Notes on <LSM-based Storage Techniques: A Survey>: Part 2
LSM-Tree improvements
尽管现在 LSM-Tree 被用到了多种 NoSQL 中,但是原始的 LSM-Tree 仍然有下面的缺点:
- 写放大:LSM-Tree 能比 in-place update 提供更好的写性能,但是 LSM-Tree 的 compaction 会造成不小的写放大。如我们之前分析的, Leveled Compaction 每层每个 key 需要写 T 次。而多层又会乘以另一个系数。这种写放大不仅会限制写性能,也会很快速的把 SSD 盘写坏
- Compaction 操作:LSM-Tree 有很重的逻辑都和 compaction 有关,所以要非常谨慎的实现 compaction 操作。此外,compaction 可能会造成 Write Stall,或者是查询的时候,因为产生了不在 cache 中的新文件,对新文件有 cache miss.
- 硬件:原始的 LSM-Tree 是以 HDD 为 C0 外其他组件存储来实现的,它的顺序写入比随机写入快很多。现在我们进入了大内存、SSD/NVME、NVM 的时代。为了适应这些新的存储,LSM-Tree 需要对应的改进
- 特殊的 workloads: 可能有一些特殊的负载,可以需要特殊的 LSM-Tree,提供能好的性能,比如 append 占绝大多数的 (mq 中),或者 key-value 小的,能全部装在 memory 中的… 对于这些可以设置特殊的结构
- secondary indexing: 对于 LSM-Tree,大部分基本实现提供了一个简单的 k/v 接口. 如果我们把这个 模型视作
<key, Tuple>,那么访问的时候,如果查询非 key 的某个 tuple 中的元素,则需要额外支持。一些 LSM-Tree 变种对这种负载提供了很好的支持。

以上一张图是论文对这个优化系谱的描述,这里只介绍 1-3。下面我们将一个个介绍这些优化。需要注意的是,由于笔者能力所限,这些介绍可能会有纰漏或者错误。欢迎读者指正。
减小写放大
大多数减小写放大的内容和 tiered compaction 相关。需要用到我们之前介绍的 vertical grouping 或者 horizontal grouping:
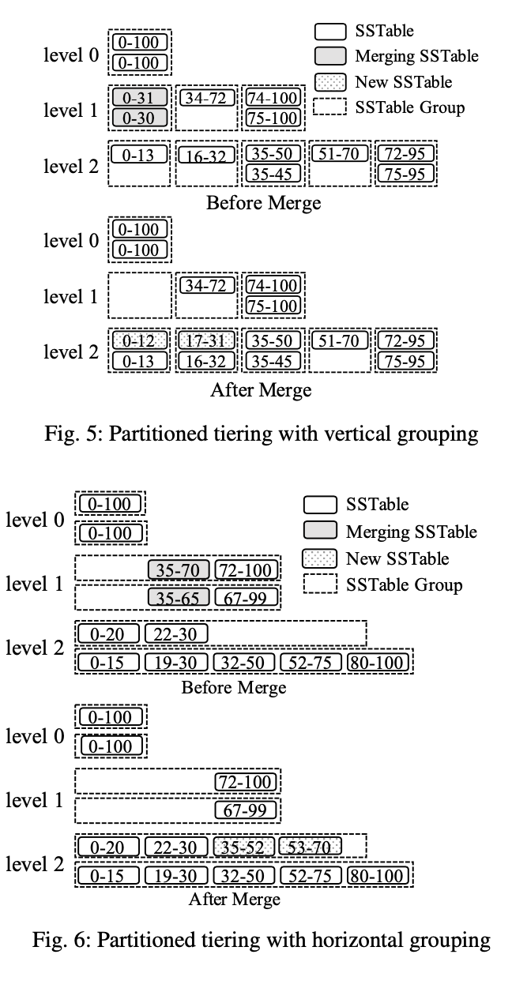
利用这种 grouping,权衡一定的读写放大。
WriteBuffer Tree
[1] WriteBuffer Tree 可以被当成 vertical grouping + tiered compaction 的变种。它出自 Design of a Write-Optimized Data Store 。
看看 WB-Tree 论文的介绍:
WB Tree, an unordered key-value store optimized for high insert performance while maintaining fast random read access.
