notes: Spanner
Spanner 也是地理隔离的数据库,把数据 sharding 地存在多组 Paxos 状态机上。这些机器位于可能地理隔离的不同区域内。
网上的 Spanner 产品有:https://cloud.google.com/spanner/docs/true-time-external-consistency?hl=zh-cn . 关于它的内容有着中文的翻译。可以在上面阅读外部一致性相关的内容,我理解的外部一致性就是:
- 提供了时间等外部的约束上的一致性
- 在一个时间戳下面的跨越数据库的全球一致性的读操作
对于 MVCC 和对应语义的系统来说,事务的 ts 是绝对重要的。Spanner 提供了 TrueTime API, 暴露了时间和不确定性,来实现对应的内容。
实现这种特性的关键技术就是一个新的 TrueTime API 及其实现。这个 API 可以直接暴露 时钟不确定性,Spanner 时间戳的保证就是取决于这个 API 实现的界限。如果这个不确定性 很大,Spanner 就降低速度来等待这个大的不确定性结束。谷歌的集群管理提供了一个 TrueTime API 的实现。这种实现可以保持较小的不确定性(通常小于 10ms),主要是借助于 现代时钟参考值(比如 GPS 和原子钟)。
架构
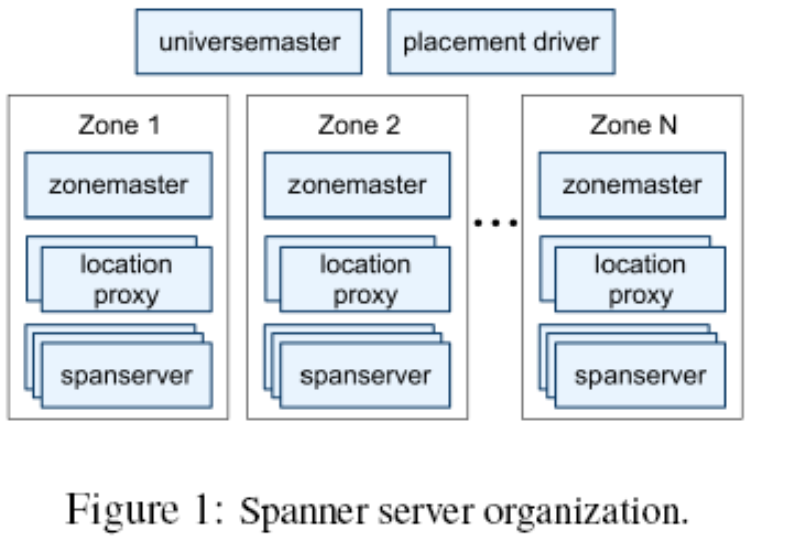
一个 Spanner 集群被称为一个 universe:
Spanner 被部署成多个 zone 的集合,每个 zone 类似一个 BigTable. 我个人感觉像是一个可用区内的集群:
- 一个 zone 包含一个 zonemaster
- 包含成百上千个 spanserver,类似 Chunk Server, 具体存储数据,把数据给客户端
- 客户端用 location proxy 来找到读写的数据
- Universe master 主要是 一个控制台,它显示了关于 zone 的各种状态信息,可以用于相互之间的调试。
- Placement driver 会周期性地与 spanserver 进行交互,来发现那些需要被转移的数据,或者是为了满足 新的副本约束条件,或者是为了进行负载均衡。
Spanserver
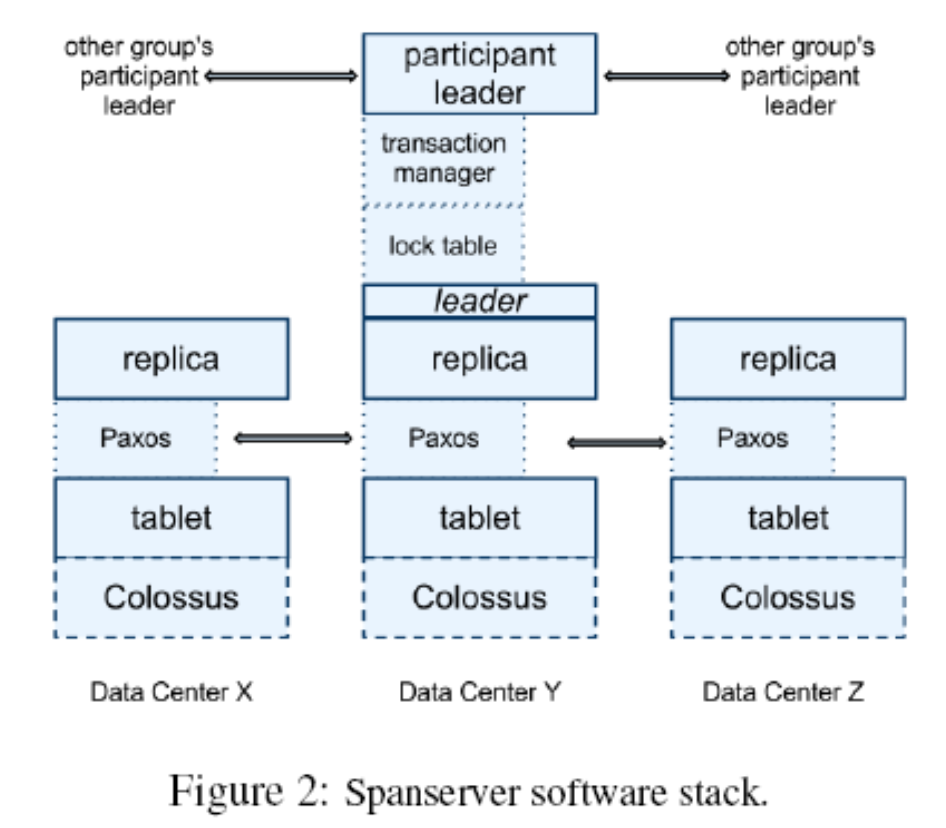
感觉开始套娃了。不过比较重要的是,SpanServer 也是跨数据中心的。
SpanServer 包含很多的 tablets。
Spanner 会把 TS 分配给数据,让其成为一个 MVCC 的 KV(还记得 TiKV 吗)。单个 tablet 的状态是以文件的形式存储的,被组织为:
