Distributed System: Master
上一篇文章中,我们介绍了 CPU 的 cache coherent 机制和两种实现方式的基础内容,同时介绍了分布式系统的 Lease 机制。这篇文章我们将回顾一下用到 Lease 的系统,同时介绍一下分布式系统的主节点操作:这也同时会涉及 ZooKeeper, Redis 和分布式锁相关的内容。
Problems
我们在介绍 Lease 的时候,引入了假设:Clock Drift 在一定范围内。我们会看到今天介绍的内容中,仍然有一部分系统是依赖这个假设的。
尽管 gettimeofday 调用是线程安全的,但是分布式系统的时间永远有种种问题。
可以简单阅读: https://tldp.org/LDP/sag/html/keeping-time.html
为了理解这个问题,不妨看一看 rCore 产生 timer interrupt 的代码(这个是教学用的,可能实际的会复杂一些):
1 | /// 设置下一次时钟中断的时间 |
- 硬件有一个 Monotonic 的时钟,在启动之后能够拿到自己的
tick。但是,可能是没有什么表意的。 - 我们也有
gettimeofday这样的调用,我们可以知道时区之类的信息,但是由于种种原因,我们的时间很可能是不准的。假设开启了 NTP, 我们甚至有可能进行短暂的回退。
上面的内容在语言的库层面也有支持,比如 C++ 的 chrono , 你可以简略阅读 cppreference,或者阅读这里:https://www.modernescpp.com/index.php/the-three-clocks
所以,简单来说,依赖什么时钟,怎么依赖时钟,都是一个问题。
Lease 和 主操作
回到 Lease, 虽然这个词语义可能不一样,比如在 memcache 里面,对 Read Miss 它会发放 Lease,以便合理的访问 DB, 保证 (1) 一致性 (2) 防止暴读打挂 DB。拜 sharding 所赐,这个 Lease 维护的时间序简单一些。同时,因为是 cache,所以丢失也无关紧要。
而我们上一篇文章介绍的 Lease,大致流程如下:
- 写入:client 需要向一个逻辑上的单点(我们在 Redis 里面会看到这个)发送 Lease Request, 拿到对应的 lease 之后,才能在 lease 期间写资源
- 另外一个写入需要写时,server 会尝试 invalid 之前 grant 的 lease,然后再 grant lease
- 如果 invalid 联系不上(比如发生网络分区),这里会等待到 grant 的 lease 时间结束。
在上述这段中,如果你感受不到什么问题的话,其实才是问题所在:
- 你依赖了一个额外的同步 Server,你做的操作和它不一定有关系。同时它是一个物理单点的话,挂掉就不好了。
- 写入操作需要保证是“只有一个拿到 Lease 的在操作“,这并不自然。
基础的 Raft 和 term
当我们需要 HA 的时候,这方面我们可能需要 Paxos 这样的 Consensus。这样,某种程度上,我们可以把一个单点变成逻辑上的 HA 的集合。我们来简单回到 Raft,来看看最简单的 Raft 是怎么做主节点的操作的:
- 半数以上(包括自己)投票产生 Leader, 而Leader 对应一个
term - 如果新 Leader 选举出来了,同时旧 Leader 还存在。那么它在集群内部的请求是无法生效的,因为它的
term小于现有半数机器的term
这里没有依赖物理时钟,而是依赖了单调递增的一个逻辑值 term,来进行操作。
Session && Lease
回到我们的 Lease, 比如 ZooKeeper 维护了一个 Session Timeout, 在这里,可以参考一下 ZooKeeper 的论文 4.4 节:
在我们的实现中,设置 timeout 是为了使 leader 在 follower 放弃他们之前意识到他们不再是 leader,因此它们就不会发布空事务。
