Long Tail Key && Memcache in FB
之前这篇文章大体介绍了一下 memcache 的架构: https://zhuanlan.zhihu.com/p/194347153
上述一些在这篇文章中会用到的概念有:
- Memcache Pool: 按照 key 切分成为不同的 Pool, 适配不同的 key 和 key 不同的读写频率。同时,把冷热-高低代价的数据放在不同的池子里,然后 tunning, 来保证系统效率。
- Lease 机制:用 Lease 来控制一致性
- In a Region: Replication
frontend cluster即一组 服务器和memcached。多组 frontend cluster 存储到底层的 storage 上。- 在 Region 层面,也有 Region Pool, 这是一种资源共享。Region 中 frontend 请求不一,但对应存储层是一样的。对于某类数据:即数量少访问贵的,可以被移到一个共享的池子中。
阅读 FB 分割的时候最好理解上述文章的对应内容。同时,这篇文章建模的时候大量使用了 user 这个词,可能某种程度上,fb 资源是以 user 做某些方式 sharding 的,不过文章也解释了,对资源的请求有和用户火热程度相似的分布。
了解了架构之后,实际上数据会有上面说的,分布的问题:
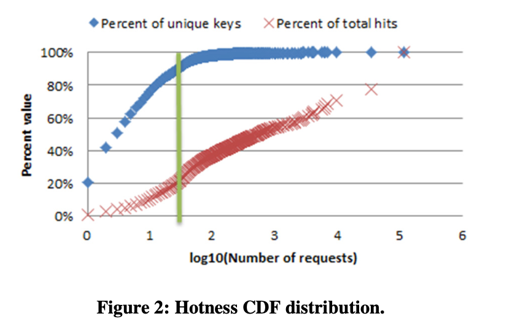
- 90% 的请求是少于访问32次的,很多人至多有 100 个朋友,并且只和他们发消息/看他们相关的内容。
- 部分火热的用户/资源访问频率很高。
FB 希望:
- 一个 region pool 内的热数据能尽量在多个对应
frontend cluster缓存中 - 冷数据全部占用 RAM 的话会是一笔巨大的开销,可以把他们分配在不常访问/访问代价稍高的地方。
论文把 memcache 集群分为了 frontend cluster 独立的 L1 cache 和共享的 L2 cache,这类似 CPU 的架构,不同于 CPU,由于访问时间/penalty 的增加,可以用一些别的可能复杂一些、更好预测的缓存算法,取代一些可以做到硬件里的 LRU/类LRU 策略,来减小 penalty。
当然,就我个人感受来看,memcache 应该是 fb 一个通用系统,所以感觉它的算法会做的 common 一些,而不是根据某些业务的请求做一些激进的优化。
Concepts
Each key-value pair has a key ID, which is a string. A normalized version of key-id is defined as a normalized key. For example, key ID
photos:foobar:{12345}:c{1}hasphotos:foobar:{N}:c{N}as its normalized key where N stands for an integer value. For this particular example, ‘12345’ is a user ID and the second N = 1 is for version number. A key family is a set for all cache key-value pairs which have the same normalized key.
同时,key 被组织称 key family, 来:
- 分配给专用的 memcached pool
- 添加 TTL
- 整个 key family 迁移
The prefix of normalized key is used to detect which pool the key belongs to. For example, all keys starting with prefix ‘photo’ go to the photo tier which has its dedicated Memcached machines.
论文定义了 work set size,指的是在给定的时间窗口内每个单独的 <key, value> 被访问过的 bytes 和。

同时,这里引入了一个计算放大的量,duplicate factor:

对于一个 key family,它可能被分配到一个 region pool,对应到一个到多个 frontend cluster。wss 表示单个 cluster 的访问的 size, duplication factor 反映在整个集群中的放大比例。region 在这一层逻辑中,可以被看作在 L2 的空间内存里。
这个值在逻辑上与 key family 对应的 user, 即 key family 实际上对应的请求者数量是相关的:
When a key family is shared across more unique users, it has a higher probability of being accessed from more frontend clusters.
现在目标是,对于某个给定的 key family, 能够把热点请求在 frontend 集群中,作为对应的 L1 cache,不那么热的就不要在 frontend 集群,丢在 L2 Cache 甚至数据库里。
Key-based Sampling
通过控制采样率来控制采样。
Because keys are not sampled by user requests, key-based sampling can capture all cache accesses including ones not associated with user activities.
这里以 key 为单位,通过以下方式完成采样:
1 | hash(key_id) % sample_rate == 0 |
Because keys are not sampled by user requests, key-based sampling can capture all cache accesses including ones not associated with user activities.
这里要说明的是,fb 请求逻辑可能会这样,比如加载页面,要一个请求加载几百张图片。这里采取的模式是应用简单的 k-v 抽象。
它的采样算法很简单,hash(key_id) % sample_rate == 0 就算命中…简单吧!
(我当时看的时候大骂:就这?LRU不来个?LFU不来个?)
Promotion Algorithm
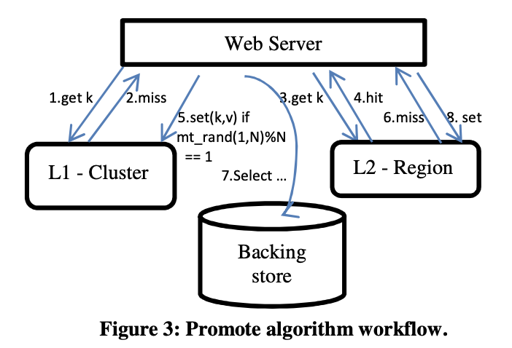

这就真的如上图所述了…我感觉反而没什么好说的。不过现在要在两层 cache 维护 lease, 感觉上原本是一个 miss 请求发一个 lease, 现在感觉两层分别做 lease 应该也可以?然后 promote 独立进行。不知道是不是。
这里重点是 5 的采样方法,和第一次 miss 加载到 L2 的不会尝试被 promote 到 L1。
概率模型

结论:
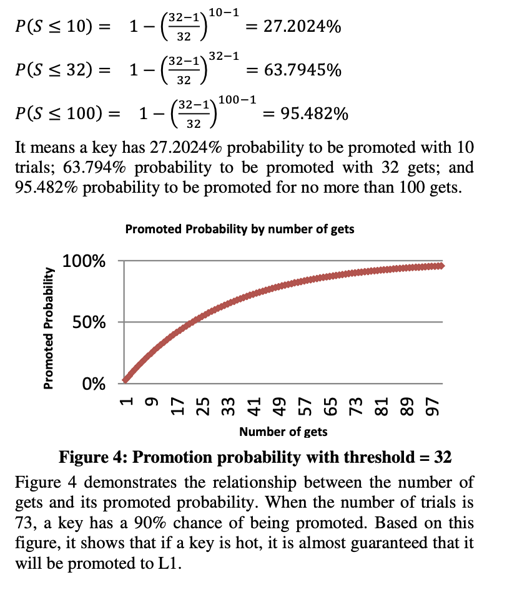
文章 4-5 节介绍了这个算法的优化效果,看上去还是不错的。原理感觉和 CPU Cache 多级原理是一样的(不过冷热分割和 cache 结合起来倒是很有意思)
Redis HotKey
我们介绍了 FB 的采样方法,现在我们讲讲国内用的多的 Redis。
阿里云 Redis 实现了 hotkeys ,可以帮我们实现热 key 查找: https://www.alibabacloud.com/help/doc-detail/101108.htm
相关的 issue 可以找到:
(还是杭州阿里的大佬做的,orz)
1 | /* Logarithmically increment a counter. The greater is the current counter value |
它依赖概率增加 counter, 同时有一个 baseval. 之前使用的是 hash(key_id) % sample_rate == 0 来决定是不是,现在用 double p = 1.0/(baseval*server.lfu_log_factor+1) 来代替sample_rate, 以增加 counter 来增加采样。
在 issue 里也提到了,因为是一个 counter, 所以要面对 key 之前常访问,现在少访问的情况,所以要有一个 last_access_time 和 counter:
1 | /* If the object decrement time is reached decrement the LFU counter but |