VLDB05: C-Store: A Column-oriented DBMS
这篇文章是 C-Store 的一片阅读笔记,重点介绍的还是它存储数据的 schema. 并发这段我没看很细,就比较简短力图不出错的介绍了一下。写笔记这周在 oncall, 有点神智不清。如果哪有问题可以 评论或者 mail [email protected] 以指正。
C-Store 是一篇比较早的论文。它描述了一个读优化的 RDBMS,支持 SQL。它的设计目标是:
- 基于 column,而不是 row,来存储数据。
- 对数据在存储上,甚至在内存上做合理的 encoding,提高存储和查询的效率。
- 并非按照
<table, [Indexes]>这种模型来存储,而是按照列的 Projections 来存储 - 实现了 Transaction、高可用、Snapshot Isolation
- 用 bitmap 索引来优化了 C-Store 场景下的 B+Tree。
传统的 DBMS,因为希望有着良好的写入性能,通常会以行存的形式存储逻辑上的行。而数据仓库等系统,则通常会进行 bulk load 导入一批数据,然后进行长期的读。在这些场景中,将单列存储在一起,有机会获得更好的查询性能。
发表论文的时候,传统的 DBMS 会将列按原本的格式乖乖一个个存储,并 padding 到 byte/word 的粒度。这一点让 CPU 不用做 codec。但当时 CPU 正在变得越来越快,而存储 bandwidth 上升量没有这么快,所以需要权衡这种开销。论文提出存储的时候减少 bandwitdh 的方式:
- 把数据以一种更紧凑的格式存储,不用 padding 到 bits。例如 varint/只存需要的bits等形式。
densepack把上述格式在内存中连续存储(?) 这里我怀疑没读懂它意思
同时,这也要求我们尽量能够让 query executor 支持处理这种压缩过的数据。
DBMS 可能会有 table heap, primary index, secondary index. 这些结构并非 read-optimized 的。在后者的场景下,bitmap indexes, cross table indexes, materialized views 有更好的性能。基于以上原因,C-Store 存储 set{[一些columns]}, 其中,每个集合被称作 projections,组内按照同样的 attribute 排列。同一个列可能被存储在多个 projections 中,为了防止重复存储导致的空间过度放大,这里会采用多种上述说的存储格式的优化。
C-Store 的运行环境在设想中类似 MapReduce 论文中的环境,部署在一个巨大的刀片机集群上,同时不会共享存储。C-Store 并不靠 Walmart 一样的 replica 来保证 HA。它利用 projections 层面的列重复性来保证 HA。可以给 C-Store 一定的配置,来保证能容忍 k 台机器故障(即 K-safe).
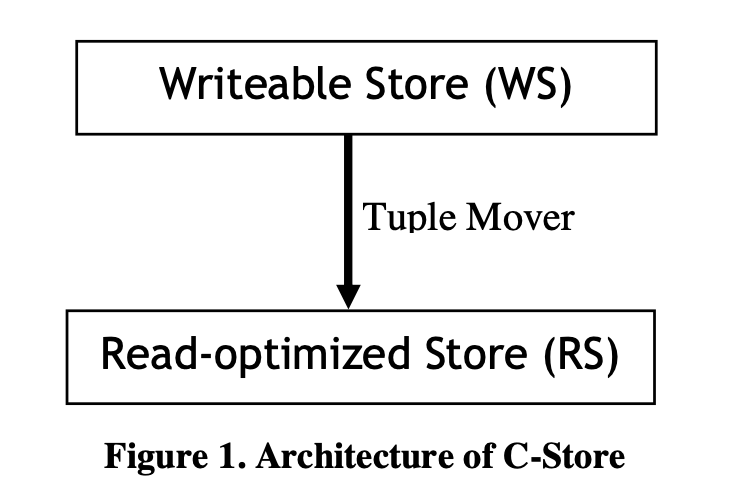
即使是 datawarehouse 类的系统,或者 CRM,也需要事务和简单的更新,来修正不正确的记录。(比如对账?). 对于 column store 而言,所有 column 都按照某个逻辑顺序排序,同时插入按照某种情况单向插入,可以获得很好的写入性能,但是读取性能又不会好。所以这里有上述的 WS 和 RS,和可以 Tuple Mover。需要注意的是,这里 WS 也是 column oriented 的。
在这里,写入会被写到 WS 中,删除需要 mark 在 RS 中。Tuple Mover 类似 LSM-Tree,定期把数据 bulk load 到 RS 中。读取的时候,系统会选择一个小于最近一个 commit 的时间戳 T,用它来构造 snapshot。通过这种模式来 historical mode read。
最后,这里需要构建一个 column oriented 相关的 query optimizer 和 query executor。
论文认为自己的创新在于:
- WS/RS
- 多个不同排序的 projections
