Note on System Design Interview
System Design Interview 介绍了 system design 的一些面试题,也介绍了分布式系统上的一些 building blocks. 这本书介绍了一下这些内容。
这本书逻辑上大概分为两部分:
- 介绍分布式应用的 building blocks
- 介绍一些分布式系统常用组件的实现方式。
- 介绍一些大型 web 应用的架构。
Part1 building blocks
这里的客户端/user 一般指的是 web 或者是移动端的 app. 这些通过 dns 来拿到服务器的 ip, 然后访问服务器。
同时,数据存储通常会丢到某个 db 上。按需求选择 MySQL MongoDB 这些选型。
说句实话一般网络 app 这些东西就够了。但是大型应用这样就等死吧。
Load balancer
一般需要负载均衡来处理一些问题,nginx, haproxy, envoy 都有这些功能。
(这里注意一下有个 L4/L7 负载均衡的区别)
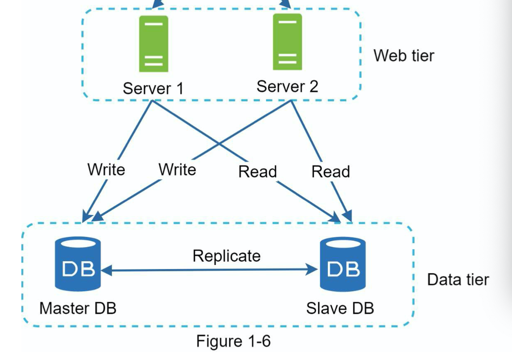
Database application
无论是 master/slave 然后挂个什么方式,可以做 db 的主从备份、在业务测切分 db。
当然也可以用分布式的 db, 不过有的时候你还是要 manage 一些数据分布之类的问题的:
cache
没有需求上缓存属于折磨自己:https://www.zhihu.com/question/383926405
但是有需求的话,缓存能够起飞。
缓存的架构也很复杂,我之前读过一篇 fb 的论文:
然后还要区分下 write through cache/write aside cache.
这本书提了一下使用 cache 需要提前设计的几件事:
- Eviction policy
- mitigating failure
- consistency
- Expiration policy
- Decide when to use cache
CDN
CDN 从一个类似 amazon s3 的服务拉内容(当然,直播的话会更复杂)
- cost (真实…)
- cache expiry
- CDN fallback: CDN 挂了怎么办
- Invalidating files
Stateful/Stateless
Stateless 的通常可以直接起飞,快乐扩容,但是很多时候也需要访问 stateful 的 db 这类的资源,访问 shared storage 这类。
Data Centers
很多时候,业务部署都需要多个 DC,一个地方机房过热,可能受灾就有多机器全挂了。
DC 需要考虑流量调度、数据同步、测试,但也给了系统更好的稳定性。
对于基础组建而言,多数据中心同步还是一个很麻烦的问题,因为 latency 高,流量贵。
Message queue
对业务而言,mq 意味着某种形式的解耦。用户可能希望希望:
- 丢就丢了,随便你怎么处理
- 希望 exactly once 之类的语义。
Logging, metrics, automation
查过问题懂得都懂。虽然我不是很懂 logging…
wrap up
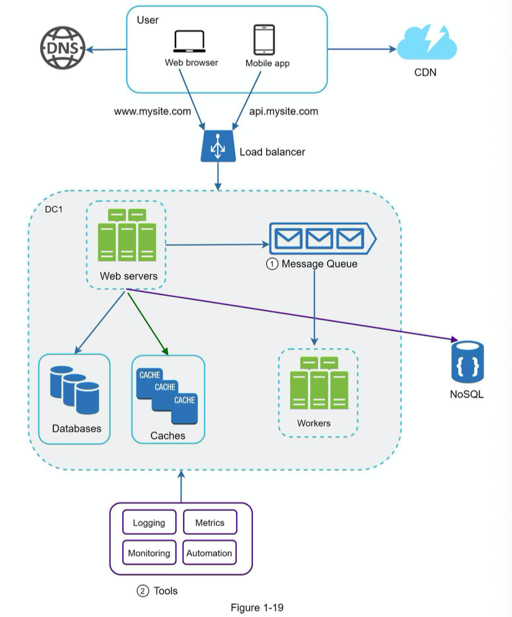
量级估计
这个可以参考 every number programmers should know, 又一个每年都会更新的网站,可以找找看。
然后知道 MB GB PB 有多大(我需要天天算这个哈哈哈)
