[CIDR 05] MonetDB/X100: Hyper-Pipelining Query Execution
MonetDB/X100 是一篇 05 年的论文,也是分析型数据库中引用较多的一篇论文。它给 MonetDB 提供了一个高效的查询层,减小了 MonetDB 之前许多操作的开销。同时,贴合了当时的硬件的发展。目前,这篇论文的 Batch 等思路已经被比较大规模的使用了,同时,文章给出的手工编码代码的 baseline 也给 Hyper 等 Codegen 提供了启发。
同时,即使不了解数据库,学习过体系结构的朋友们也可以看看这篇论文的前几章。虽然论文写得比较早,但是对CPU 性能还是提供了一个比较好的视角。
除开 MonetDB/X100 之外,本笔记在第一段会介绍比较多 MonetDB 在提出 X100 之前的逻辑。
MonetDB
MonetDB 最早基于 内存映射文件 来避免使用比较复杂的 buffer pool, 与传统的 RDBMS 不同:
- 用 column at-a-time-algebra 取代 volcano 那类的 row at a time
- minimize CPU cache misses rather than IOs
- 用类似 database cracking 的技术,来合理的生成 index
- 运行时去优化查询
传统的数据库使用 tuple-at-a-time (比如一次 Next 拉一个 tuple), pull-based (上游有需要就走 Next), iterator 类似的 next() 拿下一条数据的形式。
MonetDB 最早支持对一批 column 进行同样的操作,通过编译器/手动实现优化,来增加对流水线的友好性,提高代码的 CPI.
Column-at-at-time 在最初是以 BAT(Binary Association Table) Algebra 的形式实现的,BAT 类似 <surrogate,value> ,前一个地址是虚拟的。读出来的数据、运算过程中的数据和结果都是以 BAT 的形式存储的。
BAT 运算也类似一种 IR,前端会把请求编译成 BAT Algebra, 给 backend,即执行 BAT Algebra 的部分执行。
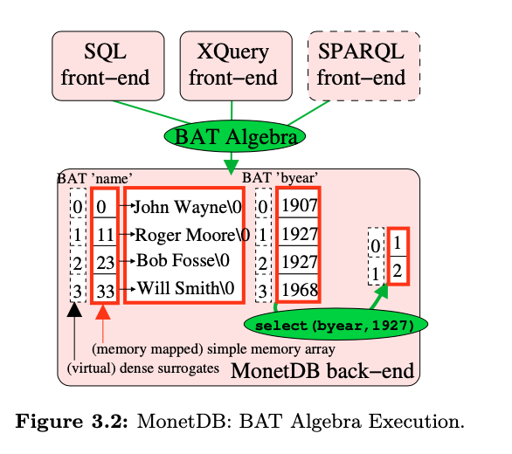
BAT algebra 针对一个 column 的所有数据执行简单高效的操作。它的思路是:
by making the algebra simple, the opportunities are created for implementations that execute the common case very fast.
为了处理更新,MonetDB 要给每个 column 准备一个 pending updates set. 读取的时候,要 merge 两边的请求。
CPU && DB
在 MySQL 等 RDBMS 中,代码的 CPI 比较低。而 05 年的时候,CPU 也在进行着发展,可以看下面两张图:
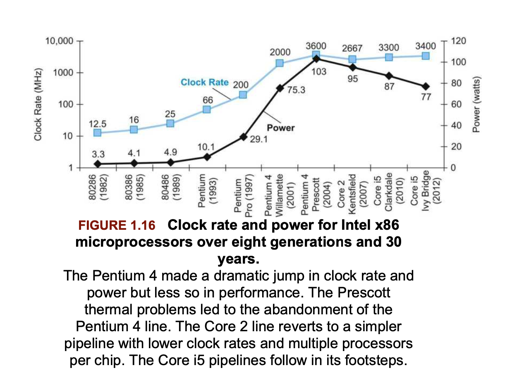
上面这张图介绍了单核的频率影响
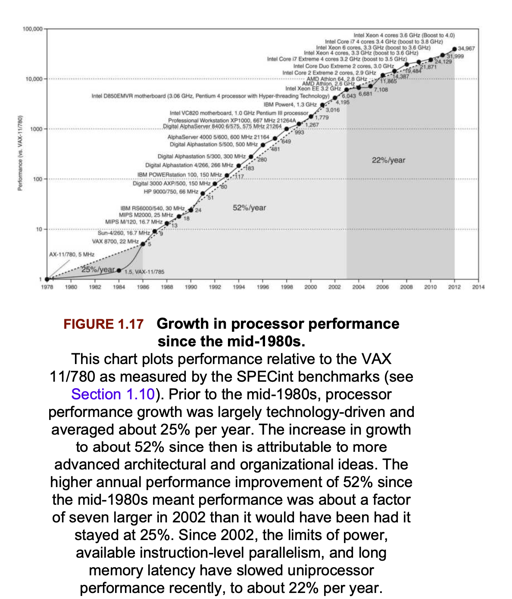
下面是 CPU 的性能。文章写于 05 年,可以看到当时的趋势。这篇文章聚焦在 Hyper-pipeline CPU 上,我看了下,感觉这个术语类似 superscalar。
文章认为,AP 型数据产品需要提升查询的性能,避免 CPI 低的情况。MonetDB 一定程度上优化了这一点,但是:
However, its policy of full column materialization causes it to generate large data streams during query execution.
