Cache and Related Part1
在 Pipeline 执行的时候,我们拆成简单的 4/5 stage 的 pipeline 的话,我们会有一些 hazard:
- Structural hazard
- Data hazard
- Control hazard
structural hazard 都给可以靠 nop 和钱解决. Data hazard 也可以 nop, 但同时,可以 forwarding 的方式,靠额外的控制逻辑,来减小这类事情的发生。而我们也有 control hazard, 对分支指令带来影响。一方面流水线有分支预测,一方面 gcc 提供了 __likely__ 之类的操作,在生成代码的时候静态的做了一些处理。
在这个阶段的分析中,我们有点对所有指令一视同仁的味道:sw lw 被我们当成伊布/同步的,它们仿佛运转的和运算指令一样快,而且不会带来什么额外开销. 但是实际上我们都知道 load memory 和计算之间是有 gap 的,而且这个 gap 还不太小。
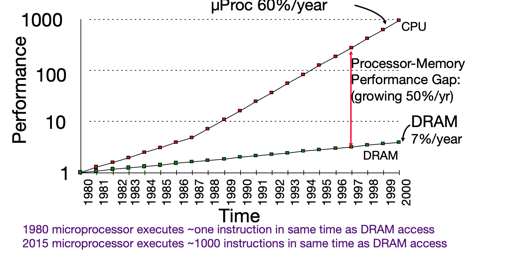
然后我们就到了喜闻乐见的存储层次山了:
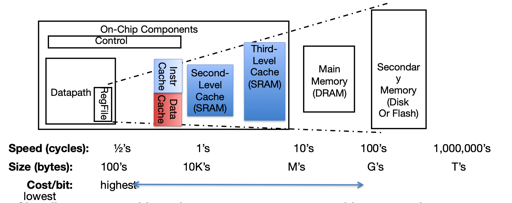
越接近 CPU, 访问越快,但是越小、单位存储量的成本越昂贵。存储层次的思想是:
- 上层的数据是下层的一个子集
- 下层在逻辑上有所有的数据
同时,相关的概念有两种 locality:
- Temporal locality: 时间上的局部性
- 如果某个 memory 被访问了,很可能近期有一定机会会再次被访问
- Spatial locality
- 如果某个 memory 被访问,那它附近的内存很可能也会被访问
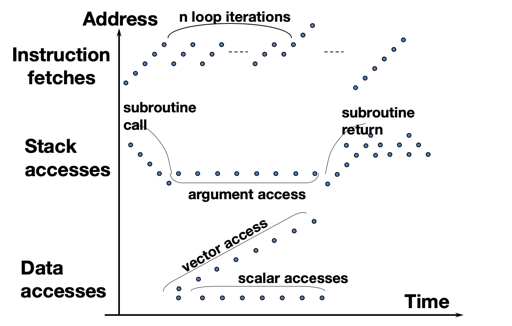
那么,我们在计算机系统里面有一些隐含的存储层次,这是除开显式的 mmap 或者写盘、共享内存外的形式:
- Register 和 memory 的读/写:由编译器或者汇编编写者生成
- cache 和 main memory: 由 cache controller 管理
- Main memory 和 disk: 由 OS 管理;也有 TLB 这样的缓存存在(总所周知,TLB 虽然叫做 buffer,实际上是个 cache)。
上面是 locality 相关的访问模式,我们会注意到一些特征。其中需要注意的是,有的访问模式是相对来说:
- 链式的结构可能会有 locality 不足的问题,因为实际上它的内存是离散的,
- Go 语言这样的语言提供 map slice 这些相对来说 locality 好一些的结构
- LevelDB 里面会用 Arena 尝试分配在连续的内存上
Cache 有一点比较重要的就是,cache 对用户是透明的,这意味着:
- 即使不知道 cache, 程序、指令也能正常的运作
- 不考虑效率的情况下,上层的使用者不需要知道 cache 的概念
考虑 lw t0, 0(t1), 这个时候 t1 对应的地址上的内存会被加载到缓存里。
具体而言:t1 contains 0x12F0, Memory[0x12F0] = 99
- 如果从 cache 中找到了对应的地址,那么直接从 cache 中读
- 如果 cache miss 了,那么从内存发送到 cache,再从 cache 发送到用户
缓存术语
读缓存的时候,可能会有三种情况
- Cache hit: 缓存命中
- cache miss: 缓存未命中,需要从下层获取
- cache miss, block replacement: cache 未命中 + 需要把原来存在的 cache 給替换掉
缓存温度
- cold: cache empty, 没有怎么加载
- warming: Cache filling with values you’ll hopefully be accessing again soon
- Warm: Cache is doing its job, fair % of hits
- Hot: Cache is doing very well, high % of hits
感觉这个温度有两层含义,一个是缓存本身占用高,一个是缓存命中率高。
- hit rate: 命中缓存的比例
- miss rate: 未命中缓存的比例