所以需要注意,它是不支持 range 的。
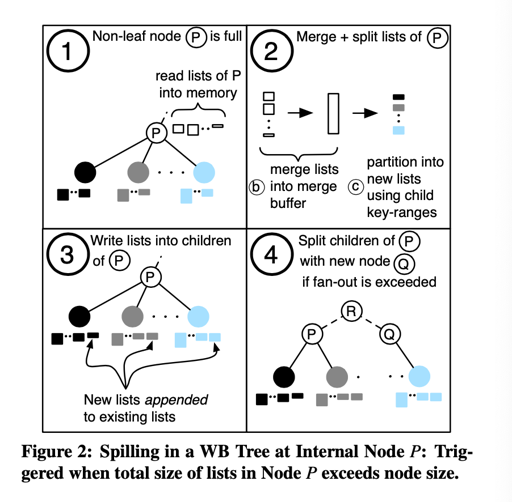
如上图所描述,它利用 hash-partition, 让每个 group 存储差不多的数据量,然后用 B-Tree 类似的结构,组织这个树。
当一个 non-leaf node 满的时候,它会执行 spill: compaction 然后写到 children 里。这里是 append 进去的,所以写开销相对小。
当一个 Leaf node 满的时候,它会执行 split, 分裂到两个叶子结点中。
LWC-Tree
LWC-Tree 可以参考这个 slide : https://www.storageconference.us/2017/Presentations/CompactionTreeToReduceIOamplification-slides.pdf
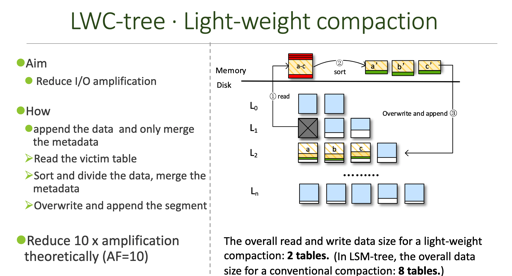
这里,把 compaction 变成了 light-weight compaction。作为添加到 sstable 中。
这种方法的困难是,需要能够处理 metadata. 因为 SSTable 的 index block 可没那么聪明。所以这里设计了一个对应的 DTable.
PebblesDB
PebblesDB 认为写放大的根本原因是,多次 rewrite data to the same level. 所以他认为,需要维护每个 level 的没有交集的文件。
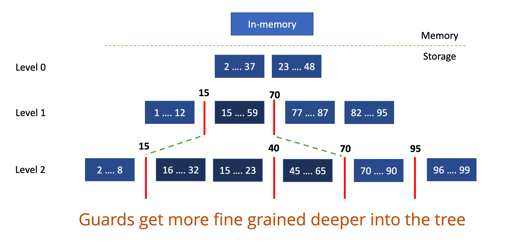
它使用 Guard 来切分这些文件。
dCompaction
dCompaction 维护了虚拟的 SSTable:
A virtual merge operation produces a virtual SSTable that sim- ply points to the input SSTables without performing actual merges. However, since a virtual SSTable points to multiple SSTables with overlapping ranges, query performance will degrade.