上述内容中,我们还记得每次它扫一列,然后生成一个 BAT, 造成了很多额外开销。
所以这篇文章主要内容是:
Therefore, we argue to combine the column-wise execution of MonetDB with the incremental materialization offered by Volcano-style pipelining.
它提供了一个 X100 的 Query Engine。提供了 vectorized query processing model.
可以提供的优化
现代 CPU 靠 Pipeline 来优化性能,而 Pipeline 可能会有各种 hazard。此外,if-else-then condition 可能会在分支预测上影响性能。2020 年,branch mispredict 大概需要 3ns. 这需要 flush pipeline. 此外,现代 CPU 依靠多级流水线来优化吞吐量。
Translated to database systems, branches that are data-dependent, such as those found in a selection operator on data with a selectivity that is neither very high or very low, are impossible to predict and can significantly slow down query execution
此外,这里还有 hyper-pipeline 等技术,能够使用多个 pipeline, 使 CPU >= 1. 我个人感觉这篇文章的 hyper-pipeline 意思应该和现在 superscalar 差不多。
编译器一般会把能优化的代码尽量优化,一种有用的技术叫 loop pipelining:
1 | F(A[0]),G(A[0]), F(A[1]),G(A[1]),.. F(A[n]),G(A[n]) |
上述内容可以帮助 CPU 用 OoO 和 SIMD 等方式执行,提高并行度。此外,编译器还能试图优化 branch prediction:

最后一点与性能的最好的朋友和最大的敌人 cache 有关:
and can significantly improve if cache-conscious data structures are used, such as cache-aligned B-trees [15, 7] or column-wise data layouts such as PAX [2] and DSM [8] (as in MonetDB).
TPC-H 测试
在测试中,传统 DMBS 的 CPU IPC 只有 0.7 。而科学计算的 IPC 有 2. 论文选去了 TPC-H Query 1 作为了测试的 case.
TPC-H 数据基于 1GB 的数据仓库,可以根据 Scaling Factor (SF) 来更新这个大小。
传统 RDBMS 通常使用火山模型,同时要支持很多 flexible 的查询,这一点会大大影响性能:
For instance, even a simple ScanSelect(R,b,P) only at query-time receives full knowledge of the format of the input relation R (number of columns, their types, and record offsets), the boolean selection expression b (which may be of any form), and a list of projection expressions P (each of arbitrary complexity) that define the output relation. In order to deal with all possible R,b, and P, DBMS implementors must in fact implement an expression interpreter that can handle expressions of arbitrary complexity.
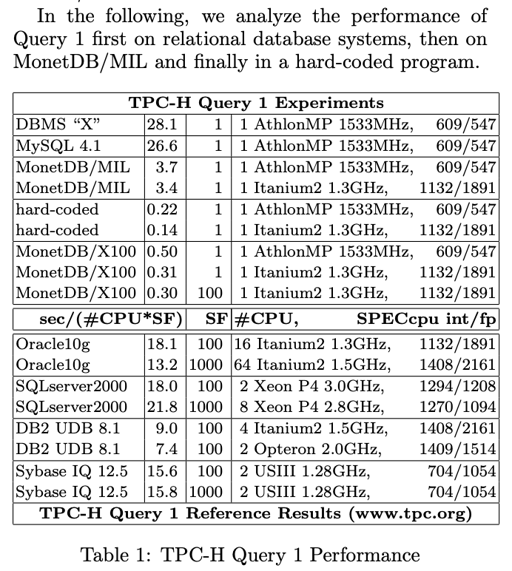
论文分析了 MySQL:
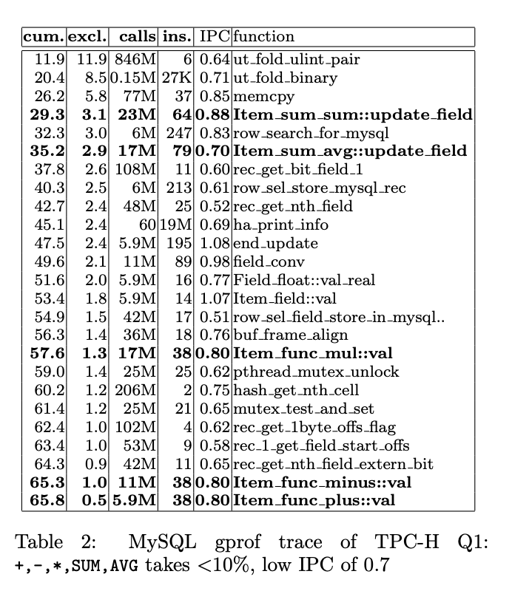
测试发现,大概很少量的工作在做实际的计算, 大部分 workload 都在 rec_get_nth_field 这种传来传去的东西上,还有 agg 的 hashset.