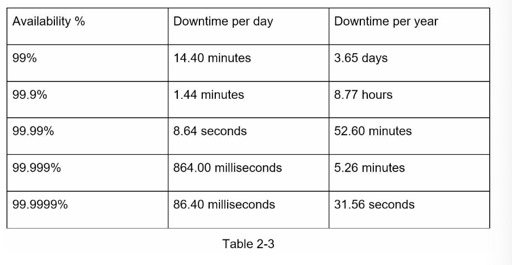
这里还有对 QPS 和 Peek QPS 的估算(实际上我感觉真实情况还是要看统计数据什么的)
Part2 组件和实现
Rate Limiter
为了不发现暴写就等死,可以做一些组件上的限流。
此外,业务本身也会自己估一个 QPS,这个虽然比较粗略,但是也能做一个基本的限制。限流在这方面可以给自己系统一个很好的保障。
这个可以以客户端的形式提供,也可以做成一个 api gateway,在 QPS 过高的时候返回一个 HTTP 429。
RateLimit 有下面的算法
- Token bucket
- Leaking bucket
- Fixed window counter
- Sliding window log
- Sliding window counter
我这里搓了一个简单的单机 leaky_bucket.rs : https://github.com/mapleFU/md-snippets/blob/master/components/ratelimiter/src/leaky_bucket.rs#L36
参考了:https://github.com/uber-go/ratelimit/blob/main/limiter_atomic.go
实际的数据可以存储在 Redis 这样的地方,让这个组件能够 scale. 同时,为了处理 Redis 这方面的并发操作,可以使用 lua script 或者 sorted sets data structure。
Consisteny Hashing
这节内容没啥讲的,基本和 Dynamo 那篇论文差不多。和 Chord 这篇论文的不一样. 这个是应该假定有 proxy 的
consistent hashing 我推荐再看看 Jump Consistent Hashing, MagLev. 这两个都是 Google 提出来的。
https://writings.sh/post/consistent-hashing-algorithms-part-2-consistent-hash-ring
上面这篇博客是我找到的最好的相关博客。
Key-Value Storage
这篇也基本是 Dynamo. 我觉得有兴趣可以看看 Spanner
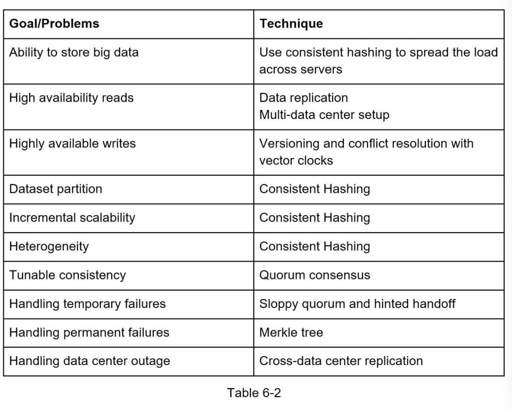
这个 cheatsheet 倒是挺有意思的,看完 dynamo 论文可以回头看一眼。
Unique ID Generator
这个其实也看对 Unique ID 的需求的:
- 是否要强有序?或者比较弱的有序?
- 你的 id 需要多少位?
下面有几种方式:
一:走 DB, 然后 db 可能可以多个 master. 比方说有 k 台机器,然后每台机器递增,然后对外提供就是:如果来自第一台就是 1, 1+k, 1 + 2k… 如此类推。
这种方式在多 DC 的环境下不太好处理,同时服务器增加的时候,不是很好处理。
然后其实也可以参考美团的 leaf: https://tech.meituan.com/2019/03/07/open-source-project-leaf.html
二:UUID
A UUID is another easy way to obtain unique IDs. UUID is a 128-bit number used to identify information in computer systems.