- B-Tree 的文件形式
- WAL
并被存储在 GFS 的进化版, Colossus 上。不过感觉上面就是单纯 B-Tree 或者 LSMTree 层了。
Spanner 实现了 Leader-based 的 Paxos, 来实现一系列被复制的 k-v 操作。
(我很奇怪的是已经有 Colossus 了为什么还要封装一套 Paxos 来复制?看了下感觉是 Colossus 是不跨数据中心的)
一个写操作来临时,会写两次:
- 写 Paxos 日志
- 对 tablet 写日志,并进行写操作。
Paxos 实现的时候是 Pipeline 化的,但是会顺序 apply 日志。
(论文对 Paxos 提的感觉比较类似于 ZooKeeper 那种,似乎读可以本地读。)
Paxos Group 是 Leader based 的,如果你是 leader, spanserver 会 Lock Table,来支持分布式的事务实现, 同时针对长事务做了特化。(这里不知道是不是可以参考 Percolator)。同时,spanserver 也会实现事务管理器,来实现跨 paxos group 的事务。
其中一个 Participant Group, 会被选为协调者,该组的 participant leader 被称为 coordinator leader,该组的 participant slaves 被称为 coordinator slaves。每个事务管理器的状态,会被保存到底层的 Paxos Group。
(上面这段话很重要,你读到后面还会回来的,因为我就是这么回来的)
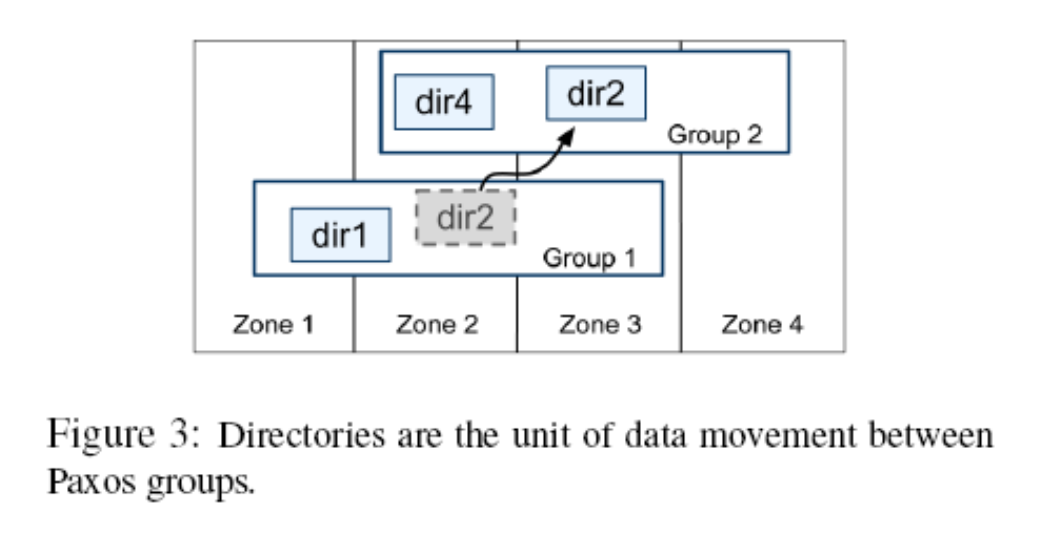
Directory
Spanner 支持 Directory 的抽象,我感觉类似 Column Family. 一个 directory 是数据存放和调度的基本单元。属于一个目录的所有数据,都具有相同的副本配置。 当数据在不同的 Paxos 组之间进行移动时,会一个目录一个目录地调度。
dir 从属于 Paxos Group.
以上的调度可以防止热点,分散负载。如果一个 dir 过大,Spanner 会把它 sharding,然后分配到不同的 Paxos Group 上。
最后,在 BigTable 中跨行事务的缺乏来导致了用户频繁的抱怨; Percolator[32]的开发就是用来部分解决这个问题的。

Spanner 数据模型如上所示,感觉还是比较接近 directory + key 的行存的。
TrueTime