- 高度压缩/提供多种编码方式的的 columns
- 列存优化的 query optimizer 和 query executor。
- 基于 projections 的 HA 和 K-safety
- 用 SI 来避免读取的时候走 2PC
数据模型
C-Store 支持标准的关系模型。也就是说,它在 逻辑上 存储的数据和 MySQL, PostgreSQL 这些并没有什么区别。但是实际上,它需要支持转化为对应的 projections
举例说,下面一张 RDBMS 的表,和 DEPT 的表关联着:
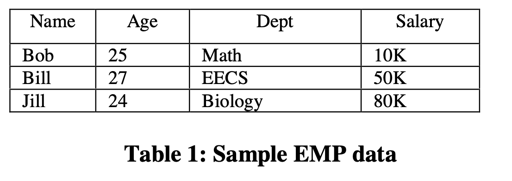
在 C-Store 中,存储逻辑类似:

在每个 projection 中,如果有 k 列,那么会有 k 个存储单列的数据结构。它们按照其中的一列 sort key 来排序。
每个 projection 都会水平分片到至少一个 segments 里面。C-Store 的 partition 是基于 sort key 来进行 partition的。每个 segment 都会有个 segment identifier, Sid. 这个数字要求大于0.
当需要处理 SQL 的时候,请求会处理相关的 projections. 但同时,c-store 需要把几个 sort key 不同的 projections 组合成要返回的数据,这实际上依赖一个类似 join 的功能。c-store 依靠 storage keys 和 join indices 来支持这些操作:
- storage keys 是针对 segment 而言的,这个被称作 SK. 在 RS 的同个 segment 中,不会实际存储 SK, 他们就是 1, 2, 3… 这样按顺序排列。(然后你也别问我为啥不是0开始的)。在 WS 中,他们需要维护这个,这和 WS 的结构和逻辑有关。
- Join Indices 是一个额外的索引,用于把 projection X 的
<SegmentID, SortKey>按顺序映射到另一个 projections 中,这个结构维护是比较昂贵的。

In practice, we expect to store each column in several projections, thereby allowing us to maintain relatively few join indices. This is because join indexes are very expensive to store and maintain in the presence of updates, since each modification to a projection requires every join index that points into or out of it to be updated as well.
C-Store 通过上述的把一列存储多份,然后实现了恢复机制,来做到 k-safety. 这也需要定义的 schema 的支持。
RS
RS 部分是一个读优化的列存储,论文主要介绍了它的存储优化和 Join Indexes, 论文分成了几部分讨论数据的 codec, 实际上未来还有一些更好的方法,但是文章给出的方法还是比较有代表性的:
Type 1:有序的且大部分值相同的序列
这种序列用 (v, f, n) 来表示
f is the position in the column where v first appears, and n is the number of times v appears in the column.
为了支持 query, c-store 对这个结构支持了 B树索引,加快了对这个内容的查找。
Type 2: 无序且大部分值相同的序列
这种序列用 (v, b) 来编码,v 是可能的值,b 是是这个值的数的 bitset:
For example, given a column of integers 0,0,1,1,2,1,0,2,1, we can Type 2-encode this as three pairs: (0, 110000100), (1, 001101001), and (2,000010010).