UUID 有几种不同的生成方法,比如 UUID V1 V2 V3 V4. 通常我们可以用 v4 来高一些随机生成
当然,uuid 也可以根据别的一些信息来生成。
三:Ticket Server
用 Etcd 之类的方式来发号,这个比较类似 PingCAP 的 PD 了。
四:twitter snowflake
这个是根据机器 ID 和时间来发号的。注意这个时间应该采用递增的时间,而不允许回退。
我写了个简单的实现:https://github.com/mapleFU/md-snippets/tree/master/components/snowflake
URL Shortener
URL Shortener 通常有要求是:
- 不能重复。
- human readable
这个内容也可以生成验证码。然后存到 db 里面,因为要做去重。这里 db 可以糊一层 cache,但是感觉 bloom 不太好搞,因为 down 掉了感觉恢复起来不晓得咋搞。
这里我也搓了一遍(不过就只有算法,DB 交互只写了个接口):https://github.com/mapleFU/md-snippets/tree/master/components/url_shortener
Part3: Systems
Web Crawler
Web crawler 需要:
- 给定一些 Seed, 然后从这些网页开始拉
- 能够拉取 robot.txt 遵纪守法;然后要有一定反爬能力
- 需要能够解析网页,找到对应的信息
- 按照 BFS/DFS 的策略,从已经爬到的链接里拿到后面的目标
- 防止无限递归的网址/反爬策略把自己搞傻了
- 对网络的访问不要过于频繁,要限流
- 要能够合理处理 timeout
- 但同时,需要有分布式的爬取能力
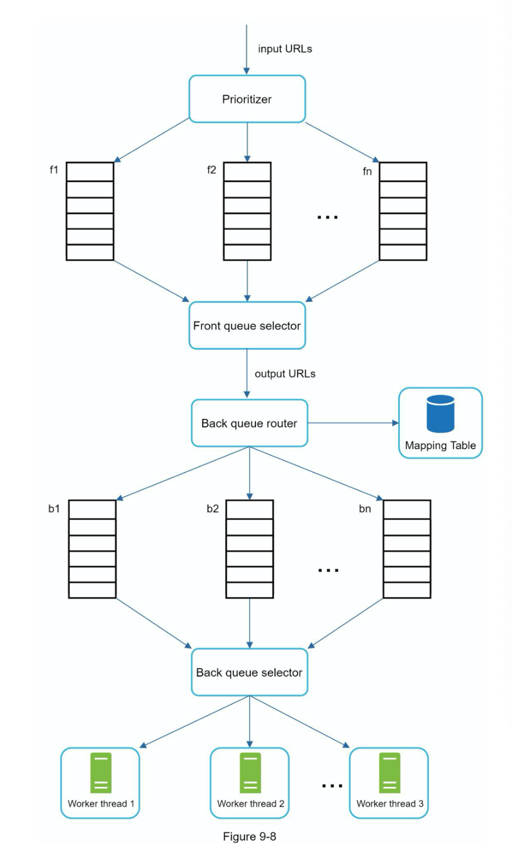

这里我觉得这个架构还是有点像 Scrapy 的,看了一下 scrapy:
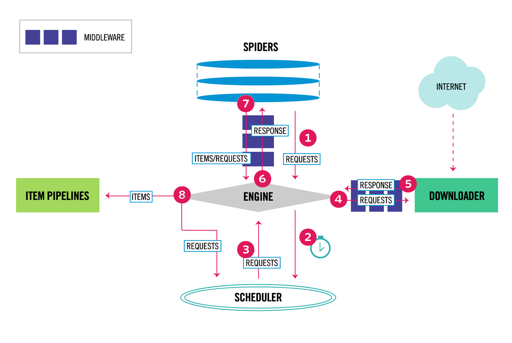
这里有一些中间件,就是上图的 extension model.
Scheduler 可能可以有一个 Redis 后端,用来调度下一个应该抓的 URL, 然后这个发给 downloader, 走逻辑下载,再回到 engine, 丢给 spiders 的中间件做一些扩展处理,最后把内容丢给 item pipeline.