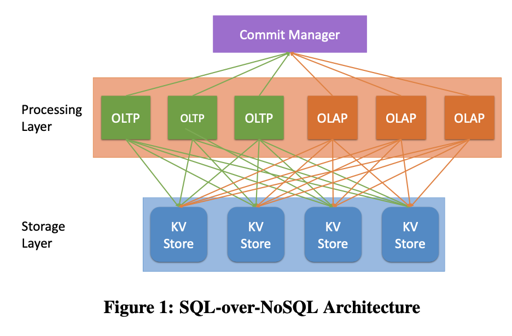
论文提供了一个 SQL-over-NoSQL 的架构,然后分为了几层,作者认为,这样的架构是弹性的,每一层可以单独的去扩展:
- Storage Layer: 存放分布式的 KV Store,这篇论文的重点
- Processing Layer: 负责处理负载。这里处理事务和查询。同时实现了 MVCC 和 SI 的隔离级别。事务相关的内容由 Commit Manager 层处理。
- Commit Manager: 维护 SI/MVCC。这里它只要给事务 Txn Timestamp, 并且管理事务的状态(active/committed/aborted), 作者认为,因为它功能比较简单,所以很少成为系统的瓶颈。
而为了支持 SQL,Storage Layer 需要提供下列的语义:
- Scans: 数据可能会以 KV 的形式被组织在 Storage Layer 上。SQL 请求通常会批量 Scan 一个范围的 KV 来完成查询。同时 Storage Layer 也要能下推一些 Selections/Projections/Aggregate 之类的请求,来减少网络带宽开销和网络请求延时。
- Versioning: 本身上层是 MVCC 的,这里需要 Storage Layer 支持多版本。不需要的版本需要被 GC 掉。
- Batching & Asynchronous Communication: 感觉这个就是很工程上和并发设计的问题了。OLTP 的简单查询应该被 Batch 发送到 Storage Layer。这样来均摊多个并发事务的通信开销。 同时,这些请求需要能够被异步处理,以不阻塞下个 Batch 的请求。
下面需要介绍 KV 设计的 trade-off:
- format: 很多的分析型系统使用 columnar storage 来存储内容。Scan 如果形式上是
sum(a)之类的请求,会在这上面大大受益。但是对于 Get/Put 而言,这样会导致Get(key)需要 materialize,Set(key)则会写放大 - versioning: 一堆版本,Scan 起来,如果它们贴一起,就得跳过一些不需要的版本的数据了,不贴一起就更麻烦了。
- batching: 这个问题就很工程化了,是一个负载相关的问题。Scan 通常 CPU 开销比较重,而 Put/Get 属于比较轻的操作。放在一起并不明智。
Design Space
Where to Put Updates?
论文把更新的地方分成了三种: Update-in-place ,log-structure,delta-main.
- Update-in-place 即 就地更新,这个可以想到我们脑海中比较原始的 B-Tree. 这样的结构对定长的数据有着很好的性能,但是对变长/多版本数据而言通常意味着相对复杂一些的处理方法,同时,这里还有一定的并发问题,例如 B-Tree 的并发控制。
- Log-structure Storage. 比较极端的,这里用 append log 来当作写数据。这个时候能够保证高效和没有空间上的碎片。纯日志结构的 put 是非常高效的,考虑类似 Bitcask 的 case,
Get的性能也可以做到很好,但是Scan可能相当复杂。LSM-Tree 是一种很好的常见妥协方案。 - Delta-main: 数据写入的时候被组织在一个写优化的结构中,定期被合入一个读优化的结构。论文认为,这是就地更新和日志更新的 trade-off: 能尽量保证两者的优点。(我个人感觉这个应该会面临比较大的写放大?)
How to arrange records?
这就是经典的行存列存的问题了。简单来说方案大概有:
- Row-major: Get/Set 能够相对来说直接的完成目标,Scan 部分负载会有较差的局部性。
- Column-major: Get/Set 可能需要物化/写放大,但是 Scan 可能受益。
- PAX 类的行列混存: 试图在 1/2 中 trade-off。
How to handle versions?
MVCC 无论如何多版本,不同版本肯定是要物理存储的:
- 不同版本物理上簇聚在一起。通常和就地更新一起用。
- 不同版本物理上不在一起,以链式来寻找版本。通常和 log-structure 一起用。它的局部性不好,但是这能简化 GC
When to do Garbage Collection?
- 有线程/进程定期触发 GC
- Scan 的时候,触发 GC
2可能会增加 Scan 的时间,但是可能被 Scan 比较多的地方更容易被 GC。同时,它在 Scan 的时候 GC,也避免了 GC 之后,可能会出现额外的 cache miss.