实际上我觉得这相当于一个懒惰的 merge ,这样会降低 query 的效率。所以根据 query 的次数触发 compaction。
上面这些方法都部份类似 tiered compaction + vertical grouping。
merge skiping
skip-tree 的设想是,一个 level 0 在 compaction 的时候,直接到达没有 overlapping 的最大层。
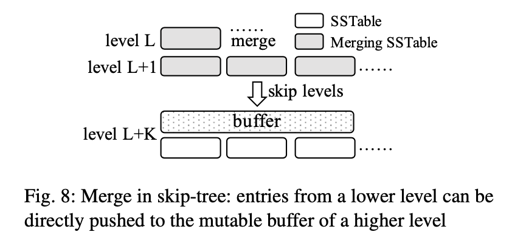
如果 merge 的时候,某个 key 在下面层都没有,那么久 skip 到最下层,每层有个 mutable buffer. 会写到这个 mutable buffer 里面。为了减小日志开销,这里只会 log merge 的 key, 让 replay wal 的时候,能够找到原来 SSTable 中的 key, value。
这种方法目前并没有怎么采用,因为管理 mutable buffer 和 merge 过于复杂。同时,相关的性能很难分析。
Exploiting Data Skew
TRIAD 在有 hot key 被频繁更新的时候,可以减小相关的写开销。它的基本 idea 是把 hot-key 做成某种 in-memory db 的结构。
减小写放大:总结
以上的写放大优化,大部分生成自己能够显著提升 LSM-T 的写性能。但是这些结果通常比较难评估,同时 RocksDB/LevelDB 默认还是采用了比较朴素的策略。此外,他们对空间放大从来也没有那么在意。
优化 merge
merge 相关的优化包括改善 merge 性能、减小 buffer cache miss、避免 write stall
改善 merge 性能
VT-Tree 做了一种优化:merge 的时候,如果一个 sstable 和别的 merge 目标没有重复空间,那么下层直接指向上层对应的内容。
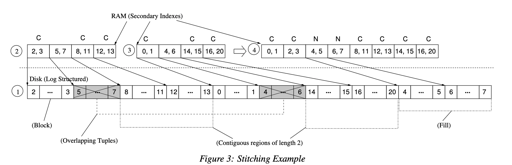
这里优化了 compaction 的性能,但是造成了碎片化。VT-Tree 添加了一个 stitching 阈值 K, 超过这个阈值的时候,相关的内容会被黏合到一起。
此外,这里 merge 的时候,因为 bloom filter 不能合起来,所以采用了 quotient filters。这种类型比较难实现,但是功能强大,能够合并起来。
此外,还有将 compaction 的过程 pipeline 的设计:
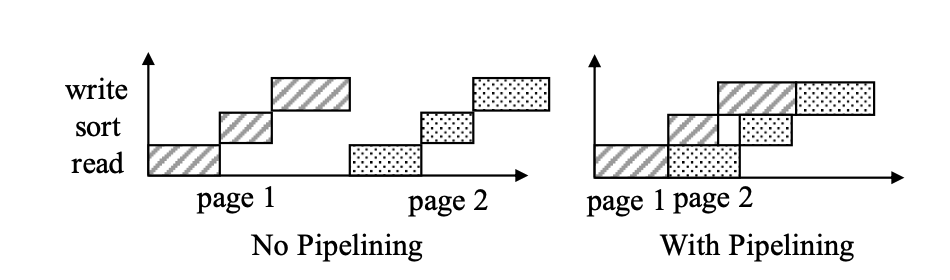
这里把 compaction 分成三个部分:read — write — sort. 这里认为 read/write 是 重IO 的,作者认为可以将这几部分流水线处理。
减小 cache miss
产生新的 component 的时候,相关的内容可能因为没在内存里,产生大量 cache miss.
有一种方法是,产生新的 component 的时候,可以 warmup 相关的内容。慢慢从旧的 component 灰度到新的内容中。用这种方式均摊暴涨的 cache miss。
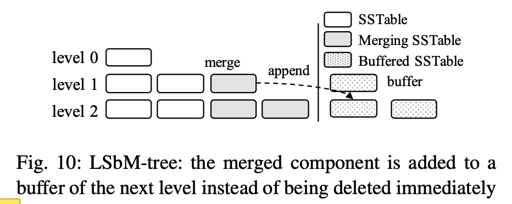
LSbM-Tree 提供了另一种方法,上层 merge 的时候,直接把对应缓存的内容推到下一层,等它们被 LRU 之类的算法换出。不过:
However, this approach is mainly effective for skewed workloads where only a small range of keys are frequently accessed. It can in- troduce extra overhead for queries accessing cold data that are not cached, especially for range queries since they can- not benefit from Bloom filters.
