Notes: Scaling Memcache at Facebook
Notes: Scaling Memcached at Facebook
这篇文章介绍的是 FB 的缓存系统 Memcache, 这套系统构建在 memcached 上,提供了可靠的、大规模的缓存。这篇论文主要内容有:
- memcache 的简单的架构
- memcache 性能的优化
- c/s communication 上的优化,即使用一定更改的 UDP 来实现 Get 语义和 batch 与并行请求
- 减轻对 db 的压力
- 压力来源包括 stale sets 和 thundering herds ,这里 memcache 实现了 Lease 机制
- 用 memcache pool 和 pool 内部的 replication 来提供一定层次的共享
- 处理因为 memcache failure 导致的 cascading failure (国内好像把这个叫雪崩?) ,引入了一个小的 Gutter
- 在单 Region 中,引入 replication
- 跨地区的主-从备份中,保持一致性(话说主从备份这个词还能用吗?)
- 单机优化,slab 优化内存和 MGet 来处理Batch Key load,我没看的很细。
阅读这篇文章需要注意一点,memcache != memcached。希望看的同学不要搞混了。同时这篇文章只介绍了 1-3. 4和5我看的都比较草率。
architecture
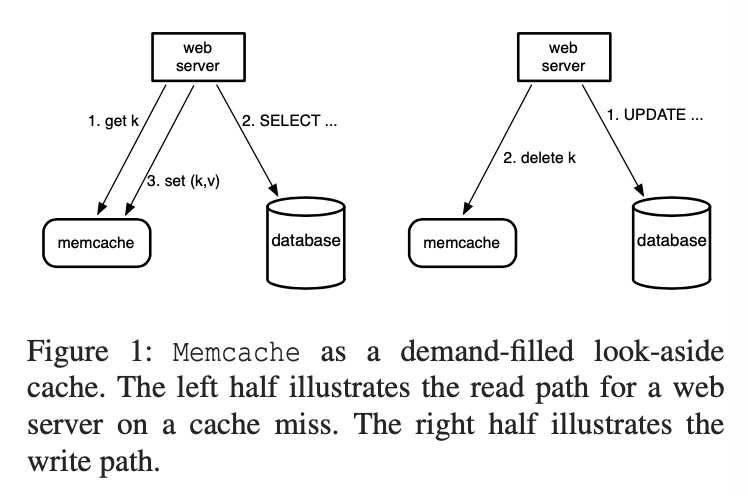
memcache 系统作为一个 look-aside cache,我们可以回顾一下 look-aside cache:
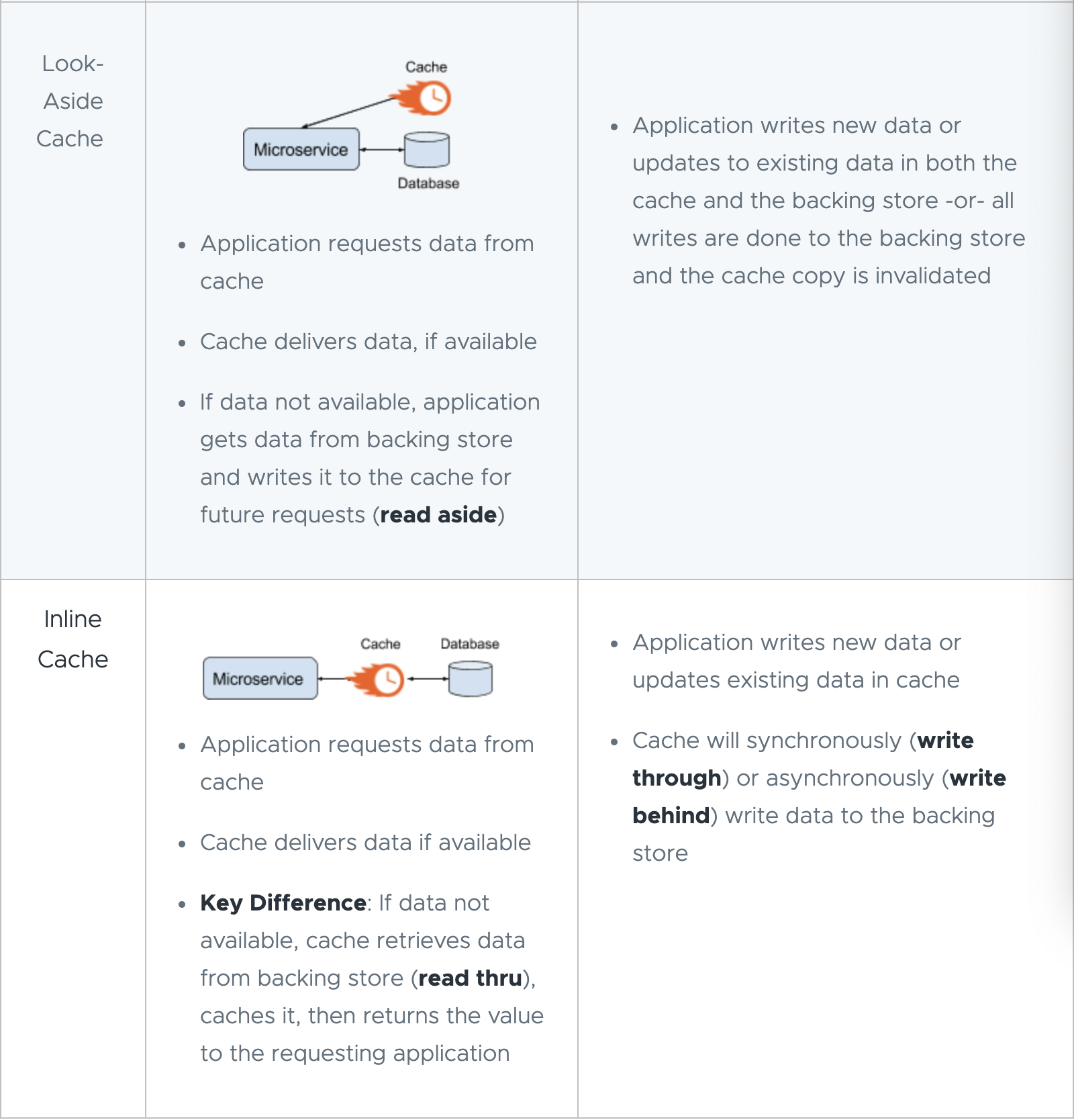
- Get 会尝试 read from cache, 如果没有的话,会 read from db 再更新 cache
- Set 会 update db, 然后 invalid cache
同时,memcached 本身不会实现和其他 peer 的通信。引入 memcache 的客户端会有:
- memcached 客户端
- 一个 proxy 服务器,用于 batch 和 proxy.
涉及这个系统的时候,有几个需要注意的地方:
- 可能会有热数据和陈旧的/很少更新的数据