另外一项操作是 ::val , 这个从具体的内存中捞出需要计算的 int 或者 float, 这个地方相对来说也比较费:
A simple arithmetic operation +(double src1, double src2) : double in RISC instructions would look like:
1 | LOAD src1,reg1 |
MySQL 这个效率非常低。倒不是执行这几条指令会很痛,而是说,这里是可以更快的:
The limiting factor in this code are the three load/store instructions, thus a MIPS processor can do one *(double,double) per 3 cycles. This is in sharp contrast to the MySQL cost of #ins/Instruction-Per- Cycle (IPC) = 38/0.8 = 49 cycles!
利用上 loop-pipelining, SIMD 等技术,一起处理,能让这块性能大大提高。这一块的结论是:
Item_func_plus::val应该被 loop-pipelining 的处理,和我们之前说的一样,这里可以利用上 SIMD, 循环展开等优化。- 函数调用的开销应该被均摊。
TPC-H 测试 MonetDB/MIL
MIL 就是我们之前提到的 BAT 运算。他提取固定形状的参数,产生固定形状的结果:
1 | join(BAT[tl,te] A, BAT[te,tr] B) : BAT[tl,tr] |
MIL 的 Join 可能需要 reverse 等操作,这个可以见图:

需要注意的是,Join 需要的 reverse 不会实际拷贝。(肯定没那么傻)
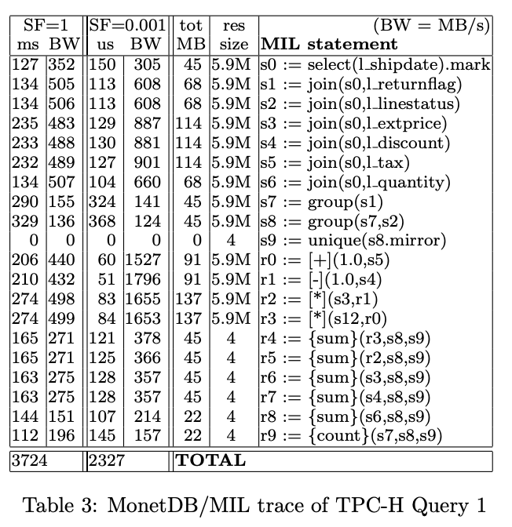
MonetDB 之前的计算 CPU 效果很好,但是 memory bandwidth 太大(因为全部一批处理 + 产生中间结果也是 BAT + mmap)。当数据规模很小的时候(SF = 0.001),bandwidth 可以很大,因为数据都可以 fit 在 cache 里。但是数据规模大的时候,Bandwidth 就受限于内存设备了,这会影响查询的效率。
当然,late materialization 可以一定程度上减少这个问题。用比较节省内存的表现形式,类似 c-store 中的 type 1-4, 只有需要的时候才 deserialize,能够提高这方面的性能。
此外,这里有很多个 join, 这些 join 是列的 join, 用来组成必要的行,可以看上面 figure 4.1。volcano + 行存,根本不需要执行这些 join
While in this paper we concentrate on CPU efficiency in main-memory scenarios, we point out that the “artificially” high bandwidths generated by MonetDB/MIL make it harder to scale the system to disk- based problems efficiently, simply because memory bandwidths tends to be much greater (and cheaper) than I/O bandwidth.