minimize write stalls
bLSM 为了 unpartioned Leveled compaction 而设计,它给 LSM-Tree 每层添加了额外的调度组件。当需要 compaction 的时候,它等待上一层往自己这层 compaction 完,在进行操作。这最终限制了写入的速度和 SSD 写入的数量。
当然,作者批评 bLSM-Tree 没有考虑这个等待相关的 queuing latency.
硬件
原始的 LSM-Tree 是以 HDD 为 C0 外其他组件存储来实现的,它的顺序写入比随机写入快很多。现在我们进入了大内存、SSD/NVME、NVM 的时代。为了适应这些新的存储,LSM-Tree 需要对应的改进,来针对上述这些介质提供好的性能、高效的操作。
big-memory
FloDB: Unlocking Memory inPersistent Key-Value Stores 这篇论文提出了 FloDB.
作者认为,对于大的内存 components, LevelDB/RocksDB 这些效果并不好,于是它使用了 HashTable 来做一个写入层。
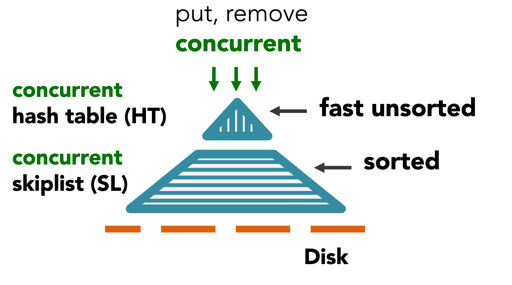

作者认为这样能提高 大 memory components 的写入性能。
Multi-Core
Scaling Concurrent Log-Structured Data Stores 提出了 cLSM:
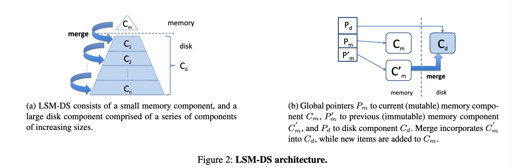
cLSM 提供了一种 Non-blocking synchronization,不过我简单看了下,感觉现在 LevelDB, RocksDB 都差不多是这样…如果我感觉不对可以提醒我。
SSD
与传统的盘不同,SSD的随机读写相对来说速度不俗。
FD-Tree 用类似 LSM-Tree 的方式来减小 SSD 的 random write. 它插入了不少 fence pointer
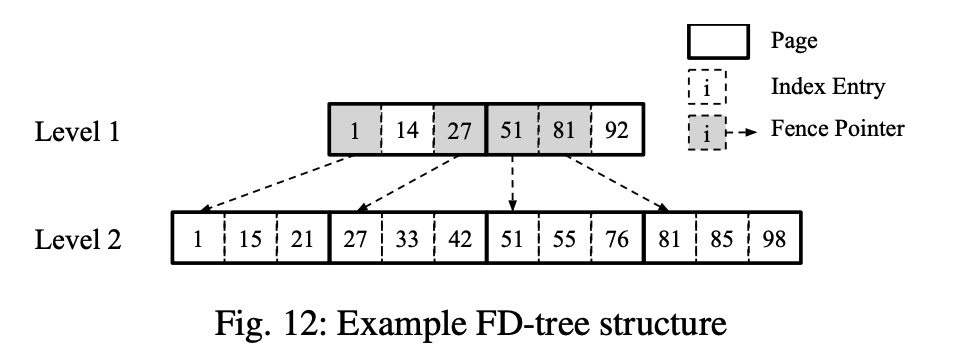
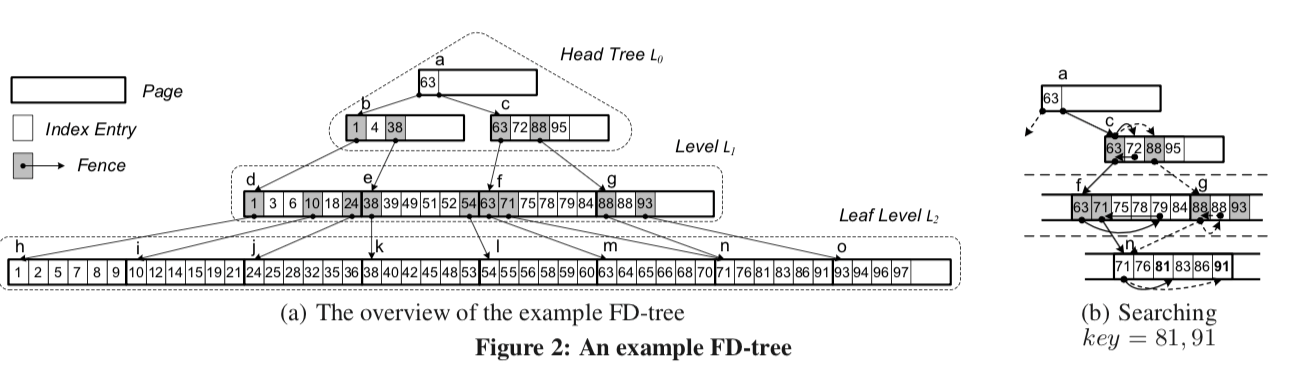
FD-Tree 算是 BTree LSMTree 的缝合怪,论文这里提到他是因为这里用 fence pointer 代替 BF。