- 复制是必要的,但是可能会导致 fan-out 很大,即更新一处需要更新换多的副本或者 cascade 的关系
- 读 >>> 写,作为 cache,读是主要的负载
In a Cluster: Latency & Load
Latency
作为 web 应用的通用缓存,与数据库依赖的 k-v 存储不同,Get 模式通常是进入一个网页,然后捞起很多子组件的数据,甚至相互之间有加载的依赖关系。论文里面表示一次用户请求可能引起上百个 cache get key的访问。这样就会造成服务器负担比较重。同时因为 memcached 本身不提供服务器沟通,所以 memcache 在客户端上解决这个问题。
引入客户端,需要引入 memcache 的客户端会有:
- memcached 客户端
- 一个 proxy 服务器
mcrouter,用于 batch 和 proxy.
同时有辅助的列表,来提供访问。
那么,客户端提供了 batch 和并行访问,客户端会 Batch 用户的请求,把一些级联的访问组织成 DAG, 来并行的访问,感觉类似数据库这种访问方式:
客户端在读请求上以 UDP + 拥塞控制 来实现,来降低 TCP Connection 带来的 CPU 和 memory 开销。为了避免 incast congestion, 即 Get 过多导致 floyd, 它实现了慢启动 + 滑动窗口。
下面是论文相关的一些性能分析:
Under peak load, memcache clients observe that 0.25% of get requests are discarded. About 80% of these drops are due to late or dropped packets, while the remainder are due to out of order delivery. Clients treat get er- rors as cache misses, but web servers will skip inserting entries into memcached after querying for data to avoid putting additional load on a possibly overloaded network or server.