为了检测客户端 session 的 failure, ZooKeeper 使用了 timeout。如果在 timeout 时间内,没有其他服务器收到一个 client session 对应的消息,即判定为 failure。如果客户端足够频繁地发送请求,则无需发送任何其他消息。 否则,客户端会在活动不足时发送心跳消息。 如果客户端无法与服务器通信以发送请求或心跳,则它将连接到其他ZooKeeper服务器以重新建立其会话。 为了防止会话超时,ZooKeeper客户端库在会话闲置了
s/3ms后发送了心跳信号,如果在2s/3ms内未收到服务器的消息,则切换到新服务器,其中s是 session timeout(以毫秒为单位)。
(顺便安利一下我翻译的:https://github.com/mapleFU/zookeeper_paper_cn#44-client-server-interactions ,可能有的地方翻译的不太好,欢迎 PR)
上述保证允许 ZooKeeper 的 client 能够比较好的使用。用 s 的 1/3 和 2/3 隐式依赖 clock drift 不会太大。
Raft 的 Lease Read 也做了 Lease 相关的优化。简单的 Raft 读一般需要 Leader 证明 “自己仍然是 Leader”,获取一个 Read Index,等提交越过这个 Read Index 之后返回。而 Lease Read 则是一个简单的推理:在一次 heartbeat 和 election timeout 相关的一段时间内,自己仍然是 Leader 。这个在博士论文中有介绍:
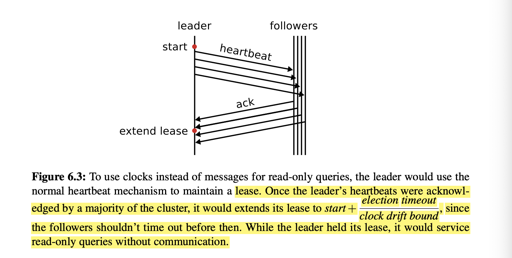
这个也可以参考 TiKV 的实现相关的讨论:https://zhuanlan.zhihu.com/p/25367435
Corner Case 与主节点操作
在上面工具的帮助下,你可能认为没有问题了,当然,这是不现实的~
DDIA 的作者在它的博客上写过一篇 how to do distributed locking https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html ,提到了下面的时序问题:
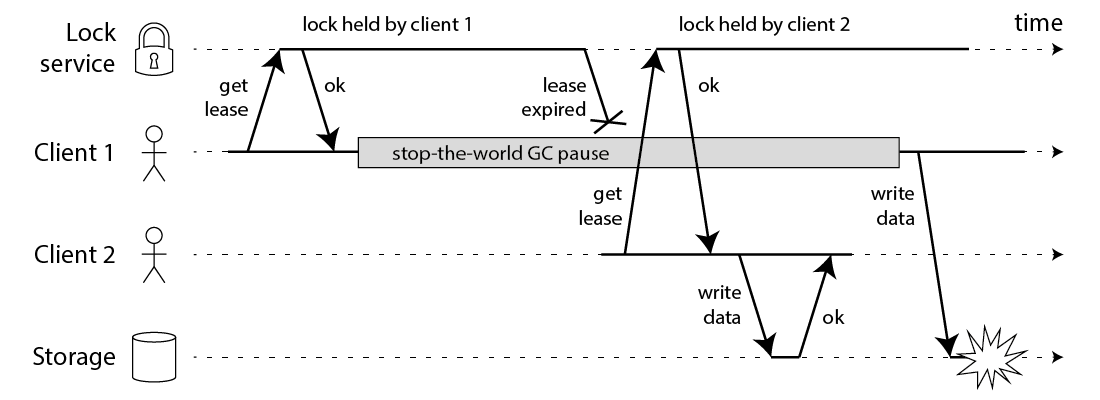
本质上,这是因为 Storage 并非 lock service, 这导致操作出现不一致:在 Lock Service 里,我们有独立的 Lock, 但是在外部操作视角,这并不是独立的。这导致我们之前的约束再次出现问题!
这两篇文章提到了 ZooKeeper 相关的解决方案:
- https://fpj.systems/2016/02/10/note-on-fencing-and-distributed-locks/
- https://zhuanlan.zhihu.com/p/299272034
(我更推荐你阅读后者,虽然其实不止要读一遍)
这里是在说,发送操作的时候,如果获取到主的权限,可以产生一个 Term,发送操作的时候带上这个 Term,如果 Term 不合理的话,下层允许拒绝掉这个操作。
此外,HDFS 中,允许你使用 IO Fencing: 当一个新的节点成为 Leader 的时候,你能够 ssh 到旧的 leader 上,来 kill 掉它,防止出现时序问题。
参考
- Hardware/Software Clocks https://tldp.org/LDP/sag/html/hw-sw-clocks.html
- Modern Cpp: The There Clocks https://www.modernescpp.com/index.php/the-three-clocks
- TiKV 读优化:https://zhuanlan.zhihu.com/p/25367435
- https://fpj.systems/2016/02/10/note-on-fencing-and-distributed-locks/
- https://zhuanlan.zhihu.com/p/299272034