这里提供了一个 硬编码的高效 UDF,作为程序的baseline,这里启发了 codegen 等方法:

X100: A Vectorized Query Processor
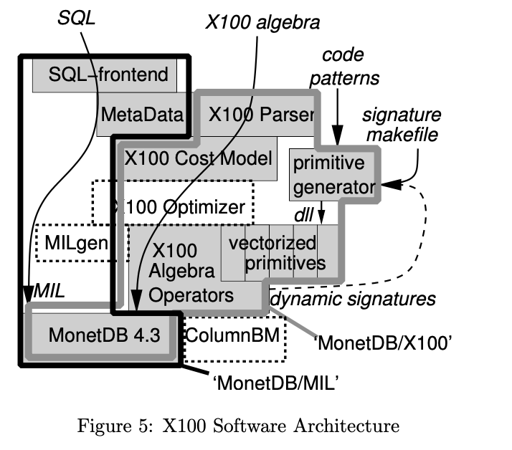
如上面的层次,X100 的目的是:
- 高效 高 IPC 处理大量的数据。
- 能够扩展,支持 SQL frontend
- 支持更大规模的存储
下面是相关的几个 part:
- Disk: 加入了 ColumnBM I/O 子系统,提供了一个水平分片的 I O访问接口和轻量的压缩。
- RAM: 这里引入了 memory to cache 等逻辑,在 memory 里面,很多东西都用压缩的格式存储,来节省空间和 bandwidth
- Cache: 这里用 vectorized processing model. 批量的处理数据,尽量能把这些东西丢在 cache 里。X100 会将大块的 BAT 内存切成这些 cache chunk, 在里面即使 random access 相对来说也比较友好。
- X100 试图 batch 处理数据,即使是 agg 这样的算子,也尝试做成 vectorized 的,这里可能依赖简单的 codegen. (agg 困难的地方是输出形状和输入不一样。)
最后的图可以跟上面的 figure5 看看。
Query Language
下面来看看具体的查询的执行:

这里会被推到:
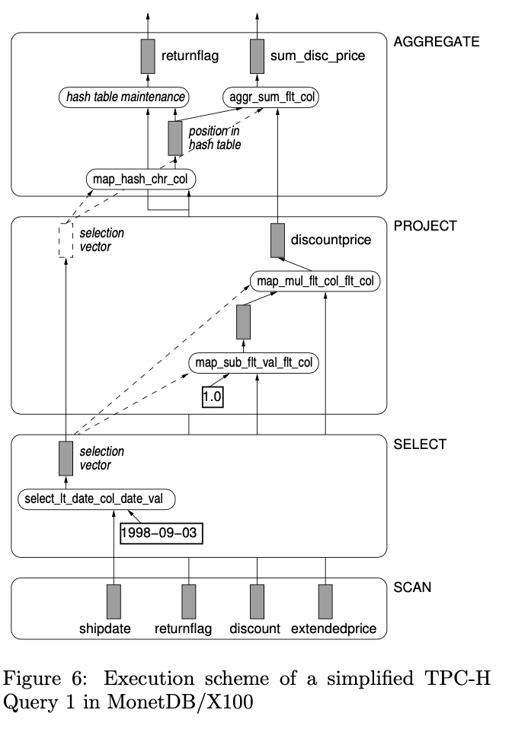
- Scan 每次突出一个 vectorize batch 的数据
- Select 筛选的时候,会产生一个 selection-vector,把过滤成功的填进区
- Project 用来投影。这里不会修改 vectorize 的数据,而是以
map原语类似的形式,拷到相同的位置中。 - 使用 Aggregate,这里因为
(3)和(2)的筛选,selection-vector 也需要传上去。
X100 Algebra
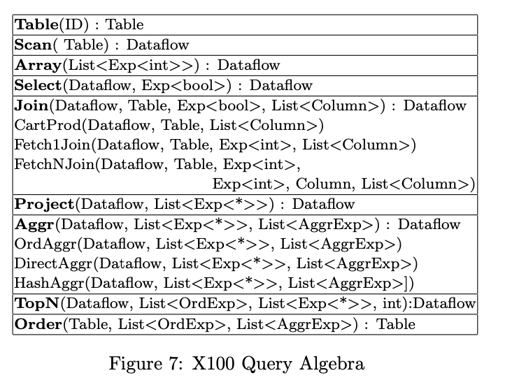
这里 Dataflow 是不断产生 vectorize items 的对象,Scan Order TopN 会产生一个 Dataflow,Project 会做转型,Aggr 会对 Group By 的对象去重,Array 会根据表达式产生一堆 N-dim array,用来把结果丢给 frontend system。
Aggr 和 Join 论文中提到了一点,不过有点老生常谈。就是怎么选算子的问题。
Vectorized Primitives
过去,实现可能会比较 flexible, 比如:
1 | /** |
这个是从 15-445 lab 抄出来的. 就比较 flexible. MonetDB 相反,使用相对定制的接口:
In a vertically fragmented data model, the execution primitives only know about the columns they operate on without having to know about the overall table layout (e.g. record offsets). When compiling X100, the C compiler sees that the X100 vectorized primitives operate on restricted (independent) arrays of fixed shape.