本人对“时间”这个计算机概念不是很熟悉,所以时间这块会过的很草率,等以后补好了回头再看看。

TrueTime API 会提供一个时间的可信度区间。在 Google,这个 API 是由原子钟 + GPS 实现的,用同一个数据中心多个 master 和机器上的 slave + GPS 共同实现时钟同步的机制。
后续内容中,有需要判断 after 的,也有需要等待 after 的。
并发
Spanner 的并发主要指它实现事务。
Requirements
- 对于只读事务和快照读而言,一旦已经选定一个时间戳,那么,提交就是不可避免的, 除非在那个时间点的数据已经被垃圾回收了
- 把 Spanner 客户端的写操作和 Paxos 看到的写操作这二者进行区分,是非常 重要的,我们把 Paxos 看到的写操作称为 Paxos 写操作。例如,两阶段提交会为准备提交阶 段生成一个 Paxos 写操作,这时不会有相应的客户端写操作。
- 在时间戳为 t 的时刻的数据库读操作,一定只能看到在 t 时刻之 前已经提交的事务。
- 事务读和写采用 S2PL 协议。As a result, they can be assigned timestamps at any time when all locks have been acquired, but before any locks have been released.
- For a given transaction, Spanner as- signs it the timestamp that Paxos assigns to the Paxos write that represents the transaction commit.
Spanner 依赖下面这些单调性:
- 在每个 Paxos Group 内,Spanner 会以单调增加的顺序给每个 Paxos 写操作分配时间戳,即使在跨越多个领导者时也是如此。
- 在多个领导者之间就会强制实现彼此隔离的不连贯:一个领导者必须只能分配属于它自己 Lease 区间内的时间戳。当分配一个 s 时,Paxos Group 的 Leader 的
smaxlease 需要大于s.
Spanner 也保证了 Paxos Group 针对外部的一致性:
if the start of a transaction T occurs after the commit of a transaction T1, then the commit timestamp of T2 must be greater than the commit timestamp of T1.