Summary
作者推出了以下的图:
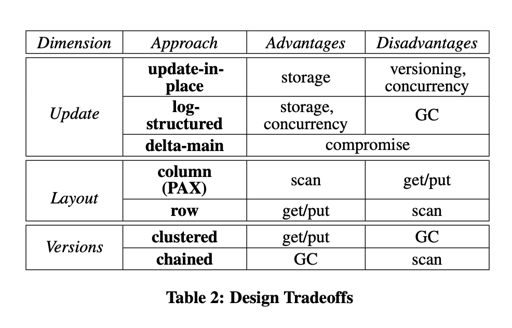

以上就是上面这几个维度的 KV 设计方案了,但是实际上可选的方案没有那么多,比方说 update-in-place 通常和 row-major 在一起,有很多方案实际上想想就不太合理。所以文章作者直接跳到结果了:
The two most extreme variants are the variant based on log- structured with chained-versions in a row-major format and the variant using a delta-main structure with clustered-versions in a column-major format. The next two sections describe our imple- mentation of these variants in TellStore, called TellStore-Log and TellStore-Col. Section 6 gives implementation details of TellStore that are important for all TellStore variants.
嗯,很合理…
下面将介绍 TellStore 的结构,这里介绍每个结构的时候,将会回答上面所有的问题。
TellStore-Log
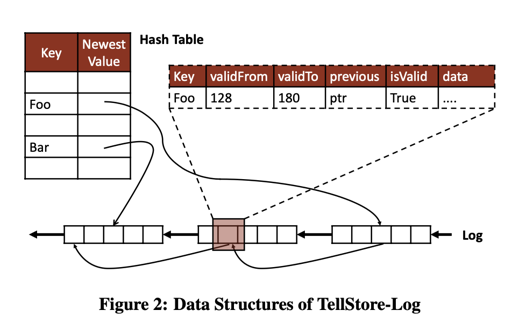
Where to Put Updates?
这里为了写入快速,显然要写到 log buffer 里面,这里写入大致逻辑如下:
1 | 1. 拿到记录,写 log buffer |
一旦上述 3 成功,日志就是 immutable 的。这使得 copy 和 recover 相对来说没有那么复杂。这里 1 可以是并发的,而 2 用来同步:对于冲突的写,写 hashtable 成功的数据.
同时,这里 hash table 实现是预先分配固定大小内存的。同时使用了开放寻址 + 线性探测的方式,以利用系统的局部性。
存储的 value 这里希望尽可能小,所以论文说就 24bytes:
To keep memory usage small while allowing for a sufficiently sized table, the hash buckets only store the table ID, record key and pointer to the record (24 bytes).
(所以这用的是 gcc4 的 cow string 吗,还是自己写了,囧…)
How to Arrange Records?
行/列?显然是行存。
此外,作者不希望 Scan 的时候还需要查 hashtable, 所以数据自己能说明自己是否是 valid 的。此外,这里为每个 table 分配了一个 log 结构,这里加快了对 table scan 的效率。(可是没有所以结构咋查啊…)
How to Handle Versions?
这里的版本如上图所示,采取链式方法串起来。新纪录需要指向旧纪录,同时 validFrom validTo 提供了对给定时间戳,允许的读范围。那么我们可以在更新一下 update
1 | 1. 拿到记录,写 log buffer |
When to do Garbage Collection?
这里每个 table 一个 log 结构的话,Scan 的时候, validTo 小于系统最小可能访问的 ts,就说明这条记录可以被 GC. 在 Scan 的时候,如果发现某个 Page (这里我想了下,感觉 log 可能是在 Page 里面存储的,有点类似 InnoDB?) 的可以被 GC 的 record 比例超过一定阈值,Page 就可以被标记为可 GC 的。这里需要把 Page 内 GC,然后调整 MVCC 关系的指针,这个操作代价很高,且 cache locality 很低。
TellStore-Col
TellStore-Log 是一个高性能更新的结构。而论文实际上希望设计一个 Delta-main 结构,将 TellStore-Log 定期合并到一个高效 Scan 的结构中。
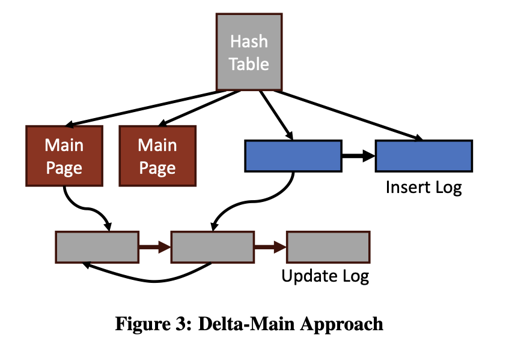
这里的逻辑大概是:
- 一系列的 Main Page 作为系统的 main 存储
- 两个逻辑上的 log list 作为系统的 delta, 分别为 insert log 和 update log
Where to Put Updates?
- 如果这个 key 不存在,那么丢到 insert-log 里面
- 如果这个 key 存在(在 insert-log 或者 main 中),丢到 update-log 里面。
此外,还有个 newest 字段:
Records in the main and insert-log both contain a mutable newest field containing a pointer to the most-recently written element with the same key.