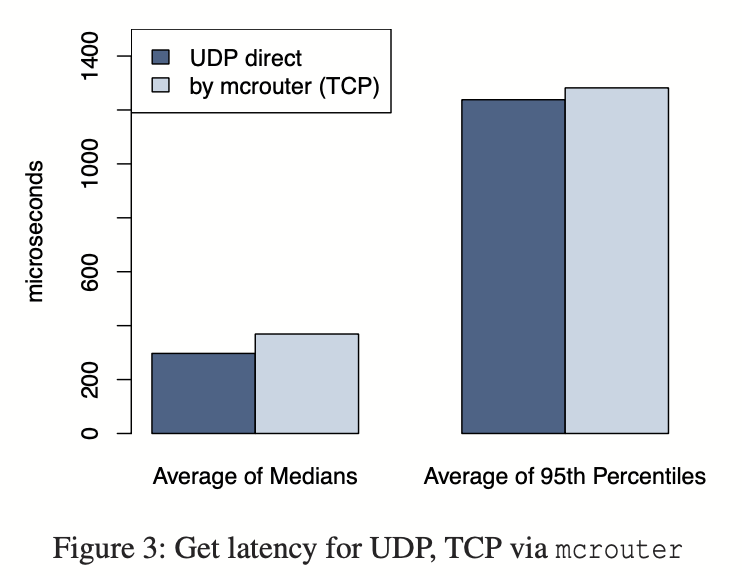
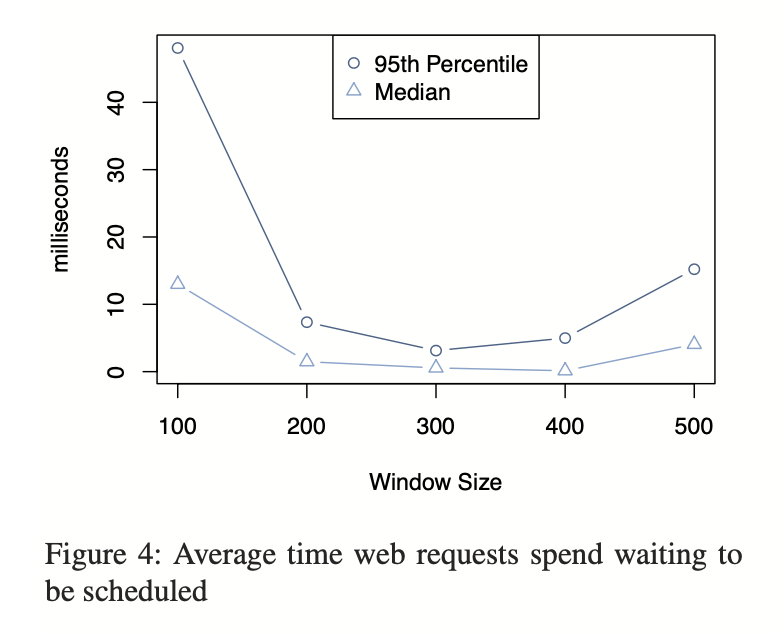
Web servers rely on a high degree of parallelism and over-subscription to achieve high throughput. The high memory demands of open TCP connections makes it prohibitively expensive to have an open connection be- tween every web thread and memcached server without some form of connection coalescing via mcrouter. Coalescing these connections improves the efficiency of the server by reducing the network, CPU and memory resources needed by high throughput TCP connections. Figure 3 shows the average, median, and 95th percentile latencies of web servers in production getting keys over UDP and through mcrouter via TCP. In all cases, the standard deviation from these averages was less than 1%. As the data show, relying on UDP can lead to a 20% reduction in latency to serve requests.
Reducing Loads
有两个问题会给数据库带来问题
- stale sets
- thundering herds
(第一个感觉是一致性问题啊)
第一个是读写都有的时候,回写带来值和数据库中值的不一致,我们考虑下面的过程:有 T1 T2 T3, 和对象 x, x 初始值是 x1, 未命中用 miss 表示,RC 表示读 cache, WC 表示写 Cache, D 代表DB, Inv 代表 Invalid Cache 那么假设如下的操作序列
1 | T1: RCx(m) RDx1 WCx1 |
那么,cache 最后的剩下的就是 x1 了,和数据库不一致。
为了解决这个问题,memcache 使用了 lease, 在 cache 未命中的时候,拿到一个 lease, 这是一个 64bit 的 random token, 最后用这个 lease 来保证写会的版本是正确的。如果 cache 被 invalid 了,之前的 cache 都会被 inv, 回写会因为 lease 被 invalid 而失效。这样保证上述的情景不会发生。
Thundering herds 表示的是另一种场景:当一个 cache 读很重的时候,出现了一个 invalid,那完蛋了,这些读全部会打到 db 上,造成 db 写急剧放大。
这个问题解决还是和 lease 有关,lease 发放场景的时机是:“在 cache 未命中的时候,拿到一个 lease”。
By default, we configure these servers to return a token only once every 10 seconds per key. Requests for a key’s value within 10 seconds of a token being issued results in a special notification telling the client to wait a short amount of time. Typically, the client with the lease will have successfully set the data within a few milliseconds. Thus, when waiting clients retry the request, the data is often present in cache.