MonetDB 需要手动编码很多接口,来保证实现的高效,比如:

(上面 * 表示一个 sequence)

(你看一个加法写四遍,这得模版大师来写一套了)
此外,这里还支持 compound primitive signature :
1 | (square(-(double*, double*)), double*) |
这种组合的 primitives 能够提供两倍的性能优化,原因应该和访存有关:
The reason why compound primitives are more efficient is a better instruction mix. Like in the example with addition on the MIPS processor in Section 3.1, vectorized execution often becomes load/store bound, because for simple 2-ary calculations, each vectorized instruction requires loading two parameters and storing one result (1 work instruction, 3 memory instructions). Modern CPUs can typically only perform 1 or 2 load/store operations per cycle. In compound primitives, the results from one calculation are passed via a CPU register to the next calculation, with load/stores only occurring at the edges of the expression graph.
Storage
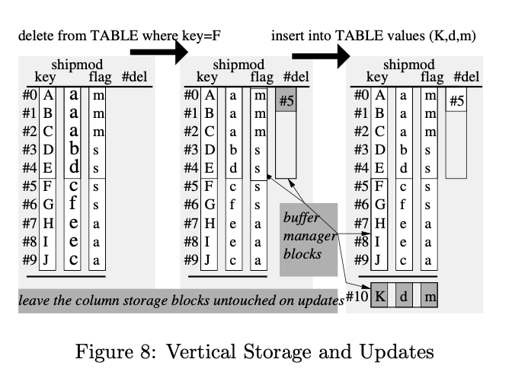
MonetDB 的 BAT 把相同的 column 存一起,而 ColumnBM 权衡了读写,把列存为大于 1MB 的 chunks.
它的更新操作如上图所属,把原本的视作不可变的对象,然后ColumnBM 实际上将所有 delta 列存储在一个块中,这等同于 PAX [2]。因此,这两种操作都只产生一个 I/O。更新只是删除后插入。更新使 delta 列增长,因此只要它们的大小超过总表大小的一个比较小的百分比,就应该重新组织数据存储(compaction?),以便垂直存储再次更新并且清空 delta。
TPC-H
再次跑 TPC-H 之后,X100 获得了没那么大的内存带宽和很好的性能,即使 SF=100,这里 RAM 开销也没那么大。Query 1 的 IPC 提升了很多:
A first observation is that X100 manages to run all primitives at a very low number of CPU cycles per tuple even relatively complex primitives like aggregation run in 6 cycles per tuple. Notice that a multiplication (map mul *) is handled in 2.2 cycles per tuple, which is way better than the 49 cycles per tuple achieved by MySQL (see Section 3.1).
测试还给出了 vector size 的影响:
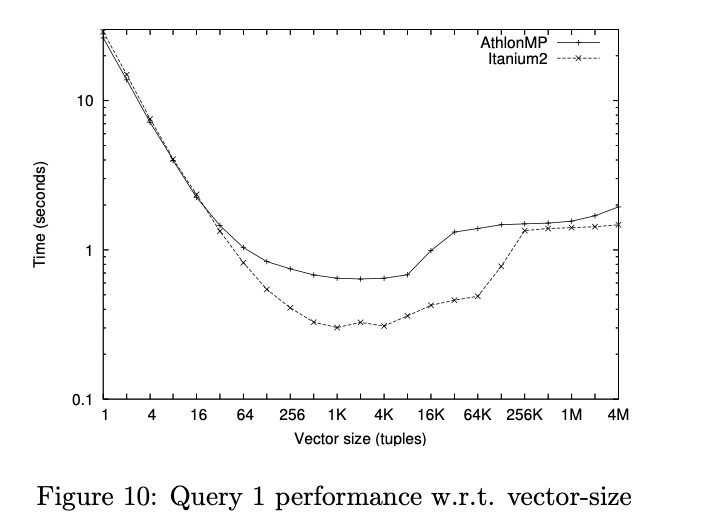
这里,比较明显的事,vector size 能在 cache 里面放下的时候,性能是提升的,当放不下的时候,开始访存,性能裂化。比较极端的情况就是回到 MonetDB/MIL 的情景。
Reference
- CIDR’05: MonetDB/X100: Hyper-Pipelining Query Execution
- The Design and Implementation of Modern Column-Oriented Database Systems
- Computer Organization and Design