这里也实现了 <position, value> 的 B+Tree 查找结构。
Type 3: 有序且值较少相同的序列
采用 Delta 的形式进行编码(我感觉这里有点怪,因为 delta 本身应该和压缩没关系,感觉像是用了 delta + varint 啥的…)
Type 4: 无序,且值较少相同的序列
这里没提具体怎么做,就提了一下目前是啥都不做,但是在探索了:
If there are a large number of values, then it probably makes sense to leave the values unencoded. However, we are still investigating possible compression techniques for this situation. A densepack B-tree can still be used for the indexing.
Join Indexes
As noted earlier, a join index is a collection of (sid, storage_key) pairs. Each of these two fields can be stored as normal columns.
这个就和之前提的差不多,看上面那个figure 应该就明白了
WS
为了避免把优化器搞得太复杂,这里 WS 也用了 projection 和列存的模式,和 RS 有相同的 projections 和 join indexes.
这里的 SK 和 RS 中的 SK 不同,每个逻辑 tuple 都有相同的 SK, 然后需要存储这个字段。SK 要比 RS 中所有的 SK 都大。(实际上这个地方需要 tuple mover 的协助)。
RS 以 (segment id, SK) 标志一个对象,实际上 WS 于 RS 有相同的逻辑 segment. 这里认为 WS 的大小相对 RS 来说非常小,所以没有对内容来进行压缩优化。
下面就是 WS 实际的结构,WS 每个列都被表示为 (v, sk) 。此外,还有一个 (s, sk) 的 B-Tree 结构,s 是 sortkey, sk 是 WS 列的位置。实际上这相当于 append only 的 heap tuple 加一个 index.
然后再回到 Join Indexes, 每个 Projection 分为 segment in RS + segment in WS. Join Index 存储了驱动表(sender) 到目标表 (receiver )的记录。
Storage Management
C-Store 又一个 storage allocator, 它会动态调整 Segment 的分区,或者申请 Segment. 这里,假设 RS 要调整分区,那实际上对应的 WS 和与 RS 相关的 Join Indexes 也需要对应的调整。
Update and Transactions
这一部分感觉逻辑还是比较难的,C-Store 提出了一个修改过的 2PC,然后用 epoch 相关的协议,来实现 Snapshot Isolation.
Update 更新的时候,需要创建 Storage Key, 这里 Tuple Mover 和 WS 维护,保证这个 Storage Key 一定大于 RS 中的任意 key。这里在 BerkeleyDB 上构建了 WS,并要求使用一个比较大的 Buffer Pool, 来保证较高的写性能。这里,C-Store 只希望有写相关的事务,它通常用 snapshot isolation 的模式来读取,所以系统不需要设置 read lock.
系统把 Snapshot Isolation 可以读的,即不会和写入干涉的时间戳称为 high water mark (HWM). 同时,系统不希望支持 time-traverse, 所以系统设置了一个 low water mark (LWM) 来做一个时间的低水位。在 LWM - HWM 中的东西是可读的。LWN 之前的删除可以尝试被 GC 掉。
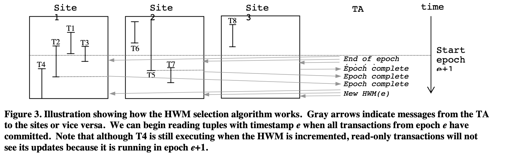
这一段的逻辑感觉是比较杂的,写入的时候,这里有个中央时间管理器 TA,它会定期前进,当事务都完成的时候,它会做一个发号,然后让系统走到下一个 epoch,然后推高 HWM(我感觉 LWM 也可以由读事务结束和 lastmove 来推高). 为了处理时间回卷的逻辑,这里设置了一个 Wrapping: 保留最低时间戳,防止不正确的回卷。
对于并发来说,只读事务会走 LWM-HWM 间的 SI,读写事务走 2PL,遵循 NO-FORCE + Steal 语义。系统不会做 REDO, 一旦丢失数据,会走从 Projections 中 Recover 的逻辑。同样的,系统的 2PC 也没有 Prepare.

系统的 Recover 如上所述。
Tuple Mover
Tuple Mover 需要做的是逻辑上的合并操作。根据 LWM HWM 来决定保留什么样的数据,然后做合并,再更新。