通过限定 lease 的频率,memcache 达到了类似“每次只让一个 key query 访问 db” 这样的效果,从而缓解了 db 因为此导致的压力。
同时,虽然为了保证与db一致,memcache会用 lease, 但是它允许一些不需要一致的应用读 stale value (毕竟一致也意味着代价):
We can further reduce this time by identifying situations in which re- turning slightly out-of-date data is acceptable. When a key is deleted, its value is transferred to a data structure that holds recently deleted items, where it lives for a short time before being flushed. A get request can re- turn a lease token or data that is marked as stale. Appli- cations that can continue to make forward progress with stale data do not need to wait for the latest value to be fetched from the databases. Our experience has shown that since the cached value tends to be a monotonically increasing snapshot of the database, most applications can use a stale value without any changes.
Memcache Pool
memcache pool 的想法是按 key 分割 memcache. 因为实际上各个应用访问模式不同,有不同读写频率。混合负载会导致负面干扰,所以有 memcache pool. 然后用不同的策略来处理,例如:
例如,我们可以为经常访问但对于 cache miss 的开销不大的 key 提供一个小的 pool 。我们还可以为不经常访问的 key 提供一个大型 pool ,对于这些 key 而言,cache miss 的代价非常高。
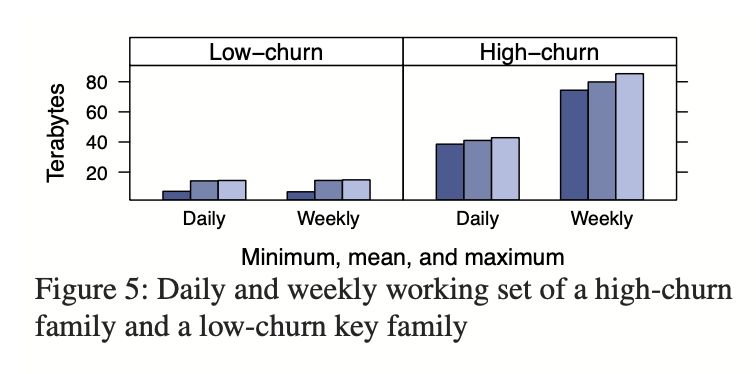
(这张图后面还会讲)
把冷热-高低代价的数据放在不同的池子里,然后 tunning, 来保证系统效率。
Memcache Pool 需要每个 Pool 内部 replication 降低负载,这个的逻辑在于:
- 如果是 sharding 的话,对于一个 100keys 的请求,两边任然要处理这么多 Query,只是每个 Query 拿的 key 少了,这是存储问题,但是不能解决 QPS 过高
- replica 会降低每个机器的读开销, 不过需要额外维护一致性。
Each client chooses replicas based on its own IP address. This approach requires delivering invalidations to all replicas to maintain consistency.
Handling Failures
Failure 是指池子之类的可能会坏掉/下线。因为是缓存,所以不影响数据库本身的正确性,但是请求仍然会全部打到数据库上。这被称为 cascading failure.
我们必须从两个方面解决故障:
- 由于网络或服务器故障而导致无法访问少量主机
- 影响 cluster 中很大比例的服务器的广泛停机。
对于小故障,我们依靠自动修复系统。这些操作不是即时的,可能需要几分钟。该持续时间足够长,以致导致上述 cascading failure,因此我们引入了一种机制,以使后端服务与故障进一步隔离。我们专用于一小组名为 Gutter 的机器来接管几台故障服务器的职责(类似 MapReduce 中那种剩余几台的 worker )。 Gutter约占集群中Memcached服务器的1%。
请求 timeout,再次请求 Gutter 池子,然后按照原来的策略处理。Gutter 会很快 expire,同时会提供 stale 数据:
Entries in Gutter expire quickly to obviate Gutter invalidations. Gutter limits the load on backend services at the cost of slightly stale data.
上面那段含义类似写入不会 invalid Gutter, 所以它可能读旧数据… 感觉这也算是写入和一致的权衡吧,在 cache 坏的时候读 stale data 时合理的就会这样?
对于 hot keys, 论文说这个和 hot keys 是不同的层面:
Note that this design differs from an approach in which a client rehashes keys among the remaining memcached servers. Such an approach risks cascading failures due to non-uniform key access frequency. For example, a single key can account for 20% of a server’s requests. The server that becomes responsible for this hot key might also become overloaded. By shunting load to idle servers we limit that risk.