写入的时候,类似 TellStore-Log 的 newest 会作为同步处来处理。
How to Arrange Records?
两个 delta 日志肯定行存,main 日志既可以行存也可以列存。TellStore-Col 是一个列存实现,然后用类似 PAX 的结构 ColumnMap 来存储信息:
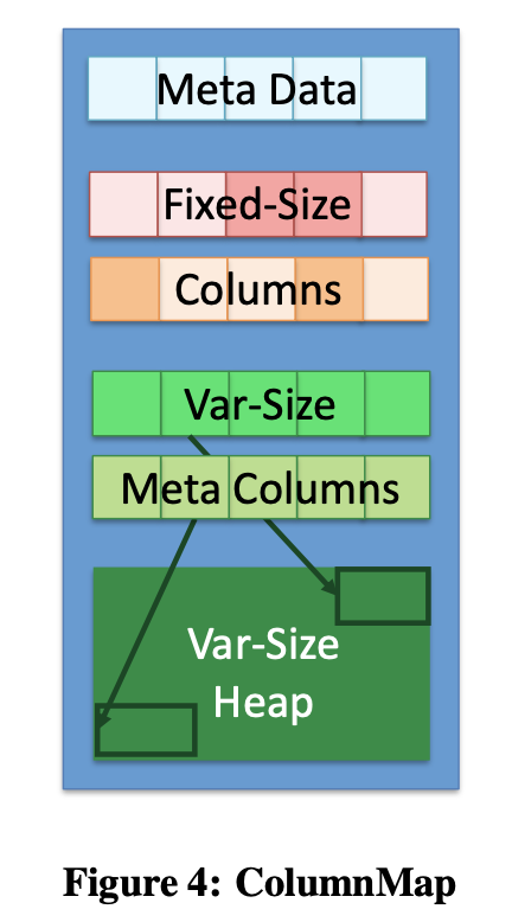
- Meta Data 存储了一些必要的元信息
- Fixed-Size Columns 可能根据 MetaData 确定有哪些内容,这里知道第一列在哪就可以很快定位“哪一个元素在哪”(似乎这里没有压缩逻辑?)
- Var-size heap 和 var-size + meta columns 是提供给变长字段,例如
stringBLOB的。“This heap is indexed by fixed-size metadata storing the 4-byte offset into the heap and its 4-byte prefix.”
How to Handle Versions?
main page 中的版本簇聚形式存储,从 lastest 到最旧的版本。这样,假设带着一个时间戳来读,那就需要一个找到对应的时间。不过因为是靠在一起的,所以局部性好一些。同时,它也有 previous 指针,指向 Update-Log 中的数据。
When to do Garbage Collection?
这里 GC 功能要复杂些:它需要把 update-log 和 insert-log 合并到 main 里面(可能是以行存 —> 列存的形式)。同时,这里形式类似 cow, 不会在 main page 原地更新,而是产生新的 page / reuse page.
这里 GC 由单独的线程处理(为什么不在 Scan 的时候处理呢?论文解释是这个工作量较大。TellStore-Log Scan 的时候需要扫全部记录,然后把没用的放前面即可。TellStore-Col 需要搞新 page + 合并 + 行转列,负载比较大)。
GC 发现某个记录需要被清除的时候会被触发。对于 main page 中的 key, 不同的版本可以从自己的临近数据和 update-log 中找到。然后可以从 insert-log 中找到新插入的数据,扫 update-log 拿到这些新的版本。validTo 过小的记录会被 discard 掉。完成后,log 记录、被 gc 的 main page 可以放入空闲 page 列表。
这里重申了一下为什么要 update-log:
- 只要 scan insert-log, 就可以找到不在 main 中的数据。
- 同时这可能降低了 locality: 原本 scan 的时候,insert-update 一起,可能找到一个记录,就可以发现它是最新的。而新的 case 下 update 这里可能要回溯到 insert 上进行 random access. 这要求 update-log 被 GC/合并到 main 是非常频繁、能够保证 update-log 足够短。
Implemention
这部分主要就是工程实现了。
网络上,这里实现采取了 boost.asio 的异步策略。同时,对 get/put 和 scan 的线程池做了切分:这里应该觉得 Scan 相对重一些,不能影响较轻的 Get/Put 查询。同时,还有线程负责 GC。
Scan 这里写的有点 hack, 有一个 scan thread 作为 coordinator,它会搜集所有 scan request,然后绑定到一个 shared scan 上,然后由一些线程去分 part 扫。感觉这里 Scan Request 多一些性能会比较好。
这里还用类似 Chord 的形式实现了个 DHT 。同时如果希望支持 Range,Tell 论文中提到了 Lock-Free Btree,它是在 processing layer 实现的,感觉到 storage layer 都是傻傻的全部 scan 然后 shared scan.
此外,这里因为 scan 的特性,还做了 codegen,这块我不是很了解,没细看。