这描述了 Spanner 自身 Commit 的约束,因为它似乎只分配了一个 ts, 没有 跟 Percolator 那样分配 start_ts 和 commit_ts。
客户端的读依赖 timestamp 和对应的机器,在上面拿到 SnapShot 来读,而写需要过 Leader。所有的 Retry 会试图在系统内部进行,不需要 Spanner 做额外的操作。
Spanner 的读写肯定都会和 Paxos 逻辑有关,感觉有点类似 Lease + Raft。Leader 会有一个 Lease,在 replica 写完成的时候,会延续自己的 lease, 而 Leader 需要 explicit 的续命。Spanner 允许切换 Leader, 但是要定义一个 Smax, 只有时间超过 Smax, 即 TT.after(s_max), 才会允许切换。
事务中,Spanner 使用 2PC,事务会分配时间戳,代表事务提交的时间(Percolator 会在 提交 和 开始 都分配时间戳,判断重复的区间)。
Spanner 依赖下面这些单调性:在每个 Paxos 组内,Spanner 会以单调增加的顺序给每个 Paxos 写操作分配时间戳,即使在跨越多个领导者时也是如此。一个单个的领导者副本,可 以很容易地以单调增加的方式分配时间戳。在多个领导者之间就会强制实现彼此隔离的不连 贯:一个领导者必须只能分配属于它自己租约时间区间内的时间戳。要注意到,一旦一个时 间戳 s 被分配,smax 就会被增加到 s,从而保证彼此隔离性(不连贯性)。
所以写的时候,会有全局的时间戳。但是同时,很吊诡的是,这个时间戳是在开始的时候被分配的

读取的事务会有一个 t_safe , 这个值代表安全读取的时间戳,没有到的话可能是要阻塞/重试的,那么可能更改的有:
- 写入状态机的最大时间 Paxos 的 safe, 即被应用到 Paxos 状态机的最大时间戳。
- Transaction Manager 的事务相关的 ts, 如果小于写入的 ts 的话,可能会有冲突,需要 block
实现细节
Like Bigtable, writes that occur in a transaction are buffered at the client until commit. As a result, reads in a transaction do not see the effects of the transaction’s writes. This design works well in Spanner because a read returns the timestamps of any data read, and uncommit- ted writes have not yet been assigned timestamps.
这个是靠 ts_safe 那个约束处理的。
RW 事务中,先请求一个 Paxos Group,拿到读锁,读需要读的数据,然后 boffer 所有的 write。然后开始 2PC:
- Participant 拿到写锁,分配一个单调递增的 prepare ts,提交一个 Prepare Paxos Log,然后把对应的 prepare ts 给 Coodinator
- Coodinator 拿到一个递增的,大于 TT.now().latest 、大于所有 prepare ts 的 commit ts
- The coordinator leader then logs a commit record through Paxos (or an abort if it timed out while waiting on the other participants).
- Before allowing any coordinator replica to apply the commit record, the coordinator leader waits until TT.after(s), so as to obey the commit-wait rule described in Section 4.1.2.
也就是说,单机上的任何冲突靠 wound-wait, 多机器靠上面的协议实现。
读相对简单的多,拿到 Group 的 scope 然后拿到 safe_ts 来读。不过 safe_ts 选举也是有技巧的:
If the scope’s values are served by a single Paxos group, then the client issues the read-only transaction to that group’s leader. (The current Spanner implementa- tion only chooses a timestamp for a read-only transac- tion at a Paxos leader.) That leader assigns sread and ex- ecutes the read. For a single-site read, Spanner gener- ally does better than TT.now().latest. Define LastTS() to be the timestamp of the last committed write at a Paxos group. If there are no prepared transactions, the assign- ment sread = LastTS() trivially satisfies external consis- tency: the transaction will see the result of the last write, and therefore be ordered after it.
If the scope’s values are served by multiple Paxos groups, there are several options. The most complicated option is to do a round of communication with all of the groups’s leaders to negotiate sread based on LastTS(). Spanner currently implements a simpler choice. The client avoids a negotiation round, and just has its reads execute at sread = TT.now().latest (which may wait for safe time to advance). All reads in the transaction can be sent to replicas that are sufficiently up-to-date.