- miss penalty: 从下一层加载到上一层需要的时间
- hit time: 访问缓存的时间
Cache Miss 的形式
从上面的 Miss 来看,我们可以得到一些 cache miss 的形式:
- compulsory misses: 程序开始的时候,因为 cold 的原因,导致的 Miss
- CPU/Cache 怎么解决的我不知道,不过我记得 Memcache 有一定解决方案:https://zhuanlan.zhihu.com/p/194347153
- Conflict Misses:内存对应 cache 处于相同的位置,需要把目前的下掉,导致的 Miss
Cache 的逻辑结构
我们需要考虑下面几个理所当然的问题:
- Cache 的速度远远大于内存,但 Cache 远远小于内存
因此,下面将由 direct-mapped cache 开始介绍 cache 相关的信息。
Direct-Mapped Cache
在 direct-mapped cache 里面,每个内存地址会关联到一个 cache 中的 block,只要:
- 查找这个 block 有没有成员
- 里面成员是不是自己的内存地址
为了实现上面两个目的,下面这第一章逻辑的图是不够的,因为
- 无法确认每个 block 对应的内存是多少
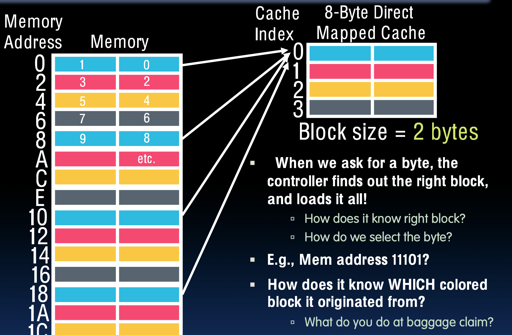
所以我们的 cache 需要一个 tag:
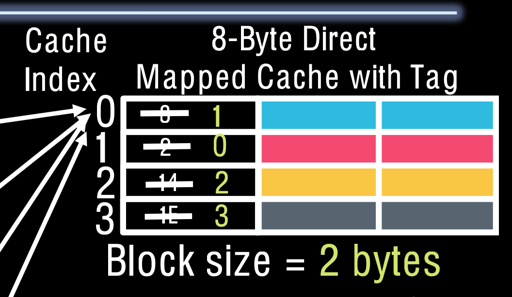
这里把一个地址分成了三部分:
- tag to check if have correct block
- index to select block
- Byte offset in block

RV32 的讨论:
- RV32 地址空间是 32bits
- 假设每个 block 是 2-byte,我们有 8Byte 的 cache
- offset 需要 1bit 来表示
- index 表示对应位置,需要有
(8 / 2)个状态,即占用 2bit - 剩下的 29bits 作为 tag
同时,实际上我们可能有一个 valid bit, 当程序开始运行的时候,除了 32bits,可能需要一个 valid bit,表示这段缓存中的内存对程序而言是否是 valid 的。
真实情况与假设
我们现在假设我们的 cache 有:
- 16KB 的 data
- direct-mapped 的模式
- 4-word 的 block
现在我们来对照 slice 看看 direct-mapped 的访问:
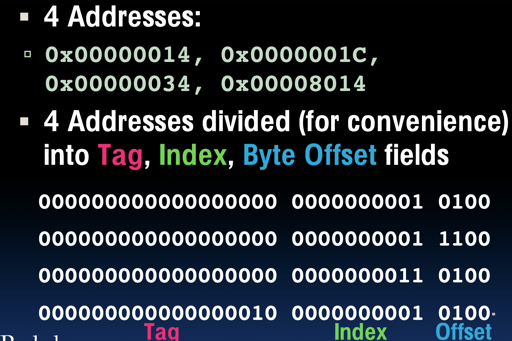
那么,具体的访问如下图所示:
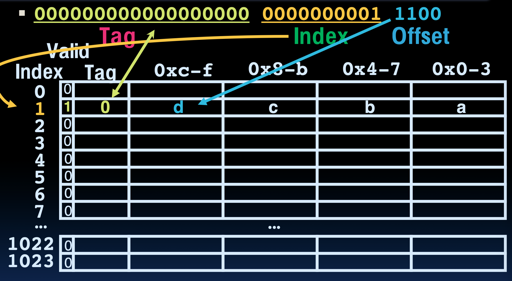
我们可以看到,在最早我们的讨论中,一个 tag 对应着可能2-byte 的内存,但是现在,我们可能一份 tag 对应 一个 block, 这个 block 可能装有比较多组的内存。实际上,这有益于 locality。
Write-through & Write-back
这两种方案相信除了这里,我们介绍很多别的形式的 cache 的时候你也会碰见它们:好吧,过去、现在、还是将来,你都会遇到这两个。
- Write-through:写入的时候需要更新cache 和 memory
- Write-back:
- 写入的时候更新 cache block
- 添加一个 dirty flag
- OS 在 IO 之前 flush cache
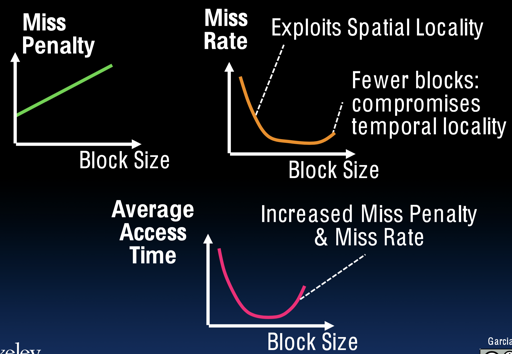
block size 的大小
- Pros:
- spatial locality: 空间 locality 受益
- 对 array 访问有好处
- 对于目前 stored-program 的形式有好处
- Cons:
- 增加了 Miss penalty
- If block size is too big relative to cache size, then there are too few blocks
其他类型
实际上,cache 有几种组织方式:
- fully associative
- Direct mapped
- N-way Set Associate
我们会在下一个 part 介绍。