In a Region: Replication
在 Region 层面,memcache 系统再次提供了某种意义上的 replica 和冷热分割.
它提出了 frontend cluster, 即一组 服务器和memcached。多组 frontend cluster 存储到底层的 storage 上。
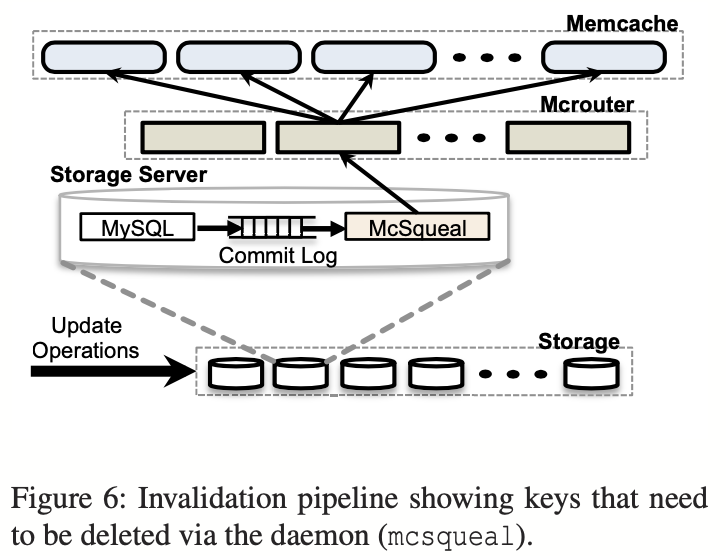
那么不同的 cache 间又要处理一致性了(我的天啊…)。 Region 提供了上层的和下层的 expire:
Reducing packet rates: While mcsqueal could contact memcached servers directly, the resulting rate of packets sent from a backend cluster to frontend clusters would be unacceptably high. This packet rate problem is a consequence of having many databases and many memcached servers communicating across a cluster boundary. Invalidation daemons batch deletes into fewer packets and send them to a set of dedicated servers running mcrouter instances in each frontend cluster. These mcrouters then unpack individual deletes from each batch and route those invalidations to the right memcached server co-located within the frontend cluster. The batching results in an 18× improvement in the median number of deletes per packet.
Invalidation via web servers: It is simpler for web servers to broadcast invalidations to all frontend clusters. This approach unfortunately suffers from two problems. First, it incurs more packet overhead as web servers are less effective at batching invalidations than mcsqueal pipeline. Second, it provides little recourse when a systemic invalidation problem arises such as misrouting of deletes due to a configuration error. In the past, this would often require a rolling restart of the entire memcache infrastructure, a slow and disruptive process we want to avoid. In contrast, embedding invalidations in SQL statements, which databases commit and store in reliable logs, allows mcsqueal to simply replay invalidations that may have been lost or misrouted.
在 Region 层面,也有 Region Pool, 这是一种资源共享。Region 中 frontend 请求不一,但对应存储层是一样的。对于图5中的 B 类数据:即数量少访问贵的,可以被移到一个共享的池子中。
The decision to migrate data into regional pools is currently based on a set of manual heuristics based on access rates, data set size, and num- ber of unique users accessing particular items.
code and warm: 重启
缓存的 code 是指:
- 可能挂掉重启,内存全丢了
- 可能刚拉起来,内存还是没东西
这个时候请求会落到 db 上,带来写入的放大。这个时候,简单的策略是直接从别的 warm 集群 cache 读,来优化效率。
但是这样又可能有不一致的问题了。所以 memcache 有下列解决机制:
- 机制开启时,delete 有 hold-off 时间
- hold-off 中,对这个 key 添加会失败
- 这代表不一致,然后需要重新去捞数据
Care must be taken to avoid inconsistencies due to race conditions. For example, if a client in the cold cluster does a database update, and a subsequent request from another client retrieves the stale value from the warm cluster before the warm cluster has received the invalidation, that item will be indefinitely inconsistent in the cold cluster. Memcached deletes support nonzero hold-off times that reject add operations for the specified hold-off time. By default, all deletes to the cold cluster are issued with a two second hold-off. When a miss is detected in the cold cluster, the client re-requests the key from the warm cluster and adds it into the cold cluster. The failure of the add indicates that newer data is available on the database and thus the client will refetch the value from the databases. While there is still a theoretical possibility that deletes get delayed more than two seconds, this is not true for the vast majority of the cases. The operational benefits of cold cluster warmup far outweigh the cost of rare cache consistency issues. We turn it off once the cold cluster’s hit rate stabilizes and the benefits diminish.