当然,这里提升了查询效率,但是差不到的东西还是要从头查到尾。所以现在的很多结构还是用 Bloom Filter.
MaSM: Efficient Online Updates in Data Warehouses 提出了 warehouse 相关的 WaSM
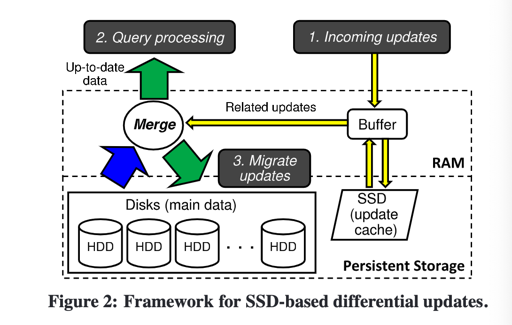
这里相当于维护一个写结构,然后 main data 放在满的 HDD 上,做读结构。Buffer 做 tiered compaction,最后丢到 main 上。
SSD 支持很快的 random read, 所以,分离 key-value 成了改善写性能的好办法。WiscKey 就是这么做的。
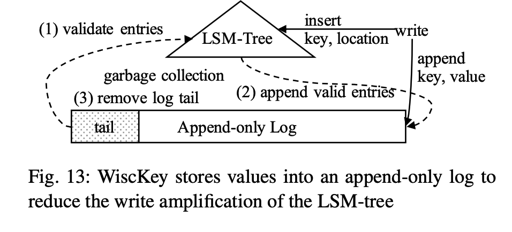
在 WiscKey 中,LSM-Tree 只维护了 <key, 索引>, value 被 append 到另外的地方。
WiscKey 会有专门的任务来 GC, 它会走三步:
- 从 WAL 尾部开始,查看这个 entry 存不存在
- 写 valid entries
- 移除掉尾部的数据
In WiscKey, garbage-collection is performed in three steps. First, WiscKey scans the log tail and validates each entry by performing point lookups against the LSM-tree to find out whether the location of each key has changed or not. Second, valid entries, whose locations have not changed, are then appended to the log and their locations are updated in the LSM-tree as well. Finally, the log tail is truncated to reclaim the storage space.
这个 GC 已经成为了新的瓶颈。而 HashKV 通过添加了一层 hash partition, 来减小了这样的开销。